









目录
1. 摘要
阐述了DBSCAN方法的原理,并使用DBSCAN方法,对随机生成的两个带噪声的圆环进行聚类分析。此外,计算了在不同密度参数下的聚类结果,分析了不同密度参数对聚类效果的影响。
2. 基本原理
2.1 DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
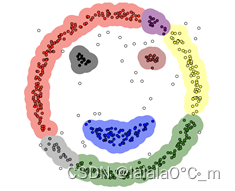
传统k-means这类聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。然而,对于往往现实中存在的其他环形和不规则形等, DBSCAN的基于密度的空间聚类特点就有传统的聚类算法所不具备的优势。
|
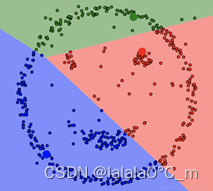
图 2.1 DBSCAN聚类结果 |
图 2.2 K-means聚类结果 |
2.2. 计算原理
基于密度的方法:空间中任意一点的密度是以该点为圆心,以EPS为半径的圆区域内包含的点数目。
它的工作原理是这样的:
- 首先,选择两个参数,一个半径epsilon和一个最小成簇数量minPoints。
- 然后,从数据集中的任意点开始。如果在距离该点epsilon的距离内有超过minPoints个点(包括原始点本身),我们认为所有这些点都是“簇”的一部分。
- 然后,通过检查所有新点来扩展该集群,看看它们在ε的距离内是否也有超过minPoints的点,如果是,则递归地增长集群。
- 最终,用完了要添加到集群中的点后,选择一个新的任意点并重复这个过程。
如果选择的一个点在其epsilon距离内的点完全有可能少于minPoints,并且也不属于任何其他簇的一部分。如果是这样的话,它被认为是一个不属于任何集群的“噪声点”。
2.3. 优缺点
(1) 优点
- 这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点
- 可发现任意形状的聚类,且对噪声数据不敏感。
- 不需要指定类的数目cluster
- 算法中只有两个参数,扫描半径 (eps)和最小包含点数(min_samples)
(2)缺点:
- 计算复杂度,不进行任何优化时,算法的时间复杂度是O(N^{2}),通常可利用R-tree,k-d tree, ball
- tree索引来加速计算,将算法的时间复杂度降为O(Nlog(N))。
- 受eps影响较大。在类中的数据分布密度不均匀时,eps较小时,密度小的cluster会被划分成多个性质相似的cluster;eps较大时,会使得距离较近且密度较大的cluster被合并成一个cluster。在高维数据时,因为维数灾难问题,eps的选取比较困难。
- 依赖距离公式的选取,由于维度灾害,距离的度量标准不重要
- 不适合数据集集中密度差异很大的,因为eps和metric选取很困难
3. 基于DBSCAN的聚类分析
随机生成包含噪声的两个圆圈,半径分别为0.8和5,每个圆圈包含400个数据,总计原始数据800个。其原始数据可视化结果如下:
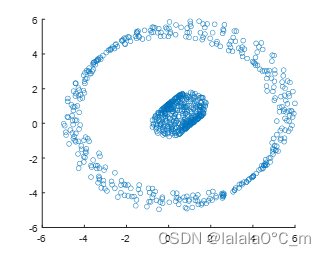
图 3.1原始数据可视化
使用matlab自编码的DBSCAN算法,计算聚类结果。其中选取了不同的半径和密度参数,设定如下3个场景:
| 场景编号 | Epsilon | Minpoints |
| 1 | 0.5 | 5 |
| 2 | 0.5 | 10 |
| 3 | 1 | 5 |
聚类结果如下:
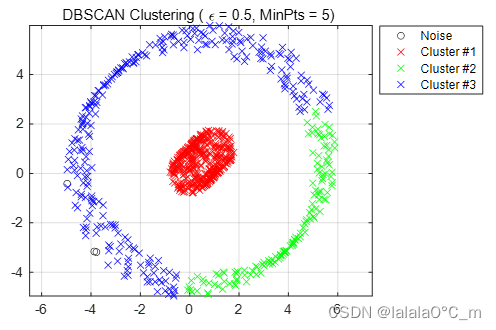
图 3.2 Epsilon=0.5,minpoints=5聚类结果
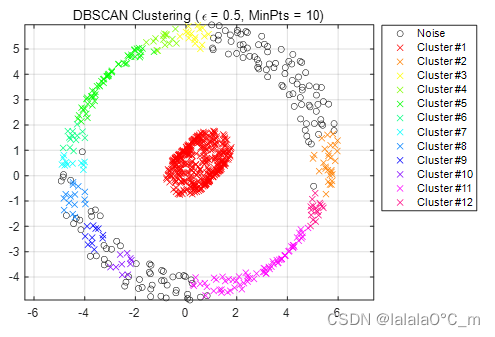
图 3.3 Epsilon=0.5,minpoints=10聚类结果
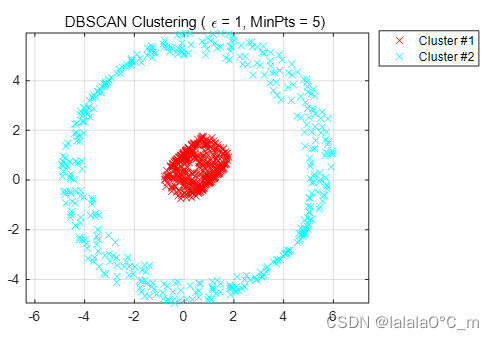
图 3.4 Epsilon=1,minpoints=5聚类结果
可见不同的密度参数会极大影响数据聚类结果,半径越大,成簇数量越小,所分类别越少,反之越多。此外,DBSCAN可发现任意形状的聚类,且对噪声数据不敏感。
参考文献
[1] DBSCAN聚类算法——机器学习(理论+图解+python代码)_风弦鹤的博客-CSDN博客. Blog. DBSCAN聚类算法——机器学习(理论+图解+python代码)-CSDN博客
[2] DBSCAN聚类算法——基于密度的聚类方式(理论+图解+python代码)_dbscan clustering_Lindsay.Lu丶的博客-CSDN博客. Blog. DBSCAN聚类算法——基于密度的聚类方式(理论+图解+python代码)_基于密度的聚类算法dbscan-CSDN博客
附录-案例代码
本案例的Matlab代码如下:
clc;
clear;
close all;
%% Generate Data
% 生成包含两个噪声圆圈的数据
N =400; % Size of each cluster
r1 = 0.8;
r2 = 5;
theta = linspace(0,2*pi,N)';
X1 = r1*[cos(theta),sin(theta)]+ rand(N,1);
X2 = r2*[cos(theta),sin(theta)]+ rand(N,1);
X = [X1;X2]; % Noisy 2-D circular data set
%% 可视化原始数据
figure('name','原始数据可视化')
scatter(X(:,1),X(:,2));
set(gca,'FontSize',12);
%% Run DBSCAN Clustering
epsilon=1; % 两个关键参数的取值
MinPts=5;
IDX=DBSCAN(X,epsilon,MinPts);
%% Plot Results
figure('name','DBSCAN聚类结果');
PlotClusterinResult(X, IDX);
set(gca,'FontSize',12);
title(['DBSCAN Clustering (\epsilon = ' num2str(epsilon) ', MinPts = ' num2str(MinPts) ')']);
%%%%%%% ————DBSCAN函数 ——————%%%%%%%%%%%%
function [IDX, isnoise]=DBSCAN(X,epsilon,MinPts) % DBSCAN聚类函数
C=0;
n=size(X,1);
IDX=zeros(n,1);
D=pdist2(X,X);
visited=false(n,1);
isnoise=false(n,1);
for i=1:n
if ~visited(i)
visited(i)=true;
Neighbors=RegionQuery(i);
if numel(Neighbors)<MinPts % 如果小于MinPts
% X(i,:) is NOISE
isnoise(i)=true; % 该点是异常点
else
C=C+1;
ExpandCluster(i,Neighbors,C);
end
end
end
function ExpandCluster(i,Neighbors,C)
IDX(i)=C;
k = 1;
while true % 一直循环
j = Neighbors(k);
if ~visited(j)
visited(j)=true;
Neighbors2=RegionQuery(j);
if numel(Neighbors2)>=MinPts
Neighbors=[Neighbors Neighbors2]; %#ok
end
end
if IDX(j)==0
IDX(j)=C;
end
k = k + 1;
if k > numel(Neighbors)
break;
end
end
end
function Neighbors=RegionQuery(i) % 该函数用来查询周围点中距离小于等于epsilon的个数
Neighbors=find(D(i,:)<=epsilon);
end
end
%%%% ————— 画图函数—————%%%%%%%
function PlotClusterinResult(X, IDX)
k=max(IDX);
Colors=hsv(k);
Legends = {};
for i=0:k
Xi=X(IDX==i,:);
if i~=0
Style = 'x';
MarkerSize = 8;
Color = Colors(i,:);
Legends{end+1} = ['Cluster #' num2str(i)];
else
Style = 'o';
MarkerSize = 6;
Color = [0 0 0];
if ~isempty(Xi)
Legends{end+1} = 'Noise';
end
end
if ~isempty(Xi)
plot(Xi(:,1),Xi(:,2),Style,'MarkerSize',MarkerSize,'Color',Color);
end
hold on;
end
hold off;
axis equal;
grid on;
legend(Legends);
legend('Location', 'NorthEastOutside');
end















 1145
1145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









