






经常看到类似下面的代码
for i,(images,target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images)
loss = criterion(outputs,target)
# 2. backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step() 这三条经常一起出现:梯度清零,反向传播求梯度,更新参数
# 2. backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step() 很多资料说梯度不清零会累加,我一开始想的是:求出新梯度不就直接赋值给变量(覆盖原来变量的值吗?)怎么会累加呢?
然后我做了个实验验证了一下:
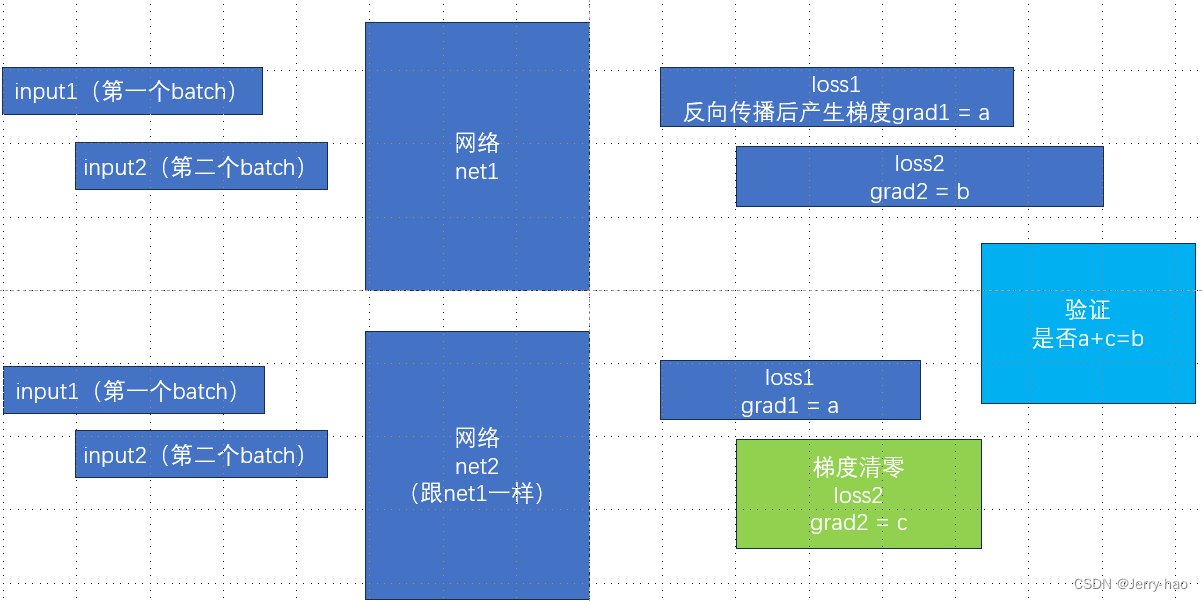
代码如下:
import torch
import torch.nn as nn
import copy
# 创建网络
net1 = nn.Linear(10, 1)
net2 = copy.deepcopy(net1)
# 创建优化器
optimizer1 = torch.optim.SGD(net1.parameters(), lr=0.01)
optimizer2 = torch.optim.SGD(net2.parameters(), lr=0.01)
# 定义输入
inputs1 = [-0.4507, 1.5306, 1.6414, -1.4976, -0.4955, 0.8670, 1.7535, 0.6661, -1.1307, 0.6601]
inputs1 = torch.Tensor(inputs1)
# print("1---inputs1",inputs1)
inputs2 = [-0.7951, 1.0476, 0.3908, 1.0368, -0.4870, 0.2596, 0.2631, 0.6549, -0.9619, -0.1810]
inputs2 = torch.Tensor(inputs2)
# print("1---inputs2",inputs2)
#定义标签
targets = [-0.4159]
targets = torch.Tensor(targets)
# print("1---targets",targets)
#网络1的第一个batch
outputs1 = net1(inputs1)
print("网络的第一次输出",outputs1)
print("网络第一次计算损失前的梯度",net1.weight.grad)
# 计算损失1
loss1_1 = torch.nn.functional.mse_loss(outputs1, targets)
print("网络的第一次损失值",loss1_1)
print("网络第一次计算损失后,反向传播前的梯度",net1.weight.grad)
# 反向传播1
loss1_1.backward() #反向传播后才产生梯度
# 打印参数的梯度
print("网络第一次反向传播后的梯度",net1.weight.grad)
optimizer1.step() #更新参数
#网络1的第二个batch
outputs2 = net1(inputs2)
print("网络的第二次输出",outputs2)
print("网络第二次计算损失前的梯度",net1.weight.grad)
# 计算损失2
loss1_2 = torch.nn.functional.mse_loss(outputs2, targets)
print("网络第二次损失",loss1_2)
print("网络第二次计算损失后,反向传播前的梯度",net1.weight.grad)
# 反向传播2
loss1_2.backward()
# 打印参数的梯度
print("网络1第二次反向传播后的梯度",net1.weight.grad)
optimizer1.step()
#第二个网络 batch1
outputs1 = net2(inputs1)
print("网络的第一次输出",outputs1)
print("网络第一次计算损失前的梯度",net2.weight.grad)
#计算损失
loss2_1 = torch.nn.functional.mse_loss(outputs1, targets)
print("网络第一次损失",loss2_1)
print("网络第一次计算损失后,反向传播前的梯度",net2.weight.grad)
# 反向传播1
optimizer2.zero_grad() # 清零梯度
loss2_1.backward()
# 打印参数的梯度
print("网络2第一次反向传播后的梯度",net2.weight.grad)
optimizer2.step() # 更新参数
# batch2
outputs2 = net2(inputs2)
print("网络2的第二次输出",outputs2)
print("网络2第二次计算损失前的梯度",net2.weight.grad)
loss2_2 = torch.nn.functional.mse_loss(outputs2, targets)
print("网络第二次损失",loss2_2)
print("网络第二次计算损失后,反向传播前的梯度",net2.weight.grad)
# 反向传播2
optimizer2.zero_grad() # 清零梯度
loss2_2.backward()
# 打印参数的梯度
print("网络2第二次反向传播后的梯度",net2.weight.grad)
optimizer2.step() # 更新参数
"""
D:\Anaconda\envs\pytch-gpu-38\python.exe E:\pycharm-project\niuke\back_ward_2.py
网络的第一次输出 tensor([0.2260], grad_fn=<AddBackward0>)
网络第一次计算损失前的梯度 None
网络的第一次损失值 tensor(0.4120, grad_fn=<MseLossBackward>)
网络第一次计算损失后,反向传播前的梯度 None
网络第一次反向传播后的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
网络的第二次输出 tensor([-0.5868], grad_fn=<AddBackward0>)
网络第二次计算损失前的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
网络第二次损失 tensor(0.0292, grad_fn=<MseLossBackward>)
网络第二次计算损失后,反向传播前的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
网络1第二次反向传播后的梯度 tensor([[-0.3069, 1.6070, 1.9736, -2.2769, -0.4697, 1.0243, 2.1612, 0.6313, -1.1229, 0.9093]])
网络的第一次输出 tensor([0.2260], grad_fn=<AddBackward0>)
网络第一次计算损失前的梯度 None
网络第一次损失 tensor(0.4120, grad_fn=<MseLossBackward>)
网络第一次计算损失后,反向传播前的梯度 None
网络2第一次反向传播后的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
网络2的第二次输出 tensor([-0.5868], grad_fn=<AddBackward0>)
网络2第二次计算损失前的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
网络第二次损失 tensor(0.0292, grad_fn=<MseLossBackward>)
网络第二次计算损失后,反向传播前的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
网络2第二次反向传播后的梯度 tensor([[ 0.2717, -0.3580, -0.1335, -0.3543, 0.1664, -0.0887, -0.0899, -0.2238, 0.3287, 0.0619]])
Process finished with exit code 0
"""
把有用的结果拿出来分析一下:
"""
# a
网络第一次反向传播后的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
# b
网络1第二次反向传播后的梯度 tensor([[-0.3069, 1.6070, 1.9736, -2.2769, -0.4697, 1.0243, 2.1612, 0.6313, -1.1229, 0.9093]])
# a
网络2第一次反向传播后的梯度 tensor([[-0.5786, 1.9649, 2.1072, -1.9226, -0.6361, 1.1130, 2.2511, 0.8551, -1.4516, 0.8474]])
# c
网络2第二次反向传播后的梯度 tensor([[ 0.2717, -0.3580, -0.1335, -0.3543, 0.1664, -0.0887, -0.0899, -0.2238, 0.3287, 0.0619]])
"""
然后需要验证一下是否 a+c = b
然后
-0.5786 + 0.2717 = -0.3069 (yes)
1.9649 - 0.3580 = 1.6069 (1.6070 不太严谨的分析是浮点数计算的小误差,或者是小数点后面很多位计算完后的四舍五入)
2.1072 - 0.1335 = 1.9737 (1.9736 , 这个结果有点蚌埠住了,暂时忽略吧)
基本上是满足 a+c=b的
....................
总之验证了 梯度不清零就是会累加的
学了这个博客:
PyTorch中梯度为什么默认自动累加,在反向传播前要手动将梯度清零?_为什么backward()要将梯度归零-CSDN博客
渐渐懂了为什么要累加梯度了。
简单解释:
辣鸡显卡显存小,一个batch不能太大,那么累加梯度的话,就可以看作是显存小的显卡也完成了“一次性处理一个大的batch”的任务。
假如,一个batch 是 8,4个batch中间不清零,可以看作大batch为32。
我们极限一点,所有的batch都不清零,也就是整个数据集是一个大batch,
那么这样的好处是,辣鸡显卡也能一次处理多条数据的任务,batch size越大训练效果越好,梯度累加则实现了batchsize的变相扩大。
坏处是容易对这个训练集的数据过拟合,也就是这个训练集上表现很好,但是泛化性差了一些。
总结:
梯度不清零:逻辑上等价于处理batch size较大的数据,训练网络的结果好,但泛化性差一点
梯度清零:处理的是batch size 较小的数据,泛化性好。
如果有错误,请及时指正。
又是钻牛角尖折磨自己的一天! /(ㄒoㄒ)/~~
参考博客:















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









