







今夜,Manus发布之后,随之而来赶到战场的,是阿里。
凌晨3点,阿里开源了他们全新的推理模型。
QwQ-32B。
本来还有点意识模糊,当看到他们发出来的性能比对图,我人傻了。
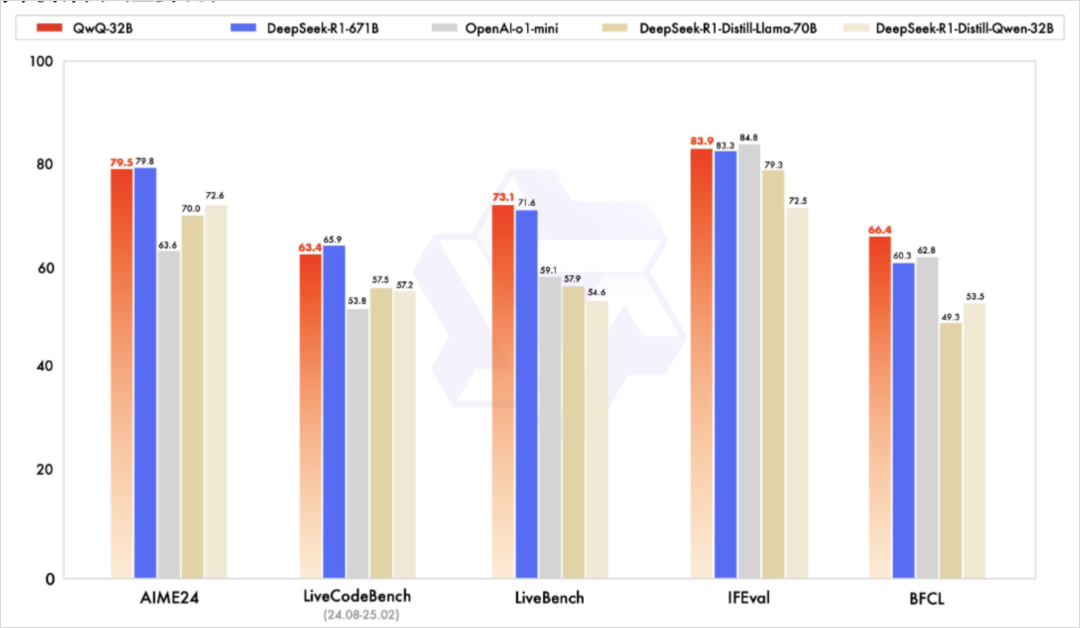
QwQ-32B 在几乎所有数据集上的表现都与满血版 DeepSeek R1(671B)相当,特别是在数学和代码方面。此外,它的基准测试成绩远超 o1-mini。这让我感到非常惊讶。今天(2025年3月6日),这个消息对我冲击很大。GPT-4.5 刚刚显示出传统方法的局限性,而阿里却用 QwQ-32B 证明了强化学习仍有巨大潜力。这一结果也与最近在 arXiv 上发表的一篇热门论文相吻合。
一堆斯坦福教授集中讨论,为什么Qwen-2.5-3B一开始就能自己检查自己的答案,Llama-3.2-3B却不行。
最后的原因还是落在了Qwen团队的强化学习上。因为,这能让模型自己学会一些关键的“思考习惯”。

魔搭开源链接:https://modelscope.cn/models/Qwen/QwQ-32B
huggingface开源链接:https://huggingface.co/Qwen/QwQ-32B
当然如果想直接上手体验,官方也给出了在线体验的地址:
https://chat.qwen.ai/?models=Qwen2.5-Plus
左上角模型选择Qwen2.5-Plus,然后开启Thinking(QwQ),就能用QwQ-32B了。
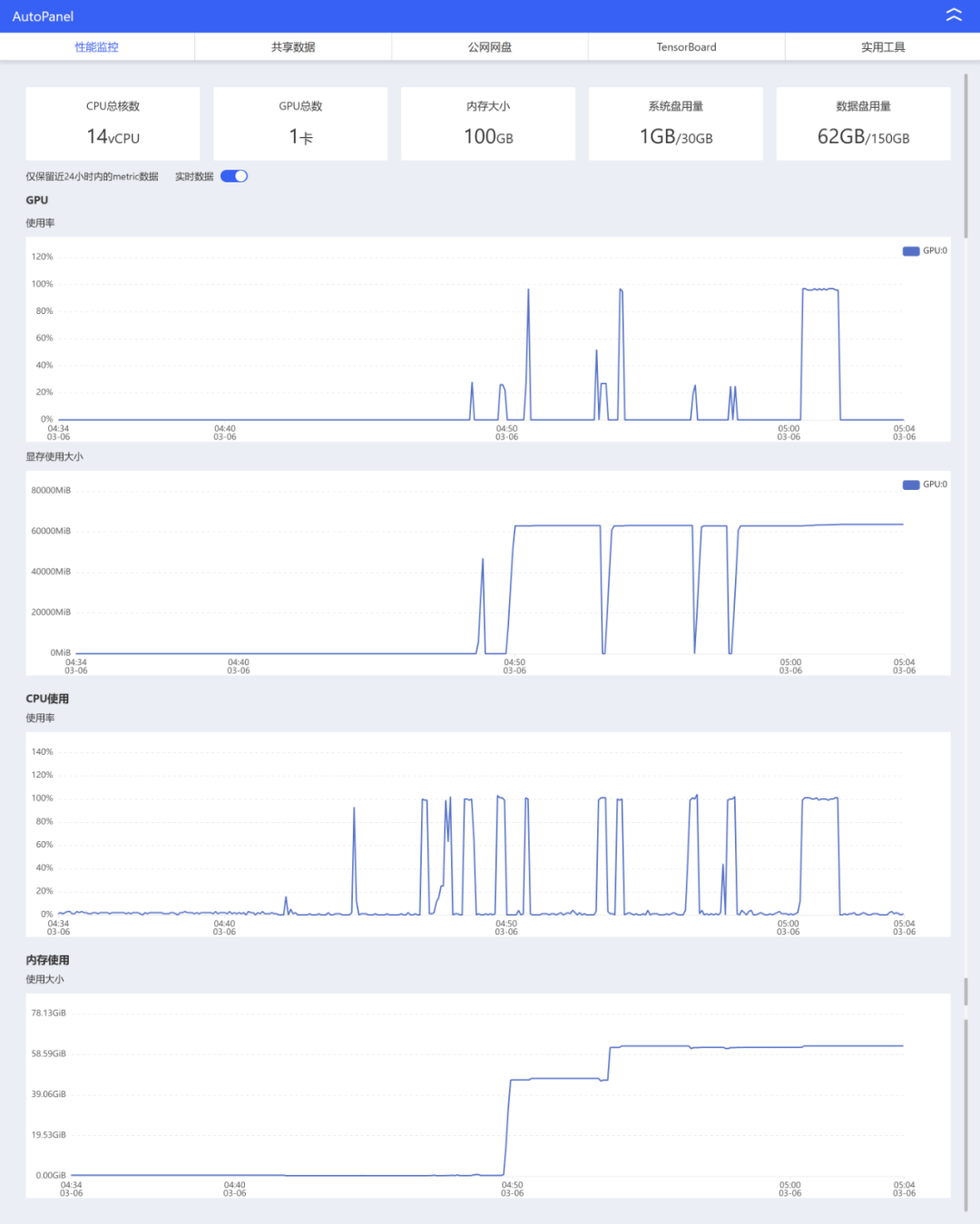
我这边也第一时间在AutoDL租了一台A800-80G的显卡,然后把模型下载了下来,并部署测试了一下这个怪物。综合体验下来,本地部署版和网页版其实是一样的。
性能曲线是这样的。
我也做了一些测试。
首先就是,我觉得赛博半仙易主了。这回的QwQ-32B真的能当八字算命大师了。
懂得都懂,AI自媒体人的命也是命,它掐指一算,就知道我经常熬大夜,狂肝文章。下半年家里那些鸡毛蒜皮的事就别提了,为了搭我的摄影棚,把景深弄得更到位,我是真得搬家啊。。。

当然,AI算命只能算是个开胃菜,接下来还是得认真测下QwQ-32B的数学能力。
然后就是拿我的著名的国庆调休题来难为下这类推理模型了:
这是中国2024年9月9日(星期一)开始到10月13日的放假调休安排:上6休3上3休2上5休1上2休7再上5休1。请你告诉我除了我本来该休的周末,我因为放假多休息了几天?
比如Grok3这种,开了推理还是直接炸了。

答案明明是4天,你咋独自加了3天。。。
而看看QwQ-32B,在一顿小推理之后。

最后答案,完全正确。

要知道,这可只是一个32B的小模型啊。。
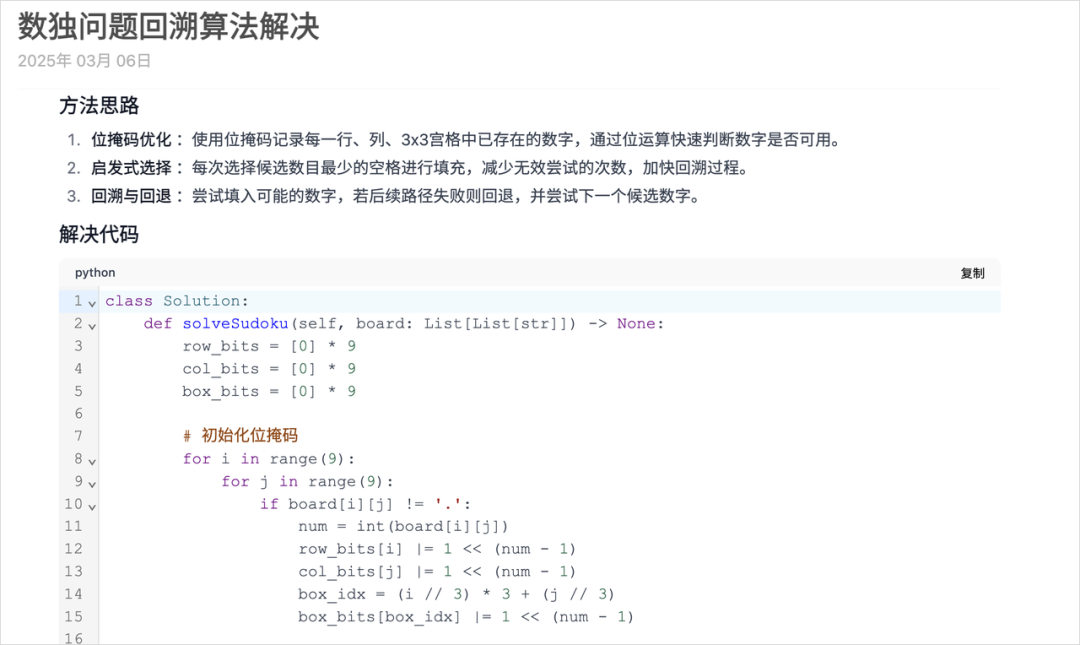
然后我还试了一下代码能力。我就直接去Leetcode找了一道困难级别的算法题,解数独。
可能有人不知道Leetcode是啥,LeetCode 是一个全球知名的在线编程练习平台,这个平台有大量不同难度的算法题库,从简单到困难的各种编程题都有。
我直接把解数独的题目还有代码模板丢给QwQ-32B,让它给出最优解的代码:
编写一个程序,通过填充空格来解决数独问题。
数独的解法需遵循如下规则:
数字 1-9 在每一行只能出现一次。
数字 1-9 在每一列只能出现一次。
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
然后给定你一个类,给我一个比较好的方案:
class Solution(object):
def solveSudoku(self, board):
"""
:type board: List[List[str]]
:rtype: None Do not return anything, modify board in-place instead.
"""
经过几分钟的思考,这道题的完整最优解代码也是被QwQ-32B成功给出。
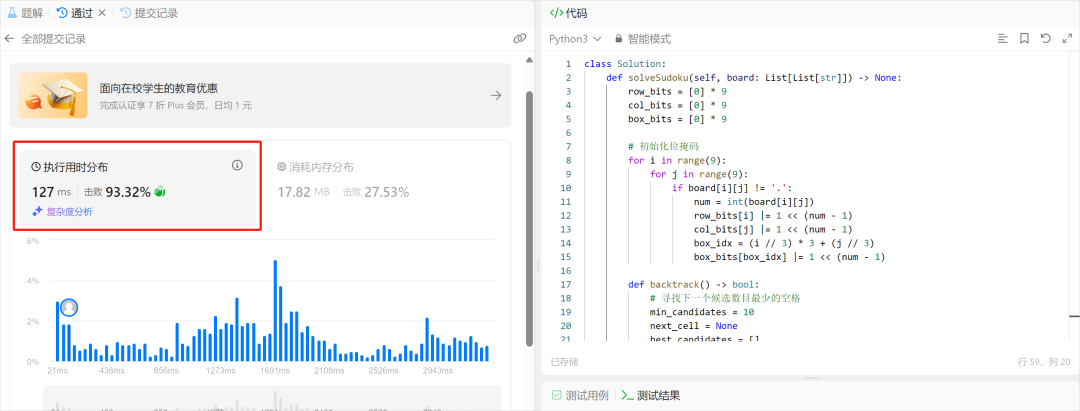
我把这段代码粘贴到了Leetcode平台上,直接提交,没想到这段代码竟然完美的通过了全部测试用例吗,而且执行用时才127ms,击败了93%的在这个算法题库做尝试的人。
说实话,这个结果让我挺惊讶的,毕竟127ms的用时,看平均的用时基本都在1691ms左右。
Qwen-32B模型的强大之处,尤其是在未来的生态建设方面。相比于671亿参数的大模型,32亿参数的Qwen在本地算力需求和云服务成本上有着显著的优势。例如,在FP16精度下运行一个671亿参数的模型需要高达1400G的显存支持,这对于很多企业和开发者来说是一个难以逾越的技术与经济障碍。相比之下,只需四张NVIDIA 4090显卡就能运行Qwen-32B版本,这不仅降低了硬件门槛近15倍,而且其智能表现几乎可以与更大规模的模型相媲美。
这种相对较低的成本投入使得更多普通企业及个人开发者能够接触到先进的AI技术,并有机会根据自身需求对模型进行定制化调整或二次开发,极大地促进了技术创新与发展。尤其是对于那些致力于打造专业级AI解决方案的小型企业或是初创团队而言,Qwen-32B无疑提供了一个极具吸引力的选择——它既具备强大的逻辑推理、数学处理以及编程能力,又保持了良好的可访问性和灵活性。
此外,通过与阿里云资源、ModelScope平台以及Hugging Face镜像站等外部工具和服务相结合,使用Qwen-32B变得更加便捷高效,几乎消除了以往部署大型语言模型时遇到的各种难题。这意味着即使是非专业人士也能轻松上手,快速构建起自己的AI应用体系。
更重要的是,Qwen-32B的成功案例证明了采用强化学习与人类反馈(RLHF)训练方法依然能够在性能上取得突破,打破了部分人对于超大规模模型发展瓶颈的担忧。它展示了即使不依赖于极其昂贵的计算资源,中等规模的模型也完全有可能达到顶级水平,从而为整个开源社区带来了新的希望与动力。
总之,随着各大科技公司不断加大研发投入,未来还将有更多令人兴奋的技术创新涌现出来。就像最近备受关注的Manus项目那样,它正是基于Claude架构并结合大量微调后的Qwen小模型所实现的一个典型例子。由此可见,Qwen-32B不仅代表了一次重要的技术进步,同时也预示着新一轮竞争格局正在形成。


















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









