









LSTM结合Transformer,在时间序列预测上效果拔群!不仅巧妙融合了二者的优势,还构建了一个强大而灵活的预测框架,为我们处理复杂时间序列数据提供了更牛x的工具。
这方向如今是深度学习领域的热门研究主题,前景非常可观,在工业物联网(如设备故障预警)、智慧城市(如交通流量预测)、生物医学、环境科学(如气象预测)等领域都有广泛应用。相关成果频繁发表于顶会顶刊,尤其是跨学科相关的。
如果想做创新,建议聚焦模型轻量化、注意力机制优化、跨领域应用,并结合实际工业需求设计实验(如大时滞、多变量场景)。本文整理了10篇LSTM+Transformer+时序预测新论文,需要参考的自取~
全部论文+开源代码需要的同学看文末
Energy consumption prediction strategy for electric vehicle based on LSTM-transformer framework
方法:论文提出了一种基于LSTM-Transformer框架的电动汽车能耗预测方法,通过整合车辆参数、环境因素、驾驶风格和驾驶条件等多维度特征,利用LSTM处理时间序列数据的短期依赖性,并结合Transformer的自注意力机制捕捉长期依赖关系,从而实现高精度的电动汽车电池剩余电量(SOC)预测。
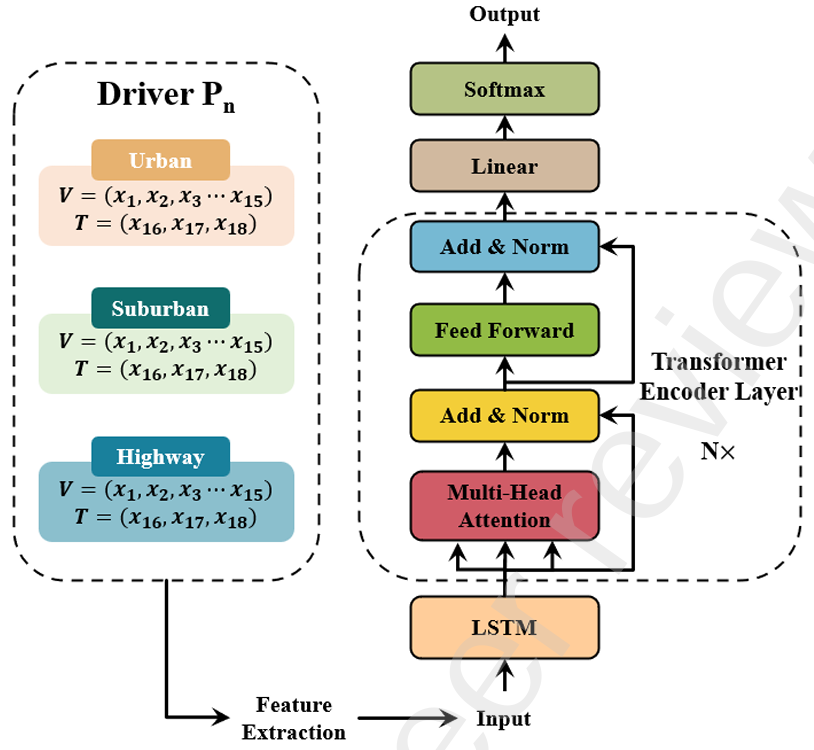
创新点:
-
提出了一种基于电池电压和电流随时间积分的数值重构方法,用于精确估计电动车能耗变化。
-
引入了一种基于LSTM-Transformer模型的电动车能耗预测框架,与传统模型相比,提高了预测精度和泛化能力。
-
提出了基于短途电力消耗预测的长途电动车能耗预测新方法,在选定的数据集上表现出良好的预测精度。
A hybrid Transformer-LSTM model apply to glucose prediction
方法:论文提出了一种基于混合Transformer-LSTM模型的血糖预测方法,利用连续血糖监测(CGM)系统收集的数据,通过结合Transformer的长距离依赖捕捉能力和LSTM的时间序列建模优势,实现了对血糖水平的高精度预测。
创新点:
-
提出了一种创新的混合模型,将Transformer的全局数据上下文处理能力与LSTM的时间序列建模优势相结合,用于提升血糖预测的准确性。
-
通过对大量CGM数据集的训练和验证,证明了混合Transformer-LSTM模型在实时血糖预测中的优越性。
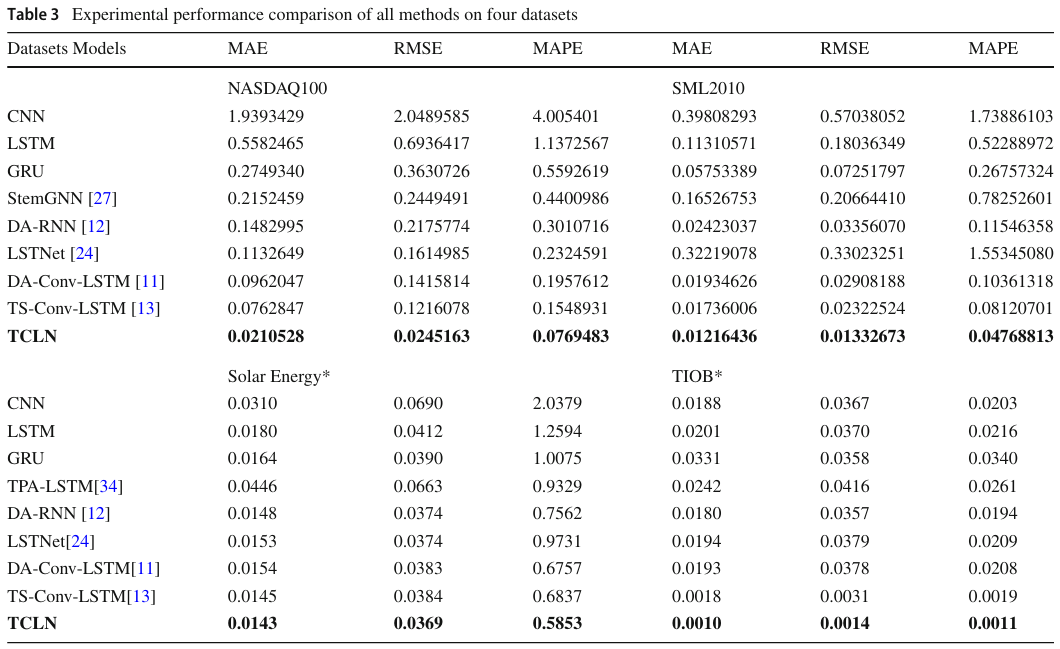
TCLN: A Transformer-based Conv-LSTM network for multivariate time series forecasting
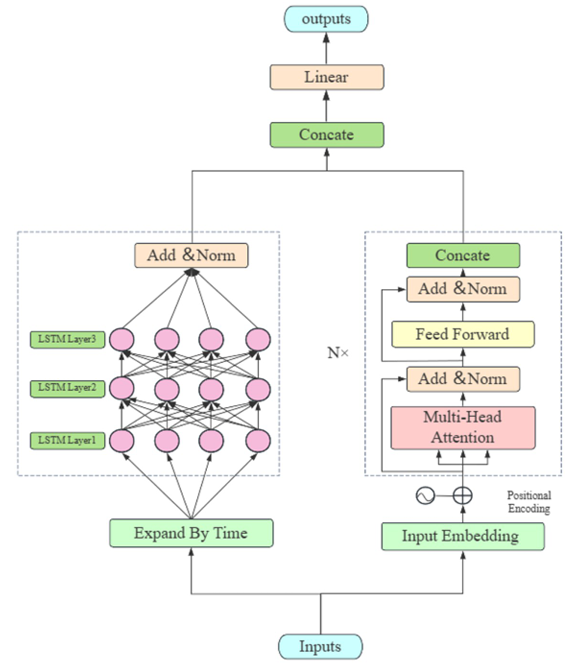
方法:论文提出了一种基于Transformer和LSTM的多变量时间序列预测模型TCLN,通过结合Transformer的自注意力机制和LSTM的时间序列建模能力,同时引入多核卷积神经网络来提取空间特征,有效捕捉时间序列中的长期依赖、空间关联和时空相关性,显著提升了多变量时间序列预测的准确性。
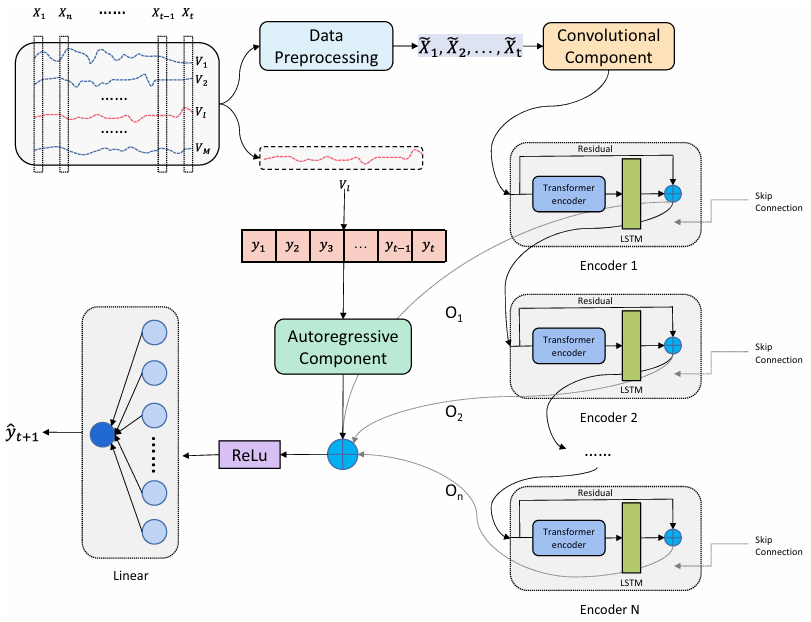
创新点:
-
多核卷积神经网络(CNN)层用于提取比传统简单CNN更丰富的空间信息。
-
结合Transformer编码器层和长短期记忆(LSTM)网络,TCLN模型能够有效捕获时间序列中的长期时序信息。
-
通过将自回归(AR)模型集成到TCLN中,增强了模型的鲁棒性。
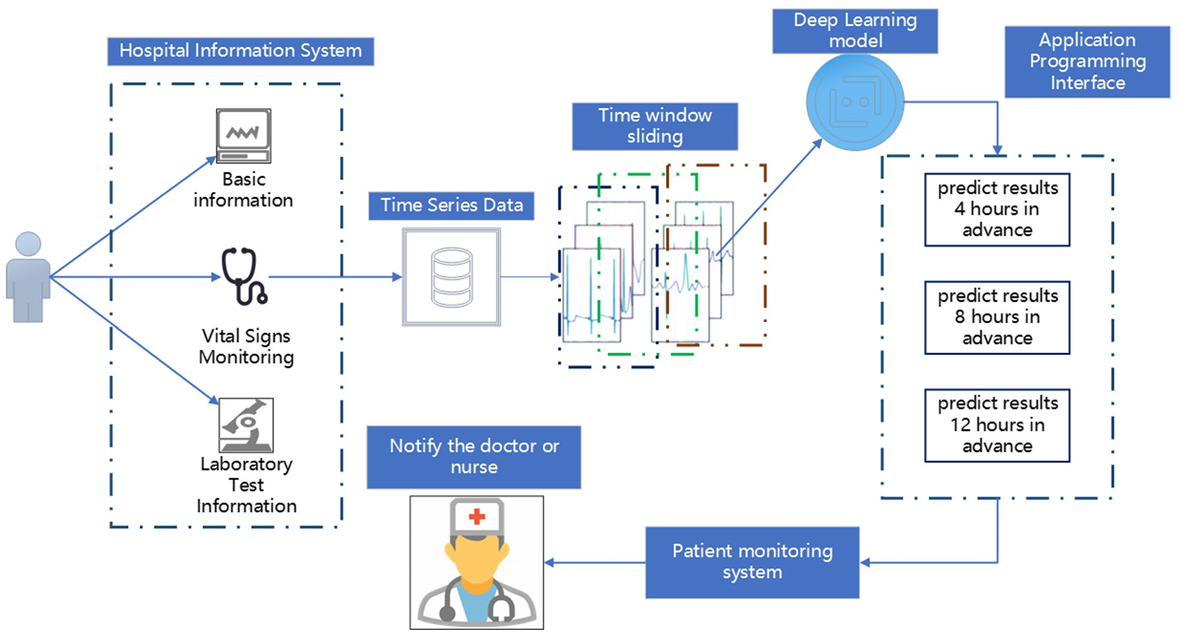
A time series driven model for early sepsis prediction based on transformer module
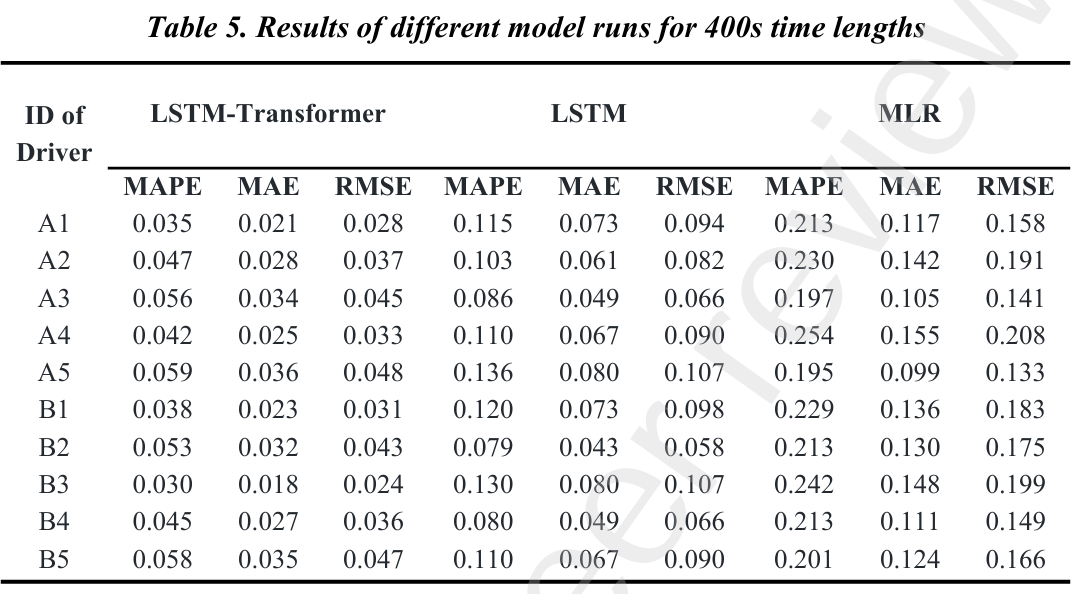
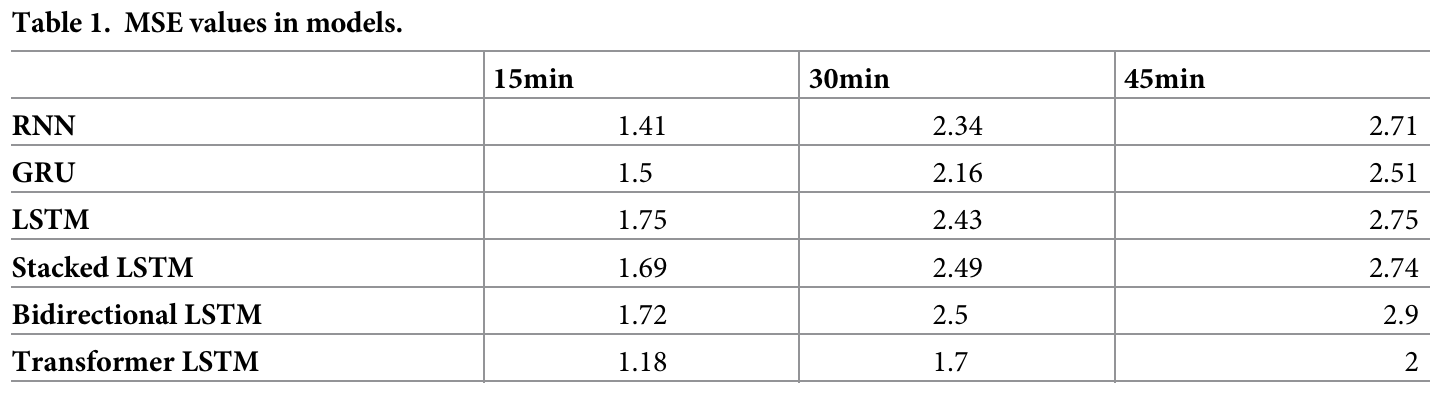
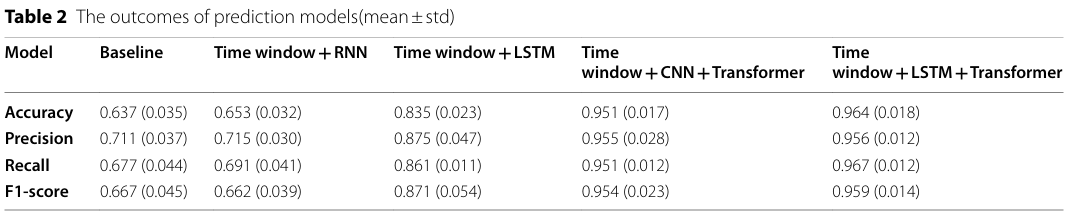
方法:论文提出了一种基于LSTM+Transformer的时间序列预测模型,用于早期预测脓毒症。通过分析患者在脓毒症发病前4小时、8小时和12小时的时间序列数据,模型在12小时时间窗口内表现出色,准确率达到0.964,显著优于传统方法。
创新点:
-
提出了一种创新的基于Transformer架构的时间序列数据预测模型,专门用于预测脓毒症的早期发生。
-
引入了不同的时间窗口(如发病前4小时、8小时和12小时)来收集患者的时间序列数据,并通过调整时间窗口来比较不同模型的预测能力。
-
开发了一个将预测模型与医院信息系统集成的框架,通过实时收集患者数据来测试模型。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“融合时序”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









