







文章目录
- 激光
- Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map(2018)
- LIO-CSI: LiDAR inertial odometry with loop closure combined with semantic information(2021)
- Semantic Lidar-Inertial SLAM for Dynamic Scenes(2022)
- RF-LIO: Removal-First Tightly-coupled Lidar Inertial Odometry in High Dynamic Environments(2022)
- A Fast Dynamic Point Detection Method for LiDAR-Inertial Odometry in Driving Scenarios(2024)
- 视觉
- 激光视觉
激光
Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map(2018)
code: https://github.com/gisbi-kim/SC-LIO-SAM
摘要: 与用于视觉场景的各种特征检测器和描述符相比,使用结构信息描述一个地方的报道相对较少。同步定位和映射(SLAM)的最新进展提供了密集的环境三维地图,并且定位是由不同的传感器提出的。针对基于结构信息的全局定位,我们提出了扫描上下文,一种基于非直方图的全局描述符,来自于三维光检测和测距(LiDAR)扫描。与以前报道的方法不同,所提出的方法直接记录了来自传感器的可见空间的三维结构,而不依赖于直方图或之前的训练。此外,该方法提出使用相似度评分来计算两个扫描上下文之间的距离,并使用两阶段搜索算法来有效地检测一个循环。扫描上下文及其搜索算法使循环检测对激光雷达视点的变化保持不变,从而可以在反向重新访问和角落等地方检测到循环。通过三维激光雷达扫描的各种基准数据集对扫描上下文性能进行了评估,该方法显示出了足够好的性能改进。

LIO-CSI: LiDAR inertial odometry with loop closure combined with semantic information(2021)
摘要: 准确、可靠的状态估计和映射是大多数自动驾驶系统的基础。近年来,研究人员主要关注利用几何特征匹配进行姿态估计。然而,文献中的大多数作品都假设了一个静态的场景。此外,基于几何特征的配准容易受到动态物体的干扰,导致精度下降。随着深度语义分割网络的发展,除了几何信息之外,我们还可以方便地从点云中获取语义信息。语义特征可以作为几何特征的辅助手段,可以提高测程法和环路闭包检测的性能。在更现实的环境中,语义信息可以过滤出数据中的动态对象,如行人和车辆,从而导致生成的地图中的信息冗余和基于地图的定位失败。在本文中,我们提出了一种结合语义信息(LIO-CSI)的激光雷达惯性测程法(LIO)方法,该方法集成了语义信息,便于前端过程和环路闭包检测。首先,我们对稀疏点-体素神经结构搜索(SPVNAS)网络提供的语义标签进行了局部优化。将优化后的语义信息通过平滑映射(LIOSAM)结合到紧密耦合光检测和测距(LiDAR)惯性测程的前端过程中,可以对动态对象进行过滤,提高点云配准的精度。然后,我们提出了一种语义辅助扫描上下文方法,以提高循环闭包检测的准确性和鲁棒性。该实验是在吉林大学(JLU)校区的一个广泛使用的数据集KITTI和一个自收集的数据集上进行的。实验结果表明,该方法优于纯几何方法,特别是在动态情况下,具有良好的泛化能力。

Semantic Lidar-Inertial SLAM for Dynamic Scenes(2022)
摘要: 在过去的几年里,许多令人印象深刻的激光雷达-惯性SLAM系统已经被开发出来,并在静态场景下表现良好。然而,在现实生活中,大多数任务都是在动态环境下,确定一种提高准确性和鲁棒性的方法是一个挑战。本文提出了一种结合点云语义分割网络和激光雷达惯性SLAM LIO映射的动态场景语义SLAM激光雷达惯性SLAM方法。我们向点conv网络中输入一个注意机制,建立一个注意权重函数,以提高预测细节的能力。来自激光雷达的点云的语义分割结果使我们能够获得每个激光雷达帧的点级标签。对动态目标进行滤波后,激光雷达-惯性SLAM系统的全局图更加清晰,估计的轨迹可以获得更高的精度。我们在一个UrbanNav数据集上进行了实验,其具有挑战性的高速公路序列有大量移动的汽车和行人。结果表明,与其他SLAM系统相比,可以在不同程度上提高运动轨迹的精度。


RF-LIO: Removal-First Tightly-coupled Lidar Inertial Odometry in High Dynamic Environments(2022)
摘要: 同步定位和映射(SLAM)被认为是智能车辆和移动机器人的一种基本能力。然而,目前大多数的激光雷达SLAM方法都是基于一个静态环境的假设。因此,在具有多个移动对象的动态环境中的定位实际上是不可靠的。本文提出了一种基于LIO-SAM的动态SLAM框架RF-LIO,该框架添加自适应多分辨率范围图像,使用紧密耦合的激光雷达惯性测程法首先去除移动物体,然后将激光雷达扫描与子图进行匹配。因此,即使在高动态的环境中,它也能获得准确的姿态。所提出的RF-LIO在自收集的数据集和开放的Urbanloco数据集上进行了评估。在高动态环境下的实验结果表明,与LOAM和LIO-SAM相比,所提出的RF-LIO的绝对轨迹精度可以分别提高90%和70%。RF-LIO是高动态环境中最先进的SLAM系统之一。


A Fast Dynamic Point Detection Method for LiDAR-Inertial Odometry in Driving Scenarios(2024)
code: https://github.com/ZikangYuan/dynamic_lio
摘要: 现有的基于三维点的动态点检测和去除方法具有显著的时间开销,使其难以适应激光雷达-惯性测程系统。本文提出了一种基于标签一致性的动态点检测和去除方法,用于处理自动驾驶场景中的移动车辆和行人,并将所提出的动态点检测和去除方法嵌入到一个自设计的激光雷达-惯性测程系统中。在三个公共数据集上的实验结果表明,我们的方法可以在LIO系统中以极低的计算开销(即1∼9ms)完成动态点检测和去除,同时实现与最先进的方法相当的保存率和拒绝率,显著提高了姿态估计的精度。我们已经发布了这项工作的源代码。

视觉
Visual SLAM in Human Populated Environments: Exploring the Trade-off between Accuracy and Speed of YOLO and Mask R-CNN(2019)
摘要:同步定位和映射(SLAM)是移动机器人技术中的一个基本问题。然而,大多数Visual SLAM算法都假设了一个静态场景,这限制了它们在现实环境中的适用性。在Visual SLAM中处理动态内容仍然是一个开放的问题,解决方案通常依赖于直接的或基于特性的方法。深度学习技术可以在具有先验动态对象的环境中改进SLAM解决方案,提供场景的高级信息。本文提出了一种基于基于深度学习技术的人类居住环境中SLAM的新方法。该系统是建立在ORB-SLAM2上,一个最先进的SLAM系统。所提出的方法使用基准数据集进行评估,在高度动态的场景中优于其他Visual SLAM方法。
VDO-SLAM: A Visual Dynamic Object-aware SLAM System (2021)
code: https://cs.paperswithcode.com/paper/vdo-slam-a-visual-dynamic-object-aware-slam
摘要:结合同步定位和映射(SLAM)估计和动态场景建模,可以高度有利于机器人在动态环境中的自主性。机器人的路径规划和避障任务依赖于对场景中动态物体运动的精确估计。本文提出了VDO-SLAM,一种鲁棒的视觉动态目标软件SLAM系统,利用语义信息,在不事先了解物体的形状或几何模型的情况下,对场景中的动态刚性物体进行精确的运动估计和跟踪。该方法可以识别并跟踪环境中的动态对象和静态结构,并将这些信息集成到一个统一的SLAM框架中。这导致了对机器人的轨迹和物体的完整的SE (3)运动的高度精确的估计,以及环境的时空地图。该系统能够从物体的SE (3)运动中提取线性速度估计值,这为在复杂的动态环境中的导航提供了一个重要的功能。
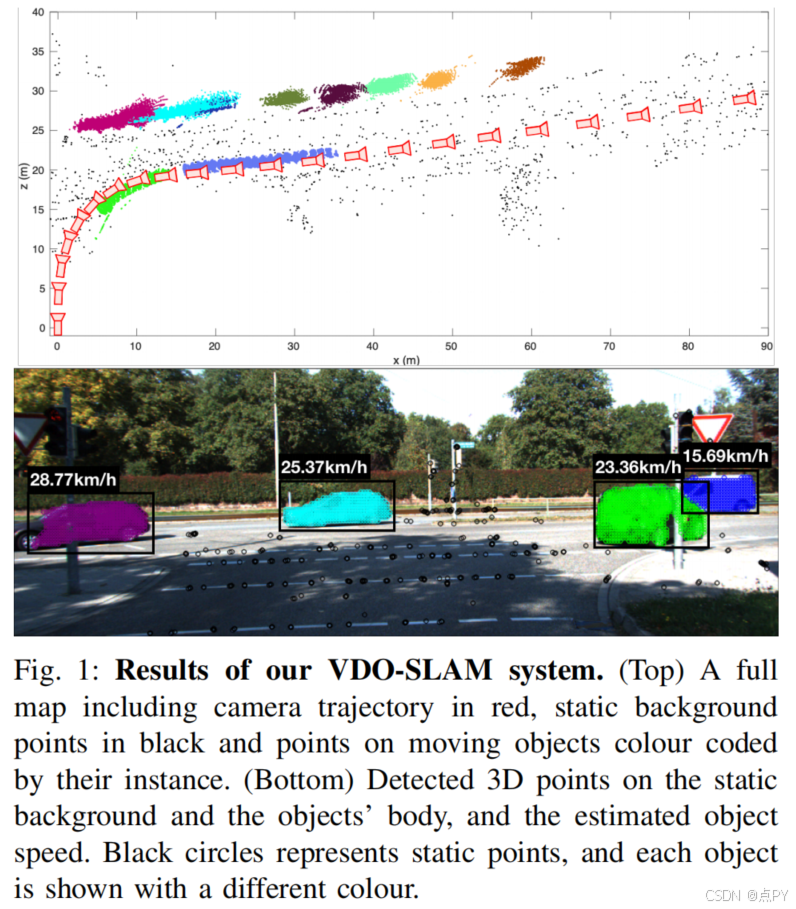

NGD-SLAM: Towards Real-Time Dynamic SLAM without GPU(2024)
code: https://paperswithcode.com/paper/ngd-slam-towards-real-time-slam-for-dynamic
摘要: 现有的SLAM(同步定位和映射)算法通过使用深度学习技术来识别动态目标,在动态环境中实现了显著的定位精度。然而,它们通常需要gpu来实时运行。因此,本文提出了一种仅在CPU上运行的开源实时动态SLAM系统,并结合了一种掩模预测机制,使深度学习方法和摄像机跟踪在不同的频率下完全并行运行。我们的SLAM系统进一步引入了一种双级光流跟踪方法,并采用了光流和ORB特性的混合使用,通过选择性地将计算资源分配到输入帧来提高效率和鲁棒性。与以往的方法相比,我们的系统在动态环境下保持了较高的定位精度,同时在笔记本电脑CPU上实现了56 FPS的跟踪帧率,证明了深度学习方法在没有GPU支持的情况下对动态SLAM是可行的。
激光视觉
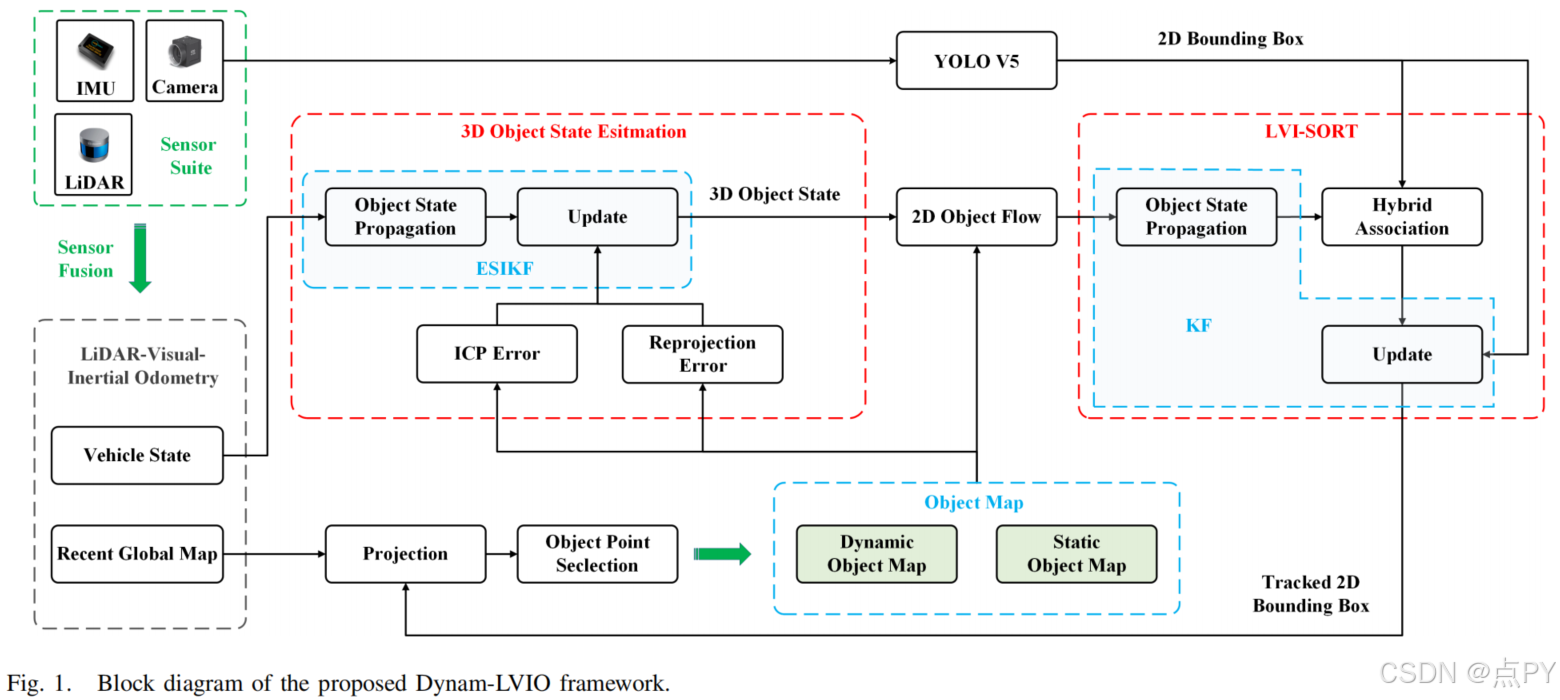
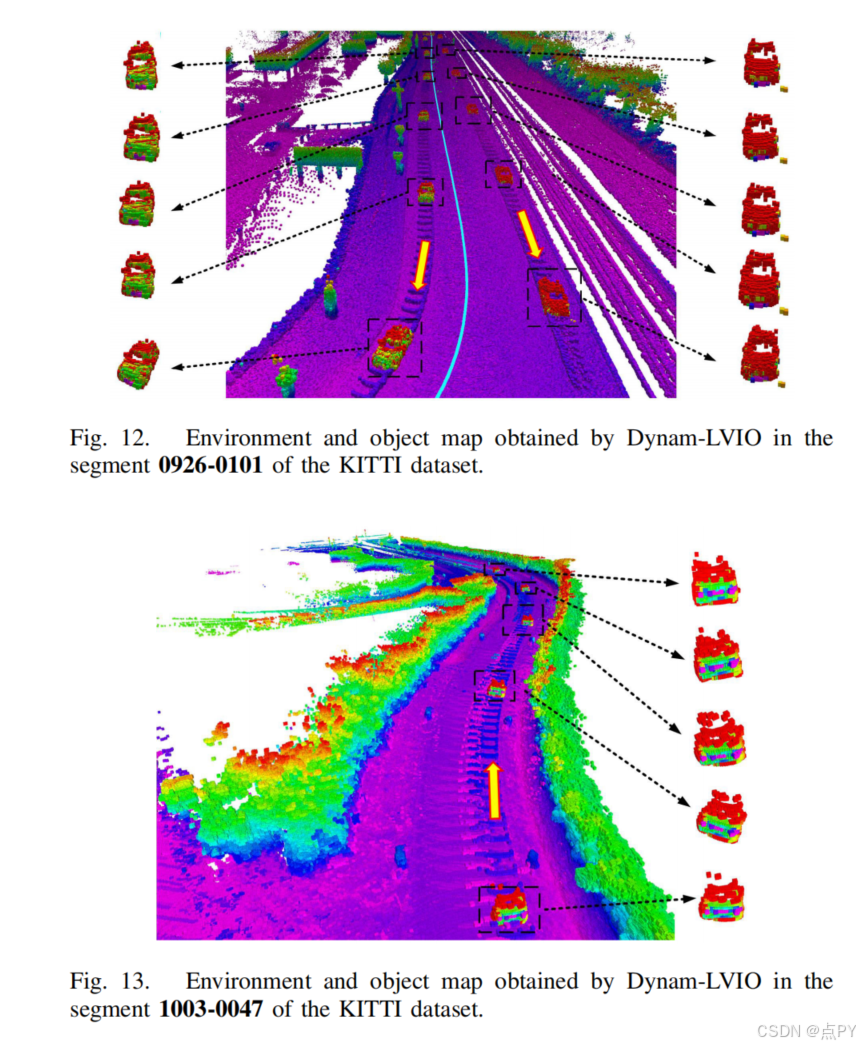
Dynam-LVIO: A Dynamic-Object-Aware LiDAR Visual Inertial Odometry in Dynamic Urban Environments(2024)
摘要: 对于大多数现有的同步定位和映射(SLAM)系统,自动驾驶车辆的周围环境被认为是静态的,这在城市环境中是不切实际的,并损害了现有的SLAM算法的有效性。在这项工作中,引入了一种动态目标感知光检测和测距(激光雷达)视觉惯性测程法(LVIO),称为Dynam-LVIO,通过构建环境地图和目标地图来提高动态环境中SLAM的精度。首先,利用目标映射计算重投影误差和迭代最近点(ICP)误差,作为误差状态迭代卡尔曼滤波器(ESIKF)的观测值,以准确地估计流形上的目标状态。随后,利用所提出的多目标跟踪(MOT)算法LVI-SORT对通过YOLOV5得到的二维边界盒进行跟踪,以在复杂场景中实现稳定的MOT。具体来说,为了提高快速移动场景中MOT的精度,在LVI-SORT的预测过程中,利用目标状态、车辆状态和目标贴图计算的二维对象流对目标状态进行预测。此外,为了减轻临时对象遮挡引起的MOT故障,在逻辑排序关联过程中提出了一种混合对象关联,通过结合对象映射点和边界盒的交叉过并集(IoU)来形成匈牙利算法中的代价矩阵。最后,利用跟踪的二维边界框将最近的全局图分割成环境图和对象图,从而减少了动态对象对激光雷达视觉惯性SLAM的影响。与其他基准测试算法相比,计算结果表明,该算法在动态场景下可以提高5%-10%的定位精度。同时,该算法还提高了目标跟踪精度近3%。
论文的贡献:
- 为了建立一个动态对象感知的SLAM框架,我们提出了一种新的MOT方法LVI-SORT,并将其与一个标准的LVIO集成,形成了Dynam-LVIO。使用使用LVI-SORT跟踪的对象,由标准LVIO生成的全局映射可以划分为静态环境映射和对象映射。这种划分减轻了动态对象对LVIO的影响,从而有效地提高了动态环境中的定位和映射精度。
- 为了提高快速移动场景中车辆或动态物体的MOT精度,将重投影误差和迭代最近点(ICP)误差同时作为误差状态迭代卡尔曼滤波器(ESIKF)的观测值,使三维物体状态能够准确估计。随后,在LVI-SORT的预测阶段,利用三维对象状态和对象映射点来计算二维对象流。这种改进有助于提高目标预测的准确性,特别是在快速移动的车辆或物体,从而提高整体MOT精度。
- 为了减轻由临时对象遮挡引起的MOT故障,二维对象流用于跟踪对象映射点。被跟踪的目标映射点随后与边界盒的交叉过并集(IoU)集成,在匈牙利算法中形成一个混合代价矩阵。该方法保证了经过一段时间的遮挡后,预测对象与YOLO-V5检测对象之间的准确数据关联,从而增强了MOT在涉及对象遮挡的场景中的稳定性。
- 利用多个数据集验证了所提出的Dynam-LVIO算法的有效性。实验结果表明,它在动态环境下的定位和映射精度方面优于目前最先进的SLAM。


















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











