










Jetson Nano
文章目录
一、Jetson Nano系统安装及基础环境配置
建议配个5V 4A的电源,5V 2A的电源需要将板子设定在5W功耗模式下,且会导致机器莫名其妙重启等问题。有条件的再加个风扇散热
1.系统安装
直接将镜像烧录到SD卡中插入设备即可安装系统。下载的时候建议用迅雷下载,十来分钟就能下完
镜像下载链接:Jetson Nano镜像(直接复制这个链接到迅雷就可以下载了,当然点击进去也可以直接用浏览器下载)
烧录镜像软件:win32disk、SD Memory Card Formatter、Etcher等都可以
2.换源
备份原来的source.list文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
修改source.list文件
sudo gedit /etc/apt/sources.list
选择以下的一个源替换文件中的内容
清华源
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiversedeb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-proposed main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-proposed main restricted universe multiverse
中科大源
deb http://mirrors.ustc.edu.cn/ubuntu-ports bionic main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports bionic-updates main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports bionic-backports main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports bionic-security main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports bionic main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports bionic-updates main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports bionic-backports main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports bionic-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb http://mirrors.ustc.edu.cn/ubuntu-ports bionic-proposed main restricted universe multiverse
# deb-src http://mirrors.ustc.edu.cn/ubuntu-ports bionic-proposed main restricted universe multiverse
阿里源
deb https://mirrors.aliyun.com/ubuntu-ports/ bionic main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu-ports/ bionic-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu-ports/ bionic main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu-ports/s bionic-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu-ports/ bionic-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.aliyun.com/ubuntu-ports/ bionic-proposed main restricted universe multiverse
# deb-src https://mirrors.aliyun.com/ubuntu-ports/ bionic-proposed main restricted universe multiverse
替换完后跟更新一下即可,不要乱upgrade,会出现老多莫名其妙的错误
sudo apt-get update
3.添加cuda路径
安装完系统后直接nvcc -V查看cuda版本会显示找不到命令,其实JetPack包里面已经装好了cuda,只不过没添加到bashrc中,将cuda的环境变量添加到改文件即可
sudo gedit ~/.bashrc
#复制下面三行到改文件的最下面
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_ROOT=/usr/local/cuda
#保存后执行下面的命令
source ~/.bashrc
开一个新的终端输入nvcc -V即可看到cuda版本号了
4.安装conda、pip
(1):安装conda
更新:原本系统的python默认版本是3.6,在安装完Archiconda后系统默认python版本变更为3.7,且出现了pip版本混乱的问题,后面我重新刷机不再安装Archiconda,有遇到这个问题的朋友可以一起讨论下
anaconda是不支持arm架构的这些嵌入式设备的,所以想在arm架构上使用conda命令只能使用Archiconda或者是miniconda,nano上我用的是Archiconda
GitHub:Archiconda

下载完后进入到文件所在的位置,执行
chmod 777 Archiconda3-0.2.3-Linux-aarch64.sh
./Archiconda3-0.2.3-Linux-aarch64.sh
安装完成后需要添加变量到bashrc,不然会出现创建环境的时候权限不够的问题
sudo gedit ~/.bashrc
#在最后添加
export PATH=~/archiconda3/bin:$PATH
#保存后退出执行
source ~/.bashrc
(2):安装pip
sudo apt-get install libhdf5-serial-dev hdf5-tools zlib1g-dev zip libjpeg8-dev libhdf5-dev python3-pip
升级pip,有些博主写的一些命令虽然可以升级pip3版本,但是后续会出现其他问题,具体问题参考一个博主写的:pip3报错
总结一下比较正确的升级命令是
python3 -m pip install --upgrade pip
二、Jetson Nano目标检测
yolo系列
1.引入库
GitHub链接:darknet
权重文件:yolov4-tiny.weight
下载解压后
cd darknet-master
make -j4
测试
#图片
./darknet detect cfg/yolov4-tiny.cfg yolov4-tiny.weights data/dog.jpg

#本地视频,需自己下载放入
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights data/sample_720p.mp4

#usb实时检测,默认不输入参数即调用摄像头
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights
#但是不输入参数是以原画质输入的,我的usb是1080p的,检测帧率只有2-3帧,可以加参数:/dev/video0,输入的变为640*480,帧率就有9帧左右
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights /dev/video0

2.模型训练
训练一个人脸识别的模型,参考博客:win10 下的YOLOv3 训练 wider_face 数据集检测人脸
数据集下载链接:WIDER FACE(超快,国内也能下,两分钟下完3G)
因为参考博客是再Win10上的,所以有些地方需要修改一下:
4、(1)配置cfg文件:将testing下的batch和subdivisions加#注释掉
在训练开始后报错:CUDA Error: out of memory,把文件中第一个subdivisions改成8,batch改成8的倍数
max_batches 改为 max_batches = 2000 (第20行)max_batches 的数量为检测的目标数 * 2000
steps 改为 steps=1600,1800 (第22行)steps =max_batches 0.8 ,0.9
classes 改为 classes =1 (第 610 、696、783 行)即自己模型的类别数
filters 改为 filters =18 (只改三个 yolo 层的上一层的 filters 即 第 603、689 、776 行 )即 filters =3(classes+5)
4、(3)配置Makefile文件:把NVCC=nvcc改为NVCC=/usr/local/cuda-10.2/bin/nvcc
5、开始训练:
回到/darknet-master目录,先make clean再make编译一下(编译失败改完Mkefile后记得再执行一下make clean再执行make),然后执行
#单GPU训练
./darknet detector train build/darknet/x64/data/obj.data build/darknet/x64/cfg/yolov3-obj.cfg build/darknet/x64/darknet53.conv.74
#多GPU训练,我用的是四块就0123,同理两块就01
./darknet detector train build/darknet/x64/data/obj.data build/darknet/x64/cfg/yolov3-obj.cfg build/darknet/x64/darknet53.conv.74 -gpus 0,1,2,3
#中断后继续训练
./darknet detector train build/darknet/x64/data/obj.data build/darknet/x64/cfg/yolov3-obj.cfg buckup/yolov3-obj.weights
部分参数介绍:
每一次迭代的第一个数值是迭代次数,每一百次迭代存储一次模型,每个类一般迭代2000次
avg loss:是错误率指标,刚开始的时候会很大,最后会降到个位数甚至接近0
训练完成在backup文件夹下生成四个权重文件,只要用last那个就行

图片测试

3.部署模型到DeepStream
所需要准备的文件(参考第二部模型训练):
data.name
yolov3-obj.cfg
yolov3-obj.weights
首先将上面的文件复制到objectDetector_Yolo文件夹下,然后打开终端复制config_infer_primary_yoloV3.txt为config_face.txt,如:
sudo cp config_infer_primary_yoloV3.txt config_face.txt
#文件有两处需要更具模型更改的地方
custom-network-config=yolov3-obj.cfg
model-file=yolov3-obj.weights
复制deepstream_app_config_yoloV3.txt为deepstream_face.txt如:
sudo cp deepstream_app_config_yoloV3.txt deepstream_face.txt
#
labelfile-path=data.name
config-file=config_face.txt
打开nvdsinfer_custom_impl_Yolo文件夹,修改nvdsparsebbox_Yolo.cpp文件下classes
static const int NUM_CLASSES_YOLO = 80;#将数字修改为模型类别数
保存退出后执行make clean后再次make
执行deepstream-app -c deepstream_face.txt即可
三、Jetson Nano TensorRT DeepStream
DeepStream已经嵌入TensorRT,所以就不需要去再烦心TensorRT的配置问题,在DeepStream里面可以直接使用TensorRT
1.安装DeepStream
先下载DeepStream SDK包:DeepStream5.1
sudo apt install \
libssl1.0.0 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstrtspserver-1.0-0 \
libjansson4=2.11-1
sudo apt-get install librdkafka1=0.11.3-1build1
安装
sudo tar -xvf deepstream_sdk_v5.1.0_jetson.tbz2 -C /
cd /opt/nvidia/deepstream/deepstream-5.1
sudo ./install.sh
sudo ldconfig
安装查看的时候出现 No EGL Display的错误

添加unset DISPLAY变量
sudo vim ~/.bashrc
unset DISPLAY
source ~/.bashrc
查看DeepStream安装情况,安装完成
deepstream-app --version-all

2.测试DeepStream
(1)deepstream-test
cd /opt/nvidia/deepstream/deepstream-5.1/sources/apps/sample_apps/deepstream-test1/
#修改Makefile中cuda的版本:CUDA_VER?= -->CUDA_VER=10.2
sudo make
./deepstream-test1-app /opt/nvidia/deepstream/deepstream-5.1/samples/streams/sample_720p.h264
视频存储路径都在/opt/nvidia/deepstream/deepstream-5.1/samples/streams/下,可以选择不同的视频测试
(2)deepstream-app
cd /opt/nvidia/deepstream/deepstream-5.1/samples/configs/deepstream-app
deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt


补充:
配置文件中,也就是source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt 或同目录其他文件中,有一个跟踪的选项可以实时跟踪检测到的物体,具体信息如下:
[tracker]
#1开启追踪,0关闭追踪
enable=1
#width和height必须是32的倍数
tracker-width=640
tracker-height=384
#以下三个so文件是三个不同的跟踪器
#IOU 追踪器的性能最好,但是同一物件的编号并不是太稳定
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_mot_iou.so
#NVDCF 追踪器的编号最为稳定,但性能大概只有 IOU 的 1/4,最多只能承受 2 路视频的实时分析
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_nvdcf.so
#KLT 算法可以支持到8路以内的实时识别,追踪能力也比 IOU 好不少,不过这个算法对 CPU 的占用率比较高
ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_mot_klt.so
(3)deepstream-yolov3
cd /opt/nvidia/deepstream/deepstream-5.1/sources/objectDetector_Yolo
#将权重文件和配置文件下载复制到这个文件夹下面,然后开打nvd开头的文件夹下面执行
sudo make
cd ..
#运行即可
deepstream-app -c deepstream_app_config_yoloV3.txt
deepstream-app -c deepstream_app_config_yoloV3_tiny.txt
在运行yolo和实时摄像头的时候有可能出现以下错误:

在运行前输入export DISPLAY=:1 or 0即可,但是这样开机后再运行还是会出错,永久更改的话就去bashrc里面把之前安装deepstream的unset DISPLAY给去掉就行了,记得source一下(unset DISPLAY是因为在安装deepstream时候显示EGL错误加入环境变量的,暂时没有找到原因,但只有这个解决方案,上面显示的这个错误也是没找到解决方法,后面看了半天把这个删掉就行,重启仍有效,所以把这个问题po出来,有同样问题的朋友可以按照这个改一下,我暂时没遇到过其他问题)
yolov3检测加跟踪,yolov3.weights下是5-6帧,tiny下是40多帧

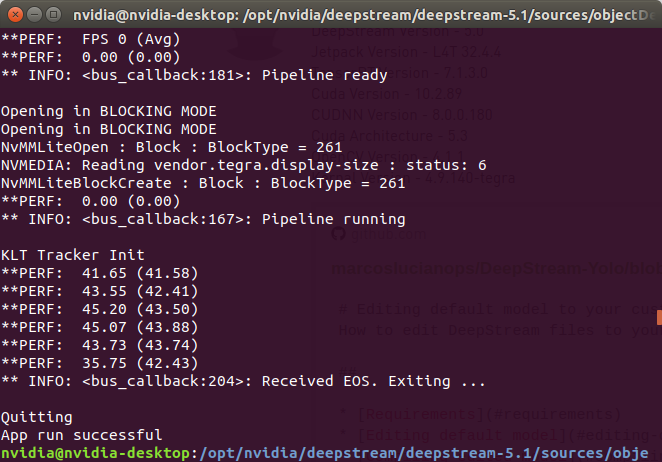
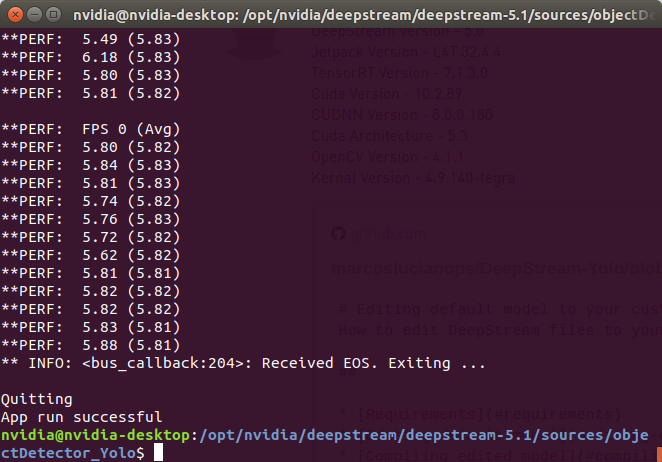
(4)deepstream-usb
我测试的时候用的是普通的usb接口摄像头,即插即用
在测试USB摄像头前,需要获取正确的摄像头参数并更改配置文件,不然会一直报错运行不起来
获取摄像头参数
#安装v4l2
sudo apt-get install v4l-utils
#查看v4l2设备
v4l2-ctl --list-devices
#运行后显示如下,说明usb摄像头所在的位置是/dev/video0
#USB 2.0 Camera (usb-3610000.xhci-2):
# /dev/video0
#查看相机参数
v4l2-ctl --device=/dev/video0 --list-formats-ext
相机参数显示如图

依照上图显示的相机参数,更改source1_usb_dec_infer_resnet_int8.txt文件
cd /opt/nvidia/deepstream/deepstream-5.1/samples/configs/deepstream-app
sudo geidt source1_usb_dec_infer_resnet_int8.txt
#更改[source0]下的信息
camera-width=800
camera-height=600
camera-fps-n=21
#更改[primary-gie]下的信息,这个是模型文件的
#在步骤2的时候在model文件下已经生成了启动文件,所以这边不需要在重新生成启动文件
model-engine-file=../../models/Primary_Detector_Nano/resnet10.caffemodel_b1_gpu0_fp16.engine
config-file=config_infer_primary_nano.txt
#保存退出后运行
deepstream-app -c source1_usb_dec_infer_resnet_int8.txt
















 7321
7321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









