










注意力机制推荐阅读:(Attention Mechanism)
- (博客)Squeeze-and-Excitation Networks(2017)
- (知乎)CBAM: Convolutional Block Attention Module
- (知乎)综述:图像处理中的注意力机制
- (期刊)卷积神经网络中的注意力机制综述(2021 计算机工程与应用)
- (博客)综述—图像处理中的注意力机制
2021年11月20日15:54:26
今天来实现CBAM模块,真心建议在使用CBAM前,先学习SE-Net,不然会很难理解!SE-Net不仅仅在CBAM中有使用,在MobileNetV3中也有使用,如果能 熟悉SE模块的话,那么能更快实现相关系列结构。

原文【CBAM: Convolutional Block Attention Module】
会议:(ECCV 2018 paper)
ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议)
摘要:

我们提出了卷积块注意力模块(CBAM),一种简单而有效的卷积神经网络注意力模块。给定一个中间特征映射(feature map),我们的模块沿着两个独立的维度(通道和空间)顺序推断注意映射,然后将注意映射乘以输入特征映射以进行自适应特征细化。因为CBAM是一个轻量级的通用模块,它可以无缝地集成到任何CNN架构中,开销可以忽略不计,并且可以与基础CNN一起进行端到端的训练。我们通过在ImageNet-1K、MS COCO检测和VOC 2007检测数据集上的大量实验来验证我们的CBAM。我们的实验表明,各种模型在分类和检测性能方面都有一致性的提升,证明了CBAM的广泛适用性。代码和模型将公开提供。
- 注意力机制可以告诉你去关注”where“并提高模型表现力
- 关注重要的特性并抑制不必要特性
- 本文采用CBAM模块来强调通道(channel)和空间(spatial)信息
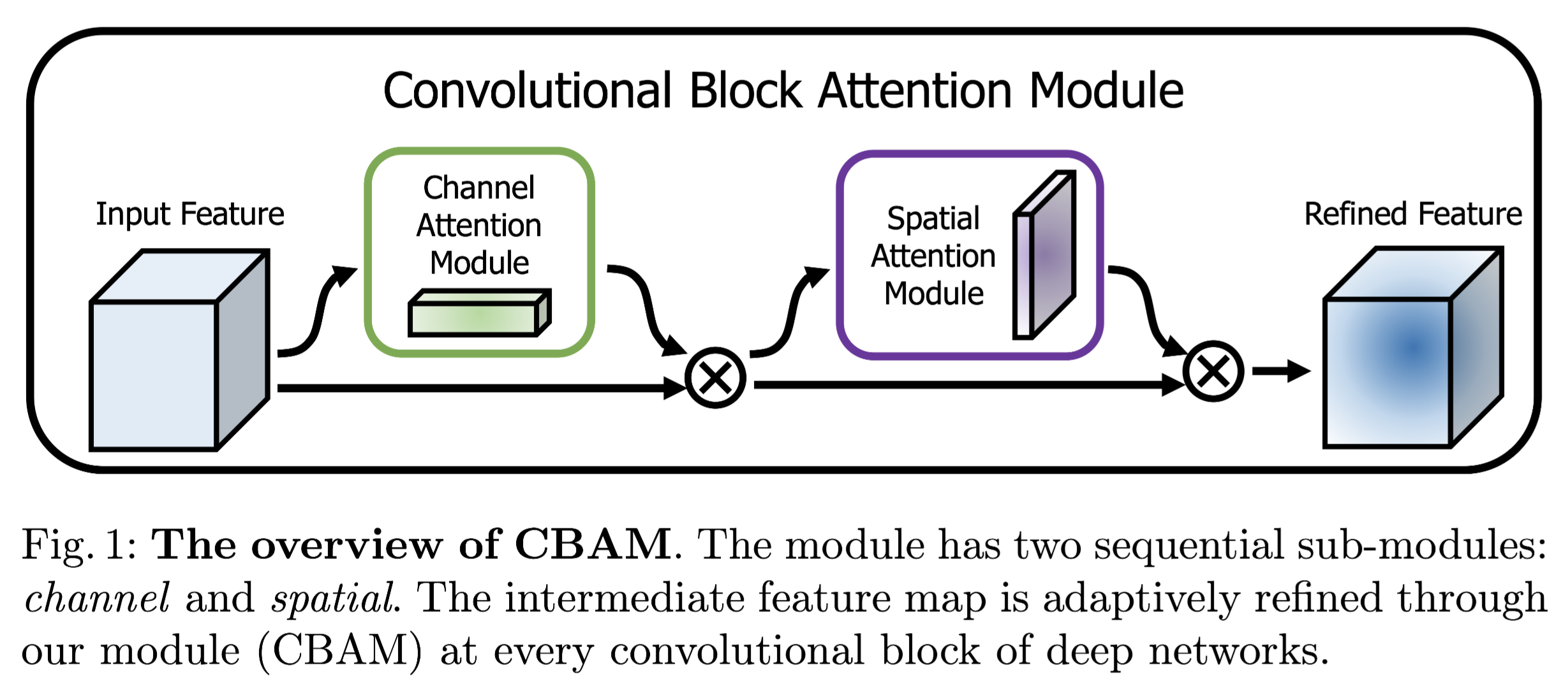
CBAM该模块有两个子模块:通道和空间(学习”what“和”where“),它能够自适应的细化特征图的映射
本文的 主要贡献:

- 提出简单而有效的CBAM模块,能够提高CNN的特征表现能力
- 通过大量的对比试验,验证了CBAM的有效性
- 在不同的模型中插入轻量级的CBAM结构能够在不同数据集上均取得较好结果
CBAM:
给一个特征图F(C×H×W)作为输入,
M
c
M_c
Mc是一维(C×1×1)的通道注意力图,
M
s
M_s
Ms是2维(1×H×W)的空间注意力图。
F
′
=
M
c
(
F
)
⊗
F
F
′
′
=
M
s
(
F
′
)
⊗
F
′
\begin{aligned} \mathbf{F}^{\prime} &=\mathbf{M}_{\mathbf{c}}(\mathbf{F}) \otimes \mathbf{F} \\ \mathbf{F}^{\prime \prime} &=\mathbf{M}_{\mathbf{s}}\left(\mathbf{F}^{\prime}\right) \otimes \mathbf{F}^{\prime} \end{aligned}
F′F′′=Mc(F)⊗F=Ms(F′)⊗F′
其中
⊗
\otimes
⊗是点乘,下图分别表示通道注意力Module和空间注意力Module。
Channel Attention Module:
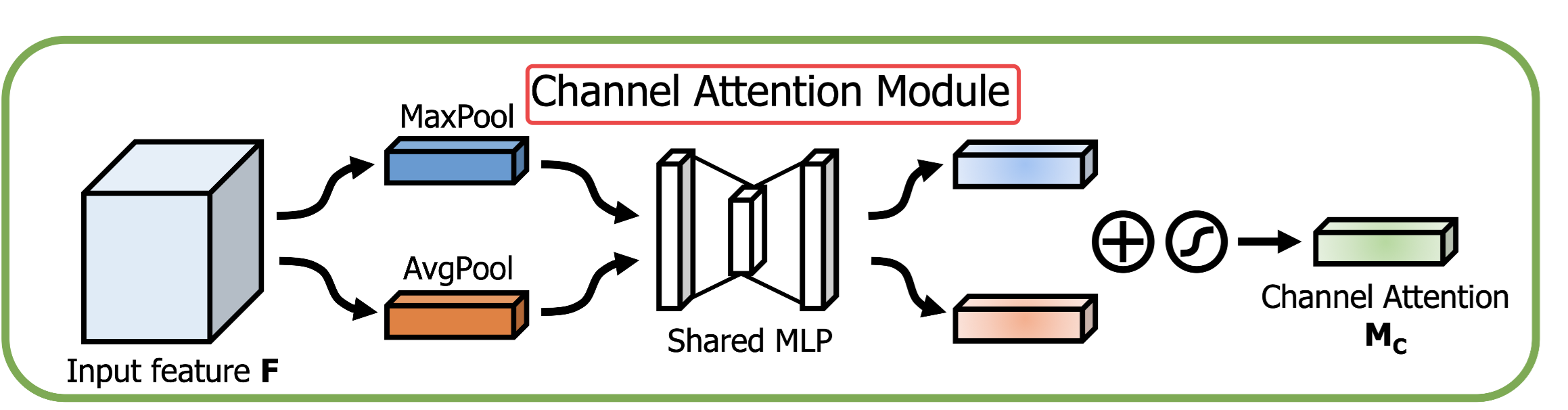
我们利用通道间的关系生成通道注意力图,它更加关注什么(what)是有意义的;同时使用MaxPool和AvgPool操作它是更加有效的!

通道注意力可以通过如下进行计算
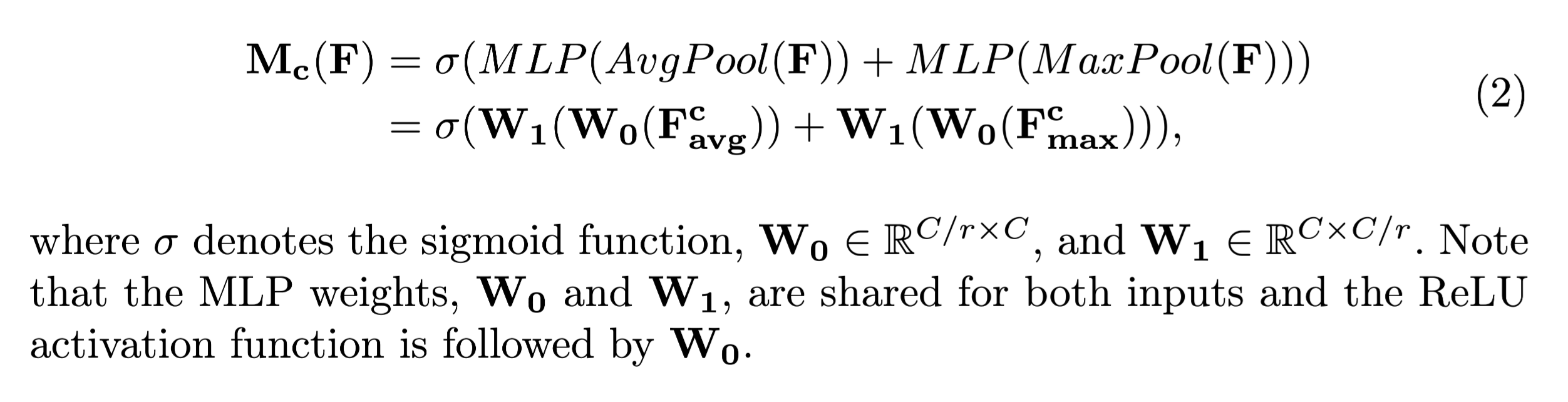
σ \sigma σ代表Sigmoid激活函数, W 0 和 W 1 W_0和W_1 W0和W1为多层感知机MPL神经元的权重。
结构说明
看通道注意力之前,我觉得要先把SE-Net读完,这个结构就是在SE-Net为基础的补充!
结构简述:
对输入特征图F(C×H×W),分别在每个channel上进行全局最大池化和全局平均池化,分别得到C个值!然后把C个值作为全连接神经网络输入层的输入,中间隐含层神经元个数压缩设为C/r(r为压缩倍数),输出层神经元个数为C,分别得到结果(隐含层使用Relu激活函数、输出层使用Sigmoid激活函数)!全局最大池化得到1×1×C的权重,全局平均池化得到1×1×C的权重,然后对这2个1×1×C的权重图对应位置相加,最后在使用Sigmoid激活函数输出得到Channel Attention的结果
M
c
M_c
Mc维数为1×1×C。
Spatial Attention Modul:
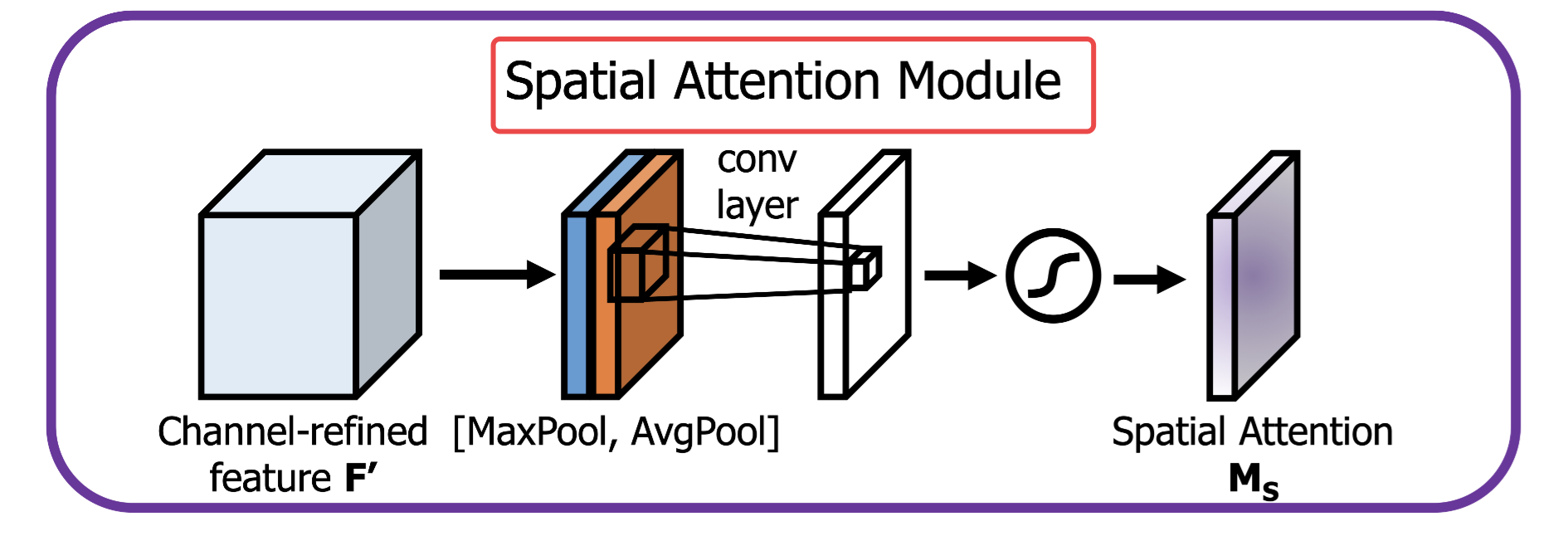
我们根据特征图的空间关系产生空间注意力图,和通道注意力不同,空间注意力更加关注”where“,是对通道注意力的补充!
我们使用2个池化层对输入特征图进行操作,得到一个二维的特征图!
M
s
(
F
)
=
σ
(
f
7
×
7
(
[
AvgPool
(
F
)
;
MaxPool
(
F
)
]
)
)
=
σ
(
f
7
×
7
(
[
F
avg
s
;
F
max
s
]
)
)
\begin{aligned} \mathbf{M}_{\mathbf{s}}(\mathbf{F}) &=\sigma\left(f^{7 \times 7}([\operatorname{AvgPool}(\mathbf{F}) ; \operatorname{MaxPool}(\mathbf{F})])\right) \\ &=\sigma\left(f^{7 \times 7}\left(\left[\mathbf{F}_{\text {avg }}^{\mathbf{s}} ; \mathbf{F}_{\max }^{\mathbf{s}}\right]\right)\right) \end{aligned}
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favg s;Fmaxs]))
σ \sigma σ代表Sigmoid激活函数, f 7 × 7 f^{7×7} f7×7代表使用7×7大小的卷积核。
结构说明:
我看得时候,最大池化和平均池化,怎么对维度上进行操作的不太明白,试了试用nn.maxpool操作是不行的,所以想到了用torch.mean和torch.max指定dim对维度进行操作,比如F=C×H×W用torch.max(F, dim=0)、F=N×C×H×W用torch.max(F, dim=1),指定维度channel通道进行操作!但我不确定到底是不是这样操作的,这样子能够算池化吗?
我去搜了搜,发现有人实现CBAM就是用的这样的方法:
ResNet_CBAM源码
他实现了代码,但是我还不能看,不然就写得和人家一样了,就看了眼空间注意力这儿,它是不是使用的torch.max/torch.mean操作,确定了是这样操作的,就等自己实现完成后再去学习人家的源码!
首先我们对输入特征图(C×H×W)在通道上分别进行MaxPool和AvgPool池化操作分别得到2张特征图1×H×C,然后在通道上进行拼接,得到2×H×C的特征图,接下来使用7×7卷积对特征图进行操作,输出维度为1×H×C,得到空间注意力的结果
M
s
M_s
Ms维数为1×H×C。
原文描述:

为了产生2维的空间注意力特征图,对每个像素的所有通道进行编码(max or average),然后使用1个卷积层对2维的特征图进行操作,得到原始空间注意力机制,最后使用Sigmoid激活函数。
模型设置
两个注意力模块,分别关注”what“和”where“,他们可以平行或者按照顺序放置,作者发现顺序放置要比平行效果更好,实验表明,先通道注意力然后在空间注意力可以拥有更好的效果。
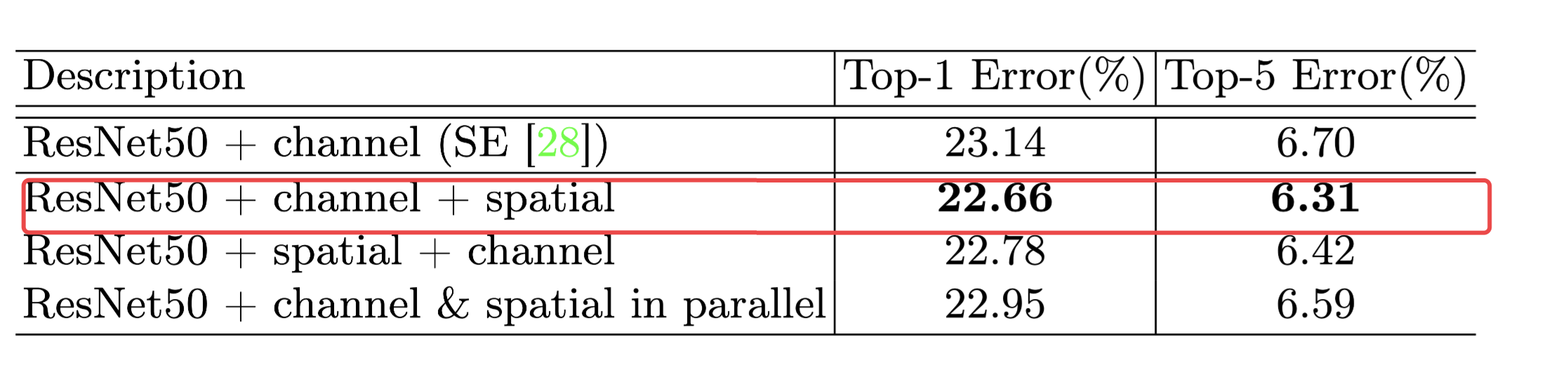
我们可以给任意的CNN模型,加入CBAM模块用于联合训练增强模型。下图是ResBlock和CBAM在ResNet中的一个例子:
代码实现
"""
Author: yida
Time is: 2021/11/21 11:40
this Code: 实现CBAM模块
"""
import os
import torch
import torch.nn as nn
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
class CBAM(nn.Module):
def __init__(self, in_channel):
super(CBAM, self).__init__()
self.Cam = ChannelAttentionModul(in_channel=in_channel) # 通道注意力模块
self.Sam = SpatialAttentionModul(in_channel=in_channel) # 空间注意力模块
def forward(self, x):
x = self.Cam(x)
x = self.Sam(x)
return x
class ChannelAttentionModul(nn.Module): # 通道注意力模块
def __init__(self, in_channel, r=0.5): # channel为输入的维度, r为全连接层缩放比例->控制中间层个数
super(ChannelAttentionModul, self).__init__()
# 全局最大池化
self.MaxPool = nn.AdaptiveMaxPool2d(1)
self.fc_MaxPool = nn.Sequential(
nn.Linear(in_channel, int(in_channel * r)), # int(channel * r)取整数, 中间层神经元数至少为1, 如有必要可设为向上取整
nn.ReLU(),
nn.Linear(int(in_channel * r), in_channel),
nn.Sigmoid(),
)
# 全局均值池化
self.AvgPool = nn.AdaptiveAvgPool2d(1)
self.fc_AvgPool = nn.Sequential(
nn.Linear(in_channel, int(in_channel * r)), # int(channel * r)取整数, 中间层神经元数至少为1, 如有必要可设为向上取整
nn.ReLU(),
nn.Linear(int(in_channel * r), in_channel),
nn.Sigmoid(),
)
# 激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1.最大池化分支
max_branch = self.MaxPool(x)
# 送入MLP全连接神经网络, 得到权重
max_in = max_branch.view(max_branch.size(0), -1)
max_weight = self.fc_MaxPool(max_in)
# 2.全局池化分支
avg_branch = self.AvgPool(x)
# 送入MLP全连接神经网络, 得到权重
avg_in = avg_branch.view(avg_branch.size(0), -1)
avg_weight = self.fc_AvgPool(avg_in)
# MaxPool + AvgPool 激活后得到权重weight
weight = max_weight + avg_weight
weight = self.sigmoid(weight)
# 将维度为b, c的weight, reshape成b, c, 1, 1 与 输入x 相乘
h, w = weight.shape
# 通道注意力Mc
Mc = torch.reshape(weight, (h, w, 1, 1))
# 乘积获得结果
x = Mc * x
return x
class SpatialAttentionModul(nn.Module): # 空间注意力模块
def __init__(self, in_channel):
super(SpatialAttentionModul, self).__init__()
self.conv = nn.Conv2d(2, 1, 7, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x维度为 [N, C, H, W] 沿着维度C进行操作, 所以dim=1, 结果为[N, H, W]
MaxPool = torch.max(x, dim=1).values # torch.max 返回的是索引和value, 要用.values去访问值才行!
AvgPool = torch.mean(x, dim=1)
# 增加维度, 变成 [N, 1, H, W]
MaxPool = torch.unsqueeze(MaxPool, dim=1)
AvgPool = torch.unsqueeze(AvgPool, dim=1)
# 维度拼接 [N, 2, H, W]
x_cat = torch.cat((MaxPool, AvgPool), dim=1) # 获得特征图
# 卷积操作得到空间注意力结果
x_out = self.conv(x_cat)
Ms = self.sigmoid(x_out)
# 与原图通道进行乘积
x = Ms * x
return x
if __name__ == '__main__':
inputs = torch.randn(10, 100, 224, 224)
model = CBAM(in_channel=100) # CBAM模块, 可以插入CNN及任意网络中, 输入特征图in_channel的维度
print(model)
outputs = model(inputs)
print("输入维度:", inputs.shape)
print("输出维度:", outputs.shape)
实验和总结
- 通道注意力,同时使用均值池化和最大池化有更好的效果
- 仅使用均值池化,和最大池化效果差不多
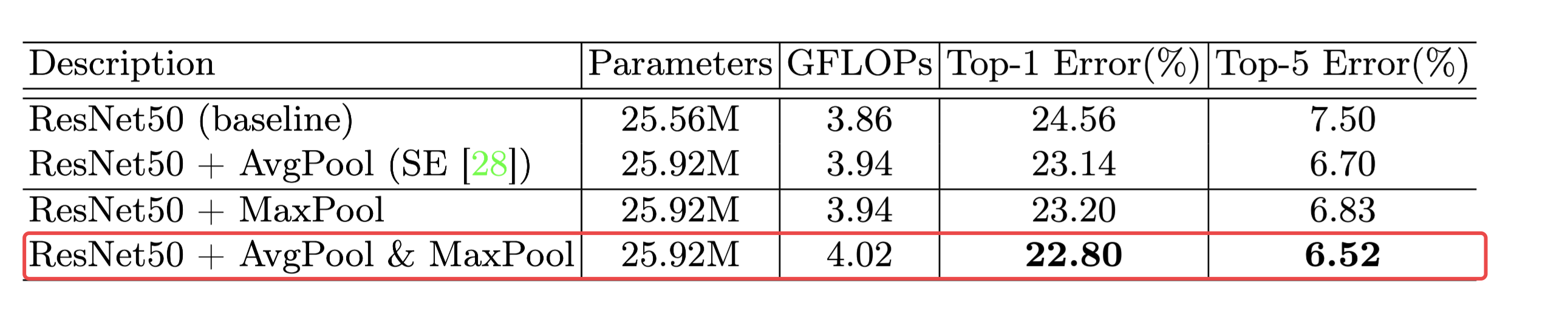
- 对通道注意力进行总结,同时使用均值和池化特征,全连接神经网络的压缩率设为r=16(隐含层神经元个数C/16)
- 空间注意力,分别使用了1×1、3×3卷积但发现使用更大的7×7卷积更好,这意味着空间上重要的区域需要更加广阔的感受野
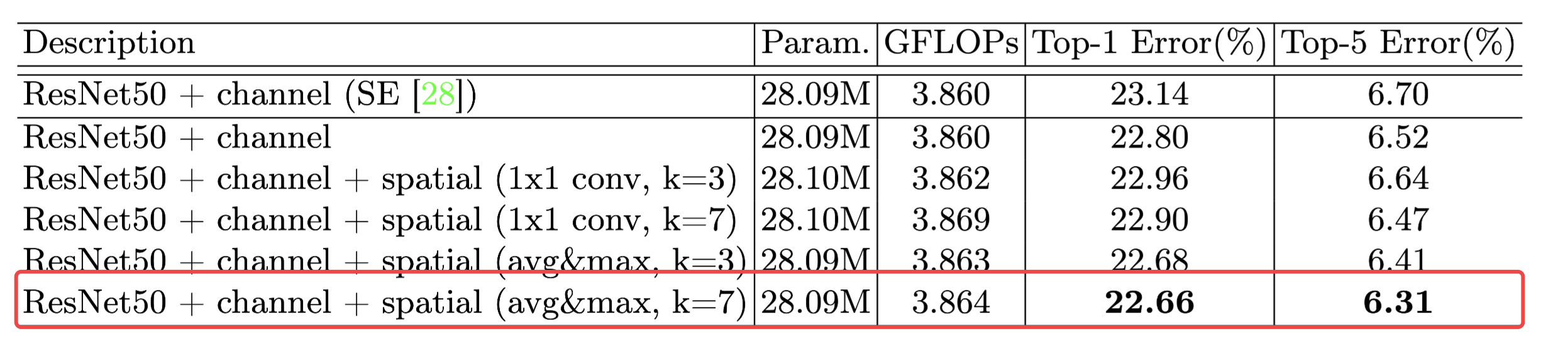
- 最终目标是为了将两个模块同时使用,所以先使用通道注意力,然后在使用空间注意力更好
- 对空间注意力总结,使用平均和最大池化对维度进行操作,然后使用7×7卷积获得我们的空间注意力模型
- 同时使用通道和空间注意力更好,先使用通道注意力然后在使用空间注意力,比并行或者现使用空间注意力效果更好
- 实验表明这两种注意力机制都是至关重要的,我们提出的结构能够提高模型的能力
实验结果:Classification results on ImageNet-1K
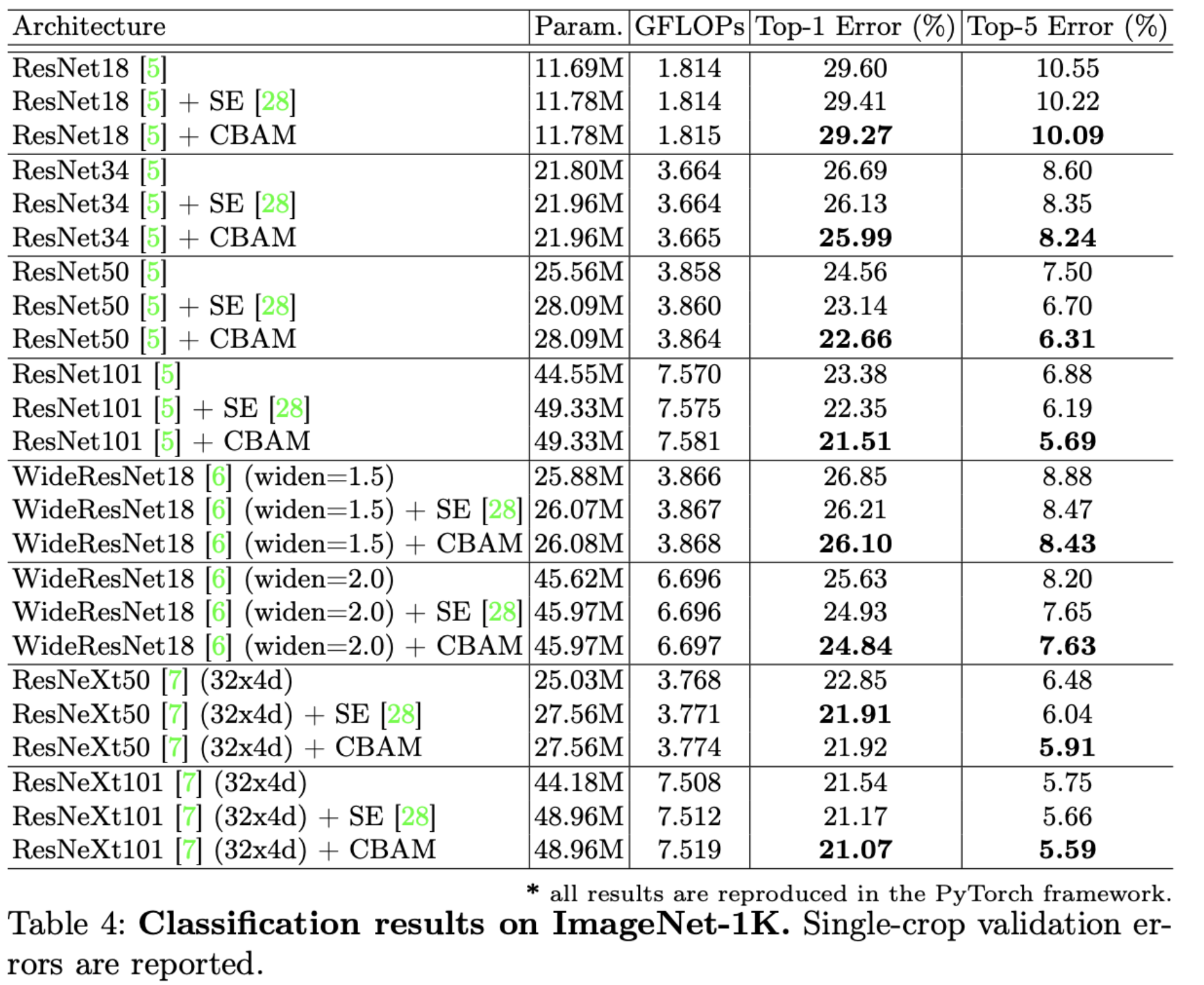
我们发现,使用了CBAM结构的模型总是有提升的!(比使用SE有一点点提升,比什么都不用的基准模型提升多一点点,参数量变化不大,总的来说在参数量不怎么变化的情况下,提高了点点准确率吧)
CBAM在ILSVRC2017任务中是成功的方法。
轻量级网络中的表现:
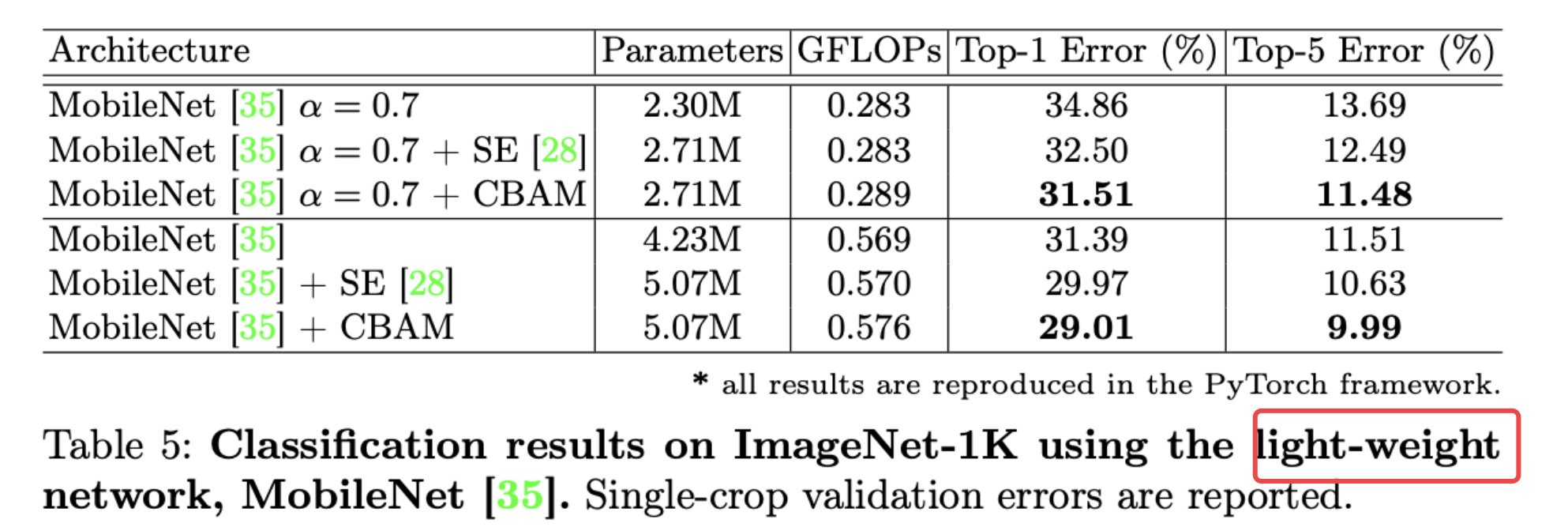
基于MobileNet轻量级网络中,效果很好, 参数及计算的开销都非常小!这表明CBAM在未来的移动端设备上有较大的潜力!
定量评价:
在实践中,给每种方法都给出完整的输入图像、地面真实标签、和两个区域交接处,如下图左1。下表二是25个受访者对50个问题集和图像的投票结果,更多的人认为使用CBAM模块获得的结果能有更好的表现!

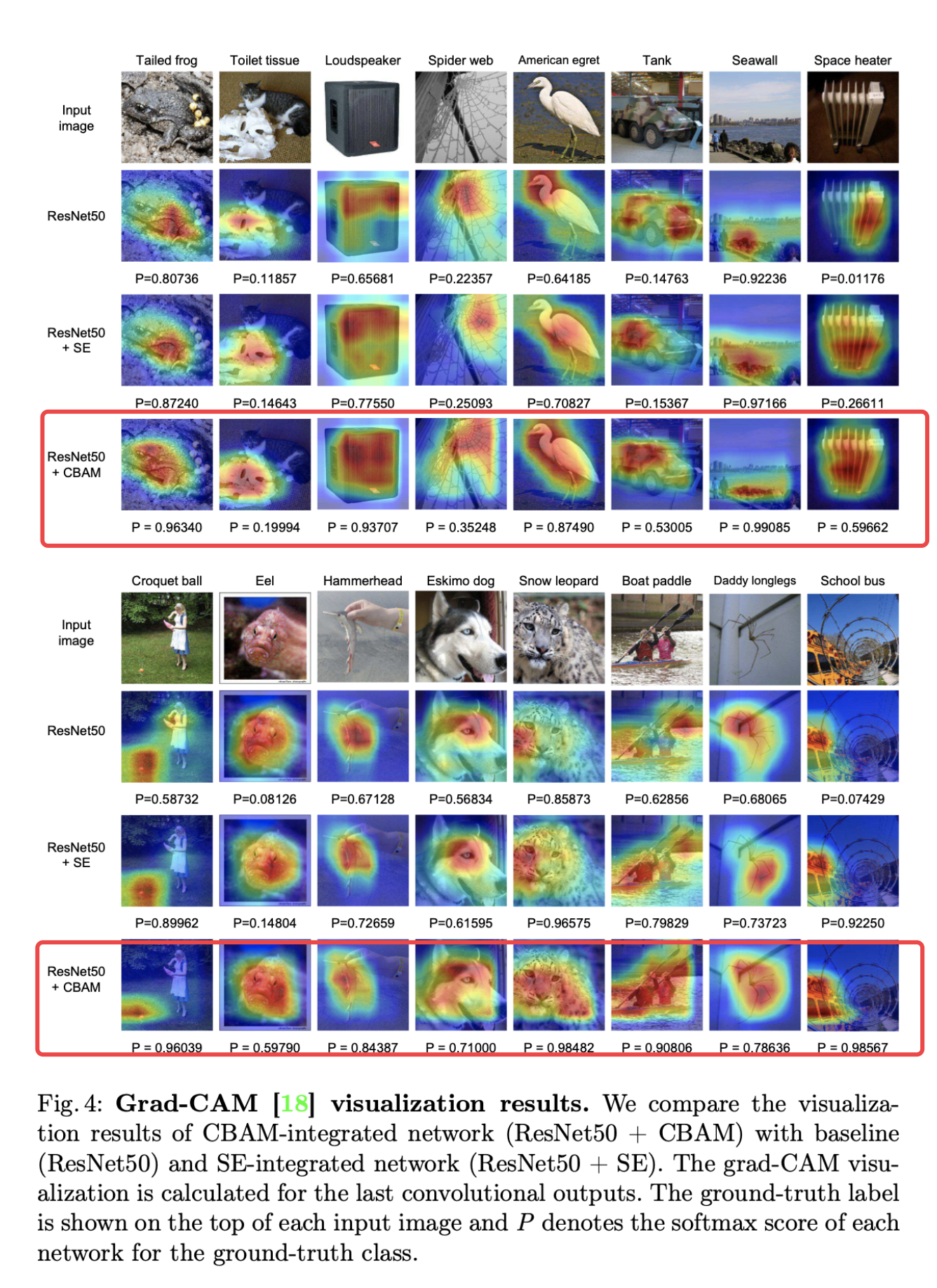
分别比较了以ResNet50为基准、ResNet50-SE、ResNet50-CBAM,计算最后一个卷积层的梯度CAM可视化结果,真实的标签在图像顶部,P代表softmax预测为真实类标签的概率。
最后,CBAM能够强调或抑制内容和位置,并有效的细化中间特征,我们希望CBAM能够成为各种网络结构中重要的组成部分!
【推荐阅读】



















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











