






Bags of Binary Words for Fast Place Recognition in Image Sequences
在图像序列中基于二进制词袋的快速地点识别
摘要
我们提出了一种新的方法,使用从FAST+BRIEF特征中获得的二进制词袋进行视觉地点识别。 首次,我们构建了一个词汇树,这个词汇树离散化了二进制描述符空间(a binary descriptor space),并使用该树加速几何对应关系的验证。使用完全相同的词汇和设置,我们在不同的数据集上呈现了竞争性的结果,没有误报。 整个技术,包括特征提取,在一个包含26300张图像的序列中每帧需要22毫秒,比以前的方法快一个数量级。
索引词:地点识别(Place Recognition),词袋( Bag of Words), SLAM,计算机视觉 Computer Vision.
一、引言
长时间(长期)视觉SLAM(同时定位与地图构建)的一个最重要的要求是稳健的地点识别。经过一段探索期,当长时间未观察到的区域被重新观察到时,标准匹配算法会失败。 当它们被稳健地检测到时,闭环提供正确的数据关联(data association)以获得一致的地图。 用于闭环检测的相同方法可以用于机器人在跟踪丢失后的重新定位,例如由于突然运动、严重遮挡或运动模糊。 在[1]中,我们得出结论,对于小环境,地图到图像( map-to-image)的方法表现良好,但对于大环境,图像到图像( image-to-image)(或基于外观的)方法如FAB-MAP [2]更具可扩展性。基本技术是通过机器人在线收集的图像构建数据库,以便在获取新图像时检索(retrieved)出最相似的图像。 如果它们足够相似,就会检测到闭环。
近年来,许多利用这个想法的算法已经出现[2]–[6],将图像匹配基于在词袋空间中将它们作为数值向量进行比较[7]。 词袋的引入会产生非常有效和快速的图像匹配器[8],但由于感知混淆(perceptual aliasing)[6],它们并不是检测闭环的完美解决方案。 因此,稍后会进行验证步骤,通过检查匹配的图像是否在几何上一致,需要特征对应。 闭环算法的瓶颈通常是特征提取,其计算周期比其他步骤多大约十倍。 这可能导致SLAM算法以两个解耦的线程运行:一个执行主要的SLAM功能,另一个仅用于检测闭环,就像[5]中一样。
在本文中,我们提出了一种新颖的算法,使用传统的CPU和单个摄像头,可以实时检测图像中的循环(闭环)并建立图像之间的点对应关系,我们的方法基于词袋和几何检查,具有几个重要的创新点,使其比当前方法快得多。 主要的速度改进来自于使用稍微修改的BRIEF描述符[9]和FAST关键点[10]的版本,如第三节所述。BRIEF描述符是一个二进制向量,每个位是关键点周围给定像素对之间的强度比较的结果。 尽管BRIEF描述符在尺度和旋转方面几乎不具备不变性,我们的实验表明它们在平面相机运动下的闭环检测非常稳健,这是移动机器人常见的情况,同时在区分度/辨别性(distinctiveness)和计算时间之间取得了良好的平衡。
我们引入了一种将二进制空间离散化的词袋,并在常规逆向索引(usual inverse index)的基础上增加(augment)了一个直接索引,如第四节所述。据我们所知,这是首次使用二进制词汇进行闭环检测。 逆向索引用于快速检索与给定图像可能相似的图像。我们展示了直接索引的新颖用法,可以高效地获取图像之间的点对应关系,在闭环(回环)验证过程中加速几何检查。
完整的循环(回环)检测算法在第五节中详细介绍。与我们之前的工作[5,6]类似,为了确定循环(回环)已经闭合,我们验证了图像匹配的时间一致性(temporal consistency)。 本文的一个创新之处是一种技术,用于在查询数据库时防止收集到的相同地点的图像相互竞争。 我们通过将匹配过程中描绘相同地点的图像进行分组来实现这一点。
第六节描述了我们工作的实验评估,包括对算法不同部分的相对优点的详细分析。 我们对BRIEF和两个版本的SURF特征[11]的有效性进行了比较,SURF特征是用于闭环检测的最常用描述符。 我们还分析了循环验证中的时间和几何一致性测试的性能。 在评估了五个公共数据集中的长达0.7-4千米的轨迹后,我们最终呈现了我们的技术取得的结果。 我们证明我们可以在26300张图像中以52毫秒的速度运行整个循环检测过程,包括特征提取(平均每张图像22毫秒),比之前的技术提升了一个数量级以上。
这项工作的初步版本在[12]中提出。 在当前论文中,我们改进了直接索引技术,并扩展了我们方法的实验评估。 我们还在新的数据集上报告了结果,并与最先进的FAB-MAP 2.0算法[13]进行了比较。
二、相关工作
基于外观的地点识别在机器人学界引起了极大的关注,因为取得了出色的结果[4,5,13,14]。 其中一个例子是FAB-MAP系统[1
3],它使用全向相机( omnidirectional camera)检测循环,获得了70公里和1000公里轨迹上的48.4%和3.1%的召回率,没有误报。 FAB-MAP使用词袋表示图像,并使用Chow Liu树离线学习词的共现概率(co-visibility probability)。 FAB-MAP已成为循环检测的黄金标准,但当图像长时间呈现非常相似的结构时,其鲁棒性会降低,这在使用前置摄像头时可能会发生[5]。 在Angeli等人的工作中[4],两个视觉词汇(外观和颜色)以增量方式在线创建。 这两种词袋表示一起作为贝叶斯滤波器的输入,估计两个图像之间的匹配概率,同时考虑先前情况的匹配概率。与这些概率方法相比,我们依靠时间一致性检查来考虑先前的匹配,并增强检测的可靠性。 这种技术在我们之前的工作中已经取得了成功[5,6]。我们的工作与上述工作的不同之处在于,我们首次使用了二进制词袋,并提出了一种技术来防止在匹配过程中时间接近且描绘相同地点的图像之间的竞争,以便我们可以以更高的频率工作。
为了验证闭环候选项,通常会进行几何检查。 我们对最佳匹配的候选项应用了一个极线约束,就像[4]中所做的那样,但我们利用直接索引来更快地计算对应点。Konolige等人[3]也使用视觉里程计和立体相机实时创建环境的视图地图(view map),并采用词袋方法检测闭环,他们的几何检查是计算匹配图像之间的空间变换。然而,他们没有考虑与之前的匹配的一致性,这导致他们将几何检查应用于多个闭环候选项。
在大多数闭环工作[4]–[6,14]中,使用的特征是SIFT [15]或SURF [11]。 它们很受欢迎,因为它们对光照、尺度和旋转变化不变,并且在轻微透视变化下表现良好。 然而,这些特征通常需要花费100到700毫秒的计算时间,正如上述出版物所报道的。 除了GPU实现[16]之外,还有其他类似的特征试图通过近似SIFT描述符[17]或降低维度[18]来减少计算时间。 Konolige等人的工作[3]提供了一个定性的改变,因为它使用了紧凑的随机树签名[19]。 这种方法计算图像块与先前在离线阶段训练的其他块之间的相似性。 图像块的描述符向量通过连接这些相似性值来计算,并且最终通过随机正交投影将其维度降低。 这产生了一个非常快速的描述符,适用于实时应用[19]。 我们的工作与[3]类似,也通过使用高效的特征来减少执行时间。 BRIEF描述符以及其他最近的描述符,如BRISK [20]或ORB [21],都是二进制的,并且计算时间非常短。 作为优势,它们的信息非常紧凑,所以占用的内存更少,比较速度更快。 这使得它们更快地转换为词袋空间。
III. 二进制特征
提取局部特征(关键点和它们的描述向向量)在比较图像时通常非常耗时。 这通常是应用于实时场景时的瓶颈。 为了克服这
个问题,在这项工作中我们使用了FAST关键点[10]和最先进的BRIEF描述符[9]。 FAST关键点是通过比较Bresenham圆半径为3的一些像素的灰度强度来检测的类似角点的点。 由于只检查了少数像素,这些点非常快速地获得,对于实时应用非常成功。
对于每个FAST关键点,我们在它们周围绘制一个正方形补丁,并计算一个BRIEF描述符。 图像补丁的BRIEF描述符是一个二
进制向量,其中每个位是补丁中两个像素之间强度比较的结果。 这些补丁先用高斯核进行平滑以减少噪声。 在离线阶段,根
据补丁的大小 Sb,在补丁中随机选择要测试的像素对。 除了 Sb,我们还必须设置参数 Lb:要执行的测试数量(即描述符的长度)。 对于图像中的一个点 p,它的BRIEF描述符向量 B§由以下给出:

其中 Bi§是描述符的第i位, I(·)是平滑图像中像素的强度, ai和 bi是第i个测试点相对于补丁中心的2D偏移量,取值为:

提前随机选择。 注意这个描述符不需要训练,只需要一个离线阶段来选择随机点,几乎不需要时间。 Calonder等人提出的原始BRIEF描述符[9]选择了每个坐标ai和 bi分根据标准正态分布:

然而我们发现使用接近的测试对会产生更好的结果[12];我们选择这些对的每一个候选项的坐标 j 通过对下列分布采样:

请注意,这种方法也是由[9]提出的,但在他们的最终实验中没有使用。对于描述符长度和补丁大小,我们选择了Lb= 256和 Sb= 48,因为它们在独特性和计算时间之间取得了良好的折衷[12]。
BRIEF描述符的主要优点是计算速度非常快(Calonder等人[9]报告每个关键点的计算时间为 17.3µs,当 Lb= 256位时)。 由于这些描述符之一只是一个位向量,测量两个向量之间的距离可以通过计算它们之间不同位的数量(汉明距离)来完成,这是通过异或操作实现的。
在这种情况下,使用二进制词袋从FAST+BRIEF特征中比计算欧氏距离更加合适,而不是像SIFT或SURF描述符那样通常使用浮点数值。
IV. 图像数据库
为了检测重访的地点,我们使用一个由分层词袋(hierarchical bag of words)[7,8]、直接和逆向索引组成的图像数据库,如图1所示。

词袋是一种技术,它使用视觉词汇将图像转换为稀疏的数值向量,从而可以管理大量的图像。 视觉词汇是离线创建的,通过将描述符空间离散化为 W个视觉词。 与SIFT或SURF等其他特征不同,我们将二进制描述符空间离散化,从而创建一个更紧凑的词汇表。 在分层词袋的情况下,词汇表被构造为一棵树。 为了构建它,我们从一些训练图像中提取出丰富的特征,与之后在线处理的图像无关。 首先,我们将提取出的描述符通过k-medians聚类和k-means++种子方法[22]进行离散化为 kw个二进制簇。 导致非二进制值的中位数被截断为 0。 这些簇形成了词汇树中的第一层节点。 通过重复这个操作,使用与每个节点相关联的描述符,创建后续的层级,最多重复 Lw次。 最终我们得到一棵有 W个叶子节点的树,这些叶子节点就是词汇表中的词。 每个词根据其在训练语料库中的相关性被赋予权重,减小那些非常频繁且不具有区分性的词的权重。


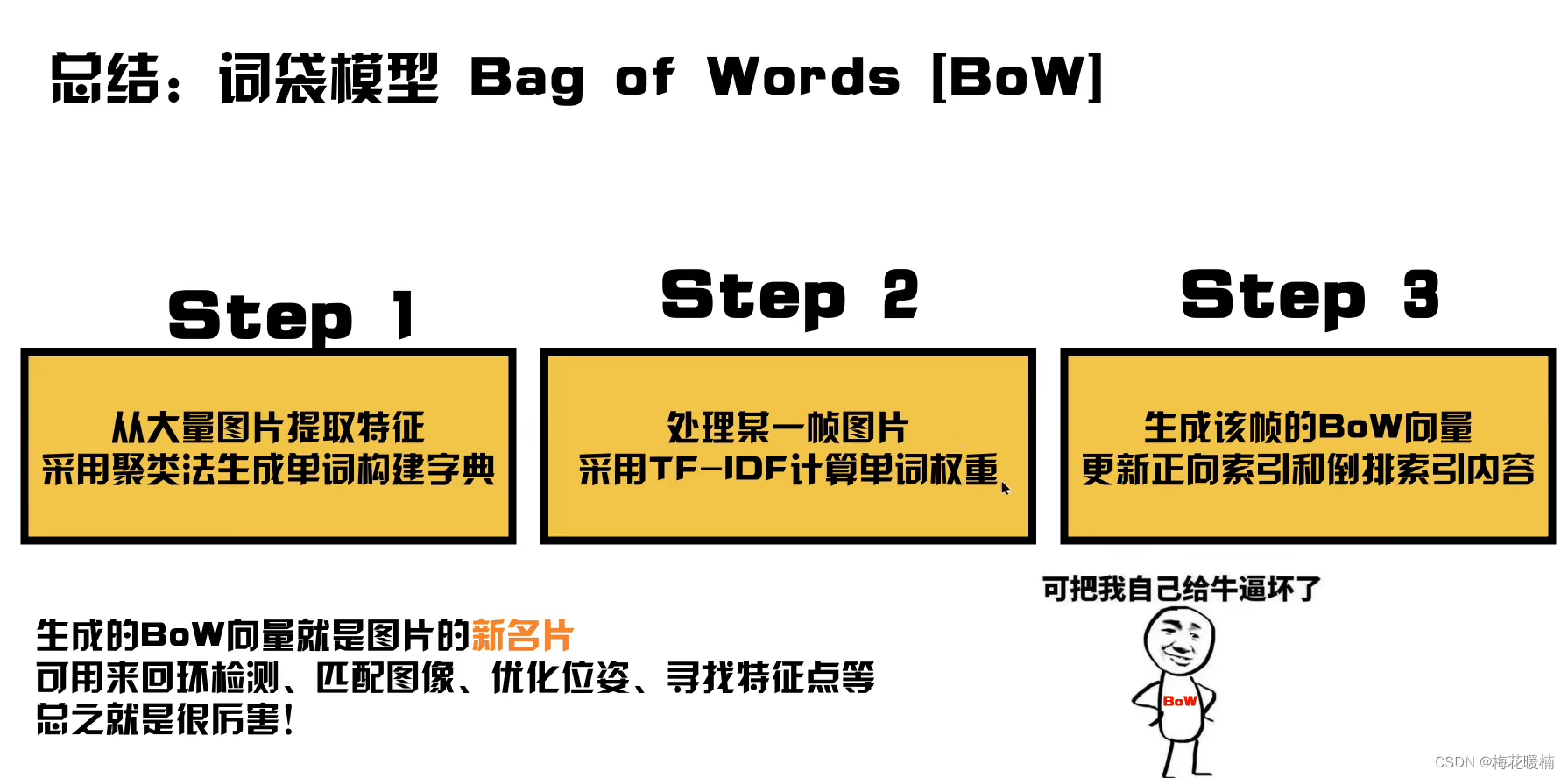
为此,我们使用术语频率-逆文档频率(tf-idf),如[7]所提出的。 然后,为了将在时间t拍摄的图像I转换为一个属于的词袋向量vt属于RW,其特征的二进制描述符通过从根节点到叶节点的树遍历来选择在每个级别上,选择最小化汉明距离的中间节点。为了衡量两个词袋向量v1和v2之间的相似性,我们计算一个L1-score s(v1,v2),其值位于[0,1]之间:

除了词袋之外,还维护了一个逆索引。 这个结构为词汇表中的每个单词wi存储了一个图像I的列表(这个列表列出了出现该单词的图像)。,当查询数据库时,这非常有用,因为它只允许对那些与查询图像有一些共同单词的图像进行比较。 我们扩展了逆索引,以存储<It, vti>对,以便快速访问图像中单词的权重。当向数据库添加新图像It时,逆索引会进行更新,并在搜索数据库中的某个图像时进行访问。
这两个结构(词袋和逆索引)通常是在搜索图像的词袋方法中唯一使用的。 然而,在这种通用方法中,我们还使用直接索引来方便地存储每个图像的特征。我们根据词汇表中节点的级别 (小L)将其分开,从叶子开始,级别 l= 0,直到根节点,级别l = Lw。 对于每个图像 It,我们在直接索引中存储级别 l的祖先节点,这些节点是 It中存在的单词的祖先节点,以及与每个节点相关联的局部特征列表 ftj。 我们利用直接索引和词袋树来近似BRIEF描述符空间中的最近邻。直接索引可以通过仅计算属于相同单词或具有共同祖先节点的单词之间的对应关系来加速几何验证。 当向数据库添加新图像时,直接索引会进行更新,并在获取候选匹配并进行几何检查时进行访问。
闭环检测算法
为了检测闭环,我们使用的方法基于我们之前的工作【5,6】,遵循下面的步骤,详述如下:
A、数据库查询
我们使用图像数据库来存储和检索与给定图像相似的图像,当最后一个图像It被获取时,它被转换成词袋向量vt,在数据库中为词袋向量vt进行搜索,得到一组匹配候选项:

并计算每个匹配项的分数(权重)s(vt,vtj)。这些分数的范围很大程度上取决于查询图像和它包含的词的分布,然后,我们将这些分
数与我们在该序列中期望获得的最佳分数进行归一化,得到归一化相似度分数 η [6]:

在这里,我们用s( vt,vt−∆t)来近似估计 vt的期望得分,其中,vt−∆t是上一张图像的词袋向量,那些s(vt−∆t)较小的情况,(例如机器人转弯时)可能会导致错误地得到高分(应该是低分吧),因此,我们跳过那些未达到最小s(vt−∆t)或者所需特征数量的图像。
第七章结论
我们提出了一种新颖的技术来检测单目序列中的循环。 我们
的工作的主要结论是二进制特征在词袋方法中非常有效和高效
。 特别是,我们的结果表明,FAST+BRIEF特征在解决平面相
机运动下的循环检测问题上与SURF(无论是64维还是128维且无
旋转不变性)一样可靠,这是移动机器人中的常见情况。 执行
时间和内存需求减少了一个数量级,而不需要特殊硬件。
我们的提案的可靠性和效率已经在五个非常不同的公共数据
集上得到了验证,这些数据集描述了室内、室外、静态和动态
环境,使用正面或侧面摄像头。 与大多数以前的工作不同,为
了避免过度调整,我们限制自己只使用相同的词汇表(从独立
数据集中获得)和相同的参数配置(从一组训练数据集中获得
),而不查看评估数据集。 因此,我们可以声称我们的系统在
各种真实情况下都提供了稳健和高效的性能,而无需任何额外
的调整。
我们技术的主要限制是使用了缺乏旋转和尺度不变性的特征
。 对于室内和城市机器人的地点识别来说已经足够了,但对于
全地形或空中车辆、人形机器人、可穿戴摄像头或物体识别来
说显然不够。
然而,我们对二进制词袋方法的有效性进行的演示为使用新的
有前景的二进制特征(如ORB [21]或BRISK [20])铺平了道路,
这些特征在计算时间上优于SIFT和SURF,并保持了旋转和尺度
不变性。















 5011
5011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









