







AttentionLight: Rethinking queue length and attention mechanism for traffic signal control
文章目录
摘要
本文重新设计了车辆队列长度和注意力机制:
- 提出一种TSC方法,Max-QL作为状态特征;
- 提出一种通用TSC范式QL-XLight,将队列长度作为状态和奖励;
- 提出一种基于QL-XLight的强化学习方法AttentionLight,利用自注意力机制来获得相位关系,而不需要人为的相位竞争知识。
在真实数据集上进行了测试,结果显示:
- M-QL方法效果好于最新的强化学习方法;
- AttentionLight实现了新的SOTA;
- 状态表示对TSC方法很重要。
引言
最新的MPLight、MetaLight都基于FRAP模型,但是FRAP模型需要人工设计相位关系,如在四相位和八相位条件下的完全竞争、部分竞争、无竞争。在四相位、八相位条件下,相位关系较好设计,但对于更复杂的的交叉路口或相位设计(如五交叉路口)会很困难并且耗费时间。为了解决这个问题,提出了AttentionLight,
综上,TSC的主要挑战是:
- 难以确定最为有效的状态表示;
- 难以对更复杂的相位以及交叉路口构建相位关系;
本文的主要贡献是:
- 重新设计了队列长度并作为状态表示;
- 提出了优化后的TSC方法:M-QL;
- 提出了QL-XLight,其将队列长度作为状态和奖励,并且以此构建了两种强化学习方法:QL-DQN和QL-GAT;
- 提出了新的强化学习模型AttentionLight,使用自注意力机制学习相位关系。
概念基础
**相位队列长度:**每个相位的队列长度是指各相位进口车道的队列长度和。
q
(
d
)
=
∑
q
(
l
)
,
l
∈
d
q(d)=\sum q(l),l\in d
q(d)=∑q(l),l∈d
**交叉路口队列长度:**每个交叉路口的队列长度是指交叉路口中进口车道的总长度。
**相位持续时间:**指相位的最小持续时间。
方法
基于队列长度的TSC方法
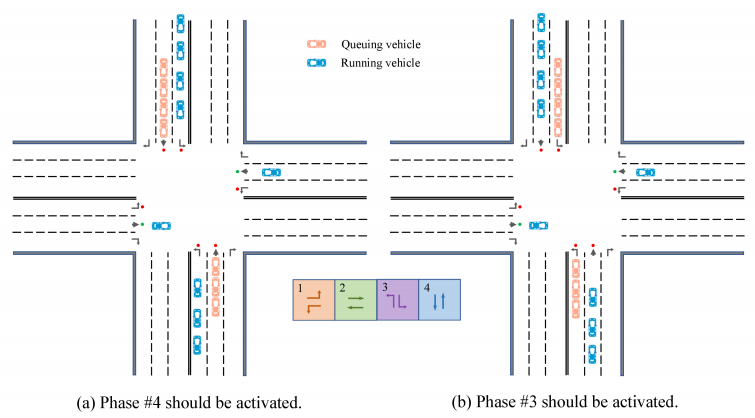
交通网络中车辆有两种状态:移动状态、排队状态。排队状态的车辆会直接造成拥堵。如图,车辆数量相同,但(a)应启动相位4,(b)应启动相位3。

M-QL控制:与MaxPressure类似,选择队列长度最长的:
d
^
=
a
r
g
m
a
x
(
q
(
d
)
∣
d
∈
D
i
)
\hat{d}=argmax(q(d)|d\in \mathcal{D}_i)
d^=argmax(q(d)∣d∈Di)
QL-XLight
将队列长度作为状态和奖励,获得了QL-XLight、QL-DQN和QL-GAT。其中QL-XLight是一个模板,可以替换使用的深度学习模型。
QL-XLight算法如下:

DQN Agent
- DQN:两层全连接层;
- GAT:类似于CoLight;
状态、动作、奖励设计:
- 状态:当前相位、进口车道的队列长度,写作 s t s_t st;
- 动作:Agent选择的动作;
- 奖励:交叉路口队列长度的负数:
r i = − ∑ q ( l ) , l ∈ L i i n r_i=-\sum q(l),l\in\mathcal{L}^{in}_i ri=−∑q(l),l∈Liin
采用贝尔曼公式进行更新。
实现参数共享、Replay共享。GAT不需要参数共享,因为所有Agent协作获得Q值。
基于自注意力的相位关系方法
AttentionLight使用自注意力机制学习相位关系并且通过自注意力机制构建的相位特征来预测各个相位迭代Q值。各个相位的Q值需要考虑彼此之间的关系。
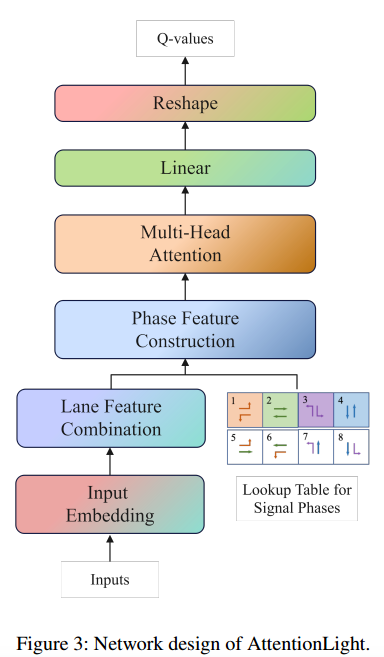
Q值预测分为三个阶段:
- 构建相位特征
- 利用多头注意力机制学习相位关系
- 预测Q值
构建相位特征
AttentionLight的输入状态包括信号相位表示(batch, 8)和交通状态特征,即队列长度(batch, 12)。
- (组合车道特征)输入嵌入:将特征转换到高维,然后将同一车道的特征串联组合,得到每个进口车道的特征表示;
- (组合两个车道,成为相位)阶段特征建设:每个相位特征通过对应车道特征的特征融合来构建,特征融合可以直接相加或加权相加,或由网络学习。
最后,获得每个相位特征表示,四相位为(batch, 4, dims),八相位为(batch, 8, dims)
利用多头注意力机制学习相位关系
将相位特征作为输入,并使用自关注来学习相位相关性。通过自注意力机制学习各阶段的相关性,并根据各阶段的相关性构建新的阶段特征。
预测Q值
将四相位(batch, 4, dims)或八相位(batch, 8, dims)特征作为输入,获得每个相位的Q值。3个全连接层得到(batch, n, 1),n为相位,再通过1个Reshape层得(batch, n)得到q值。















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









