









2025年了,小样本学习还能做吗?当然是可以的,最近几个Nature子刊(比如nature machine intelligence),以及CVPR24等顶会上还出现了不少成果。比如小样本异常检测SOTA模型PromptAD。
这些新成果的创新主要体现在如何在数据稀缺的环境下,通过借用元学习、迁移学习、生成模型、度量学习等技术,提升模型的学习效率和泛化能力,当然这也是小样本学习现在的主流研究方向,说具体点就是4个思路:基于数据增强、基于度量学习、基于元学习、添加其他辅助任务。
本文根据以上4点分别整理了最新的小样本学习参考论文,共27篇,可以说前沿的成果和创新思路基本都在这了,强烈建议想发论文的同学研读。
全部论文+开源代码需要的同学看文末
基于数据增强的方法
通过各种技术手段扩充训练数据集,以提高模型的泛化能力。
LLM2LLM:Boosting LLMswith Novel Iterative Data Enhancement
方法:论文介绍了一种名为LLM2LLM的方法,用于小样本学习场景中的大型语言模型(LLM)性能提升,该模型通过使用教师LLM生成合成数据来扩充小规模特定任务数据集,解决低数据环境下微调大语言模型的挑战,显著提升模型性能并减少数据收集成本。
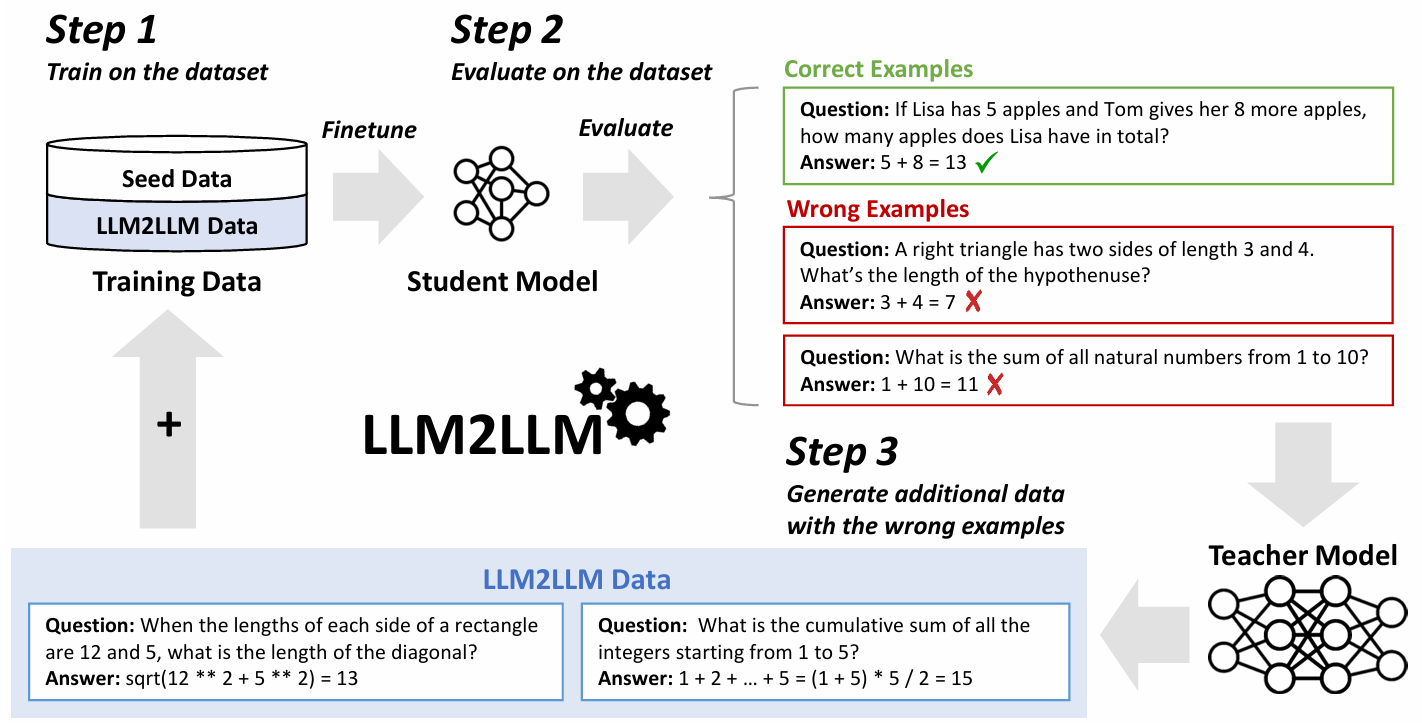
创新点:
-
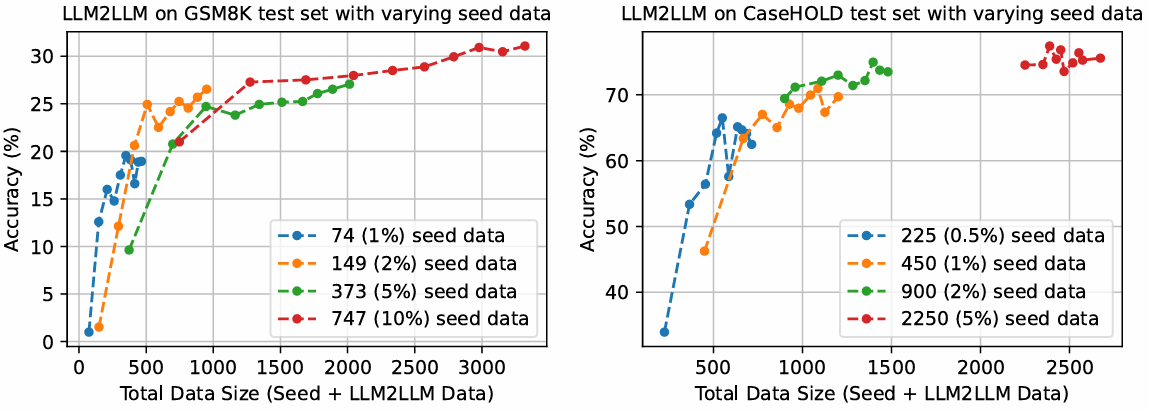
引入了一种称为LLM2LLM的自适应迭代数据增强框架。利用大型语言模型(LLM)来扩展小规模微调数据集,通过生成合成数据来减少实际数据的需求。
-
采用了针对性和迭代性的增强策略。这种策略通过只增强模型在训练中错误的例子,避免了无效的数据扩展,并提高了数据增强的效率。
基于度量学习的方法
侧重于学习有效的样本间距离度量,以改善分类性能。
Does Few-shot Learning Suffer from Backdoor Attacks?
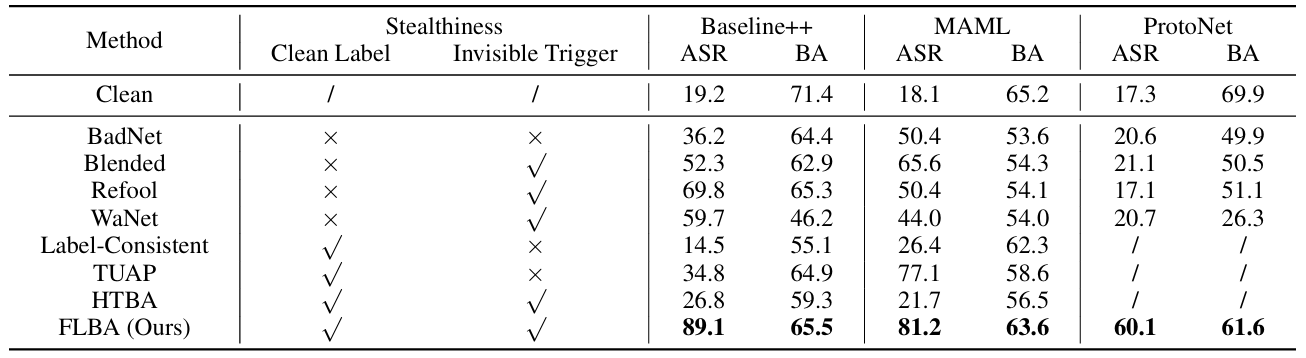
方法:本文探讨了小样本学习(FSL)中后门攻击的潜在威胁,提出了一种新颖的后门攻击方法FLBA,通过生成具有嵌入偏差的触发器和优化吸引与排斥扰动来提高攻击成功率,同时保持干净样本的表现。
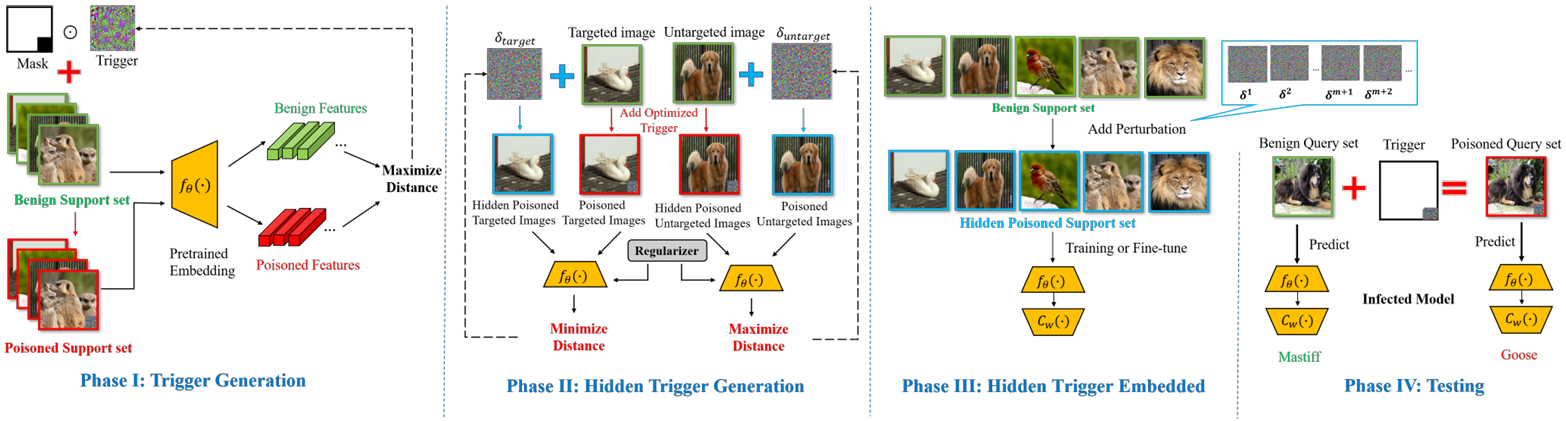
创新点:
-
提出了一种新的后门攻击方法,称为少样本学习后门攻击(FLBA),其中生成了一种触发器以最大化中毒特征和良性特征之间的差距。
-
为了增强攻击的隐蔽性,作者引入了最大-最小相似度损失,用于生成不可察觉的吸引和排斥扰动。
添加其他辅助任务的方法
通过引入多任务学习、自监督学习和对比学习等技术,进一步提升模型的泛化能力和特征表示质量。
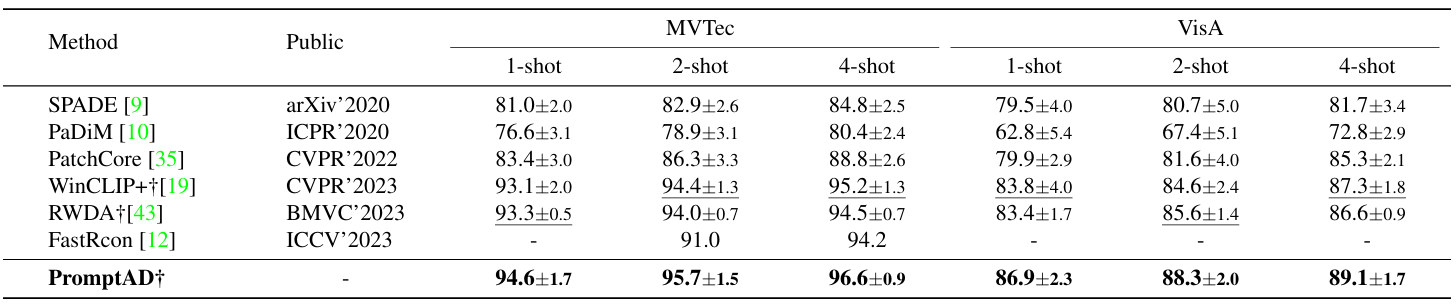
PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
方法:本文研究探讨了提示学习在单类异常检测中的可行性,提出了一种名为PromptAD的单类提示学习方法,通过语义连接及显式异常边距等创新技术在小样本场景下实现了优异的图像/像素级检测效果。
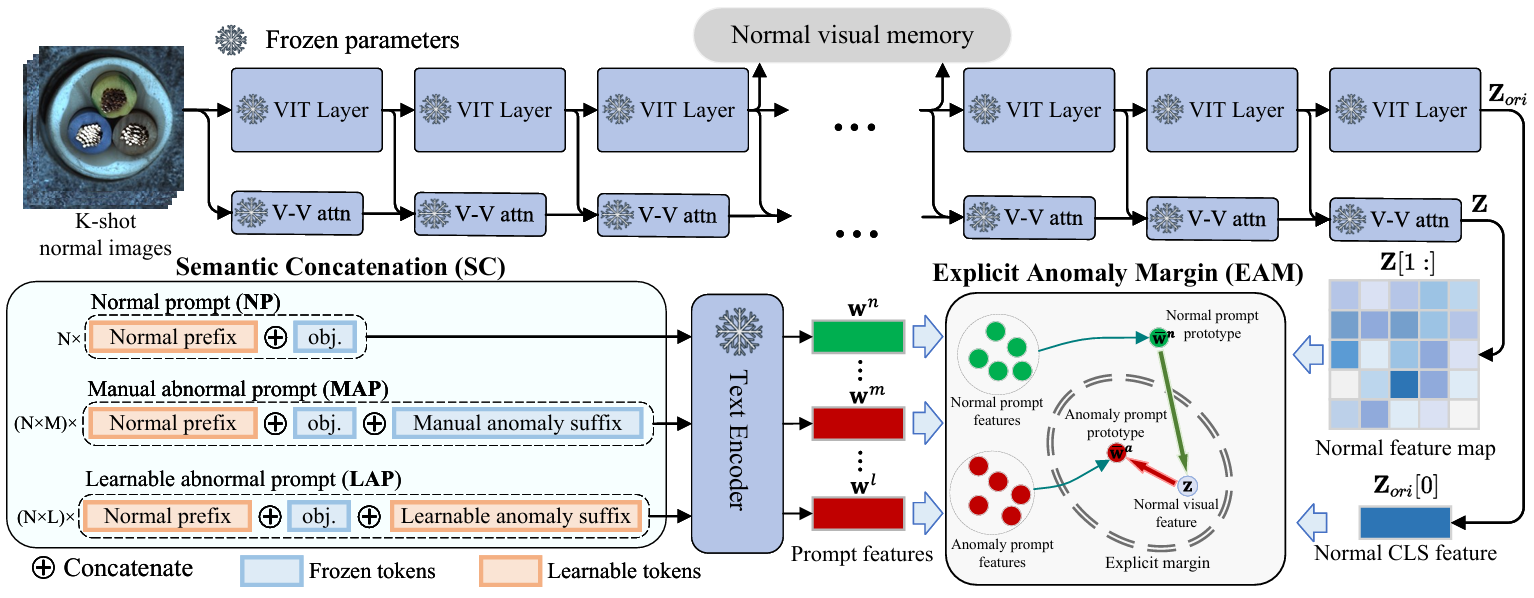
创新点:
-
提出了一种新的语义拼接方法,通过将正常提示与异常后缀拼接,构建大量的异常提示样本。
-
提出了一种显式异常边界损失,通过超参数控制正常提示特征与异常提示特征之间的边界。
-
提出了一种新的异常检测方法PromptAD,在仅有少量正常样本的情况下自动学习提示。
基于元学习的方法
通过模型无关的元学习方法、优化参数初始化和记忆增强等策略,让模型能够在少量甚至单个示例的情况下快速适应新任务。
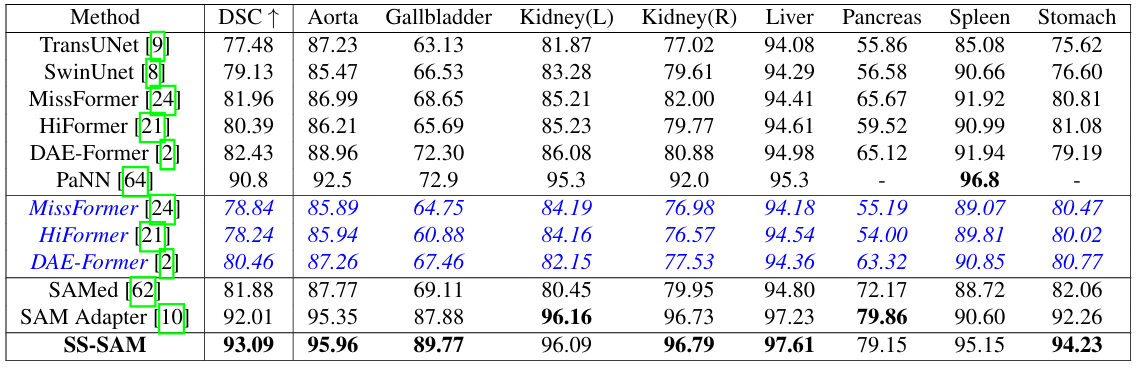
Self-Sampling Meta SAM: Enhancing Few-shot Medical Image Segmentation with Meta-Learning
方法:论文提出了一种创新的SSM-SAM模型,专门针对小样本医疗图像分割问题进行了优化。该模型通过正负自采样提示编码器和灵活掩码注意力解码器,有效提升了上下文关系和精细边界信息的捕捉能力。
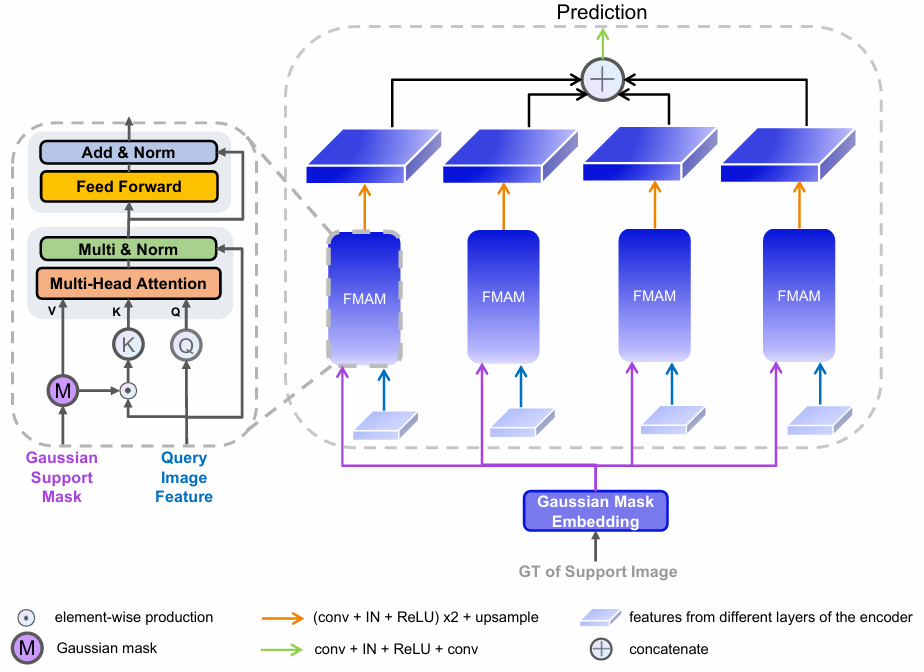
创新点:
-
通过结合正负点提示,模型不仅关注正部位,还能有效识别负部位,从而在推理时仅需一个点即可提升分割性能。
-
通过引入灵活掩码注意力模块(FMAM),利用跨注意力机制扩展或收缩模糊的支持掩码,从而为查询图像预测掩码。
-
引入一种基于MAML++的在线参数适应技术,优化了SAM的泛化和小样本学习能力。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“27小样”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









