







本文是参考 FCN网络结构详解(语义分割)_哔哩哔哩_bilibili
自己做的笔记,理解还不到位,有错误的地方请各位大佬指正。

首个端对端的全卷积网络(语义分割领域,,,是否是全领域的首个端对端就不知道了)
地位相当于目标检测中的Faster RCNN

效果不错,MIOU提高 ,推理时间减少。

将全连接层的权重转换到卷积层,这样就解决了:图像的大小需要固定这个问题。

比如下面的这个 224X224 的图片最后变成了 7X7的才能进入全连接层,
但是换成了卷积层就不用担心因为形状不匹配报错了

将全连接层换成卷积层,发现参数是一样多的。

backbone会让图片下采样32倍,如果输入图片是32X32的,还没有跑完这个backbone这个网络就报错了。
如果FC6 那里输入进来的图片是小于7的,就会报错,因为图片的尺寸已经小于卷积核的大小了。
所以在进入FC6前会![]() 加一个padding =100
加一个padding =100
后面接一个conv2d和一个转置卷积(convTranspose2d)采用双线性插值的方法来的。卷积核的个数是种类的个数。
ps:转置卷积用于上采样,不是卷积的逆运算,不能得到原来的数据,只是可以把尺寸变成原来的大小。

FCN16不是直接恢复成原尺度大小,而是利用了类似残差结构的东西(我瞎编的)
先恢复成原图的16分之一,再变成原图的大小。

如图:Maxpool3 下采样8倍
Maxpool4 下采样16倍
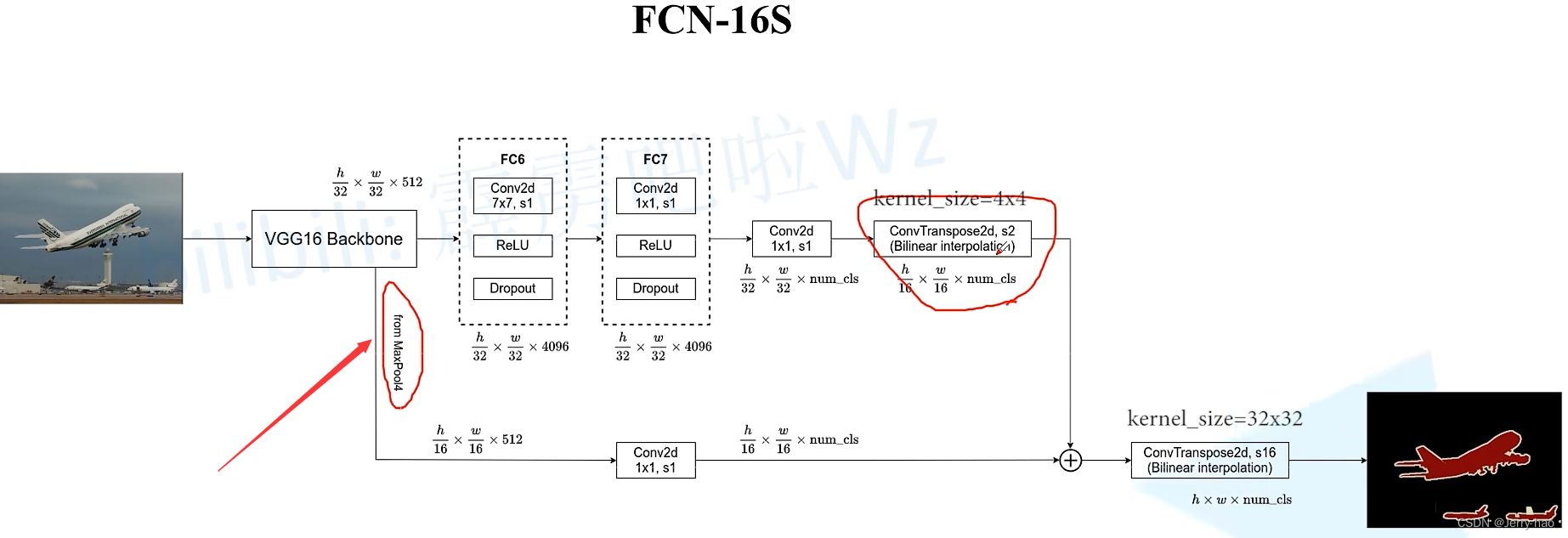
上图箭头就是maxpool4中输出的

上图的MP3 为maxpool3,mp4为maxpool4。
文章是2015年的,那个时候的backbone可选择的不多,现在pytorch官方实现的backbone采用的是ResNet。














 29万+
29万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









