







监督学习
监督学习的存在它的弊端,例如对我们人类还无法分辨和归类的事物,监督学习就无法完成,所以为了弥补这个缺陷,下面我们看一下新非监督学习,它可以让计算机学会进行更加复杂的分类。
分析过程
监督学习的构建一般由三个部分组成,数据的预处理,神经网络的搭建,然后进行训练测试,训练测试生成数据集和模型,最后倒入已知数据,让计算机对我们输入的数据进行分类。
项目案例:
猫狗识别
知识点:
1、数据的预处理
2、搭建神经网络
3、模型的训练与储存
项目分步分析:
第一步:创建六个文件夹
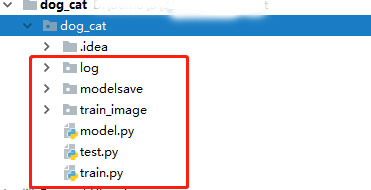
1、log文件夹,用于存放丢失数据和数据误差
2、modelsave文件夹用于存放训练好的模型
3、train_image文件夹用于,存放猫狗的图片,这些图片是作为训练模型的数据
4、train.py 用于进行数据的预处理和模型的搭建
5、model.py 搭建神经网络
6、test.py 测试搭建好的模型,用于猫狗识别
第二步:train_image文件内容
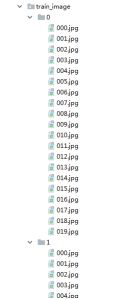
在train_image文件夹中穿件名为0的文件夹,用于存放猫的图片(数据),然后创建名为1的文件夹,用于存放狗的数据。
创建好0和1的文件之后,分别放入 猫和狗的图片。
第三步:train.py 文件第一部分的内容,对数据进行预处理,数据的预处理分为连个步骤,第一步是获取数据并生成标签集,第二不是将数据进行分批处理。
#导入tensorflow
import tensorflow as tf
#创建函数获取train_image中的文件,生成标签集合
def get_files(file_path):
#两个文件,一个是用于存放图片路径,一个是用于对图片标记
class_train = []
label_train = []
#根据路径将图片遍历出来
for train_class in os.listdir(file_path):
#pic_name is the train image name
for pic_name in os.listdir(file_path + train_class):
#添加入前面创建好的列表当中
class_train.append(file_path + train_class + '/' + pic_name)
#train_class is 0,1,2,3,4....
label_train.append(train_class)
#将trainimage和trainlabel合并到二维数组(2,n)
temp = np.array([class_train, label_train])
#进行数据降维
temp = temp.transpose()
np.random.shuffle(temp)
#获取降维后的数据
image_list = list(temp[:,0])
label_list = list(temp[:,1])
label_list = [int(i) for i in label_list]
return image_list, label_list
def get_batches(image, label, resize_w, resize_h, batch_size, capacity):
#用TensorFlow进行数据字符的提取
image = tf.cast(image, tf.string)
#用TensorFlow进行特殊字符的标记,为64位
label = tf.cast(label, tf.int64)
#让图片和标记形成队列
queue = tf.train.slice_input_producer([image, label])
label = queue[1]
image_temp = tf.read_file(queue[0])
image = tf.image.decode_jpeg(image_temp, channels = 3)
#宠幸标记图片型号
image = tf.image.resize_image_with_crop_or_pad(image, resize_w, resize_h)
image = tf.image.per_image_standardization(image)
image_batch, label_batch = tf.train.batch([image, label], batch_size = batch_size,
num_threads = 64,
capacity = capacity)
images_batch = tf.cast(image_batch, tf.float32)
labels_batch = tf. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









