







DBoW2是一种高效的回环检测算法,DBow2算法的全称为Bags of binary words for fast place recognition in image sequence,使用的特征检测算法为Fast,描述子为BRIEF描述子,是一种离线方法。
算法流程
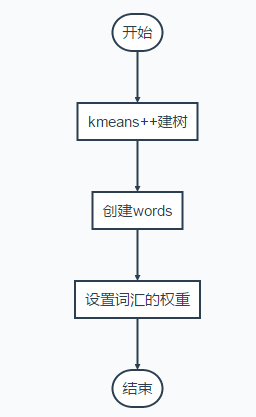
Bag of Words字典建立方法(最终得到的就是每一层的不同类的median,每一个叶子节点对应的就是一个词汇)
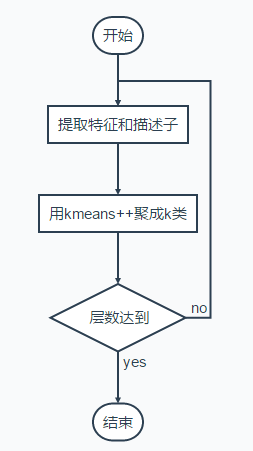
建树流程
权重设置
权重设置用的是idf,意思是词汇在训练过程中出现的频率越高,区分度越低,因此权重越低
idf=logNni
每一个节点包含
struct Node
{
//在所有节点中的标号
NodeId id;
//该节点的权重,该权重为
//训练的过程中设置的,在得到了树之后,
//所有的描述子过一遍树,得到每一个单词出现
//的次数,除以总的描述子数目
WorldValue weight;
//描述符,为每一类的均值(对于brief描述子,则要对均值进行二值化)
TDescriptor descriptor;
//如果有叶节点,则有词汇的ID
WordID word_id;
}上面的方法是分层聚类的,每一次聚类得到的多个节点,都有median v表示该类,可以用来判断新的词汇是否属于该类。最终建立的树包括W个叶节点,也就是W个视觉词汇,词汇也用median表示。
视觉词典
DBoW2库采用树状结构存储词袋,搜索复杂度在log(N)。每个叶节点被赋予一个权重,默认为TF-IDF。
TF-IDF主要思想是:如果某个词或短语在一片文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类.TF-IDF实际上是TF*IDF,TF代表词频(Term Frequency),表示词条在文档d中的出现频率.IDF代表逆向文件频率(Inverse Document Frequency)。如果包含词条t的文档越少,IDF越大,表明词条t具有很好的类别区分能力。
第k个叶节点的TF和IDF分别定义为
IDFk=lognumber of all imagesnumber of images reach k−th leaf node
TFk=lognumber of features locates in leaf node knumber of all features
视觉词典可以通过离线训练大量数据得到。训练中只计算和保存单词的IDF值,即单词在众多图像中的区分度。TF则是从实际图像中计算得到各个单词的频率。单词的TF越高,说明单词在这幅图像中出现的越多;单词的IDF越高,说明单词本身具有高区分度。二者结合起来,即可得到这幅图像的BoW描述。
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor, F>::create(
const std::vector<std::vector<TDescriptor> > &training_features, // 图像特征集合
int k, // 每层的类的个数
int L, // 树的层数
WeightingType weighting, //权重类型,默认为TF-IDF
ScoringType scoring) // 得分的类型,默认为L1-norm
{
m_nodes.clear();
m_words.clear();
//节点数 = Sum_(i=0..L) (k^i)
int expected_nodes = (int)((pow((double)m_k,(double)m_L + 1) - 1) / (m_k - 1));
m_nodes.reserve(expected_nodes);
//将所有特征描述集合到一个vector
std::vector<pDescriptor> features;
getFeature(training_features, features);
//生成根节点
m_nodes.push_back(Node(0)); //root
//k-means++ (内有递归)
HKmeansStep(0, features, 1);
//建立一个只有叶节点的序列m_words
createWords();
//为每一个叶节点生成权重,此处计算IDF部分,如果不用IDF,则为1
setNodeWeights(training_features)
}
/*k-means++过程*/
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor, F>::HKmeansStep(
NodeId parent_id, // 父节点ID
const std::vector<pDescriptor> &descriptor, // 该父节点对应的描述集合
int current_level // 当前层数)
{
if(descriptors.empty()) return;
//用来储存子节点的特征描述
std::vector<TDescriptor> clusters;
//用来储存每一个子节点对应的特征描述在descriptor向量中的id
std::vector<std::vector<unsigned int > groups; //groups[i] = {j1, j2, ...}
// j1, j2 ... indices of descriptors associated to cluster 1
clusters.reserve(m_k);
group.reserve(m_k);
//如果特征描述个数小于m_k,直接分类
if((int)descriptors.size() <= m_k)
{
groups.resize(descriptors.size());
for(unsigned int i = 0; i < descriptors.size(); i++)
{
groups[i].push_back(i);
clusters[i].push_back(*descriptors[i]);
}
}
else
{
//k_means分类
bool first_time = true;
bool goon = true;
//用来检测迭代过程中前后两次分类结果是否一致,如果一致,分类结束
std::vector<int> last_association, current_association;
//迭代过程
while(goon)
{
// 1. 分类
if(first_time)
{
//第一次分类,初始化分类
initiateClusters(descriptors, clusters);
}
else
{
//计算每一类的meanValue
for(unsigned int c = 0; c < clusters.size(); c++)
{
std::vector<pDescriptor> cluster_descriptors;
cluster_descriptors.reserve(groups[c].size());
//利用group,读取每一类对应的id
std::vector<unsigned int>::const_iterator vit;
for(vit = groups[c].begin(); vit != groups[c].end(); ++vit)
{
cluster_descriptors.push_back(descriptors[*vit]);
}
//计算meanValue
F::meanValue(cluster_descriptors, clusters[c]);
}
}
// 2. 利用1计算的中心重新分类
groups.clear();
groups.resize(clusters.size(), std::vector<unsigned int>());
current_association.resize(descriptors.size());
typename std::vector<pDescriptor>::const_iterator fit;
//对每一个特征,计算它与k个中心特征的距离,标记距离最小的中心特征的id
for(fit = descriptors.begin(); fit != descriptors.end(); ++fit)
{
double best_dist = F::distance(*(*fit)), clusters[0]);
undigned int icluster = 0;
for(unsigned int c = 1; c < clusters.size(); ++c)
{
double dist = F::distance(*(*fit), clusters[c]);
if(dist < best_dist)
{
best_dist = dist;
icluster = c;
}
}
//记录分类信息
groups[icluster].push_back(fit - descriptors.begin());
current_association[fit - descriptors.begin()] = icluster;
}
//k-means++ ensures all the clusters has any feature associated with them
//3 . 检测前后两次分类结果是否一致,如一致,分类结束
if(first_time)
first_time = false;
else
{
goon = false;
for(unsigned int i = 0; i < current_association.size(); i++)
{
if(current_association[i] != last_association[i])
goon = true;
break;
}
}
if(goon)
{
last_association = current_association;
}
}
//生成本层的节点,其特征描述为每一类的meanValue
for(unsigned int i = 0; i < clusters.size(); ++i)
{
NodeId id = m_nodes.size();
m_nodes.push_back(Node(id));
m_nodes.back().descriptor = clusters[i];
m_nodes.back().parent = parent_id;
m_nodes[parent_id].children.push_back(id);
}
// go on with the next level
if(current_level < m_L)
{
// iterate again with the resulting clusters
const std::vector<NodeId> &children_ids = m_nodes[parent_id].children;
for(unsigned int i = 0; i < clusters.size(); ++i)
{
NodeId id = children_ids[i];
std::vector<pDescriptor> child_features;
child_features.reserve(groups[i].size());
std::vector<unsigned int>::const_iterator vit;
for(vit = groups[i].begin(); vit != groups[i].end(); ++vit)
{
child_features.push_back(descriptors[*vit]);
}
//进入下一层,继续分类
if(child_features.size() > 1)
{
HKmeansStep(id, child_features, current_level + 1);
}
}
}
}















 2122
2122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









