







强化学习
本文开始强化学习的研究,主要跟随百度飞桨科老师在B站的视频,在老师原有的基础上,将课堂上所有的内容以及代码根据自己的理解进行重述。
1、区别于监督学习
监督学习与强化学习具有不同的侧重点
强化学习和监督学习具有不同的侧重点,这是认识强化学习的基础。监督学习无论是采用手动设计特征的传统算法或者是采用自动提取特征的深度学习的方式,均侧重于解决认知问题,即:A是什么,B是什么的分类问题;或者A的预测值是多少的回归问题。
但是,强化学习更加侧重于决策层。在某个环境(observation)下,采取什么样的行为(action)能够获得更大的收益。
2、强化学习分类
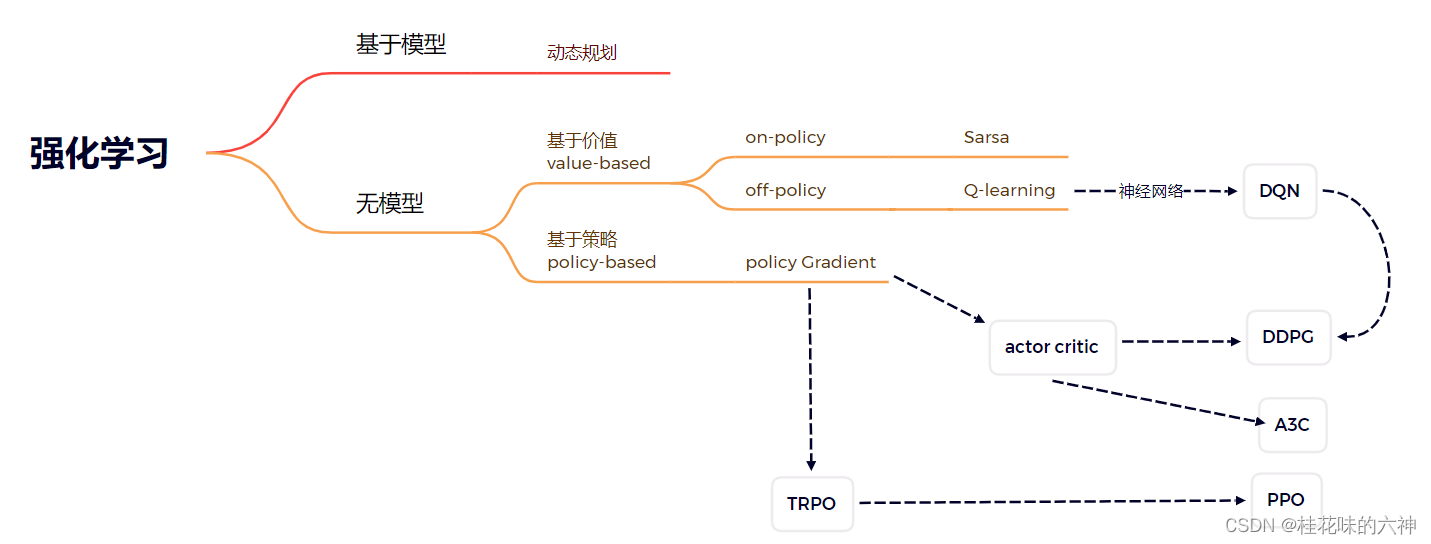
根据不同的标准,强化学习有不同的分类,按照科老师的讲解,将强化学习按照不同的标准进行分类:
| 分类标准 | 类别1 | 类别2 |
|---|---|---|
| 环境是否已知 | model-based | model-free |
| 学习方式 | on-policy | off-policy |
| 学习目标 | value-based | policy-based |
将重点算法按照上述分类标准进行分类:
3、GYM简介
两种理解思路:
官方的GYM简介:仿真平台、python开源库、RL测试平台、用于开发和比较强化学习算法工具包。
个人理解:以内置的各种场景验证和比较开发的强化学习算法的效果的平台,也就是说,当一个强化学习算法开发完成后,可以用其中内置的场景进行验证。当然,也可以直接基于其中内置的场景进行开发,接下来的Sarsa和Q-learning都会基于其中内置的“悬崖漫步”环境进行开发。
4、GYM安装
网上关于GYM的安装的方法不计其数,但是都没有讲述的特别清晰明了的博客,很大一部分原因是GYM对Linux的支持比较友好,但是在windows下却并没有非常的完善,尤其是atari以及mujoco的安装也是非常繁琐。以后会找时间专门研究一下这两个组件的安装,在此先简易安装GYM,简易安装对于大部分需求已经基本可以满足。
安装:
pip install gym
优点:有手即可
缺点:缺失部分组件
5、GYM的简单使用
首先用一句话概述强化学习的过程:智能体(agent)在某个观测值(observation)下选择特定的行为(action)与环境(env)交互(step),根据环境反馈(reward)学习(learning)经验。
如上所述,强化学习主要解决的问题是,在某一个环境下该选择什么样的决策。用于强化学习的GYM就是通过创建一个环境;然后,通过智能体(Agent)与环境不断地交互来学习经验,学习完成后即可在任意一个条件下选择最优行为(action)。
在此明确了几个概念:
agent:智能体,也就是采取行为的主体
reward:环境对智能体action做出的奖励
action:智能体选择的行为
observation:观测值,也就是智能体做出action后环境所达到的新的状态
既然GYM是用于强化学习的仿真平台,就支持上述几种操作,以下做简单介绍:
import gym
# 创建一个环境,具体有多少环境可以到gym的源码查看
env = gym.make("CartPole-v0")
# 用于重置环境,一般在初始化环境或者重开游戏时使用
env.reset()
"""
用于与环境产生交互
参数obs表示agent做出action之后环境达到的新状态
参数reward表示agent做出action后环境给agent的奖励
is_done表示做出action之后,当前场景是否达到终点
占位符_所代表的参数的实际意义不大,几乎没有用到过
"""
obs, reward, is_done,_ = env.step(action)
# 渲染环境
env.render()
6、强化学习GYM实例
下面给出一个GYM的强化学习的实例,可以直接运行,先看到效果,然后再进一步研究学习。
## 导入gym包
import gym
## 创建一个游戏环境
env = gym.make("CartPole-v0")
## 训练20个epoch
for i in range(20):
## 每次训练前都初始化环境
env.reset()
## 与环境的最大交互次数为100
for step in range(100):
## 渲染环境
env.render()
## 从 action 空间中获取一个 action
action = env.action_space.sample()
## 根据 action 与环境进运行一次交互
observation,reward,done,info = env.step(action)
## 如果返回当前游戏结束,推出当前游戏继续下一次训练
if(done):
break















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









