






训练代码
python tools/train.py D:/Project/CEASC-main/configs/UAV/dynamic_retinanet_res18_visdrone.py -- work-dir D:/Project/CEASC-main/work_dirs
Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object
Detection on Drone Images


直接看head部分
整个模型结构
RetinaNet(
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3),
bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1,
ceil_mode=False)
(layer1): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Pretrained', 'checkpoint': 'torchvision://resnet18'}
(neck): FPN(
(lateral_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
)
)
(fpn_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1))
)
(1): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1))
)
(2): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1,
1))
)
(3): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1,
1))
)
(4): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1,
1))
)
)
)
init_cfg={'type': 'Xavier', 'layer': 'Conv2d', 'distribution': 'uniform'}
(bbox_head): RetinaDYHead(
(loss_cls): FocalLoss()
(loss_bbox): L1Loss()
(relu): ReLU(inplace=True)
(cls_convs): ModuleList(
(0): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
(1): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
(2): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
(3): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
)
(reg_convs): ModuleList(
(0): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
(1): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
(2): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
(3): Sequential(
(0): DyConv2D(
(conv): SparseConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(gn): GroupNorm(32, 512, eps=1e-05, affine=True)
)
)
)
(cls_pw_convs): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
)
(reg_pw_convs): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
)
(retina_cls): DyConv2D(
(conv): SparseConv2d(512, 90, kernel_size=(3, 3), stride=(1, 1), padding=
(1, 1))
)
(retina_reg): DyConv2D(
(conv): SparseConv2d(512, 36, kernel_size=(3, 3), stride=(1, 1), padding=
(1, 1))
)
(retina_cls_mask): Sequential(
(0): Conv2d(512, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Gumbel()
)
(retina_reg_mask): Sequential(
(0): Conv2d(512, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Gumbel()
)
(a_relu): ReLU(inplace=True)
)
)
使用的是
18
层的
Resnet
模型结构
FPN中
首先



- 前三个 ConvModule 的卷积核尺寸都是 3x3,步长为 1x1,padding 为 1x1,用于实现特征的融合和保持尺寸不变。
- 第四个和第五个 ConvModule 的卷积核尺寸也是 3x3,但步长为 2x2,padding 为 1x1,用于实现特征的下采样和尺度变化。

也就是说只有
P4
和
P5
的特征图尺寸发生了改变。
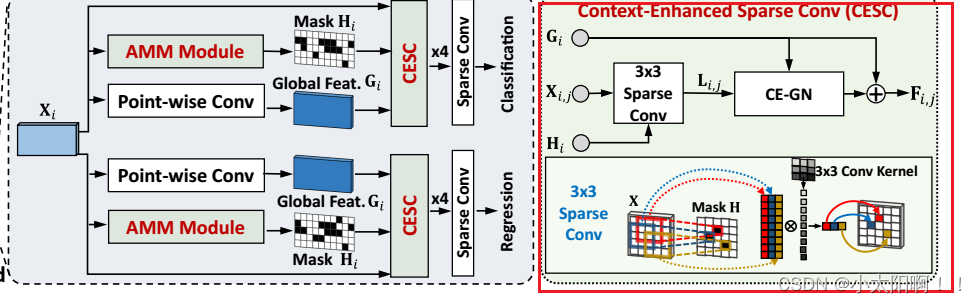
Head部分
为每个头分别引入了一个掩码网络。每个检测头采用四个卷积
GN-ReLU
层和一个卷积层进行预测,其中我们用SC
层代替了传统的卷积层。
分类头


回归头



RetinaDyHead类




DyConv2D卷积类


使用稀疏卷积
SparseConv2d
类
初始化


forward
函数

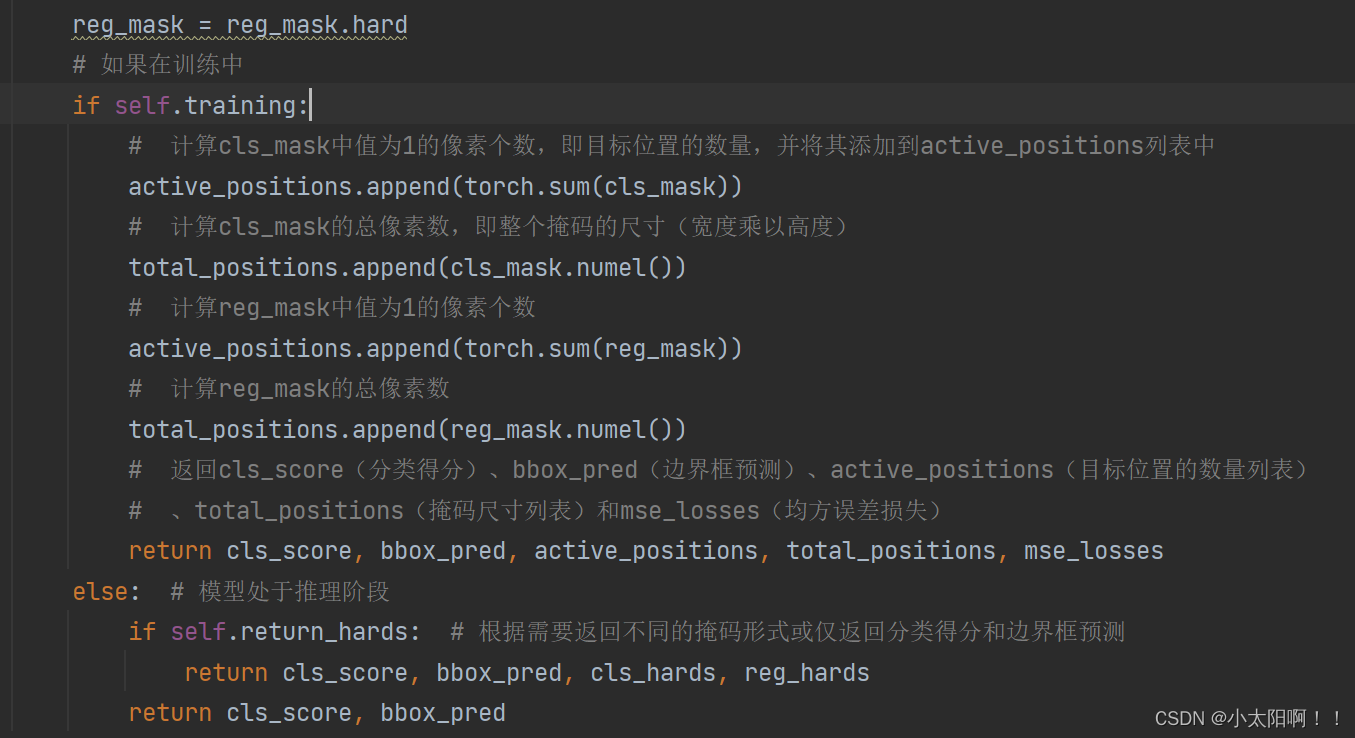
在训练时,使用
_slow_forward()
函数

该代码的作用是将卷积操作的结果
x
与基础值
self.base
进行加权和。对于保留的位置(
hard =
1
),使用
hard * x
,即保留
x
的值;对于丢弃的位置(
hard = 0
),使用
(1.0
-
hard)
控制基
础值
self.base
的权重,即保留
self.base
的值。
通过这样的加权和操作,最终得到了经过动态调整的输出结果,其中保留位置的特征来自卷积操作,丢弃位置的特征来自基础值 self.base
。这样可以在动态卷积中实现对输入特征图的局部保留和丢弃,进而影响网络的自适应性和表达能力。



回到DyConv2D卷积中

Head的前向传播过程


上述得到这里的
Hi
掩码。

得到的应该是
Point-wise Conv
后的
Gi
有了这些以后就可以进行
CESC
的过程了。
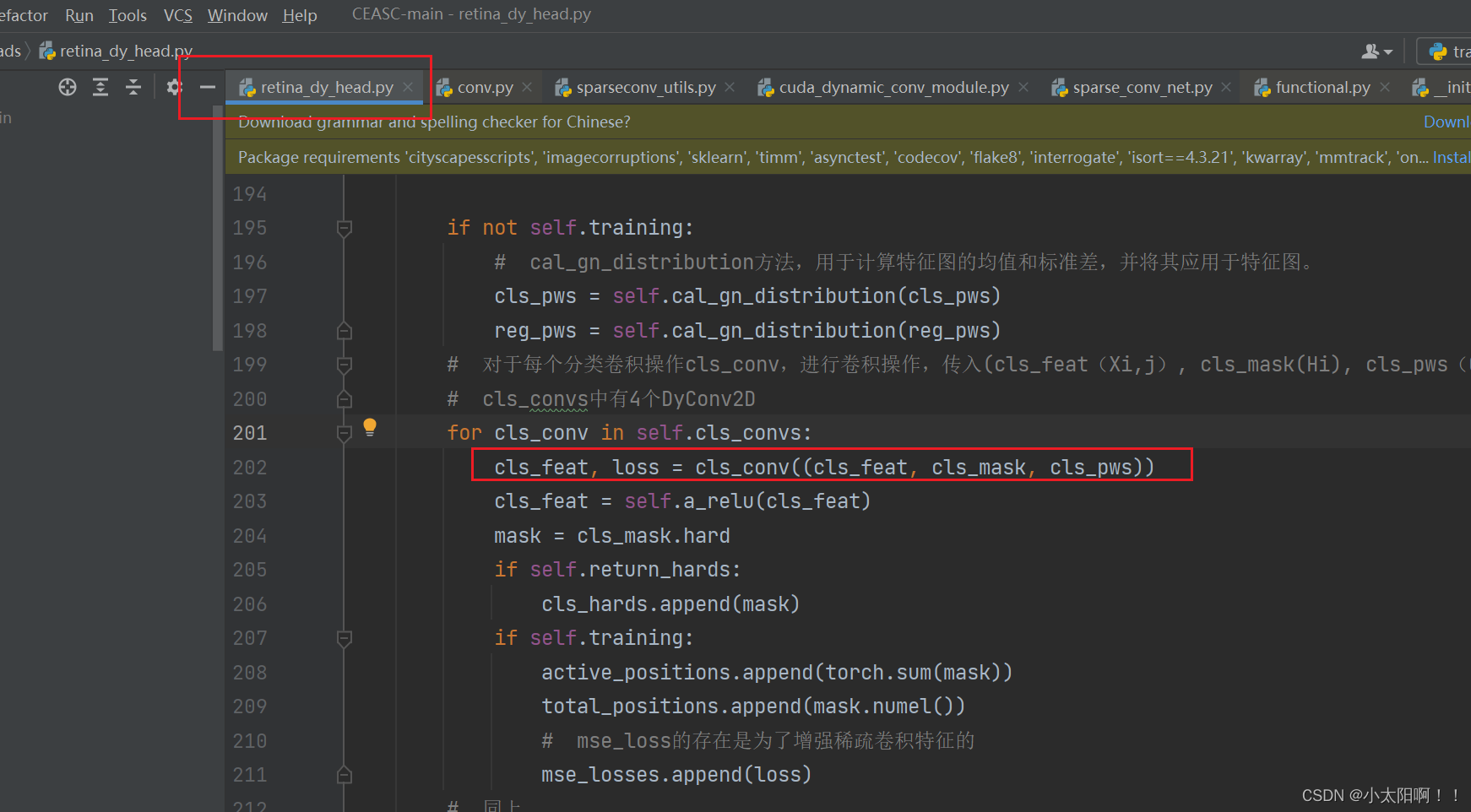
CESC的过程


这里调用了
cls_conv
中
DyConv2D
的
froward
函数,传入的参数是一个元组
(cls_feat, cls_mask,
cls_pws)
,作为
forward
方法的输入参数
inputs_meta
。

在
DyConv2D
的
forward
函数中


因此

进入
SpareConv2d
的
forward
函数

进入
_slow_forward
函数

现在就是对
x
执行一个动态卷积操作
传入的
gn
是不为
0
的。


组归一化
sparse_gn(x,gn,pw)
的过程

加权后的归一化特征图
x_part
与硬化掩码
hard
进行元素级乘法。


损失
F.mse_loss(x_part,x_total_detach())
实现的就是这个损失等式。
x_total
就是
Ci,j*Hi
,
x_part
就是
Fi,j
。
因此,此时
Sparse_Conv2d
的
forward
执行结束后,我们就得到了卷积过后的特征图
cls_feat
和
mse
损失。
这部分完成






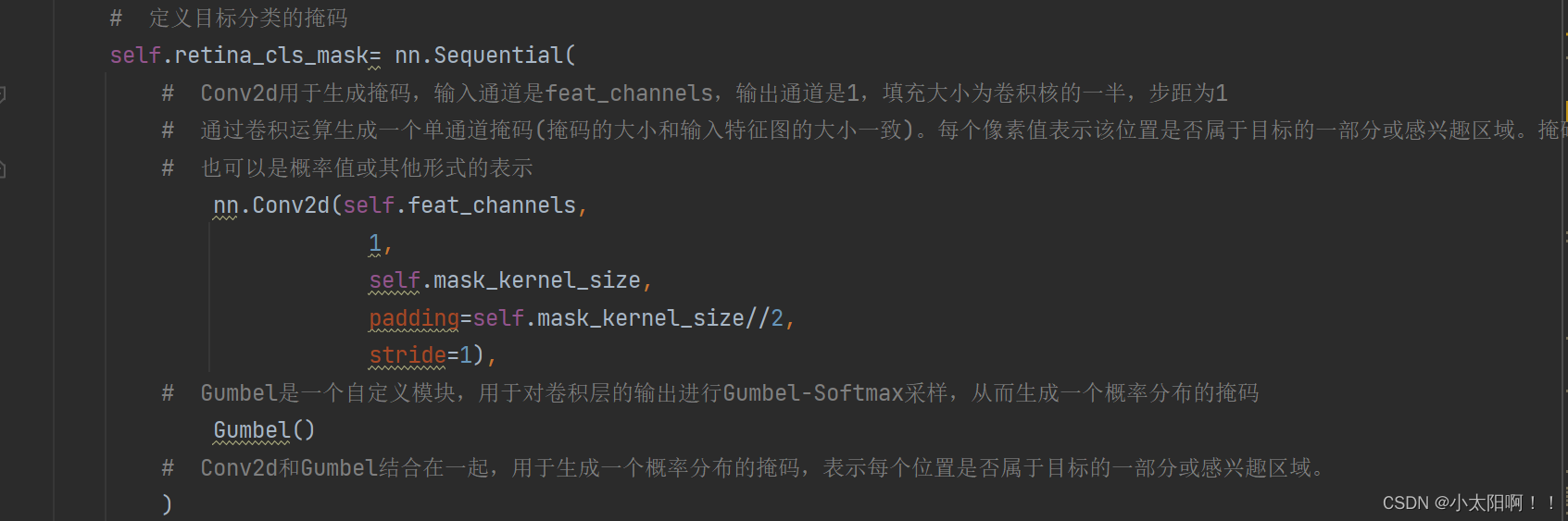
在这个过程中,首先特征图输入到
Conv2d
中进行卷积操作,生成一个输出特征图,输出特征图会传递给Gumbel 模块。
Gumbel
模块用于对卷积层的输出进行
Gumbel-Softmax
采样,从而生成一个概率分布的掩码。这个掩码表示每个位置是否属于目标的一部分或感兴趣区域。
正确部分

forward
函数

forward
方法通过调用
multi_apply
函数在不同的输入特征和尺度上并行地执行
forward_single
方
法,然后将分类得分和边界框预测结果作为元组返回。这种设计可以有效地处理多尺度的特征并生成相应的分类和回归结果
(也就是说对于
FPN
的几层输出分别调用
forward_single
函数进行处理,去得到最终的类别得分和回归)
打印
AP














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









