









DBoW2个人学习笔记
概述
DBoW2来源于论文Bags of Binary Words for Fast Place Recognition in Image Sequences,如果没看错,是ORB_SLAM2的作者同门师兄的一作(学术近亲繁(long)殖(duan))这样真的好嘛~~
总的来说,DBoW2是一个对大量训练图像使用fast关键点+BRIEF描述子的方法提取特征,再将大量特征做K-mean++聚类形成一棵词典树的模型。词典离线建立好之后,在实际应用过程之中,将每一幅待处理图像提取特征与词典树中的描述子相比较得到一些索引,从而可以提高搜索相似图像和得到图像之间特征匹配的效率。(待改)
Fast关键点和BRIEF描述子
Fast关键点是在图像之中像素点周围,选取半径为3的Breseham圆,选取之上的部分像素点,与初始像素点做灰度比较,找到灰度值差别较大的类角点(corner-like point)。
BRIEF描述子是以Fast关键点为原点,选择固定大小的patch,如长宽均为为Sb,则有描述子B(p)计算公式如下:
B i(p):BRIEF描述子的第i位。
I(·):高斯平滑处理之后的图像的像素的灰度。
a i&b i:第i个待测点距离patch中心的2-D偏移,取值范围为 [−Sb2…Sb2]×[−Sb2…Sb2] [ − S b 2 … S b 2 ] × [ − S b 2 … S b 2 ] ,值实现随机取好。
L b:描述子长度(DBoW2取L b为256,S b为48)。
简而言之,BRIEF描述子是一个长度为256的二进制串。
词典树结构及其所对应数据结构
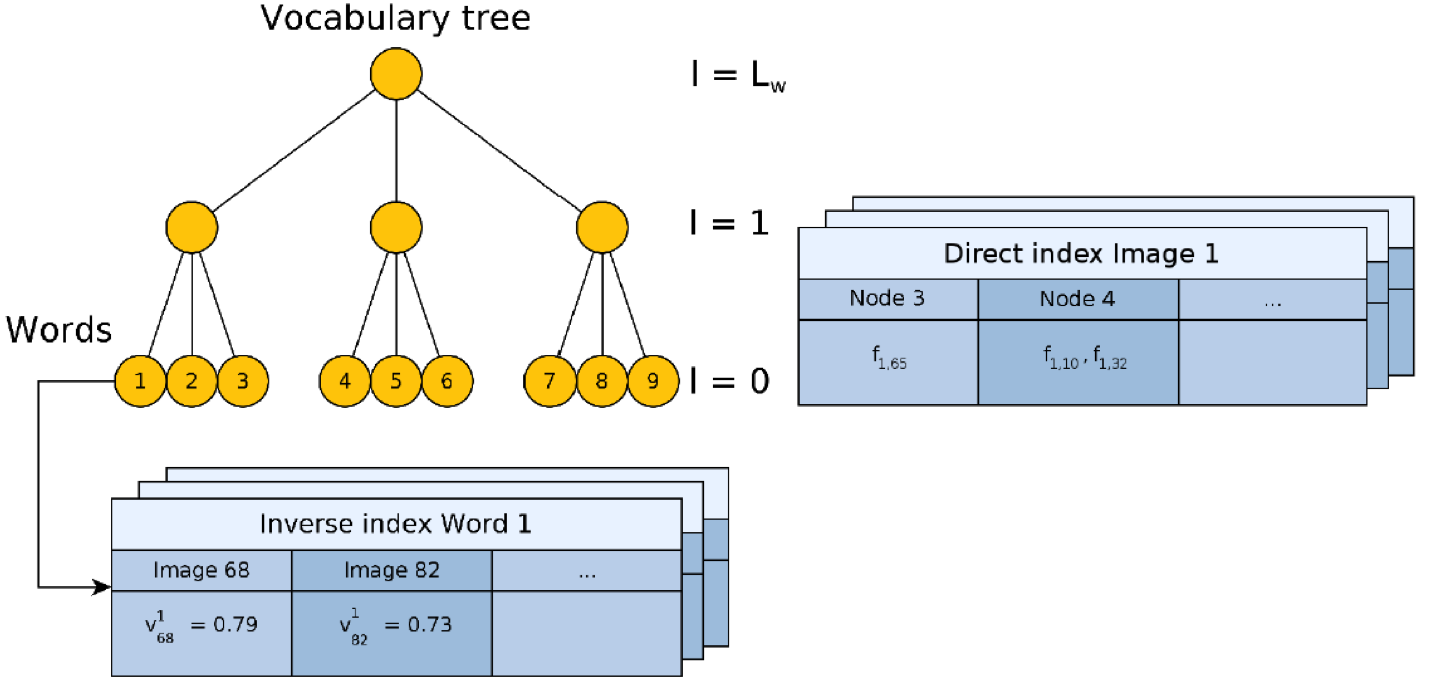
基于大量训练图像形成的丰富描述子(特征)使用聚类方法构造一棵词典树。
1.从根节点开始使用K-means++聚类方法,聚kw类。
2.对于下面的每一个节点聚类,同样聚kw类。
3.聚类Lw层,结束,形成W个叶子节点。
节点关联的直接索引和word关联的倒排索引。
词典树的查找过程
还有些问题,//TODO
ORB_SLAM2中的应用
在这里,以Frame类和KeyFrame类中的成员函数ComputeBoW()进行分析。
函数代码如下:
//每个frame类里都有三个关于词袋的成员变量
ORBVocabulary* mpORBvocabulary;//使用的字典的指针,字典用于全局重定位和闭环检测
DBoW2::BowVector mBowVec;//bag of words vector
DBoW2::FeatureVector mFeatVec;//feature vectorvoid Frame::ComputeBoW()
{
if (mBowVec.empty())
{
vector<cv::Mat> vCurrentDesc = Converter::toDescriptorVector(mDescriptors);//把mDescriptors pushback 到 currentDesc中
mpORBvocabulary->transform(vCurrentDesc, mBowVec, mFeatVec, 4); //当前描述子转换为词袋向量和节点与索引的特征向量,4代表字典树中的从叶子节点向上数的第4层,见下段代码中的注释。
}
}void KeyFrame::ComputeBoW()
{
if(mBowVec.empty() || mFeatVec.empty())
{
vector<cv::Mat> vCurrentDesc = Converter::toDescriptorVector(mDescriptors);
// Feature vector associate features with nodes in the 4th level (from leaves up)
// We assume the vocabulary tree has 6 levels, change the 4 otherwise
mpORBvocabulary->transform(vCurrentDesc,mBowVec,mFeatVec,4);
}
}
BowVec就是描述一张图像的一系列视觉词汇,视觉词汇的id和它的权重值
FeatVec就是节点的id和节点拥有的特征数目。
ORB_SLAM2中,主要使用DBoW2用来做重定位和闭环检测
以闭环检测为例,代码比较长,但是其实主要使用了计算词袋向量相似性的score函数,作为筛选关键帧的依据而已。
vector<KeyFrame*> KeyFrameDatabase::DetectLoopCandidates(KeyFrame* pKF, float minScore)
{
set<KeyFrame*> spConnectedKeyFrames = pKF->GetConnectedKeyFrames();
list<KeyFrame*> lKFsSharingWords;
// Search all keyframes that share a word with current keyframes
// Discard keyframes connected to the query keyframe
{
unique_lock<mutex> lock(mMutex);
//class BowVector:
// public std::map<WordId, WordValue>
for(DBoW2::BowVector::const_iterator vit=pKF->mBowVec.begin(), vend=pKF->mBowVec.end(); vit != vend; vit++)
{
//找到和当前关键帧有共同视觉词汇的关键帧
list<KeyFrame*> &lKFs = mvInvertedFile[vit->first];// std::vector<list<KeyFrame*> > mvInvertedFile;
for(list<KeyFrame*>::iterator lit=lKFs.begin(), lend= lKFs.end(); lit!=lend; lit++)
{
//遍历这些和当前关键帧有共同视觉词汇的关键帧,如果不属于与当前关键帧相连的关键帧,就把这些关键帧加入到一个vector中,叫做lKFsSharingWords
KeyFrame* pKFi=*lit;
if(pKFi->mnLoopQuery!=pKF->mnId)
{
pKFi->mnLoopWords=0;
if(!spConnectedKeyFrames.count(pKFi))
{
pKFi->mnLoopQuery=pKF->mnId;
lKFsSharingWords.push_back(pKFi);
}
}
pKFi->mnLoopWords++;
}
}
}
if(lKFsSharingWords.empty())
return vector<KeyFrame*>();
list<pair<float,KeyFrame*> > lScoreAndMatch;
// Only compare against those keyframes that share enough words
//在lKFsSharingWords中有一些关键帧,与当前关键帧有共同的视觉词汇,最多的数目为maxCommonWords,再乘0.8为minCommonWords
int maxCommonWords=0;
for(list<KeyFrame*>::iterator lit=lKFsSharingWords.begin(), lend= lKFsSharingWords.end(); lit!=lend; lit++)
{
if((*lit)->mnLoopWords>maxCommonWords)
maxCommonWords=(*lit)->mnLoopWords;
}
int minCommonWords = maxCommonWords*0.8f;
int nscores=0;
// Compute similarity score. Retain the matches whose score is higher than minScore
//在有共同视觉词汇的关键帧中,找到词袋向量与关键帧的词袋向量比较的score大于minScore的关键帧,保留其score,共同放入list<pair<float,KeyFrame*> >lScoreAndMatch
for(list<KeyFrame*>::iterator lit=lKFsSharingWords.begin(), lend= lKFsSharingWords.end(); lit!=lend; lit++)
{
KeyFrame* pKFi = *lit;
if(pKFi->mnLoopWords>minCommonWords)
{
nscores++;
float si = mpVoc->score(pKF->mBowVec,pKFi->mBowVec);
pKFi->mLoopScore = si;
if(si>=minScore)//minScore是寻找闭环的参数,是词袋向量之间比较得到的分值。
lScoreAndMatch.push_back(make_pair(si,pKFi));
}
}
if(lScoreAndMatch.empty())
return vector<KeyFrame*>();
list<pair<float,KeyFrame*> > lAccScoreAndMatch;
float bestAccScore = minScore;
// Lets now accumulate score by covisibility
//在与当前关键帧有共同的视觉词汇,且词袋之比值评分大于minScore的关键帧中,继续挑选,通过共视关系,选出10个共视的最好的关键帧,然后继续积累score值,找到一个比较好的,用作阈值的标杆
for(list<pair<float,KeyFrame*> >::iterator it=lScoreAndMatch.begin(), itend=lScoreAndMatch.end(); it!=itend; it++)
{
KeyFrame* pKFi = it->second;
vector<KeyFrame*> vpNeighs = pKFi->GetBestCovisibilityKeyFrames(10);
float bestScore = it->first;
float accScore = it->first;
KeyFrame* pBestKF = pKFi;
for(vector<KeyFrame*>::iterator vit=vpNeighs.begin(), vend=vpNeighs.end(); vit!=vend; vit++)
{
KeyFrame* pKF2 = *vit;
if(pKF2->mnLoopQuery==pKF->mnId && pKF2->mnLoopWords>minCommonWords)
{
accScore+=pKF2->mLoopScore;
if(pKF2->mLoopScore>bestScore)
{
pBestKF=pKF2;
bestScore = pKF2->mLoopScore;
}
}
}
lAccScoreAndMatch.push_back(make_pair(accScore,pBestKF));
if(accScore>bestAccScore)
bestAccScore=accScore;
}
// Return all those keyframes with a score higher than 0.75*bestScore
float minScoreToRetain = 0.75f*bestAccScore;
set<KeyFrame*> spAlreadyAddedKF;
vector<KeyFrame*> vpLoopCandidates;
vpLoopCandidates.reserve(lAccScoreAndMatch.size());
for(list<pair<float,KeyFrame*> >::iterator it=lAccScoreAndMatch.begin(), itend=lAccScoreAndMatch.end(); it!=itend; it++)
{
if(it->first>minScoreToRetain)//卡一个阈值
{
KeyFrame* pKFi = it->second;
if(!spAlreadyAddedKF.count(pKFi))//没有重复出现过的
{
vpLoopCandidates.push_back(pKFi);//得到最后的闭环候选帧的集合
spAlreadyAddedKF.insert(pKFi);
}
}
}
return vpLoopCandidates;
}














 2126
2126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









