







SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
原文链接:https://arxiv.org/abs/2404.09502
1. 引言
目前的3D密集体素表达效率较低,而BEV表达则损失了信息。三视图(TPV)表达可以减少信息损失,但其感知性能仍然不高。
本文使用3D稀疏表达,在不损失信息的情况下提高效率。本文的方法为SparseOcc,其关键设计包括:
- 稀疏隐式扩散器:将非空体素的特征扩散到周围空体素,以进行场景补全;其中3D扩散核被分解为三个正交核的组合。
- 稀疏特征金字塔:通过稀疏插值操作组成特征金字塔,以使用其余尺度的信息增强当前尺度。这样可以扩展感受野,减少各尺度的扩散器数量,从而保持稀疏性。
- 稀疏Transformer头:仅分割被占用的体素,生成语义占用预测。
实验表明,本文方法的时空效率均比密集表达或TPV表达高,而性能也更优,因为稀疏表达能避免空体素上的幻觉。
3. 方法
3.1 准备知识:场景表达
给定环视图像 I = { I i } i = 1 N v i e w I=\{I_i\}_{i=1}^{N_{view}} I={Ii}i=1Nview,基于视觉的3D语义占用预测的目标是为预定义3D体素预测语义标签 { 0 , 1 , ⋯ , C } H × W × D \{0,1,\cdots,C\}^{H\times W\times D} {0,1,⋯,C}H×W×D,其中类别标签0表示空体素, C C C为非空体素的类别数。
本文使用LSS的方法,使用图像编码器得到2D透视平面上的图像特征,并使用预测深度图提升到3D空间,得到密集体素特征 V ∈ R H × W × D × C V\in\mathbb R^{H\times W\times D\times C} V∈RH×W×D×C(其中,80%的体素为空体素)。
通过收集非空体素,将
V
V
V转化为稀疏表达,以坐标方式存储稀疏张量:
V
=
{
(
p
i
=
[
x
i
,
y
i
,
z
i
]
∈
R
3
,
f
i
∈
R
C
)
∣
i
=
1
,
2
,
⋯
,
N
}
\mathbb V=\{(p_i=[x_i,y_i,z_i]\in\mathbb R^3,f_i\in\mathbb R^C)|i=1,2,\cdots,N\}
V={(pi=[xi,yi,zi]∈R3,fi∈RC)∣i=1,2,⋯,N}
其中
N
N
N为非空体素数,
p
i
p_i
pi与
f
i
f_i
fi分别为第
i
i
i个体素的坐标和特征。后续操作均基于稀疏操作块组成,结构图如图所示。
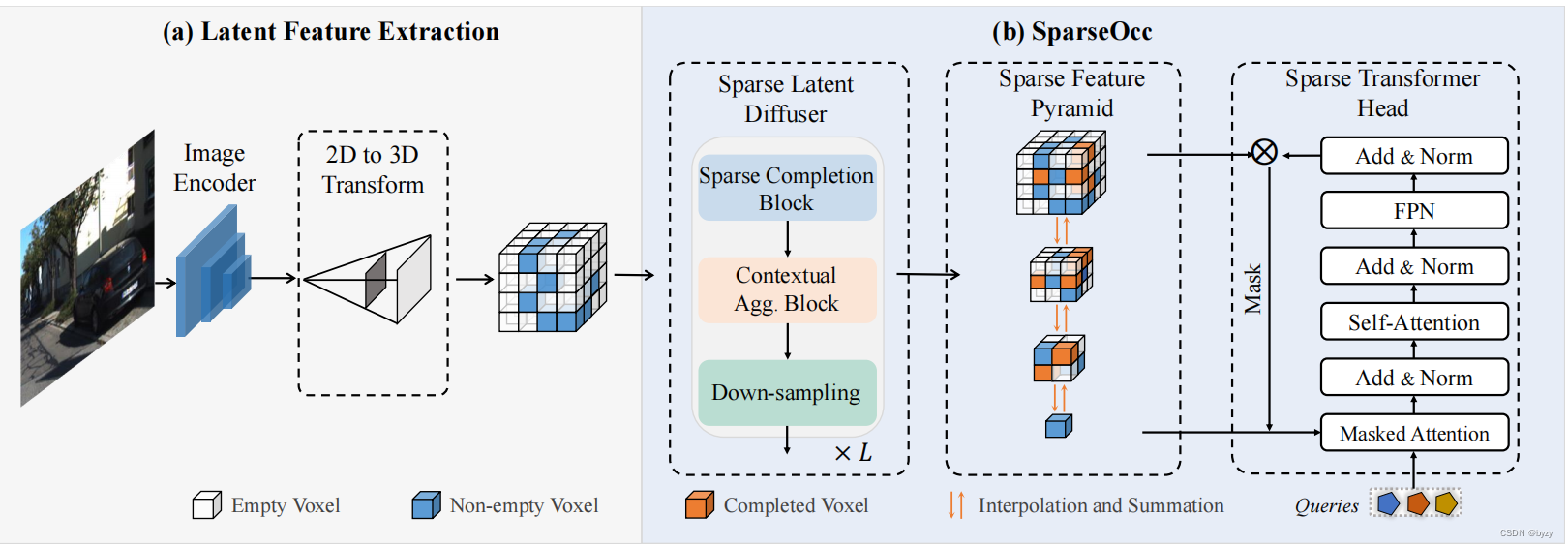
3.2 稀疏隐式扩散器
稀疏表达 V \mathbb V V是通过射线投射方式得到的,因此大部分观测是不完整的。传统方法使用3D密集卷积或注意力层扩散非空特征到相邻空区域,以补全场景。场景补全的目标与稀疏设计冲突:场景补全后的稀疏性下降,会影响效率。本文使用稀疏隐式扩散器,平衡场景完整性和稀疏性,包含两部分:稀疏补全块(仅进行必要的隐式扩散)和上下文聚合块(在不接触补全的情况下聚合有效特征)。
稀疏补全块:基于3D稀疏卷积建立,将非空体素的特征扩散到邻域体素,其扩散范围可通过堆叠3D稀疏卷积增大。本文的稀疏补全块仅使用1个3D卷积。
上下文聚合块:从局部上下文聚合语义和几何特征,使用稀疏子流形卷积,仅在输入的非空位置处输出特征,从而多层堆叠不会影响稀疏性。
核分解:为利用不同的形状分布(如路面是平坦的,需要进行水平扩散;而建筑或车辆是矩形的,需要进行垂直扩散),本文将传统的
k
×
k
×
k
k\times k\times k
k×k×k的核分解为正交核。具体来说,在稀疏补全块中,稀疏卷积被分解为
k
×
k
×
1
,
k
×
1
×
k
,
1
×
k
×
k
k\times k\times 1,k\times 1\times k,1\times k\times k
k×k×1,k×1×k,1×k×k的核。在上下文聚合块中,将稀疏子流形卷积替换为并行且不对称的分解层组成的分支,如图所示。分解后的复杂度由
O
(
k
3
)
O(k^3)
O(k3)变为
O
(
3
k
2
)
O(3k^2)
O(3k2)或
O
(
4
k
2
)
O(4k^2)
O(4k2),仅管在
k
=
3
k=3
k=3时没有减小实际计算,但其更大的容量使其性能更优,从而可用更少的层数实现高效率。

3.3 稀疏特征金字塔
实现场景补全的方法是堆叠多个稀疏扩散器以保证大型物体或静态元素的识别,但会导致计算量增大。本文使用多尺度系数特征金字塔,实现粗糙到精细的场景表达。具体来说,本文堆叠 L L L层稀疏扩散器,每层后跟下采样,得到特征金字塔 { V l } l = 1 L \{\mathbb V_l\}_{l=1}^L {Vl}l=1L(最后几层的空间高度尺寸为1,对应稀疏补全块的核为 3 × 3 3\times 3 3×3的2D核、上下文聚合块的核为2个并行的 5 × 5 5\times5 5×5核)。
稀疏体素解码器:为减小时空消耗,本文未使用多尺度可变形注意力进行尺度内和尺度间的特征交互,而是使用插值来融合多尺度稀疏特征。给定
V
l
\mathbb V_l
Vl,按下式聚合其余尺度的特征:
V
^
l
=
∑
j
≠
l
W
j
⋅
Interp
(
V
j
,
V
l
)
\hat {\mathbb V}_l=\sum_{j\neq l}W_j\cdot\text{Interp}(\mathbb V_j,\mathbb V_l)
V^l=j=l∑Wj⋅Interp(Vj,Vl)
其中 W j W_j Wj为可学习权重, Interp ( X , Y ) \text{Interp}(\mathbb X,\mathbb Y) Interp(X,Y)表示 X \mathbb X X到 Y \mathbb Y Y的线性插值。
这样,低分辨率特征本身的密集性可以抵抗插值的稀释,高分辨率的特征可获得来自低分辨率特征的补全。
3.4 稀疏Transformer头
本文参考Mask2Former,使用可学习查询,通过掩膜注意力更新,并解码为各类别的3D掩膜。注意到仅需要对非空体素进行精确分割,本文使用稀疏的Transformer头。
预处理和标记法:给定稀疏特征金字塔,首先使用线性二元分类器进行粗糙分割,得到非空体素与空体素。记非空体素组成的特征为 V ^ l = { ( p i , f i ) ∣ i = 1 , ⋯ , N l } \hat{\mathbb V}_l=\{(p_i,f_i)|i=1,\cdots,N_l\} V^l={(pi,fi)∣i=1,⋯,Nl},其中 N l N_l Nl为预测的非空体素数。本文使用单一的可学习token p ϕ p_\phi pϕ表达所有空体素。
查询解码:OccFormer使用查询 Q ∈ R N q × C Q\in\mathbb R^{N_q\times C} Q∈RNq×C与3D密集特征 F ∈ R C × H × W × D F\in\mathbb R^{C\times H\times W\times D} F∈RC×H×W×D的外积来将查询解码为大小为 ( N q , H , W , D ) (N_q,H,W,D) (Nq,H,W,D)的3D掩膜,其时间复杂度为 O ( N q H W D C ) O(N_qHWDC) O(NqHWDC)。本文使用 Q Q Q与 p ϕ ∪ { f i ∣ ( p i , f i ) ∈ V ^ l } p_\phi\cup\{f_i|(p_i,f_i)\in\hat{\mathbb V}_l\} pϕ∪{fi∣(pi,fi)∈V^l}的外积得到占用掩膜 M o c c ∈ R N q × N l M^{occ}\in\mathbb R^{N_q\times N_l} Mocc∈RNq×Nl和表达空体素的掩膜 M ϕ ∈ R N q × 1 M^\phi\in\mathbb R^{N_q\times1} Mϕ∈RNq×1。根据占用体素的坐标 p p p,可重建密集3D掩膜 M ∈ R N q × H × W × D M\in\mathbb R^{N_q\times H\times W\times D} M∈RNq×H×W×D。这样,本文的掩膜预测和重建的复杂度为 O ( N l N q C + H W D ) O(N_lN_qC+HWD) O(NlNqC+HWD),低于OccFormer。此外, N q N_q Nq个查询也被送入线性分类器得到对应的类别。
查询更新:给定
l
−
1
l-1
l−1层的预测3D掩膜
M
l
−
1
M_{l-1}
Ml−1,使用下式更新查询
Q
l
=
softmax
[
M
l
−
1
+
W
q
Q
l
−
1
(
W
k
V
^
l
)
T
]
W
v
V
^
l
+
Q
l
−
1
Q_l=\text{softmax}[\mathcal M_{l-1}+W_qQ_{l-1}(W_k\hat V_l)^T]W_v\hat V_l+Q_{l-1}
Ql=softmax[Ml−1+WqQl−1(WkV^l)T]WvV^l+Ql−1
其中
W
q
,
W
k
,
W
v
W_q,W_k,W_v
Wq,Wk,Wv为线性层,
V
^
l
\hat V_l
V^l为由
V
^
l
\hat{\mathbb V}_l
V^l重建的密集特征,
M
l
−
1
(
x
,
y
,
z
)
=
{
0
若
σ
(
M
l
−
1
′
(
x
,
y
,
z
)
)
≥
0.5
−
∞
否则
\mathcal M_{l-1}(x,y,z)=\begin{cases}0&若\sigma(M'_{l-1}(x,y,z))\geq 0.5\\-\infin &否则\end{cases}
Ml−1(x,y,z)={0−∞若σ(Ml−1′(x,y,z))≥0.5否则
其中 σ \sigma σ为sigmoid函数, M l − 1 ′ = maxpool ( M l − 1 ) M'_{l-1}=\text{maxpool}(M_{l-1}) Ml−1′=maxpool(Ml−1)(分辨率与 V ^ l \hat V_l V^l相同)。
3.5 目标函数
由于稀疏Transformer将语义占用作为掩膜预测任务,需要使用匈牙利算法进行预测语义标签和真值的二部匹配。基于分配结果,计算掩膜损失和分类损失。此外,使用深度损失监督LSS的深度估计。非空体素的粗糙二元分类使用分割损失。
4. 实验
4.1 实验设置
实施细节:训练时,采样若干点进行监督;推断时,将预测掩膜通过三线性插值进行上采样,达到与真值同样的分辨率。
4.2 基准性能
实验表明,本文方法能达到密集表达方法相当或更高的性能水平,能大幅超越TPV表达方法的性能,且有更少的计算量。
4.4 消融研究
稀疏补全块:实验表明,即便没有稀疏补全块,本文方法的性能也能达到满意水平。这可能是因为融合特征金字塔的解码器也能在一定程度上补全场景。与 3 × 3 × 3 3\times3\times3 3×3×3核相比,分解的正交核有更高的场景补全和分割性能。增加更多的卷积块不会提高性能。
稀疏特征金字塔:使用多尺度可变形注意力替换本文的稀疏解码器后,需要多层堆叠才能达到更高的性能,且计算量和空间消耗更高;FPN3D有相当的计算量,但其性能更低。
稀疏Transformer头:使用线性头、OccFormer的Transformer头和本文的稀疏Transformer头,发现线性头的几何占用预测性能最优,这是因为其直接受到显式的几何监督;而Transformer解码器将占用预测视为逐类的掩膜生成,没有显式的监督。因此,本文使用线性头进行粗糙的占用分割,使用稀疏Transformer解码器进行掩膜预测,以平衡两类占用头的优势。
输入图像大小:本文方法即使在低分辨率图像输入和小容量主干下也能达到比C-CONet更高的性能。使用更高的图像分辨率能提高语义特征的密度,从而提高语义占用预测性能。但几何占用预测性能会下降,因为过度密集的3D稀疏特征会在空体素上产生幻觉。当去除最后一层稀疏扩散器的稀疏补全块后,该幻觉会被减轻。
















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











