









 本文探讨了模糊集的概念,解释了为什么需要模糊集,尤其是在处理自然语言中的不确定性时。通过对比经典二元集,介绍了模糊集如何通过隶属函数来描述元素的匹配度,从而提供更丰富的语义描述。
本文探讨了模糊集的概念,解释了为什么需要模糊集,尤其是在处理自然语言中的不确定性时。通过对比经典二元集,介绍了模糊集如何通过隶属函数来描述元素的匹配度,从而提供更丰富的语义描述。
Fuzzy Sets
一、为什么要定义模糊集?
首先来看个例子。例如我们先定义一个“高个子”的集合A,然后去匹配你身边认识的人是否属于集合A。在经典的Crisp Sets(two-valued 二元集)理论中,只定义某一元素隶属于或不隶属于A。假设“高个子”的标准是身高高于1.75m,那么身高1.78m的人是A的成员,而身高1.50m的人不是A的成员。
但是,二元集理论有以下问题:
- 假设一个人身高1.73m,尽管他离1.75m的标准只差了0.02m,却被粗暴地判定为不是“高个子”。
- 在“高个子”集合A里面,也没有任何区分度。身高1.75m与身高2.20m被一视同仁。
- 对于集合A内成员,也没有包含语义(semantic)描述。
相反地,fuzzy set(模糊集)没有以上问题。
在模糊集理论中,所有人都是集合A的成员(member),只是匹配度不同。例如身高2.20m的人的成员匹配度可为0.95,而身高1.7m的人成员匹配度为0.40。
模糊集是二元集的一个扩展,并使为自然语言中的不确定度(uncertainty)建模成为了可能。自然语言中的模糊性更多地用语义上的词语去描述,比如“今天乌云很多,很有可能下雨”,就使用了“很多”,“很有可能”这两个语义词汇——人的大脑是能理解这种描述的。而模糊集,和配套的模糊逻辑系统,为计算机系统理解并推理这种语义含糊的描述提供了工具。
二、模糊集,隶属函数(membership function)的定义
与传统集合不同,模糊集中的每个元素都有对应的隶属度(membership degree)。隶属度是指一个元素属于这个集合的确定度(或不确定度)。所以,模糊集被隶属度映射函数所描述。严格定义如下:
- Fuzzy sets: a fuzzy subset A of X is associated with a characteristic function
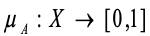
- The characteristic function is called membership function(隶属函数).x ∈ X
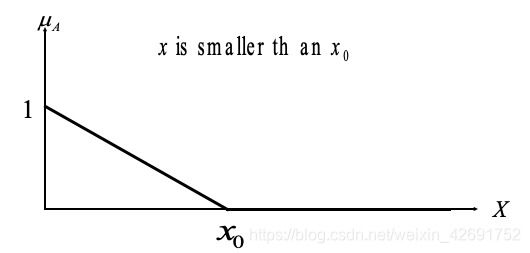
特别地,对于二元集,隶属函数μA的取值只有0或1。

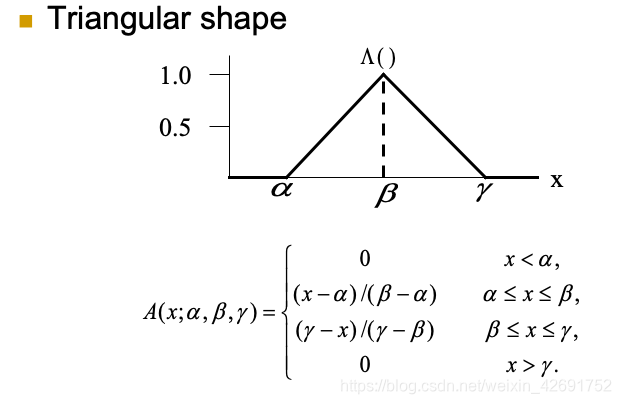
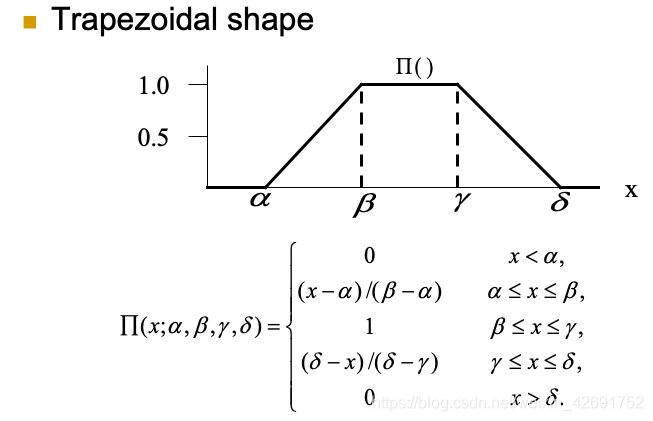
三、隶属函数(membership function)的常用形式
在为模糊集选择适当的隶属函数时,要符合以下约束:
- 隶属函数的下界是0,上界是1。
- 因此,隶属函数的取值范围是[0,1]。
- 对于每个 x ∈ X,μA(x)的值唯一。也就是同一个模糊集中,每一个元素只有一个隶属度。
以下是常见可以使用的离散或连续函数:
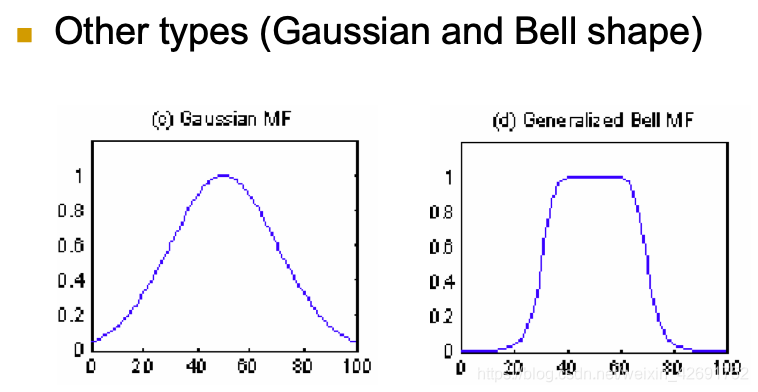
四、Fuzzy Subset
在许多应用中,模糊子集用于
传递更详细的语义概念。比如,可以将词语“old”定义为“age”的子集。
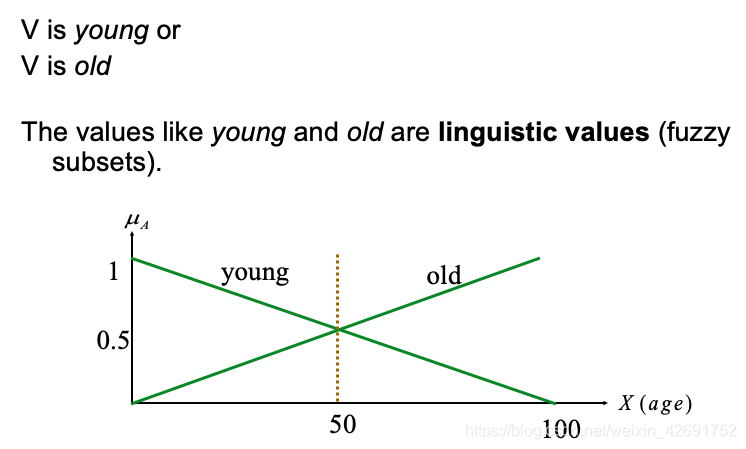
或者“temperature”的子集
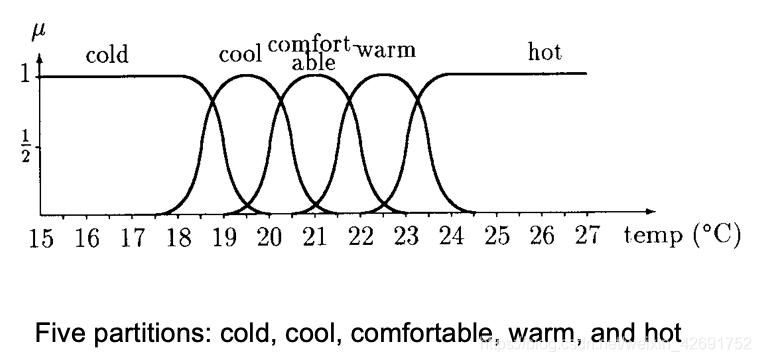
更常见的子集形式:
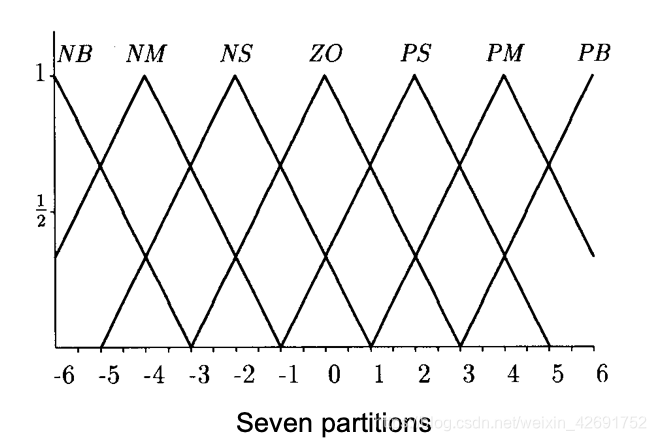
NB:Negative Big
NM:Negative Middle
NS:Negative Small
PB:Positive Big
PM:Positive Middle
PS:Positive Small

















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









