







 SwAV是一种自监督学习方法,通过多视图聚类和软标签分配,利用不同分辨率的图像增强来提升模型性能。
SwAV是一种自监督学习方法,通过多视图聚类和软标签分配,利用不同分辨率的图像增强来提升模型性能。
前面讲到的MOCO、SimCLR把优化的方向主要放在增加负例上,费时费力,SwAV来了个返璞归真。。
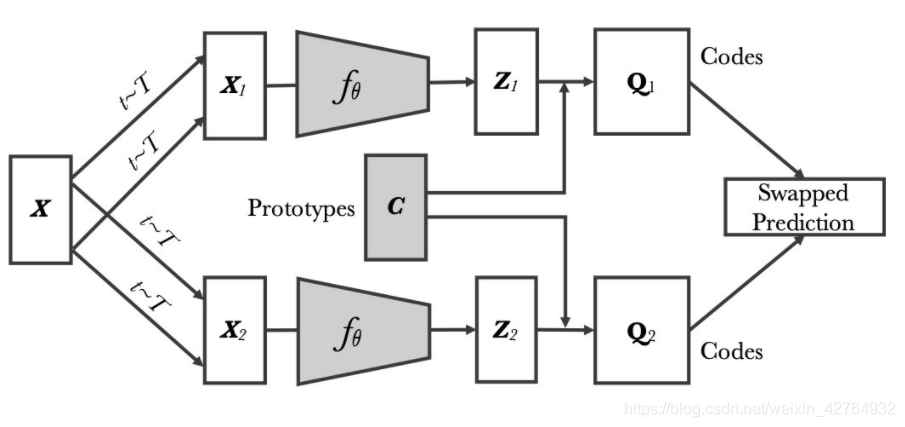
简要步骤
- 每个batch输入数据为 x ∈ R N ∗ C ∗ H ∗ W x\in R^{N*C*H*W} x∈RN∗C∗H∗W, 分别经过不同的Aug, 得到 x 1 , x 2 x_1, x_2 x1,x2
- 将 x 1 , x 2 x_1, x_2 x1,x2输入网络中,得到输出 z 1 , z 2 ∈ R N ∗ d z_1, z_2 \in R^{N*d} z1,z2∈RN∗d
- 已知K个聚类中心,表示为 C ∈ R K ∗ d C\in R^{K*d} C∈RK∗d,将输出与聚类中心计算相似度,得到相似度矩阵 Q ∈ R K ∗ N Q \in R^{K*N} Q∈RK∗N,理想情况下,样本与自己的类簇中心相似度为1,与其他的为0,其实就类似于有监督任务中的one-hot label,不过作者发现soft label效果会好一些。这样每个样本又获得了一个新的表示(Codes)。
- 计算损失,有了 z 和 q 之后,理论上同一张图片不同view所产生的 z 和 q 也可以相互预测,作者便定义了新的loss:
L
(
z
t
,
z
s
)
=
l
(
z
t
,
q
s
)
+
l
(
z
s
,
q
t
)
L(z_{t},z_{s})=l(z_{t},q_{s})+l(z_{s},q_{t})
L(zt,zs)=l(zt,qs)+l(zs,qt)
其中 l ( z t , q s ) = − ∑ k q s ( k ) log g p t ( k ) l(z_{t},q_{s})=- \sum _{k}q_{s}^{(k)}\log gp_{t}^{(k)} l(zt,qs)=−k∑qs(k)loggpt(k)
p t = e x p ( z t T c k / τ ) ∑ k ′ e x p ( z t T c k / / τ ) p_{t}= \frac{exp(z_{t}^{T}c_{k}/ \tau)}{\sum _{k^{\prime}}exp(z_{t}^{T}c_{k}// \tau)} pt=∑k′exp(ztTck//τ)exp(ztTck/τ)
所以题目说SwAV像是在假装自己是有监督的。。
同时SwAV也提出了一种新的数据增强方法,将不同分辨率的view进行mix。
Multi-crop策略包括了:
(1)两个标准的RandomResizedCrop;
(2)V个额外的小views。
例如对于ImageNet数据集,如下的代码中:
- nmb_crops = [2, 6]表示两个标准随机裁剪和六个小views;
- size_crops = [224, 96]表示标准RandomResizedCrop后得到的尺寸为 224 ∗ 224 224*224 224∗224,小views经过RandomResizedCrop后得到的尺寸为 96 ∗ 96 96*96 96∗96;
- min_scale_crops = [0.14, 0.05], max_scale_crops = [1.00, 0.14]表示小views在RandomResizedCrop时的尺度为(0.05, 0.14), 标准RandomResizedCrop时的尺度为(0.14, 1.00)。
color_transform = [get_color_distortion(), RandomGaussianBlur()]
if pil_blur:
color_transform = [get_color_distortion(), PILRandomGaussianBlur()]
mean = [0.485, 0.456, 0.406]
std = [0.228, 0.224, 0.225]
trans = []
for i in range(len(size_crops)):
randomresizedcrop = transforms.RandomResizedCrop(
size_crops[i],
scale=(min_scale_crops[i], max_scale_crops[i]),
)
trans.extend([transforms.Compose([
randomresizedcrop,
transforms.RandomHorizontalFlip(p=0.5),
transforms.Compose(color_transform),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)])
] * nmb_crops[i])
self.trans = trans
SwAV进一步拉近了自监督学习方法和有监督学习的距离,离有监督学习的准确率只差1.2%。这里的SwAV在大的batch(4096)上训练了800个epochs。最终两种方法的结合带来了4.2个点的提升:
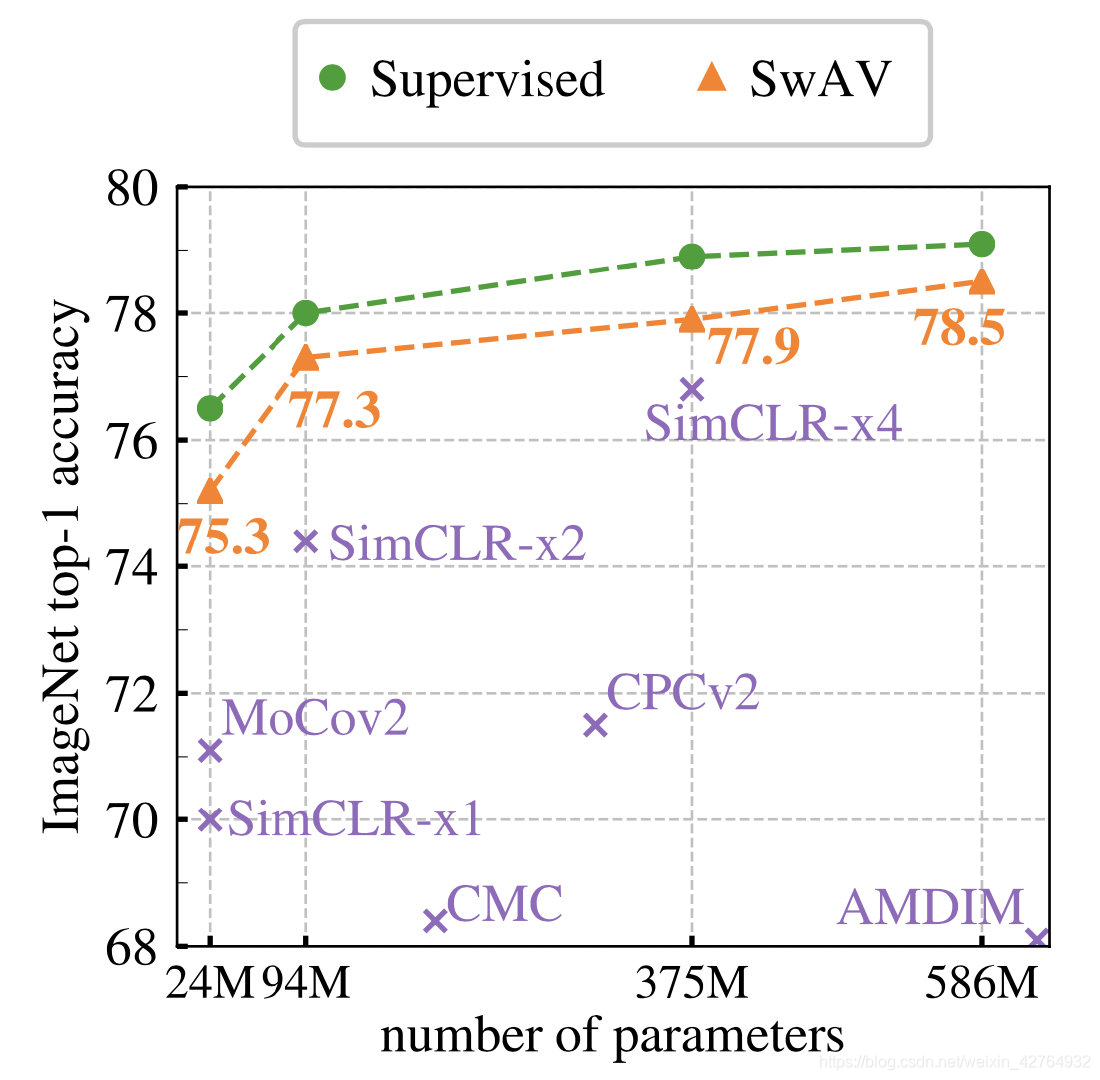
比较不同自监督学习方法在batch_size = 256时的表现,SwAV仍然是效果最SOTA的。
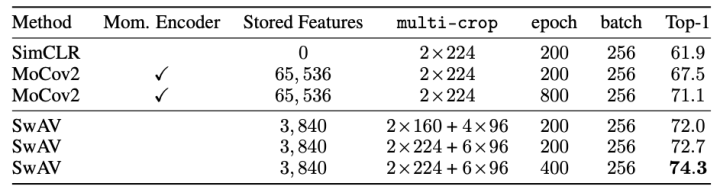
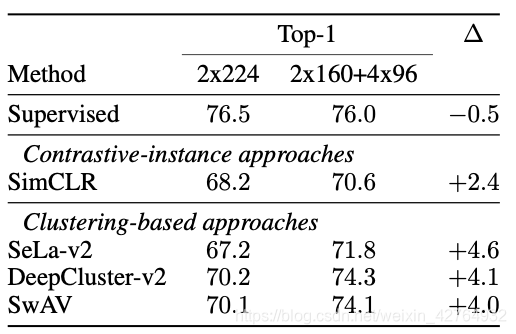
Multi-crop的作用
如下图所示,对于自监督学习方法来说,2160+496的Multi-crop策略总是比2*224的增广效果好。

















 28
28

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









