






论文题目:Pyramid Scene Parsing Network
论文地址:https://arxiv.org/pdf/1612.01105
代码地址:https://github.com/hszhao/PSPNet
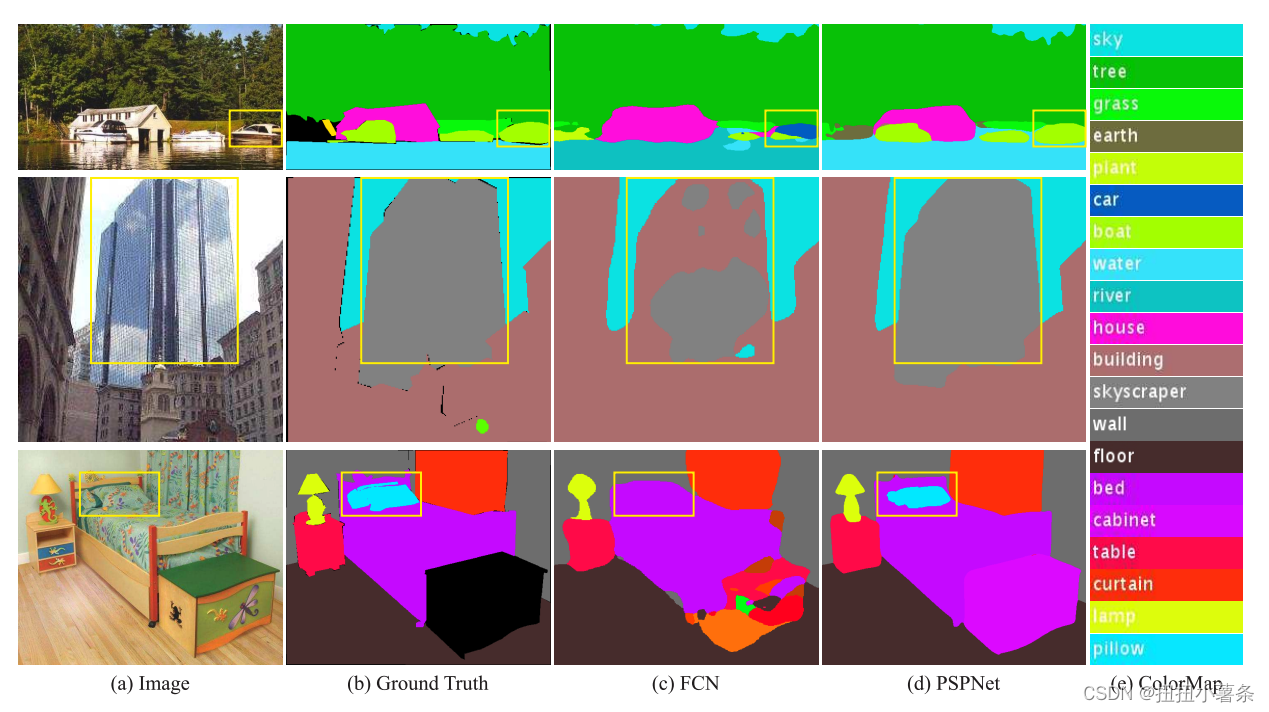
一、发现的问题:
1、Mismatched Relationship:
车和船的混淆没有考虑环境。
2、Confusion Categories:
相似类别混淆,如第二行,人有时候也会犯错。作者说可以通过类别间关系改善。
3、Inconspicuous Classes:
不引人注目的类别。不规则的小物体或者大物体超过感受野不连续。更加注重不显眼的区域解决。

二、提出的方法:
1、多尺度的池化层和卷积层拼接:
我们的金字塔池化模块有四个级别,分别为1×1、2×2、3×3和6×6的箱大小。
2、辅助loss
设计分割头,按照0.4的权重加入最终的loss。
数据增强:
对于数据增强,我们对所有数据集采用随机镜像和随机调整大小在0.5和2之间,并额外添加了在-10到10度之间的随机旋转以及对ImageNet和PASCAL VOC进行随机高斯模糊。
三、实验结果:(每部分贡献)
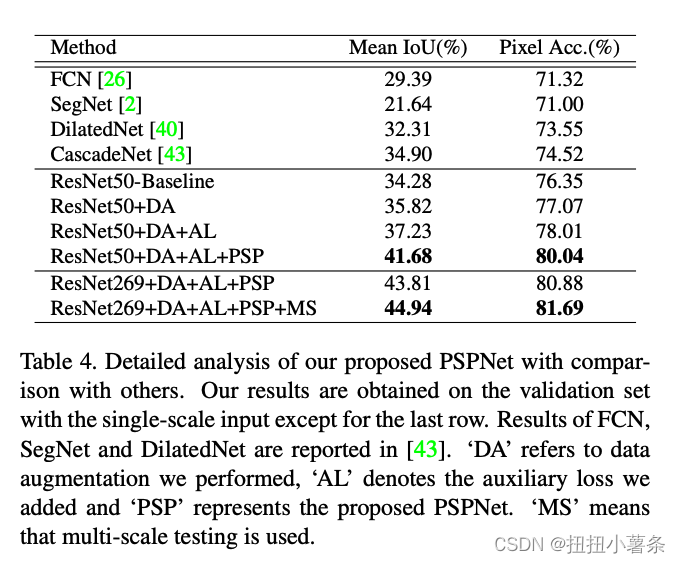
四、代码
1、PPM模块,根据一系列pool_sizes,返回pool后插值的结果
class PPM(nn.ModuleList):
def __init__(self, pool_sizes, in_channels, out_channels):
super(PPM, self).__init__()
self.pool_sizes = pool_sizes
self.in_channels = in_channels
self.out_channels = out_channels
for pool_size in pool_sizes:
self.append(
nn.Sequential(
nn.AdaptiveMaxPool2d(pool_size),
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1),
)
)
def forward(self, x):
out_puts = []
for ppm in self:
ppm_out = nn.functional.interpolate(ppm(x), size=x.size()[-2:], mode='bilinear', align_corners=True)
out_puts.append(ppm_out)
return out_puts
2、PSPHEAD模块:结果的拼接输出
class PSPHEAD(nn.Module):
def __init__(self, in_channels, out_channels,pool_sizes = [1, 2, 3, 6],num_classes=3):
super(PSPHEAD, self).__init__()
self.pool_sizes = pool_sizes
self.num_classes = num_classes
self.in_channels = in_channels
self.out_channels = out_channels
self.psp_modules = PPM(self.pool_sizes, self.in_channels, self.out_channels)
self.final = nn.Sequential(
nn.Conv2d(self.in_channels + len(self.pool_sizes)*self.out_channels, self.out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(),
)
def forward(self, x):
out = self.psp_modules(x)
out.append(x)
out = torch.cat(out, 1)
out = self.final(out)
return out
3、 Aux_Head 辅助分割头:逐步减少channel直到channel设为self.num_classes。
class Aux_Head(nn.Module):
def __init__(self, in_channels=1024, num_classes=3):
super(Aux_Head, self).__init__()
self.num_classes = num_classes
self.in_channels = in_channels
self.decode_head = nn.Sequential(
nn.Conv2d(self.in_channels, self.in_channels//2, kernel_size=3, padding=1),
nn.BatchNorm2d(self.in_channels//2),
nn.ReLU(),
nn.Conv2d(self.in_channels//2, self.in_channels//4, kernel_size=3, padding=1),
nn.BatchNorm2d(self.in_channels//4),
nn.ReLU(),
nn.Conv2d(self.in_channels//4, self.num_classes, kernel_size=3, padding=1),
)
def forward(self, x):
return self.decode_head(x)
4、PspNet:
class Pspnet(nn.Module):
def __init__(self, num_classes, aux_loss = True):
super(Pspnet, self).__init__()
self.num_classes = num_classes
self.backbone = IntermediateLayerGetter(
resnet50(pretrained=False, replace_stride_with_dilation=[False, True, True]),
return_layers={'layer3':"aux" ,'layer4': 'stage4'}
)
self.aux_loss = aux_loss
self.decoder = PSPHEAD(in_channels=2048, out_channels=512, pool_sizes = [1, 2, 3, 6], num_classes=self.num_classes)
self.cls_seg = nn.Sequential(
nn.Conv2d(512, self.num_classes, kernel_size=3, padding=1),
)
if self.aux_loss:
self.aux_head = Aux_Head(in_channels=1024, num_classes=self.num_classes)
def forward(self, x):
_, _, h, w = x.size()
feats = self.backbone(x)
x = self.decoder(feats["stage4"])
x = self.cls_seg(x)
x = nn.functional.interpolate(x, size=(h, w),mode='bilinear', align_corners=True)
# 如果需要添加辅助损失
if self.aux_loss:
aux_output = self.aux_head(feats['aux'])
aux_output = nn.functional.interpolate(aux_output, size=(h, w),mode='bilinear', align_corners=True)
return {"output":x, "aux_output":aux_output}
return {"output":x}
5、最后两层Dilation
from torchvision.models._utils import IntermediateLayerGetter
backbone=IntermediateLayerGetter(
resnet101(pretrained=False, replace_stride_with_dilation=[False, True, True]),
return_layers={'layer3':'aux','layer4': 'stage4'}
)
整个网络仅在最后加了PSP head模块。最后两层使用了Dilation卷积。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









