









 本文分析了塞罕坝林场对生态环境、防沙能力及北京气候的影响,建立数学模型进行量化评估。通过熵权法确定指标权重,发现森林覆盖率和面积对环境改善有显著作用。模型还探讨了将塞罕坝模式扩展至全国和印度的可能性,以应对碳排放和建设生态保护区。
本文分析了塞罕坝林场对生态环境、防沙能力及北京气候的影响,建立数学模型进行量化评估。通过熵权法确定指标权重,发现森林覆盖率和面积对环境改善有显著作用。模型还探讨了将塞罕坝模式扩展至全国和印度的可能性,以应对碳排放和建设生态保护区。
2021年亚太杯APMCM数学建模大赛
C题 生态保护的建设及其对环境影响的评价
为方便各位阅览及了解掌握亚太杯的写作技巧,这里非技术使用中文,公式部分由于翻译过程繁琐使用英文来撰写此文章,由不知名同学传稿
原题再现:
中国坚持清澈、青山是宝贵资产的理念,坚持尊重、和谐保护自然,优先节约资源,保护环境、让自然恢复,实施可持续发展战略,完善生态文明领域整体协调机制,建设生态文明体系,促进经济社会发展向全面绿色增长转型,建设美丽国家。在中国政府的帮助下,中国的塞罕坝林场已从沙漠中恢复过来,现已成为具有防沙功能稳定的环保、绿色农场。
自1962年以来,有369名平均年龄在24岁以下的年轻人来到这片布满沙土的荒地。从那时起,他们在这里献出了自己的生命,一波又一波,在沙子里种植种子,在石头的缝隙里种植绿色,就像钉子钉着荒地上数百万英亩的森林。他们植树来固定沙子和保护水源,建造一个绿色屏障来阻挡风和沙子。目前,塞罕坝地区的森林覆盖率已达到80% 。它每年向北京和天津提供1.37亿立方米的清洁水,封存74.7万吨碳,排放54.5万吨氧
经过半个多世纪的斗争,世界上最大的人工林建在塞罕坝的地球上。扩大造林112万亩,树木4亿多棵,在北京以北400公里的高原荒地上形成了一片绿地。一方面,“文明发展,动物学繁荣”是历史使命。另一方面,在绿色发展的道路上也遇到了一些新的问题。因此,塞罕坝人现在有了一个更高的目标,即恢复生态。自中共十八届全国代表大会以来,先后启动了植树造林、人工林自然改良、自然林近归化栽培三大重大项目。他们试图使人工森林更接近自然森林。
请由您的团队建立数学模型,并回答以下问题:
1.塞罕坝在抗风抗沙、保护环境、维持生态平衡和稳定等方面起着重要作用。请选择合适的指标,收集相关数据,建立塞罕坝对生态环境影响的评价模型,定量评价塞罕坝恢复后对环境的影响,即对塞罕坝恢复前后的环境条件进行比较分析。
2.塞罕坝林场的恢复对北京抗沙尘暴发挥了重要作用。请选择合适的指标,收集相关数据,建立评价塞罕坝对北京抗沙尘暴能力影响的数学模型,并定量评价塞罕坝在北京抵御沙尘暴中的作用。
3.假设我们计划将塞罕坝的生态保护模型扩展到全国,请建立数学模型并收集相关数据,以确定中国哪些地理位置需要建立生态区域。生态保护区),确定待建设的生态区域数量或规模,评价其对实现中国碳中和目标的影响。
4.中国的塞罕坝生态保护模式为亚太地区树立了榜样。请从亚太地区选择另一个国家建立数学模型,收集相关数据,然后讨论该国需要建设哪个地理位置。生态保护区),以及确定要建设的生态区域的数量或规模;此外,评估其对吸收温室气体和减轻碳排放的影响。
5.请向亚太地区数学竞赛建模组委会(APMCM)撰写一份非技术性报告,描述您的模型,并提出建立生态保护区的可行计划和建议。提示:在建立模型的过程中,可以考虑中国等亚太地区现有生态森林的条件;不同树木的生长环境要求(即特定树木的特定区域);如何平衡生态林地、经济发展用地和工业用地的布局;目标地理区域是否有足够的土地来开发生态保护区。
整体求解过程概述(摘要)
近年来,我国赛罕坝林场从沙漠中恢复过来,现已成为具有稳定防沙功能的环保绿色农场。塞罕坝的成功就是一个很好的例子。研究塞罕坝对北京生态环境的影响,有助于将塞罕坝的优势推广到全国乃至世界。
首先,收集三个指标的评价模型,取对环境保护、气候条件和维持生态平衡最突出的二级指标,采用熵法计算权重,按二级指标加权分别为0.5244、0.1810、0.2945,根据西汉坝3个指标的权重进一步综合得分数据历年; 从历史评分数据曲线的斜率可以看出,塞罕坝的生态环境保护越来越好。
其次,分析了收集到的森林指标森林面积、森林覆盖率和IQA平均值、污染频率和平均风速对北京气候变化有影响。引入了斯皮尔曼相关系数。QQ图谱验证后,森林覆盖率、森林面积与IQA平均值、污染频率和平均风速的相关系数分别为-0.9762、-0.9524和-0.7835。前者与后者的相关系数较大,等级很强,而后者的相关系数不是很大,等级较强,均为严格的线性负相关。可以得出结论,森林覆盖率和覆盖面积的增加与更好的空气质量相对应,减少了沙尘暴对气候的影响。
最后,赛汉坝模式推广到全国和印度。针对碳排放量和森林面积的选定指标,我国基于这两个指标,引入分类模型,利用系统聚类算法找出4种分类方案,结合肘数图得出5个分类,有15个省,北京有1个类,因此有15个省可以建设自然服务。 请参阅地理位置可视化效果的文本。对于印度来说,这种算法也用于获得5个分类方案,其中分类1中的6个城市污染严重,得到这6个城市的经纬度。
本文还总结了该模型,并给出了该模型及其扩展的优缺点。
问题分析:
对于问题1,首先收集塞罕坝的历史数据集,并根据历史数据集建立3个等级指标。建立了一级指标,包括气候条件、环境保护和维护生态平衡,然后根据二级指标建立了13个等级指标。
根据三级指标,引入熵权重法求解三级指标权重,根据指标权重和数据集得到下一个更高级别的指数权重,进而进行权重计算,得到二级指标权重,符合西汉坝近代以来综合评价得分趋势的二级指标权重曲线, 分析环境的变化。
对于问题2,数据分析表明,森林覆盖率和森林面积对塞罕坝的防沙起着决定性作用,而对于气候,影响气候的因素是空气质量、平均风速和重大污染频率。通过相关关系分析模型可以得到塞罕坝森林指数与气候因子之间的斯皮尔曼关联系数,并根据相关系数的数值水平指示因子对气候指数的影响。
对于问题3和问题4,实际上使用了相同的模型,但需要数据挖掘和求解。首先我们分析三个问题,统计我国统计各省碳排放量和省林面积这两个指标的历史,比较分析吸收和排放这两个指标,并根据聚类模型,介绍这两个措施,采取系统聚类算法,与北京市同类聚类, 因此得出结论,需要建立生态保护的选址。对于问题 4,我们只需要再次收集数据并使用相同的算法解决问题。对于选定的国家,我们选择污染严重的国家印度,并进行聚类分析以获得相应的类别并做出一定的分析。
模型假设:
1.假设PM2.5浓度在一定程度上代表了赛罕坝的空气质量,所选数据具有很强的代表性。
2.假设目标地理区域内有足够的土地来开发生态保护区。
3.假设没有考虑自然灾害对塞罕坝的影响。
模型的建立与求解

本文首先挖掘了1962-2021年亚伯拉罕大坝竞赛的森林覆盖率、覆盖面积、树木、节水及二氧化碳吸收量、氧气释放量、降水量、平均温度、平均最低温度、平均最高温度,以及2002-2020年城市空气质量天数、城市PM2.5浓度、地表水质标准率相关指标数据, 我们将这些指标可视化如下:
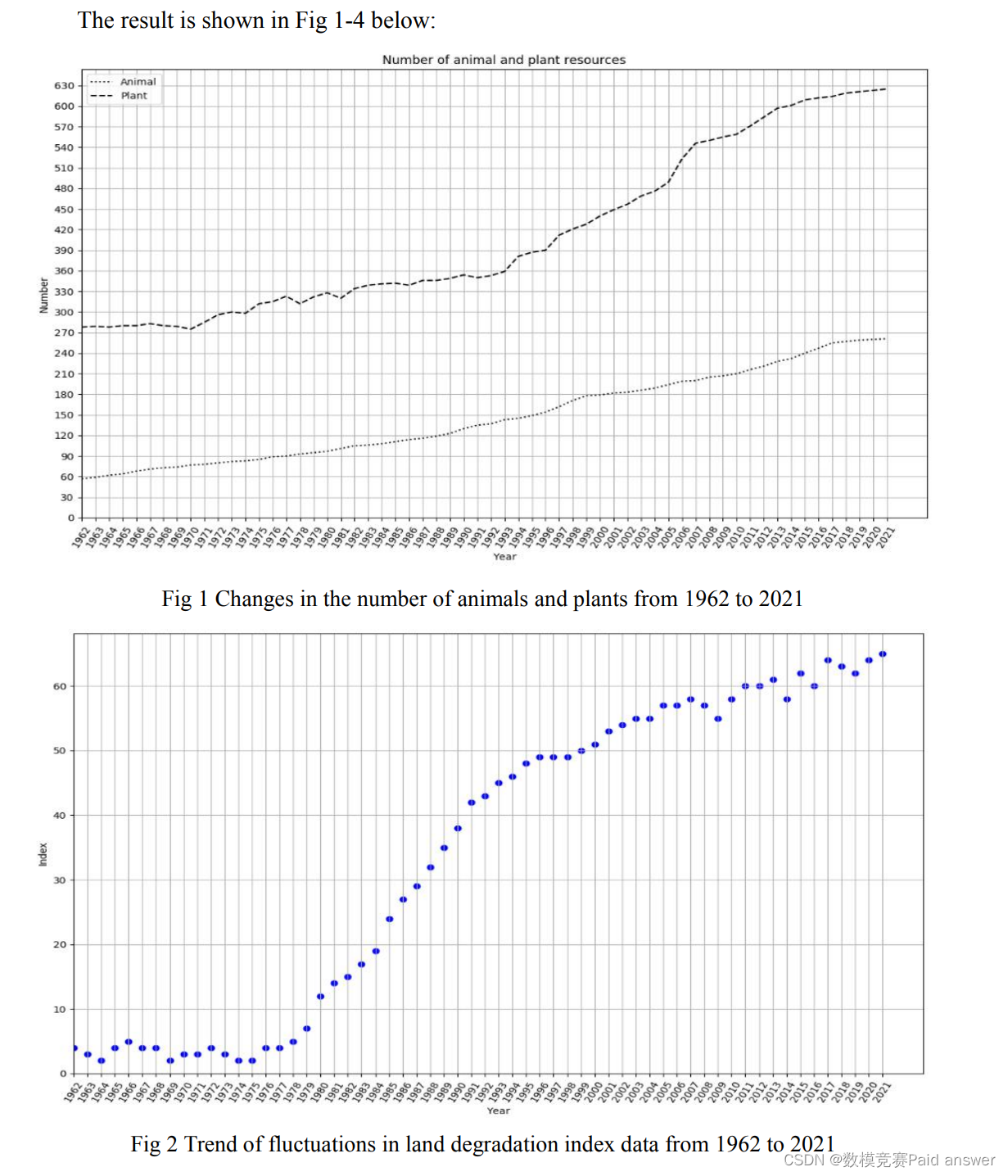
定量评价赛罕坝对生态环境的影响,首先要确定主要影响指标。查阅数据后,可以把环境保护、维持生态平衡和气候变化三大指标作为次要指标。在此基础上,可以分别建立相应的三级指标。根据挖掘的数据,引入熵权重法计算各指标对应的权重,构建综合评价体系,如下图所示:
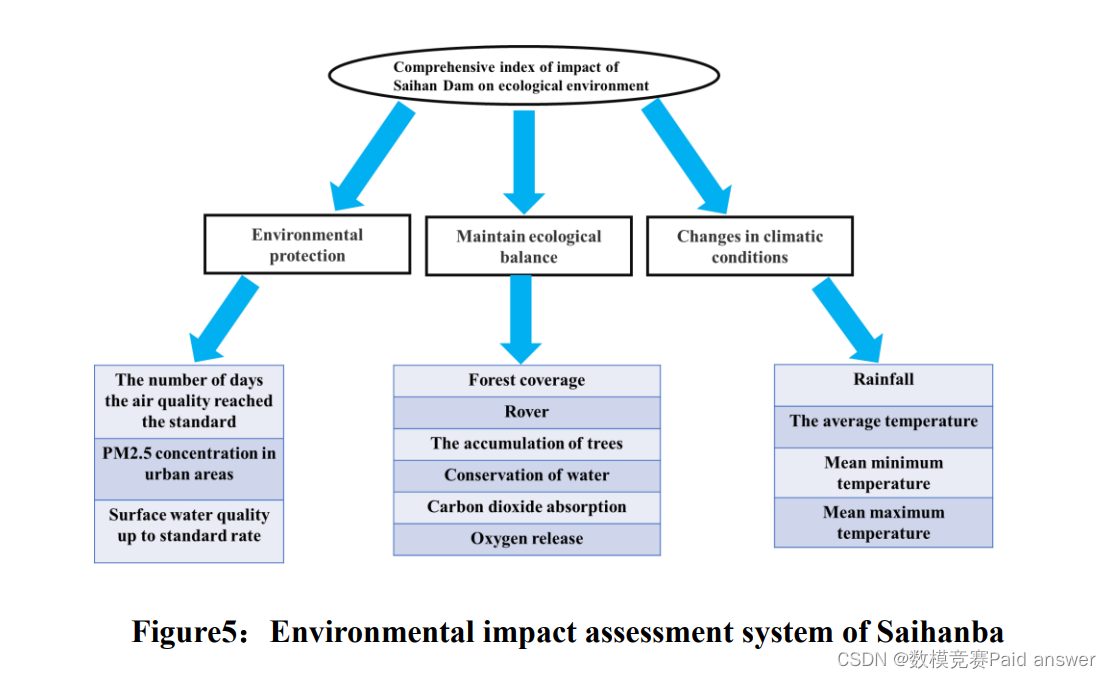
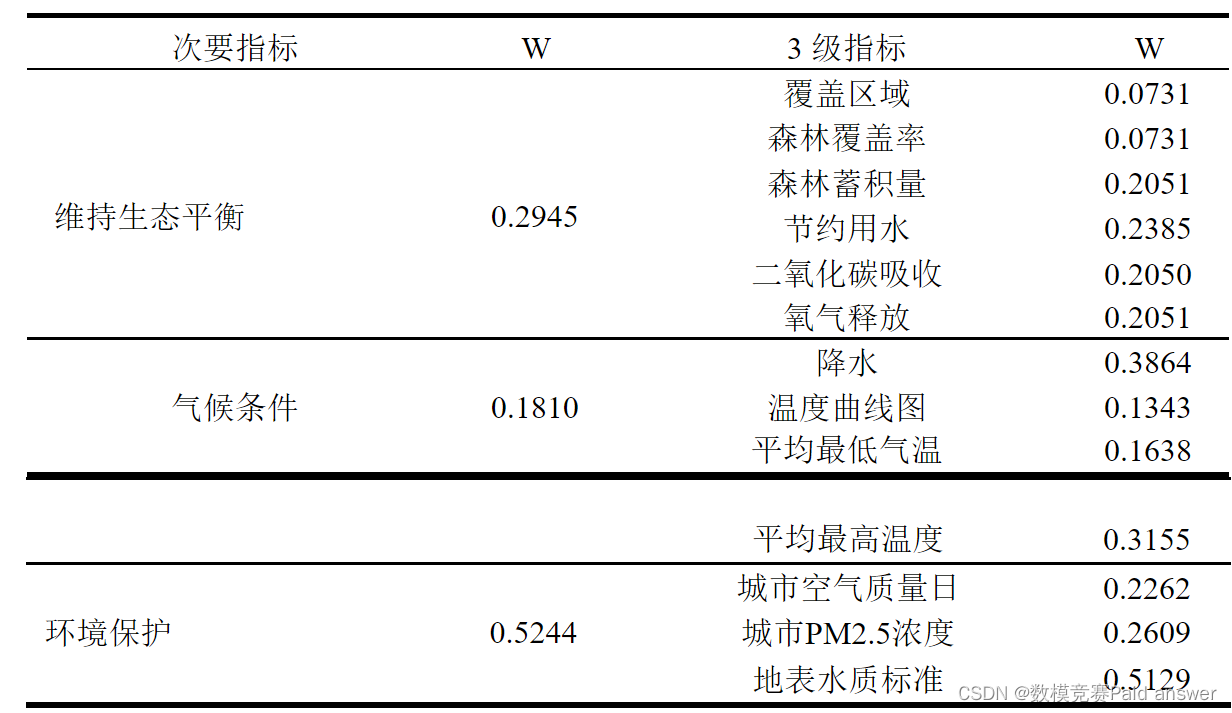
据指数权重表可以得出一些结论:二级指数中权重最大的指数是环境保护,是温度气候条件指数的两倍以上,说明气候条件对环境保护和生态平衡的影响较小,而生态平衡的比例适中。在三个层次指标中,首先,森林蓄水量、水源涵养、二氧化碳吸收、放氧占比较为明显,四大指标占比在20%左右,森林覆盖率和覆盖面积占比较小;其次,降雨量和平均最高气温的比例在30%以上,而平均气温和平均最低气温的比例很小。最后,地表水水质达标比例是城市空气质量达标或城市PM2.5浓度的两倍以上。
解决方案获得的塞罕坝环境影响综合指数得分如下图所示:
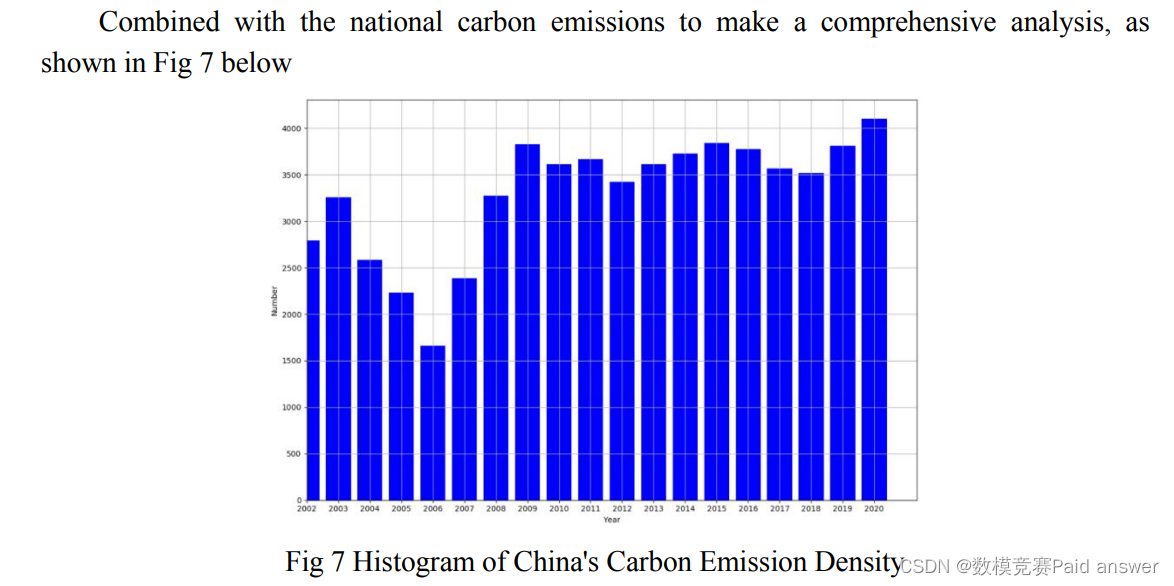
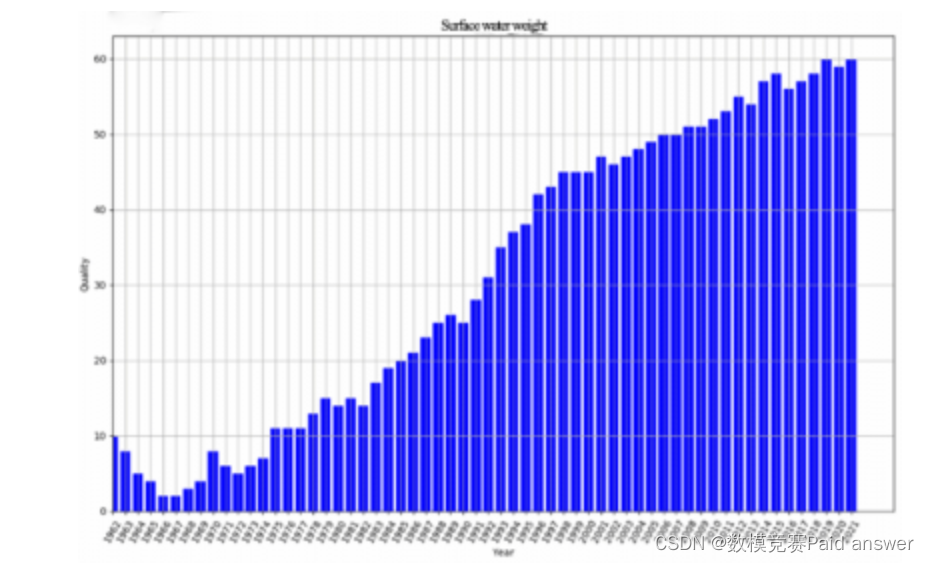
从1962年到1966年,地表水重总体上每年都在下降,只是猜测原因可能是林业建设工作,没有经验和技术支持,引进的幼苗成活率极低,第一年只有5%,第二年只有8%,幼苗死亡的数量也吸收了大量的地表水, 近年来,地表水重量持续下降。1964年以后,【3】大规模造林成功后,新树吸收了部分地表水,直到1967年,高成活的树苗开始影响湿度并引起降雨,地表水重量开始增加。
但从1967年至今,地表水重总体呈上升趋势,在气候和人为因素的影响下,可能还有几年地表水重有所下降,但下降幅度不大。它可以分为三个阶段。在第一阶段,从1967年到1990年,随着树苗和机械供应等技术问题的解决,树木的成活率得到保证,地表水的重量开始提高。【4】1990-2000年地表含水量显著增加,这与1989年颁布的《中华人民共和国环境保护法》的实施密切相关。在政策支持下,加大了对塞罕坝林场建设的投资力度。进入20世纪后,上升趋势逐渐趋于平缓,可能是因为林场的建设模式已经固定,绿色化面积每年都在稳步扩大,因此地表水重量也稳步增加。
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
论文缩略图:



程序代码:
程序代码1
import openpyxl
def dataGet(filename, sheetname):
file2 = openpyxl.load_workbook(filename)
file2training = file2.get_sheet_by_name(sheetname)
data_all = []
for line in file2training.iter_rows(min_row=1, max_row=8, min_col=2, max_col=2):
data = []
for d in line:
data.append(d.value)
data_all.append(data[0])
return data_all
data_all = dataGet('pro4_data.xlsx', 'Sheet1')
from matplotlib import pyplot as plt
from matplotlib.ticker import MultipleLocator
ytic = MultipleLocator(50)
xtic = MultipleLocator(1)
fig = plt.figure(figsize=(12,8))
ax = plt.subplot(1,1,1)
plt.grid()
label = [str(i) for i in range(2013, 2021)]
import numpy as np
plt.bar(np.arange(len(label)), data_all, color='black')
ax.yaxis.set_major_locator(ytic)
ax.xaxis.set_major_locator(xtic)
ax.set_ylim(bottom=0)
ax.set_xlim(left=0)
# plt.xticks(np.arange(len(label)), np.arange(len(label)), rotation=60)
plt.xticks(range(len(label)), label)
plt.xlabel('Year',size=10)
plt.ylabel("Number",size=10)
plt.show()
程序代码2
import openpyxl
def dataGet(filename, sheetname):
file2 = openpyxl.load_workbook(filename)
file2training = file2.get_sheet_by_name(sheetname)
data_all = []
for line in file2training.iter_rows(min_row=1, max_row=34, min_col=1, max_col=4):
data = []
for d in line:
data.append(d.value)
data_all.append(data)
return data_all
data_all = dataGet('area.xlsx', 'Sheet1')
dbs = []
st = []
for item in data_all:
if item[-1]*(1/20) < 1:
dbs.append(1.0)
else:
dbs.append(round(item[-1]*(1/20), 2))
st.append(round(item[-1]*(1/3), 2))
file = openpyxl.load_workbook('pro3_result_data.xlsx')
file_test = file['Sheet1']
columus_data = ['省份', '城市', '区域', '水资源面积', '生态保护区面积']
for i, item in enumerate(columus_data):
file_test.cell(row=1, column=1+i).value = item
file.save("pro3_result_data.xlsx")
def writeData(data, column, index):
for row_index in range(len(data)):
file_test.cell(row=2+row_index, column=column).value = data[row_index][index]
file.save("pro3_result_data.xlsx")
def writeData1(data, column):
for row_index in range(len(data)):
file_test.cell(row=2+row_index, column=column).value = data[row_index]
file.save("pro3_result_data.xlsx")
writeData(data_all, 1, 0)
writeData(data_all, 2, 1)
writeData(data_all, 3, 2)
writeData1(dbs, 4)
writeData1(st, 5)
程序代码3
import openpyxl
def dataGet(filename, sheetname):
file2 = openpyxl.load_workbook(filename)
file2training = file2.get_sheet_by_name(sheetname)
data_all = []
for line in file2training.iter_rows(min_row=2, max_row=20, min_col=2, max_col=2):
data = []
for d in line:
data.append(d.value)
data_all.append(data[0])
return data_all
data_all = dataGet('pro3_data.xlsx', 'Sheet3')
from matplotlib import pyplot as plt
from matplotlib.ticker import MultipleLocator
ytic = MultipleLocator(500)
xtic = MultipleLocator(1)
fig = plt.figure(figsize=(12,8))
ax = plt.subplot(1,1,1)
plt.grid()
label = [str(i) for i in range(2002, 2021)]
import numpy as np
plt.bar(np.arange(len(label)), data_all, color='black')
ax.yaxis.set_major_locator(ytic)
ax.xaxis.set_major_locator(xtic)
ax.set_ylim(bottom=0)
ax.set_xlim(left=0)
# plt.xticks(np.arange(len(label)), np.arange(len(label)), rotation=60)
plt.xticks(range(len(label)), label)
plt.xlabel('Year',size=10)
plt.ylabel("Number",size=10)
plt.show()

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









