







 文章汇总了2D激光雷达和3D激光雷达在行人检测和追踪以及多目标跟踪中的研究,包括使用点云数据的滤波和分类算法,以及结合社交信息的预测模型。同时,讨论了图像传感器与雷达数据融合在多传感器跟踪系统中的应用,强调了实时性和鲁棒性的重要性。文章还提到了一些开源项目和算法,如DeepSORT、ByteTrack等,它们在提高跟踪性能和处理遮挡问题上表现出色。
文章汇总了2D激光雷达和3D激光雷达在行人检测和追踪以及多目标跟踪中的研究,包括使用点云数据的滤波和分类算法,以及结合社交信息的预测模型。同时,讨论了图像传感器与雷达数据融合在多传感器跟踪系统中的应用,强调了实时性和鲁棒性的重要性。文章还提到了一些开源项目和算法,如DeepSORT、ByteTrack等,它们在提高跟踪性能和处理遮挡问题上表现出色。
文章目录
- 人体姿态
-
- DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion
- Self-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos(重要)
- Simple Baselines for Human Pose Estimation and Tracking
- AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
- training-free
- 重识别
-
- FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
- RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation(2021)
- Online multi-object tracking using multi-function integration and tracking simulation training(2021)
- MeMOT: Multi-Object Tracking with Memory(2021)
- TransTrack: Multiple Object Tracking with Transformer(2021)
- Rethinking the Competition between Detection and ReID in Multi-Object Tracking
- One-Shot Multiple Object Tracking in UAV Videos Using Task-Specific Fine-Grained Features(2022)
- ReidTrack: Reid-only Multi-target Multi-camera Tracking(2023)
- Multi-Object Tracking by Self-supervised Learning Appearance Model(2023)
- 光照
-
- Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
- All-Day Object Tracking for Unmanned Aerial Vehicle
- A Cross-Scale and Illumination Invariance-Based Model for Robust Object Detection in Traffic Surveillance Scenarios
- A vision-based method for automatic tracking of construction machines at nighttime based on deep learning illumination enhancement(重要)
- Object tracking on event cameras with offline–online learning
- Fusion-based simultaneous estimation of reflectance and illumination for low-light image enhancement
- 避障
- 跟踪器
- 2d激光雷达
- 图像
-
- 2010
- 2015
- 2017
- 2018
- 2019
- 2020
- 2021
- 2022
- 2023
-
- Segment and Track Anything
- Track Anything: Segment Anything Meets Videos
- SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation
- Tracking Anything with Decoupled Video Segmentation
- JRDB-Pose: A Large-scale Dataset for Multi-Person Pose Estimation and Tracking
- Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking
- 3D lidar
- 多传感器融合
-
- 2020
- 2021
-
- CFTrack: Center-based Radar and Camera Fusion for 3D Multi-Object Tracking(重要)
- Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving
- Robust Detection and Tracking Method for Moving Object Based on Radar and Camera Data Fusion
- EagerMOT: 3D Multi-Object Tracking via Sensor Fusion
- DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
- Distributed Multi-Object Tracking Under Limited Field of View Sensors
- 2022
-
- MSA-MOT Multi-Stage Association for 3D Multimodality Multi-Object Tracking
- FUTR3D: A Unified Sensor Fusion Framework for 3D Detection
- Robust Multiobject Tracking Using Mmwave Radar-Camera Sensor Fusion
- CAMO-MOT: Combined Appearance-Motion Optimization for 3D Multi-Object Tracking with Camera-LiDAR Fusion
- DeepFusionMOT: A 3D Multi-Object Tracking Framework Based on Camera-LiDAR Fusion with Deep Association
- 2023
-
- Adaptive multi-object tracking based on sensors fusion with confidence updating
- Real time object detection using LiDAR and camera fusion for autonomous driving
- DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
- Multi-Modal Sensor Fusion and Object Tracking for Autonomous Racing(重要)
- StrongFusionMOT: A Multi-Object Tracking Method Based on LiDAR-Camera Fusion
- 2024
- 机器人开源项目
- 其他介绍
- 参考
人体姿态
DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion
code: https://paperswithcode.com/paper/dancetrack-multi-object-tracking-in-uniform
摘要: 多对象跟踪(MOT)的一个典型流程是使用检测器进行对象定位,然后使用再识别(re-ID)进行对象关联。这个管道的部分动机是由于最近在对象检测和re-ID方面的进展,部分动机是由于现有跟踪数据集的偏差,其中大多数对象倾向于有区别的外观,而re-ID模型足以建立关联。为了应对这种偏差,我们想再次强调的是,当物体外观不够区分时,多物体跟踪的方法也应该起作用。为此,我们提出了一个用于多人类跟踪的大规模数据集,其中人类有相似的外观,不同的运动和极端的关节。由于该数据集主要包含团体舞蹈视频,我们将其命名为“舞蹈轨迹”。我们希望舞蹈跟踪能提供一个更好的平台来开发更多的MOT算法,更少地依赖于视觉辨别,更多地依赖于运动分析。我们在数据集上对几个最先进的跟踪器进行基准测试,与现有基准测试相比,舞蹈跟踪上的性能显著下降。

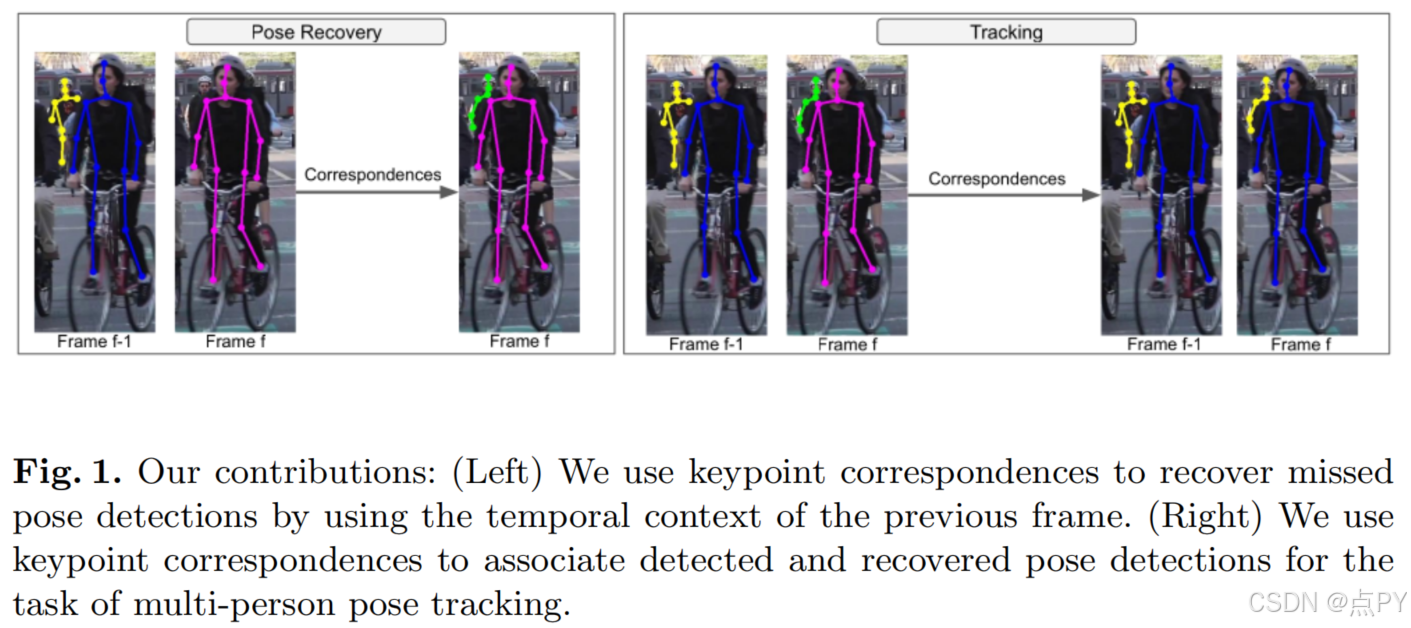
Self-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos(重要)
code: https://github.com/andoer/posetrack21
摘要: 视频注释既昂贵又耗时。因此,与用于人体姿态估计的大规模图像数据集相比,用于多人姿态估计和跟踪的数据集多样化较少,稀疏标注较多。这使得学习基于深度学习的模型具有挑战性,用于关联不同帧之间的关键点,这些关键点对多人姿态跟踪任务中的运动模糊和遮挡等有害因素具有鲁棒性。为了解决这个问题,我们提出了一种依赖于关键点对应的方法来关联视频中的人。它不是训练网络来估计视频数据上的关键点对应,而是在一个大规模的图像数据集上进行训练,使用自我监督进行人体姿态估计。结合人体姿态估计的自顶向下框架,我们使用关键点对应于(i)恢复错过的姿态检测和(ii)关联跨视频帧的姿态检测。我们的方法在PoseTrack 2017年和2018年的数据集上实现了多帧姿态估计和多人姿态跟踪的最新结果。

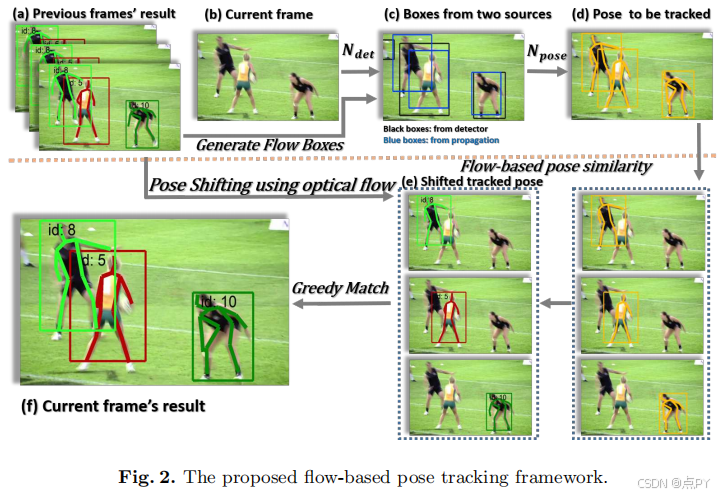
Simple Baselines for Human Pose Estimation and Tracking
code: https://github.com/Microsoft/human-pose-estimation.pytorch
摘要: 近年来,在姿态估计方面取得了显著进展,对姿态跟踪的兴趣越来越大。同时,整体算法和系统复杂度也增加,使得算法的分析和比较更加困难。这项工作提供了简单和有效的基线方法。它们有助于激励和评估该领域的新想法。在具有挑战性的基准上取得了最先进的结果。
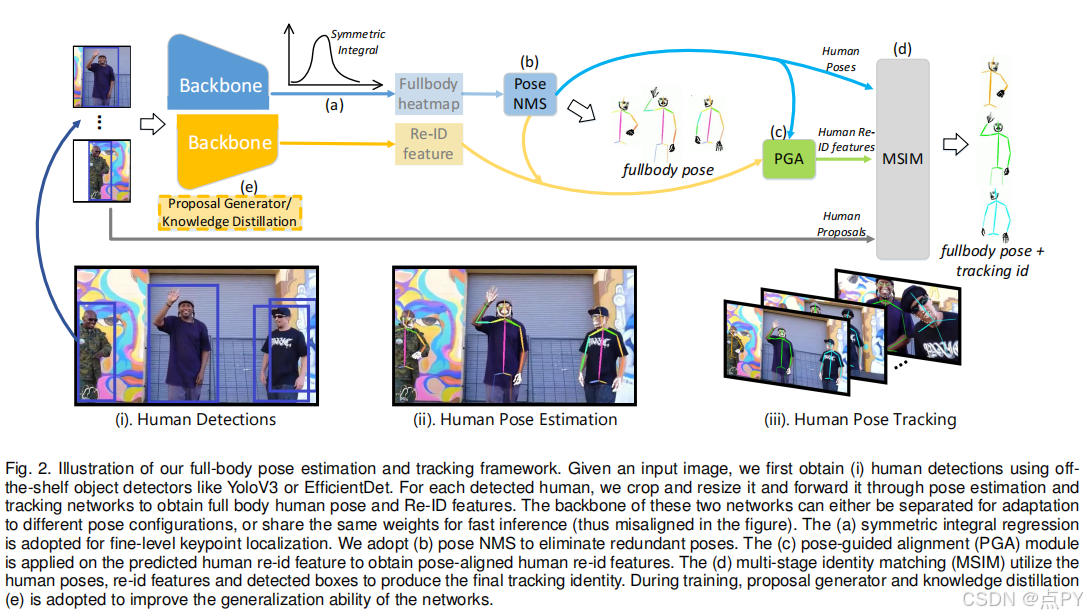
AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
code: https://paperswithcode.com/paper/alphapose-whole-body-regional-multi-person
摘要: 准确的全身多人姿态估计和跟踪是计算机视觉中一个重要但具有挑战性的课题。为了在复杂的行为分析中捕捉人类的微妙行为,包括脸、身体、手和脚在内的全身姿势估计比传统的纯身体姿势估计是必不可少的。在本文中,我们提出了一个可以在实时运行的同时联合进行精确的全身姿态估计和跟踪的系统。为此,我们提出了几种新的技术:用于快速和精细定位的对称积分关键点回归(SIKR)、用于消除冗余人工检测的参数姿态非最大抑制(P-NMS)和用于联合姿态估计和跟踪的姿态感知身份嵌入。在训练过程中,我们采用部分引导建议生成器(PGPG)和多领域知识蒸馏来进一步提高精度。我们的方法能够准确地定位全身的关键点,并同时跟踪人类给定不准确的边界盒和冗余的检测。我们在COCO-全身、COCO、PoseTrack和我们提出的Halpe-全身姿态估计数据集上显示了在速度和精度方面比目前最先进的方法有了显著的改进。
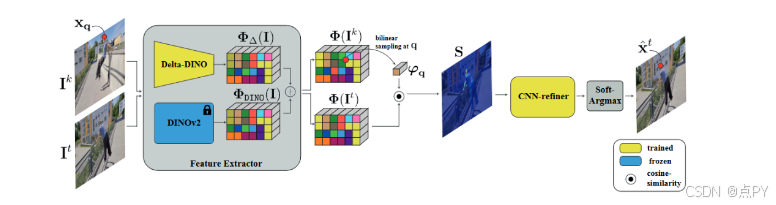
training-free
DINO-Tracker: Taming DINO for Self-Supervised Point Tracking in a Single Video
code: https://github.com/AssafSinger94/dino-tracker
近年来,在视频中建立密集点对应关系这一研究取得了巨大进展。在短期的密集运动估计方面,比如光流估计,研究界的关注焦点是监督学习——设计强大的前馈模型,并在各种合成数据集上进行训练,利用精确的监督信息。最近,这一趋势扩展到了视频中的长期点跟踪领域。随着新架构(如Transformers)和提供长期轨迹监督的新合成数据集的出现,各种监督跟踪器被开发出来,展示了令人印象深刻的成果。
然而,精准的跟踪视频中每一个运动点对此类基于监督学习的方法而言是一个极大的挑战:
首先,用于点跟踪的合成数据集通常包含在不现实配置中的移动物体,相对于自然视频中运动和物体的广泛分布,这些数据集在多样性和规模上受到限制;
此外,现有模型在跨越整个视频时空范围内聚合信息的能力仍然有限——这一点在长时间遮挡(例如在物体被遮挡之前和之后正确匹配一个点)中尤其重要。
为了应对这些挑战,Omnimotion(也就是23年的Tracking Everything)提出了一种测试的优化框架,通过预计算的光流和视频重建作为监督,将跟踪提升到3D层面。这种方法通过优化给定测试视频上的跟踪器,本质上一次性解决了所有视频像素的运动问题。然而,Omnimotion存在一个致命缺点:它严重依赖预计算的光流和单个视频中的信息,没有利用关于视觉世界的外部知识和先验。
在本文中,作者提出了一种新方法,训练与大量数据的学习结合起来,取长补短,形成一个针对特定视频特征提取匹配再到追踪优化框架,该框架结合由广泛的无标签图像训练的外部图像模型学习到的强大特征表示。受到最近自监督学习巨大进展的启发,作者的框架利用了预训练的DINOv2模型——一个使用大量自然图像进行预训练的视觉Transformers。DINO的特征提取已经被证明能够捕捉细粒度的语义信息,并被用于各种视觉任务,如分割和语义对应。
本项工作是首次将基于DINO提取的特征用于密集跟踪的研究。 作者展示了使用原始DINO特征匹配可以作为一个强大的跟踪baseline,但这些特征本身不足以支持亚像素精度的跟踪。因此,作者的框架同时调整DINO的特征以适应测试视频中的运动观察,同时训练一个直接利用这些精炼特征的跟踪器。为此,作者设计了一个新的目标函数,通过在精炼特征空间中培养稳健的语义特征级别对应关系,超越了光流监督实现的效果。

重识别
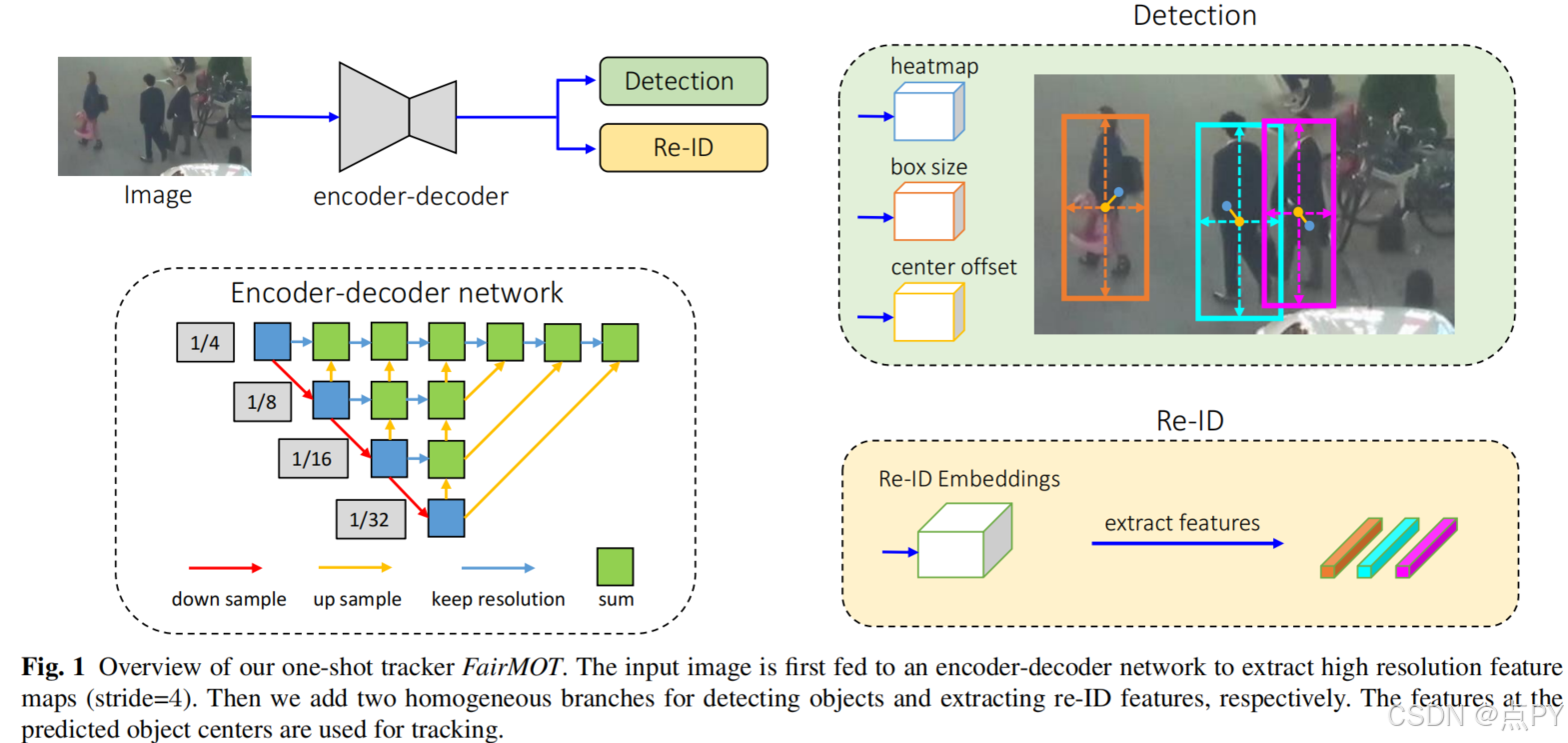
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
code: https://github.com/ifzhang/FairMOT
摘要: 多目标跟踪(MOT)是计算机视觉中的一个重要问题,具有广泛的应用前景。将MOT表示为单个网络中目标检测和reid的多任务学习,因为它允许两个任务的联合优化,并且具有较高的计算效率。然而,我们发现这两个任务倾向于相互竞争,这需要仔细处理。特别是,以往的工作通常将re-ID视为次要任务,其准确性受到主要检测任务的严重影响。因此,网络偏向于主检测任务,这对re-ID任务不公平。为了解决这个问题,我们提出了一种基于无锚定目标检测架构centet网络的简单而有效的方法,称为FairMOT。请注意,它并不是CenterNet和re-ID的幼稚组合。相反,我们提出了一堆详细的设计,这些设计对于通过彻底的实证研究获得良好的跟踪结果至关重要。该方法对检测和跟踪都具有较高的精度。该方法在几个公共数据集上的性能大大优于最先进的方法。
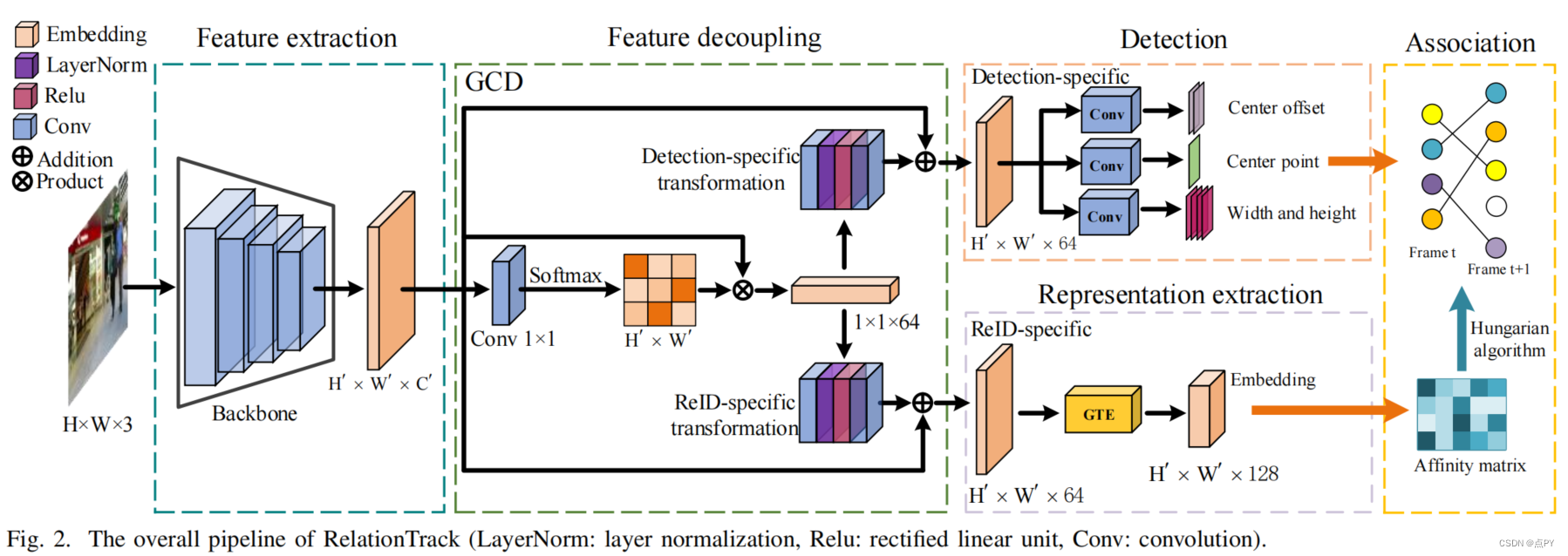
RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation(2021)
摘要: 现有的在线多目标跟踪(MOT)算法通常包括两个子任务,检测和再识别(ReID)。为了提高推理速度和降低复杂性,目前的方法通常将这些双子任务集成到一个统一的框架中。然而,检测和ReID需要不同的特性。这一问题会导致训练过程中的优化矛盾。为了缓解这一矛盾,我们设计了一个名为全局上下文解纠缠(GCD)的模块,该模块将学习到的表示解耦为检测特定和reid特定的嵌入。因此,该模块提供了一种隐式的方式来平衡这两个子任务的不同需求。此外,我们观察到,之前的MOT方法通常利用局部信息来关联检测到的目标,而忽略了考虑全局语义关系。为了解决这一限制,我们开发了一个模块,称为引导Transformer编码器(GTE),通过结合变压器编码器强大的推理能力和可变形注意。与之前的工作不同,GTE避免了分析所有的像素,只关注捕获查询节点和一些自适应选择的关键样本之间的关系。因此,它的计算效率很高。在MOT16、MOT17和MOT20基准上进行了广泛的实验,以证明所提出的MOT框架的优越性,即关系跟踪。实验结果表明,关系track显著超过了以往的方法,建立了新的性能,如MOT20的IDF1为70.5%,MOTA为67.2%。
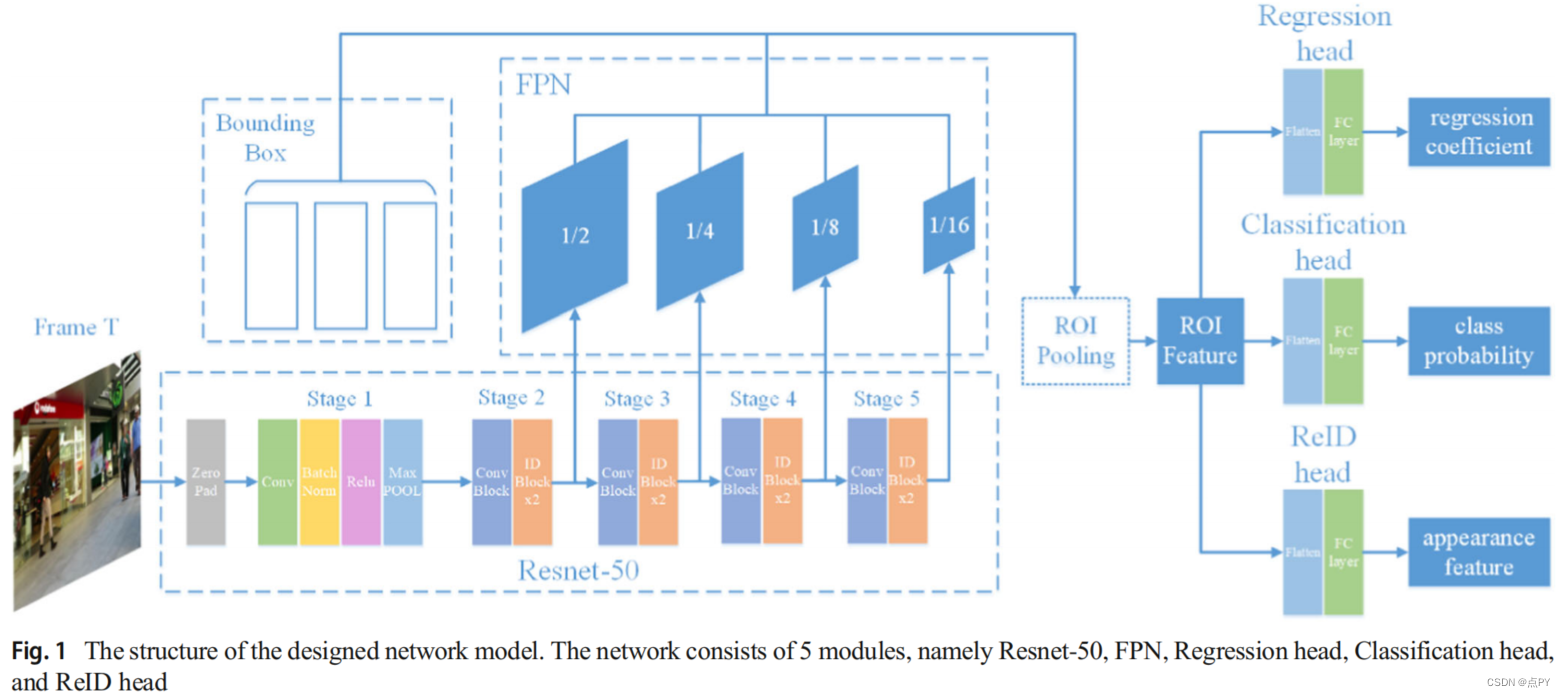
Online multi-object tracking using multi-function integration and tracking simulation training(2021)
摘要: 近年来,随着深度学习的发展,基于深度神经网络的多目标跟踪算法的性能得到了极大提高。然而,大多数方法将不同的功能模块分离成多个网络,并在特定的任务上独立地训练它们。当这些网络模块被直接使用时,它们之间不能有效地兼容,也不能更好地适应多目标跟踪任务,从而导致跟踪效果较差。因此,设计了一种网络结构,将帧间对象的回归和外观特征的提取聚合成一个模型,以提高多目标跟踪的各种功能模块之间的和谐性。为了提高对多目标跟踪任务的支持度,还提出了一种端到端训练方法来模拟训练过程中的多目标跟踪过程,并利用目标的历史位置结合运动模型的预测来扩展训练数据。利用目标的历史外观特征的度量损失对外观特征提取模块进行训练,以提高提取的外观特征的时间相关性。对MOTThasty基准数据集的评价结果表明,该方法达到了最先进的性能。
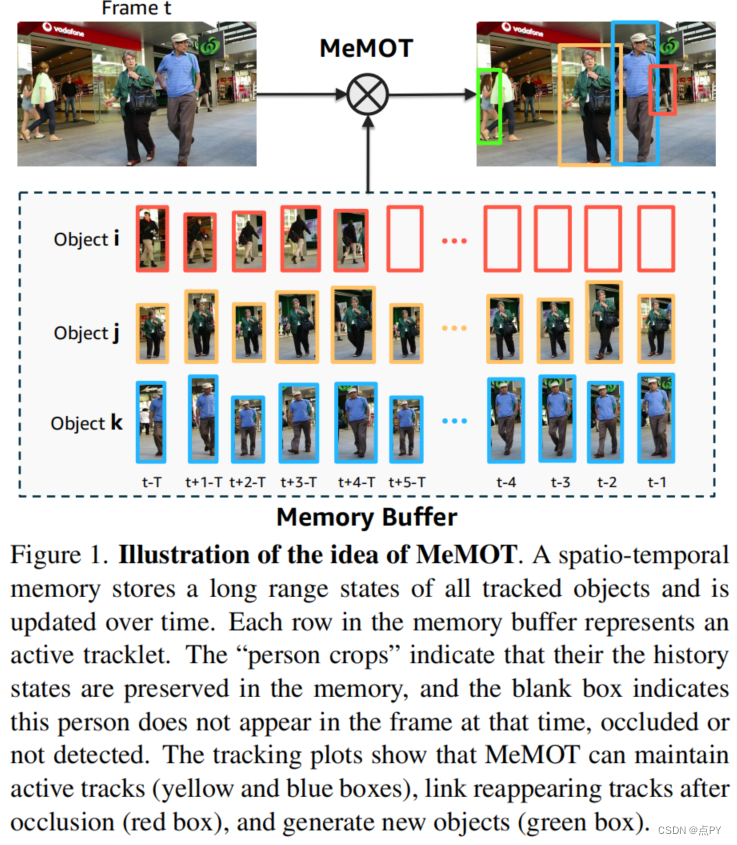
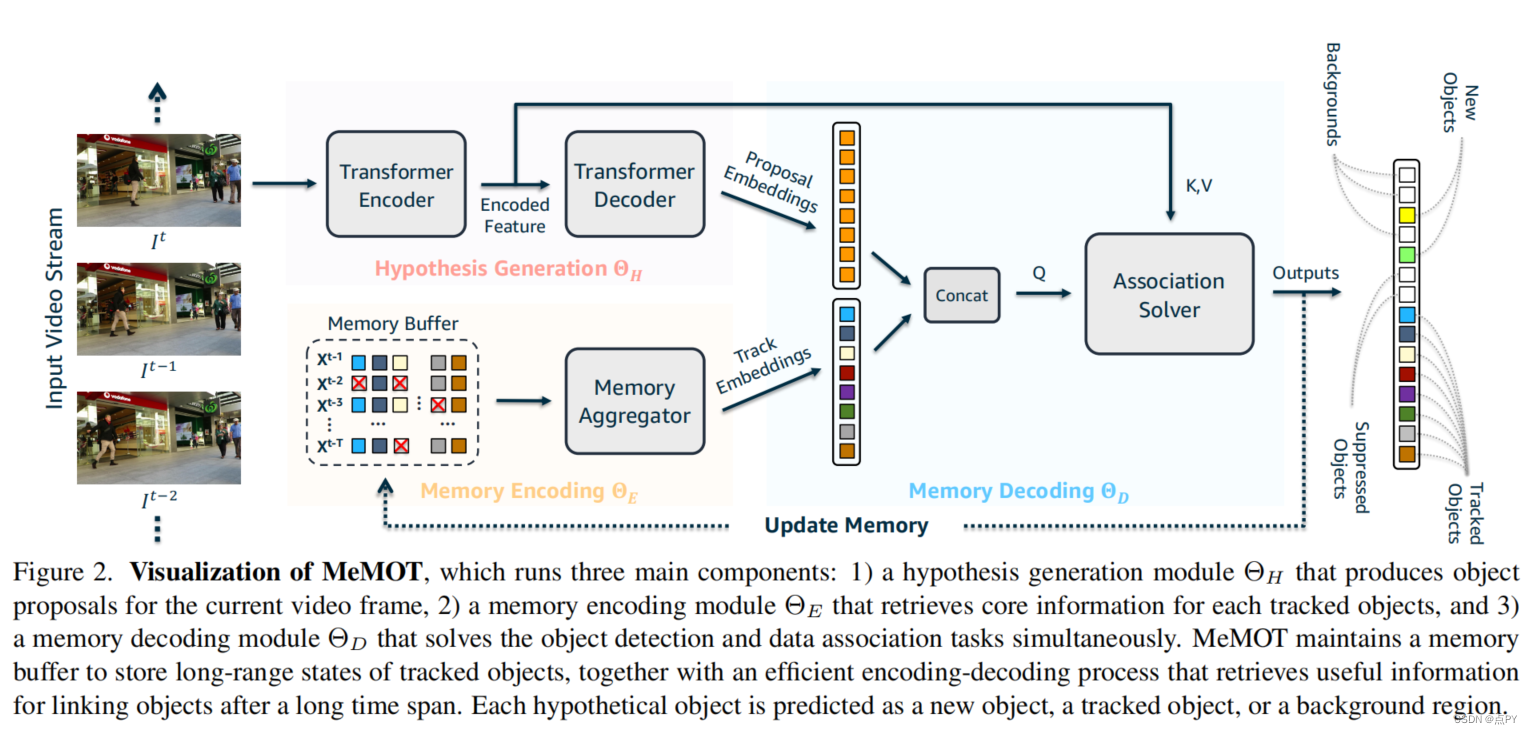
MeMOT: Multi-Object Tracking with Memory(2021)
摘要: 我们提出了一种在线跟踪算法,在一个公共框架下执行对象检测和数据关联,能够在长时间跨度后链接对象。这是通过保留一个大的时空内存来存储被跟踪对象的身份嵌入,并通过根据需要自适应地引用和聚合内存中的有用信息来实现的。我们的模型称为MeMOT,由三个主要模块组成,它们都是基于变压器的: 1)假设生成,在当前视频帧中生成目标建议;2)内存编码,从每个被跟踪对象的内存中提取核心信息;3)内存解码,同时解决目标检测和数据关联任务,进行多目标跟踪。
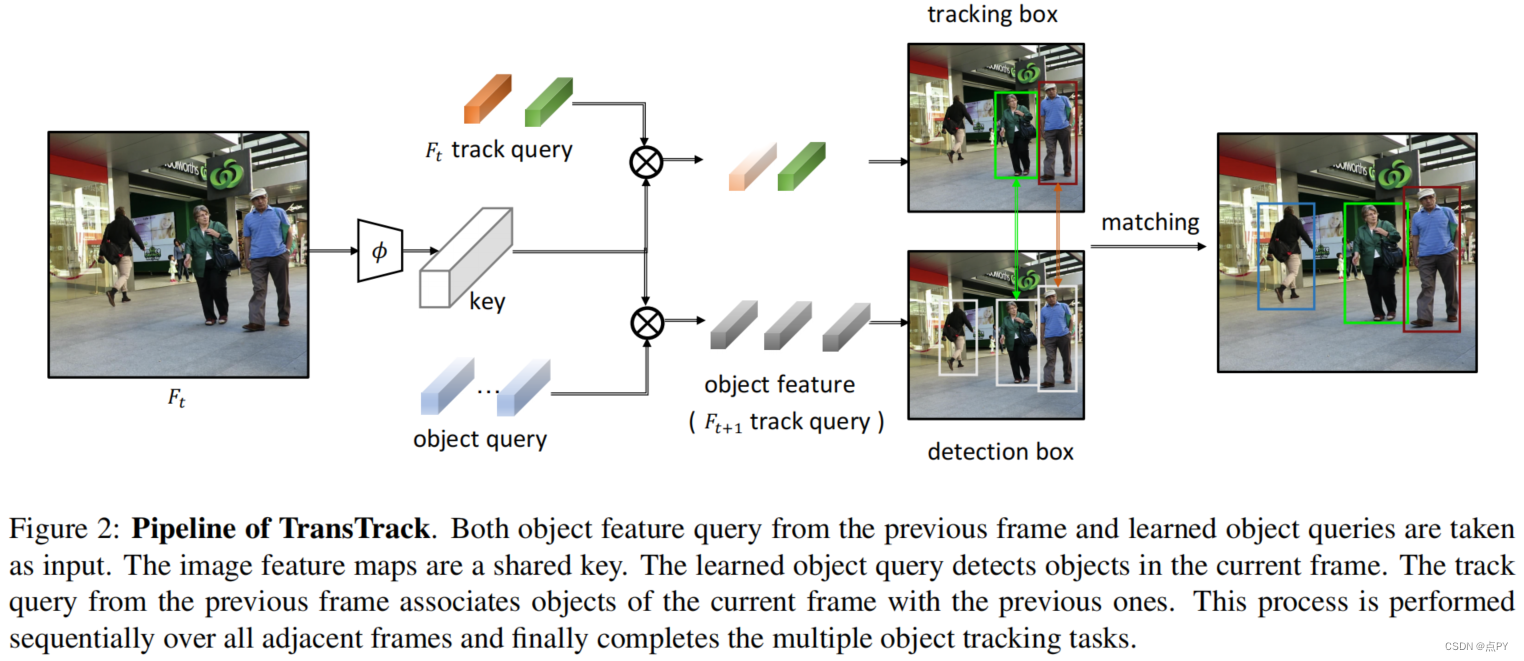
TransTrack: Multiple Object Tracking with Transformer(2021)
code: https://github.com/PeizeSun/TransTrack
摘要: 在这项工作中,我们提出了一个简单但有效的方案来解决多目标跟踪问题。TransTrack利用了Transformer架构,这是一种基于注意力的查询键机制。它应用了来自前一帧的对象特征作为对当前帧的查询,并引入了一组已学习到的对象查询,以支持检测新的即将到来的对象。通过在单镜头中完成目标检测和目标关联,简化了复杂的检测跟踪方法中的多步骤设置,建立了一种新的联合检测和跟踪范式。在MOT17和MOT20基准上,TransTrack分别达到了74.5%和64.5%的MOTA,与最先进的方法竞争。我们期望跨跟踪为多目标跟踪提供一个新的视角。
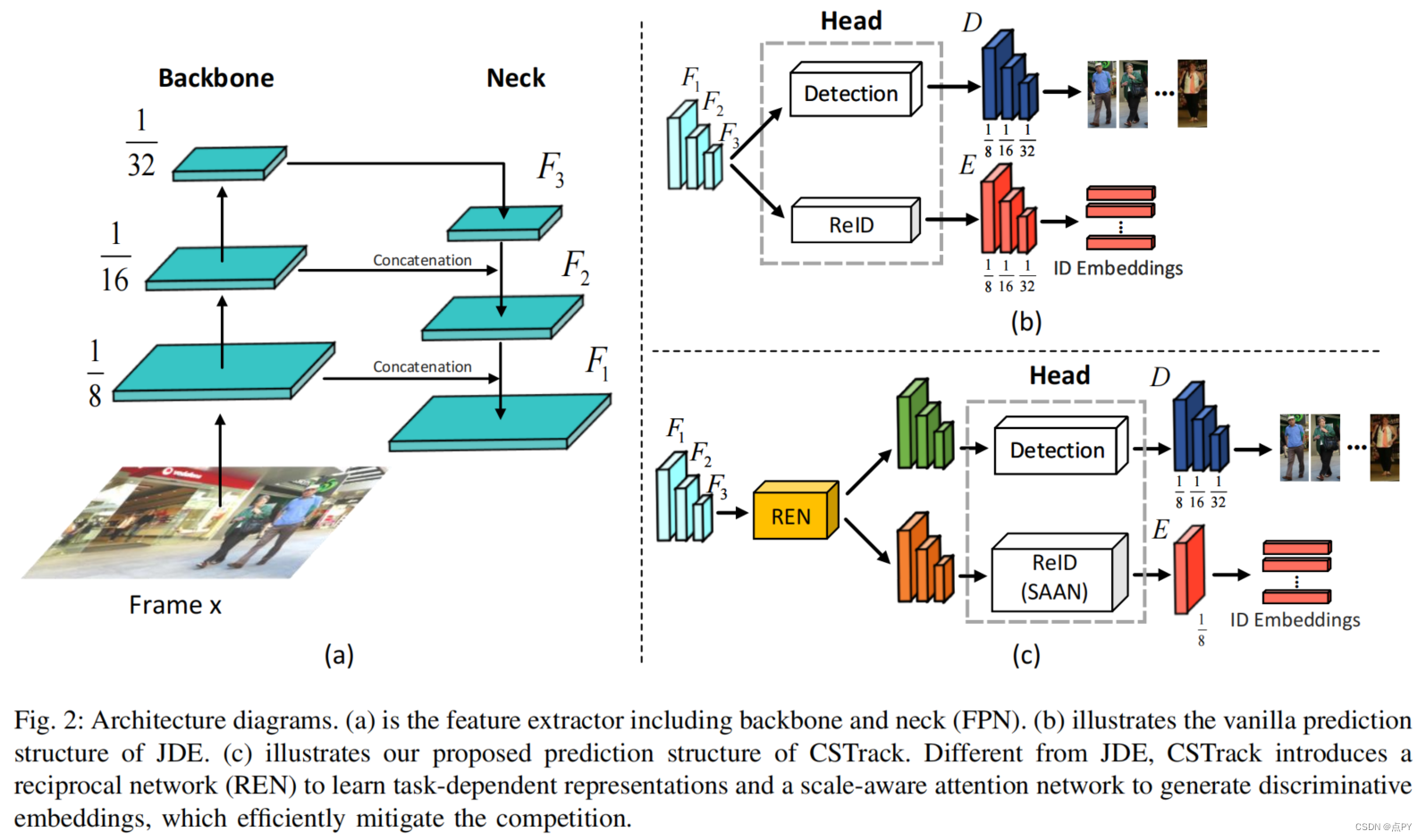
Rethinking the Competition between Detection and ReID in Multi-Object Tracking
摘要: 由于精度和速度的平衡,一次性模型联合学习检测和识别嵌入,在多目标跟踪(MOT)中引起了广泛的关注。然而,检测和再识别(ReID)之间的内在差异和关系被无意识地忽略了,因为它们在一次性跟踪范式中被视为两个孤立的任务。与现有的两阶段方法相比,这导致了性能较差的方法。在本文中,我们首先剖析了这两个任务的推理过程,发现它们之间的竞争不可避免地会破坏任务依赖的表征学习。为了解决这一问题,我们提出了一种新的具有自关系和交叉关系设计的互易网络(REN),以促使每个分支更好地学习依赖于任务的表示。该模型旨在缓解有害任务竞争,同时提高检测与ReID之间的协作性。此外,我们还引入了一种尺度感知注意网络(SAAN),可以防止语义级错位,以提高ID嵌入的关联能力。通过将这两个精心设计的网络集成到一个一次性的在线MOT系统中,我们构建了一个强大的MOT跟踪器,即CSTrack。我们的跟踪器在MOT16、MOT17和MOT20数据集上实现了最先进的性能,没有其他的附加功能。此外,CSTrack是高效的,在一个现代GPU上的运行速度为16.4 FPS,而它的轻量级版本的运行速度甚至为34.6 FPS。
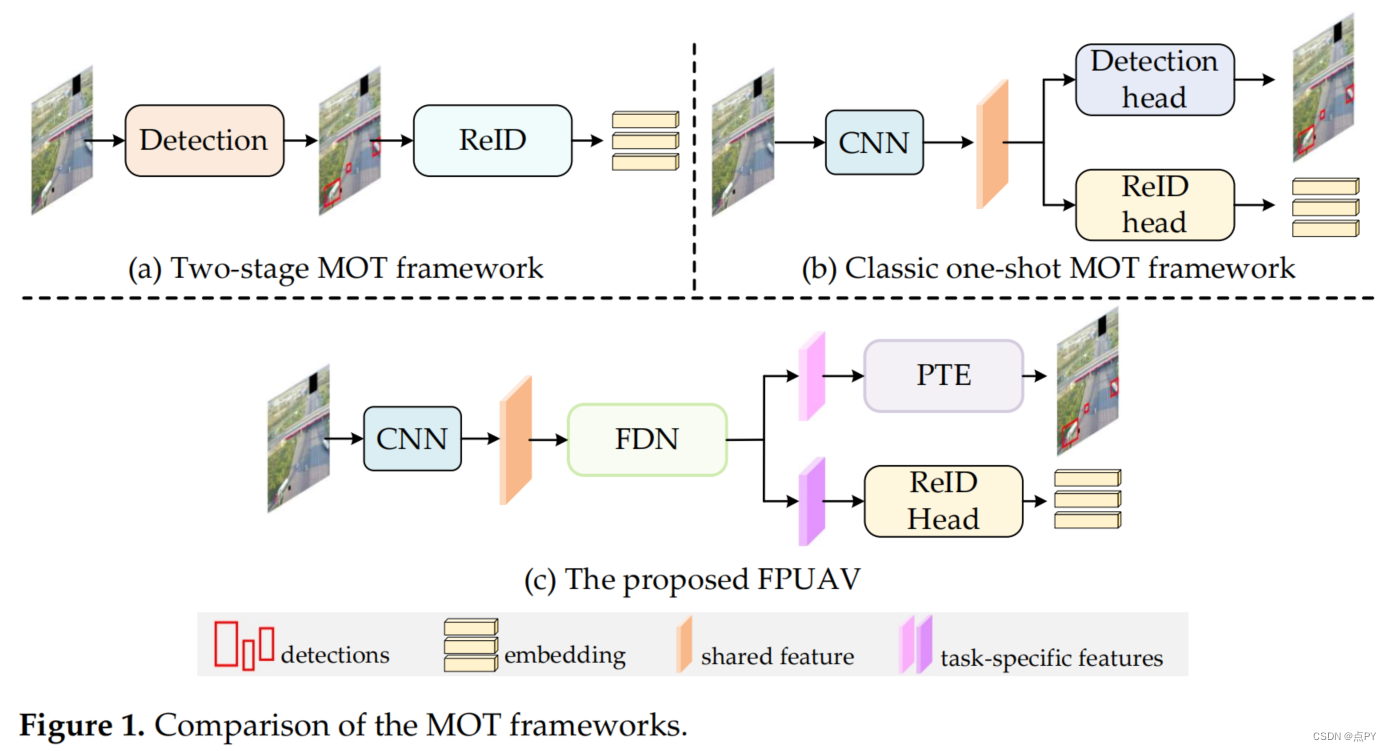
One-Shot Multiple Object Tracking in UAV Videos Using Task-Specific Fine-Grained Features(2022)
摘要: 无人机(UAV)视频中的多目标跟踪(MOT)是一项基本任务,可应用于许多领域。MOT包括两个关键的程序,即目标检测和再识别(ReID)。一次性MOT将检测和ReID集成到一个统一的网络中,由于其快速的推理速度而受到人们的关注。它通过使两个子任务共享特性,显著地降低了计算开销。然而,大多数现有的一次性跟踪器都难以在无人机视频中实现鲁棒跟踪。我们观察到,检测和ReID之间的本质差异导致了一次性网络中的优化矛盾。为了缓解这一矛盾,我们提出了一种新的特征解耦网络(FDN),将共享特征转换为检测特异性和reid特异性表示。FDN搜索这两个任务之间的特征和共性,以协同检测和ReID。此外,现有的一次性跟踪器很难在无人机视频中定位小目标。因此,我们设计了一个金字塔转换器编码器(PTE)来丰富由此产生的检测特定表示的语义信息。通过学习尺度感知的细粒度特征,PTE使我们的跟踪器能够准确地定位无人机视频中的目标。在VisDrone2021和UAVDT基准测试上进行的大量实验表明,我们的跟踪器实现了最先进的跟踪性能。
ReidTrack: Reid-only Multi-target Multi-camera Tracking(2023)
摘要: 在零售商店或仓库等室内场景中对人员进行多目标多摄像头跟踪,使产品的高效放置和改进工作流程。在这项工作中,我们提出了ReidTrack框架,它仅仅基于人们的视觉外观来执行任务。理论上,准确的人的再识别能够解决整个任务,而不需要额外的和复杂的场景模型或后处理步骤。ReidTrack是基于聚类外观嵌入的,其机制是为了避免由显示多个个体身体部位的检测边界框引起的身份切换。只有一个鲁棒的人再识别模型和实时检测器YOLOv8,并且没有任何辅助信息,如复杂的场景模型,我们的方法在2023年AI城市挑战的轨道1中排名第四。
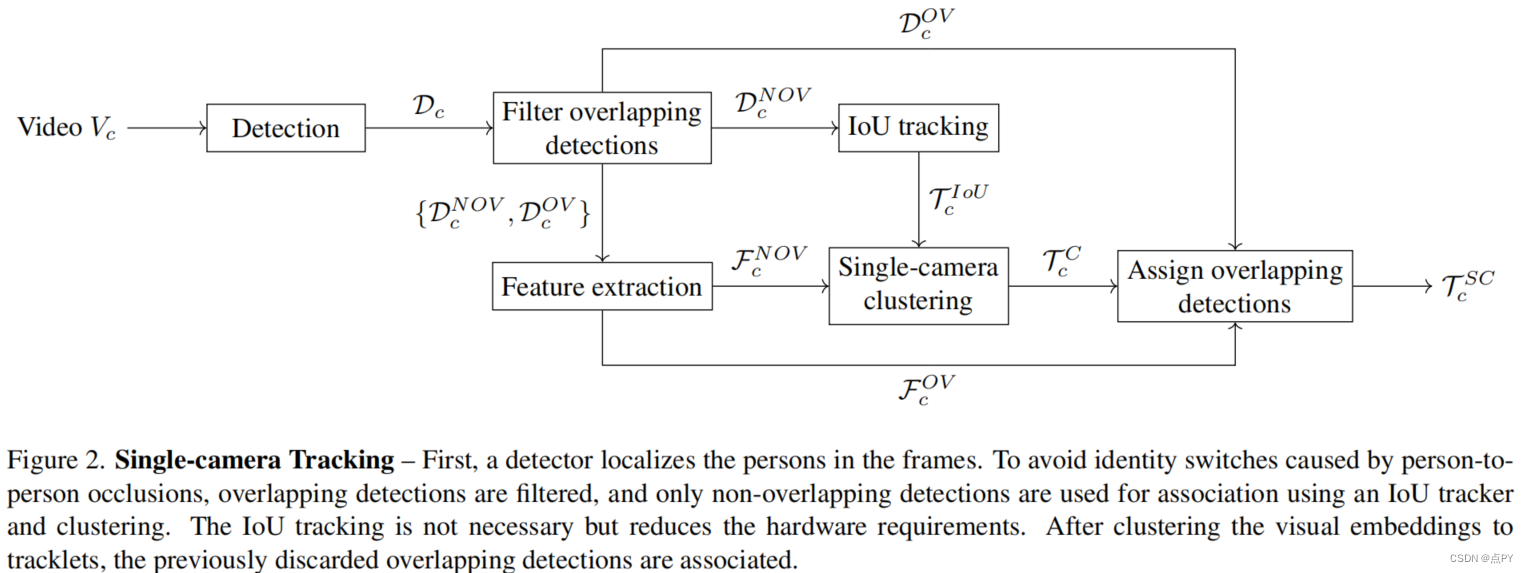
Multi-Object Tracking by Self-supervised Learning Appearance Model(2023)
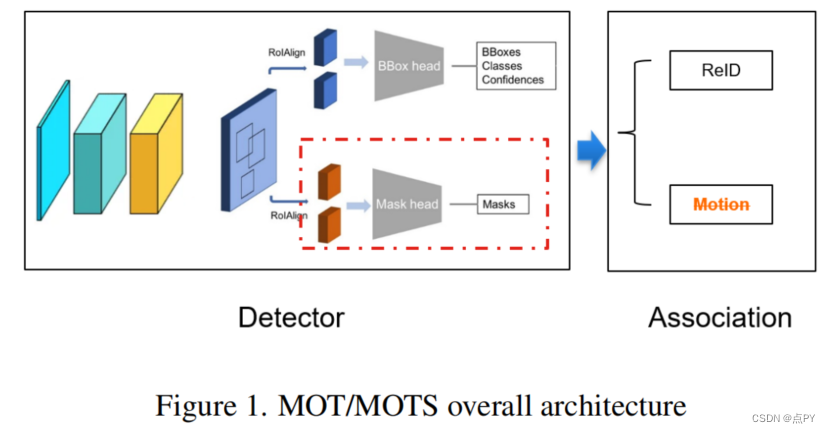
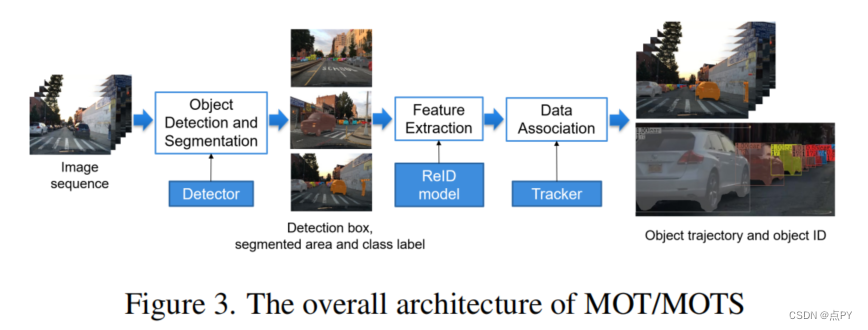
摘要:近年来,占主导的多目标跟踪(MOT)和分割(MOTS)方法主要遵循检测跟踪范式。基于transformer的端端(E2E)解决方案为MOT和MOT带来了一些想法,但它们不能在主要MOT和MOTS基准中实现新的最先进(SOTA)性能。检测和关联是逐检测跟踪范式的两个主要模块。联想技术主要依赖于运动和外观信息的结合。随着深度学习的发展,检测和外观模型的性能得到了迅速的提高。这些趋势使我们开始考虑是否可以仅基于高性能的检测和外观模型来实现SOTA。本文以CBNetV2为检测模型,moCo-ov2为自监督外观模型,探索这一方向。在关联过程中去除运动信息和离子单位映射。该方法在2个主流MOT数据集和1个MOTS数据集、WAYMO 2D跟踪、BDD100K100KMOTS数据集上获得了SOTA结果。在BDD 100K MOT和MOTS基准上,我们的方法使+分别显著提高了10.7%和+33.7%。在CVPR 2022自动驾驶研讨会上,该方法在BDD100K多目标跟踪(MOT)挑战中获得了第一名。在ECCV 2022下一代行业级自动驾驶(SSLAD)研讨会上,我们的方法也在BDD100K多目标跟踪(MOT)和多目标跟踪和分割(MOTS)挑战中获得了第一名。我们希望我们的简单有效的方法能够为MOT和MOTS研究界提供一些见解。
光照
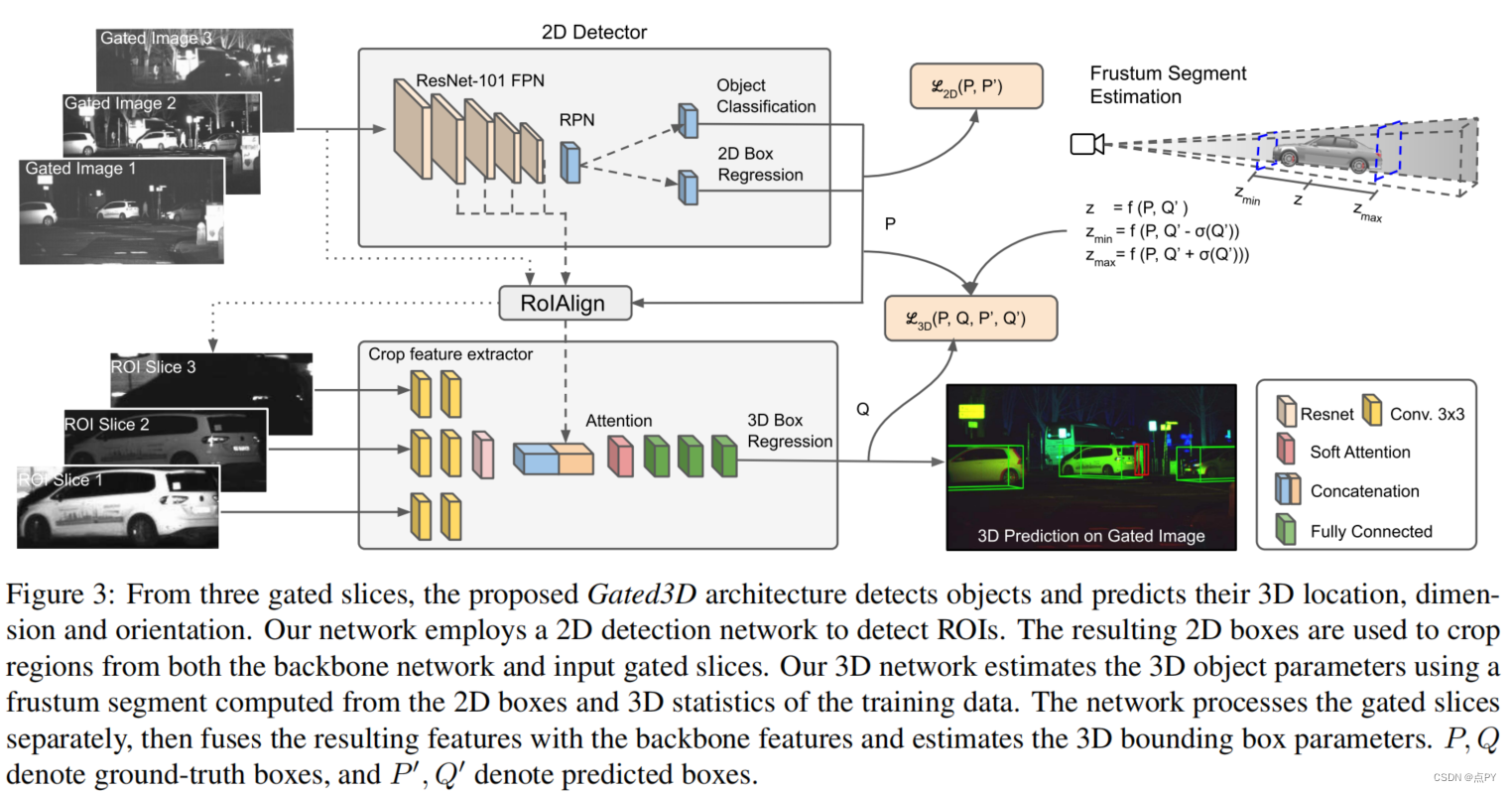
Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
code: https://light.princeton.edu/gated3d
摘要:当今最先进的3D物体检测方法是基于激光雷达、立体声或单眼相机。基于激光雷达的方法实现了最好的精度,但具有较大的足迹、成本高和机械限制的角度采样率,导致长距离的低空间分辨率。最近使用低成本单眼或立体相机的方法有望克服这些限制,但在低光或低对比度区域存在困难,因为它们依赖于被动CMOS传感器。我们提出了一种新的三维目标检测模式,利用来自一个低成本的单眼门控成像仪的时间照明线索。我们介绍了一种新的深度检测架构,门控3D,它是针对门控图像中的时间照明线索。这种模态允许我们利用成熟的二维对象特征提取器,通过一个挫折段估计来指导三维预测。我们在一个三维检测数据集上通过实验评估了所提出的方法,该数据集包括超过10,000公里的驾驶数据所捕获的门控图像。
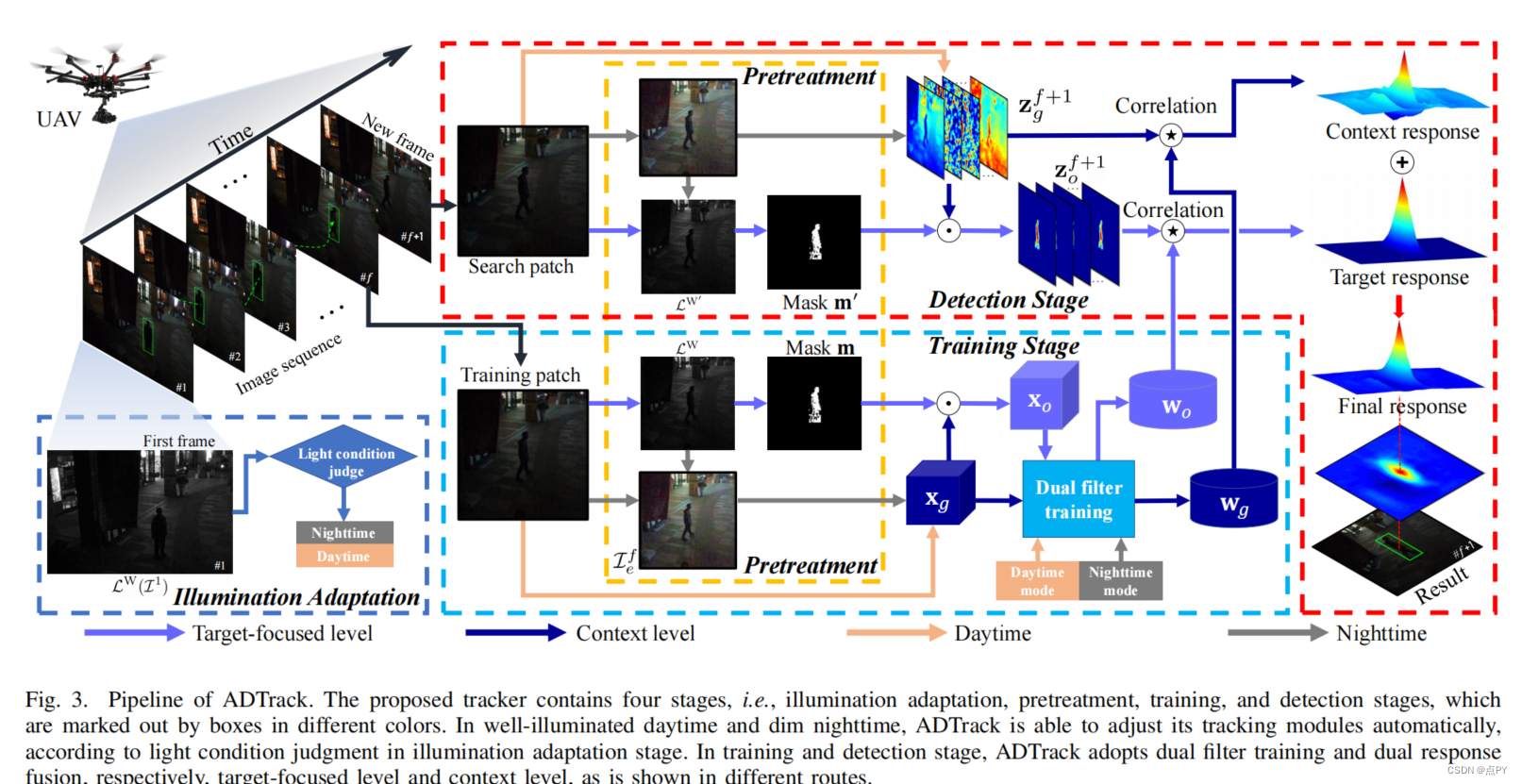
All-Day Object Tracking for Unmanned Aerial Vehicle
code: https://github.com/vision4robotics/ADTrack_v2
摘要:视觉对象跟踪是图像处理领域的主要兴趣,促进了许多现实世界的应用。其中,为无人机(UAV)配备实时强大的视觉跟踪器,用于全天空中机动,目前正逐渐引起人们的关注,并显著拓宽了目标跟踪的应用范围。然而,之前的跟踪方法仅仅关注于在光照良好的场景中的稳健跟踪,而忽略了追踪器在黑暗中部署的能力。在黑暗中,条件可能更复杂和苛刻,容易造成劣质的稳健跟踪,甚至跟踪失败。为此,本文提出了一种新的具有照明自适应和反暗能力的基于鉴别相关滤波器的跟踪器,即ADTrack。ADTrack首先利用图像照度信息,使模型对给定光照条件的适应性。然后,通过一个高效和有效的图像增强器,ADTrack进行图像预处理,其中生成一个目标感知的掩模。得益于掩模,ADTrack旨在解决一个对偶回归问题,其中双滤波器,即上下文滤波器和目标聚焦滤波器,是在相互约束下训练的。因此,ADTrack能够在全天的条件下持续保持良好的性能。此外,本工作还构建了一架无人机夜间跟踪基准UAVDark135,包含超过125k的手动标注帧,这也是第一个无人机暗跟踪基准。详尽的实验在权威的日间基准测试上进行了扩展,即,UAV123@10fps,DTB70,和新构建的暗基准测试UAVDark135。我们的研究结果验证了ADTrack在明亮和黑暗条件下比其他艺术的优越性。同时,ADTrack在一个CPU上实现了超过30帧/秒的实时速度,显著地保证了在全天场景下的真实世界的无人机目标跟踪。
论文的贡献:
- 本文提出了一种具有照明自适应和反暗功能的新型跟踪器(ADTrack)
- 所提出的ADTrack利用图像照明获取目标感知掩模,可以创造性地用于求解对偶回归。
- 这项工作构建了非常先进的无人机暗跟踪基准UAVDark135来进行大规模的评估
- 在两个权威的日间基准无人机123@10fps,DTB70和新建的夜间基准UAVDark135上进行了详尽的实验,以验证所提出的ADTrack在24小时跟踪性能方面的惊人能力。

A Cross-Scale and Illumination Invariance-Based Model for Robust Object Detection in Traffic Surveillance Scenarios
摘要: 由于室外场景的大规模变形和照明变化,交通监控场景中稳健的目标检测方法经常遇到挑战。为了增强这类方法对这些变化的容忍度,我们设计了一个基于“你只看一次”(YOLO)体系结构的跨尺度和照明不变检测模型(CSIM)。在大规模检测任务中,错误检测的一个主要原因是不同特征尺度之间的不一致。为了解决这个问题,我们引入了一个自适应的跨尺度特征融合模型,以确保所构造的特征金字塔的一致性。为了克服不均匀光的影响,我们在CSIM模型上建立了一个光照不变的色度空间,该空间与相关的色温无关。此外,我们采用空间注意模块、K-means聚类和Mish激活函数来进一步优化模型。实验结果表明,所提出的CSIM对解决交通监测过程中大规模变形和光照变化的挑战产生了良好的检测结果。与公共数据集上最先进的目标检测方法相比,我们提出的模型在交通监控场景中的鲁棒目标检测任务中取得了具有竞争力的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3356
3356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











