







PyTorch
1. python学习中的两大法宝函数
dir():打开
help():说明书
2. Pycharm及Jupyter使用及对比
Jupyter:使用anaconda prompt激活环境:conda activate pytorch
打开Jupyter:Jupyter notebook
3. pytorch加载数据初认识
主要使用两个类:
-
Dataset:
提供一种方式去获取数据及其label
- 如何获取每一个数据及其label
- 告诉我们总共有多少数据
-
Dataloader:为网络提供不同的数据形式
4. Dataset类代码实战
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
# 提供全局变量
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "data/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
img, label = ants_dataset[0]
img.show()
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
5. TensorBoard的使用
tensorboard:用于数据可视化的工具
主要功能:
- 可视化模型的网络架构
- 跟踪模型指标,如损失和准确性等
- 检查机器学习工作流程中权重、偏差和其他组件的直方图
- 显示非表格数据,包括图像、文本和音频
- 将高维嵌入投影到低维空间
举例:y=x
from torch.utils.tensorboard import SummaryWriter
#将事件存储到logs文件夹下
writer=SummaryWriter("logs")
#两个方法
# writer.add_image()
#y=x
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
打开事件文件夹:tensorboard --logdir=logs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MjGW1ipQ-1657962781175)(F:\研究生\研0笔记\图片库\image-20220712151934966.png)]](https://img-blog.csdnimg.cn/5d9ca1718dd94cbdaa3e14c5f122f99e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vGRTDeFG-1657962781176)(F:\研究生\研0笔记\图片库\image-20220712152056337.png)]](https://img-blog.csdnimg.cn/3106726d2303408bb3bf50b6b7a90cfe.png)
修改显示的输出端口
tensorboard --logdir=logs --port=6007
利用opencv读取图片,获取numpy型图片数据
利用numpy.array(),对PIL图片进行转换
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
# 将事件存储到logs文件夹下
writer = SummaryWriter("logs")
# 两个方法
# 1.writer.add_image()
image_path = "data/hymenoptera_data/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
print(type(img_PIL))
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)# hwc(高度,宽度,通道)
# 从PIL到numpy,需要在add_image()中指定shape中每一个数字/维表示的含义
writer.add_image("test",img_array,1,dataformats="HWC")
# 2.writer.add_scalar()
# y=2x
for i in range(100):
writer.add_scalar("y=2x", 2 * i, i)
writer.close()
查看时也是在terminal中输入tensorboard --logdir=logs --port=6007
6. Transforms的使用
主要功能:对图片进行一些变换
transforms的结构及用法
totensor:把数据类型转化为tensor数据类型
resize
1.transforms该如何使用
from torchvision import transforms
from PIL import Image
# python的用法->tensor数据类型
# 通过transforms.ToTensor去看两个问题
# 1.transforms该如何使用(python)
# 2.为什么我们需要Tensor数据类型
img_path = "data/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
2.为什么我们需要Tensor数据类型
查看函数需要的参数:ctrl+p
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
# python的用法->tensor数据类型
# 通过transforms.ToTensor去看两个问题
# 1.transforms该如何使用(python)
# 2.为什么我们需要Tensor数据类型
img_path = "data/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
writer=SummaryWriter("logs")
# 1.transforms该如何使用(python)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("Tensor_img",tensor_img)
writer.close()
7. 常见的Transforms
输入 PIL --> Image.open()
输出 tensor --> ToTensor()
作用 narrays --> cv.imread()
使用模板创建工具,然后使用工具
python中的_ _call _ _用法
call方法使得可以直接调用输出,不用调用其中的方法
class Person:
def __call__(self, name):
print("__call__"+"hello"+name)
def hello(self,name):
print("hello"+name)
person=Person()
person("zhangsan")
person.hello("lisi")
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z90uMhuj-1657962781177)(F:\研究生\研0笔记\图片库\image-20220713105709457.png)]](https://img-blog.csdnimg.cn/0db27a5ea4604d8e96cb9593946b1844.png)
ToTensor的使用
img_path = "data/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
writer=SummaryWriter("logs")
trans_totensor = transforms.ToTensor()
tensor_img = trans_totensor(img)
writer.add_image("Tensor_img",tensor_img)
writer.close()

Normalize的使用
# Normalize:归一化,输入是均值和标准差
print(tensor_img[0][0][0])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_norm(tensor_img)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()

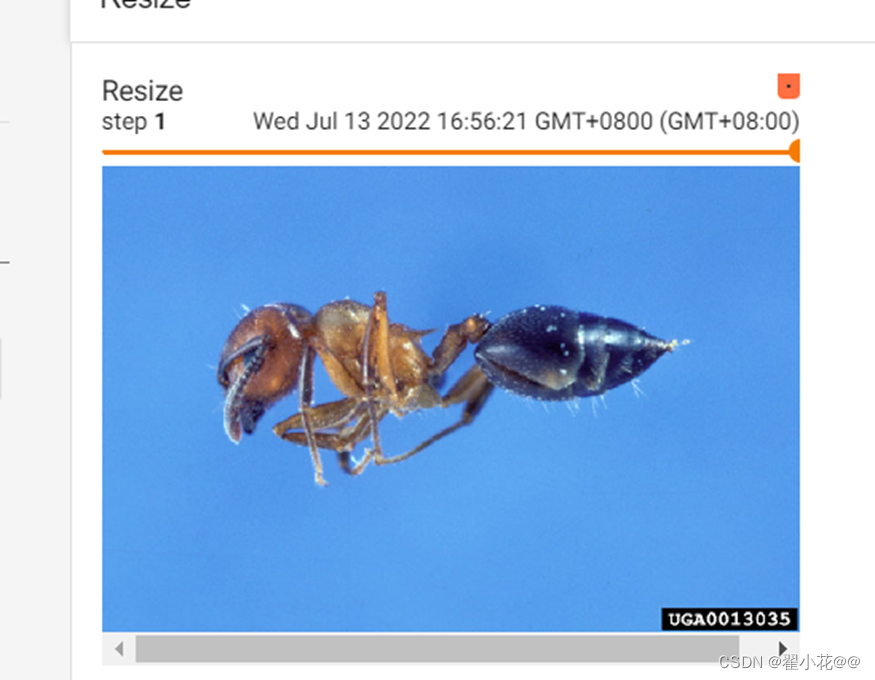
Resize
#Resize
print(img.size)
trans_resize=transforms.Resize((512,512))
# img PIL ->resize-> img_resize PIL
img_resize=trans_resize(img)
print(img_resize)
#img_resize PIL->totensor->img_resize totensor
img_resize=trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
writer.close()

Compose()中的参数需要是一个列表,在python中,列表的表示形式为[数据1,数据2,…]在Compose()中的参数需要时transforms类型的,所以列表为([transforms参数1,transforms参数2,…])
#Compose - resize - 2
trans_resize_2=transforms.Resize(512)
trans_compose=transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2=trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
writer.close()
对比原先的Resize直接将图片缩成正方形,compose方法成功保持了原有比例并且限制了最长边
注意:需要注意transforms参数1的输出是否与transforms参数2的输入匹配
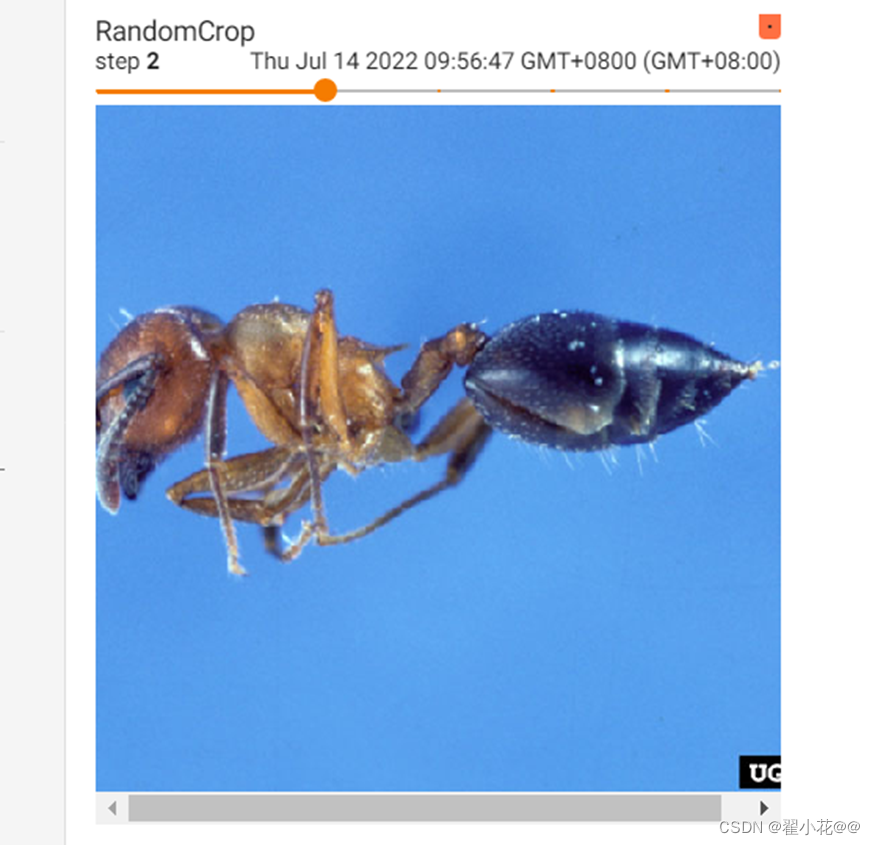
RandomCrop()随机裁剪
#RandomCrop
trans_random=transforms.RandomCrop((100,100))
trans_compose_2=transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop=trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
8. torchvision中的数据集使用
torchvision常见的使用
import torchvision
# 数据集的下载
train_set=torchvision.datasets.CIFAR10(root="./data/dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./data/dataset",train=False,download=True)
# 查看数据集中的第一个数据
print(test_set[0])
# 查看数据集的分类有哪些
print(test_set.classes)
img,target=test_set[0]
# target是标签存放的位置
# 查看图片信息
print(img)
# 查看该图片对应类别
print(test_set.classes[target])
img.show()
与transforms连用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# 数据集的下载,加了使用transforms工具转化数据类型
train_set=torchvision.datasets.CIFAR10(root="./data/dataset",transform=dataset_transform,train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./data/dataset",transform=dataset_transform,train=False,download=True)
#数据集中数据的显示
writer=SummaryWriter("torchvision_log")
for i in range(10):
img,target=test_set[i]
writer.add_image("test_set",img,i)
9. DataLoader的使用

dataloader:从dataset中取数据
# 准备测试数据集
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./data/dataset", train=False, transform=torchvision.transforms.ToTensor())
'''
batch_size=4:每次从数据集中取4个数据并进行打包
shuffle=True:用于打乱数据集,每次都会以不同的顺序返回
'''
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
# print(img.shape)
# print(target)
writer = SummaryWriter("dataloader_log")
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("test_data", imgs, step)
step = step + 1
# print(imgs.shape)
# print(targets)
writer.close()
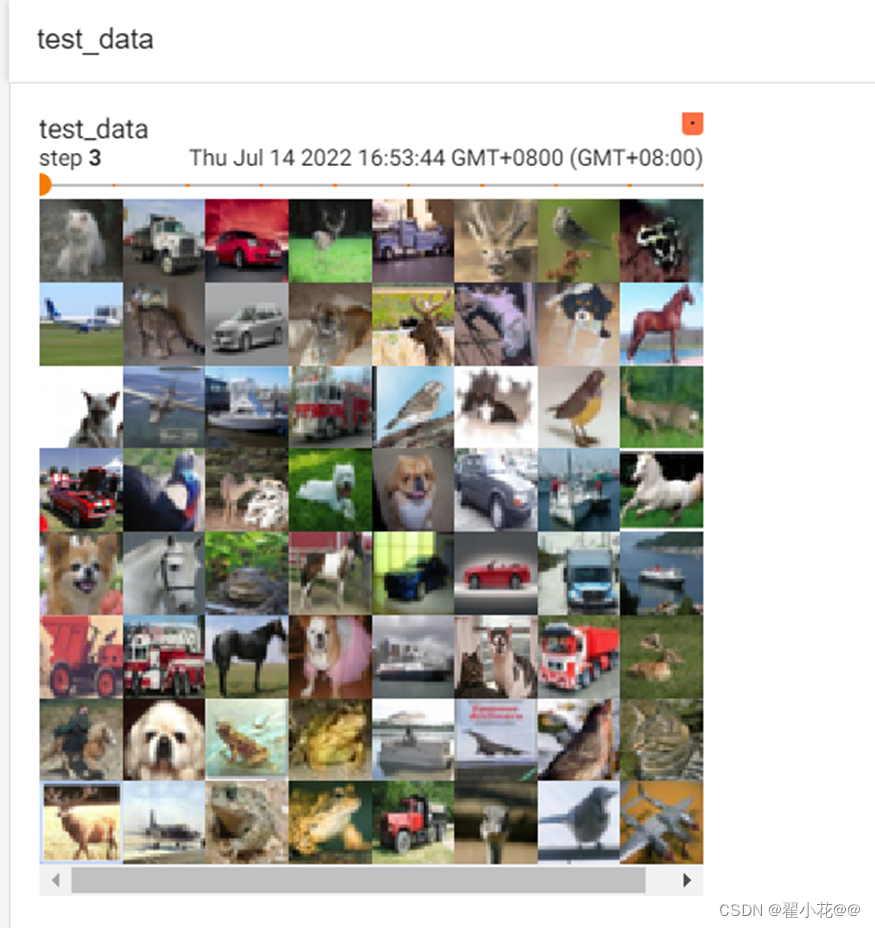
若drop_last改为true,那么最后不足64张的时候会舍去
shuffle=True:用于打乱数据集,每次都会以不同的顺序返回
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
# print(img.shape)
# print(target)
writer = SummaryWriter("dataloader_log")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
# print(imgs.shape)
# print(targets)
writer.close()
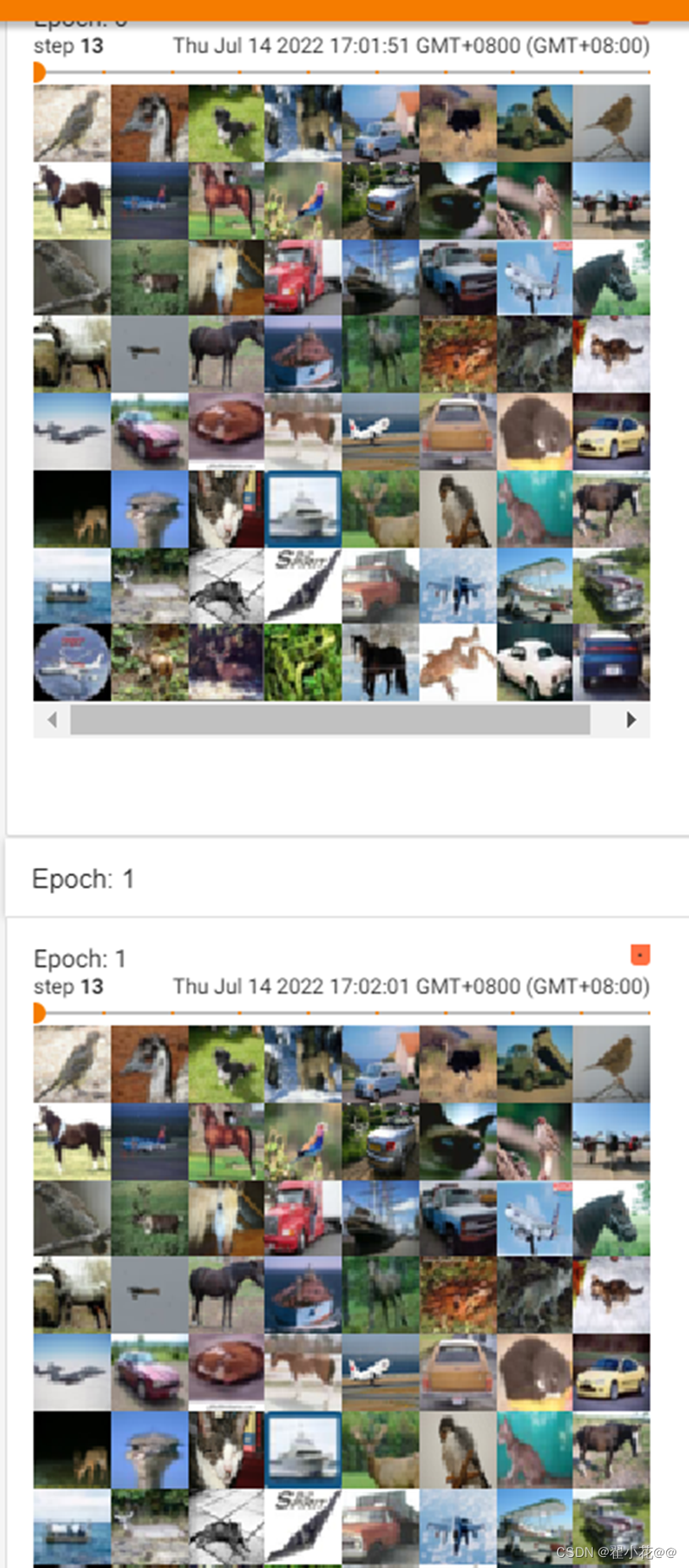
两次不同
在这里插入图片描述
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=False)
img, target = test_data[0]
# print(img.shape)
# print(target)
writer = SummaryWriter("dataloader_log")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
# print(imgs.shape)
# print(targets)
writer.close()
两次相同
10. 神经网络的基本骨架-nn.Module的使用
常用的参考文档:PyTorch documentation — PyTorch 1.12 documentation在torch.nn中
import torch
from torch import nn
class NN_Module(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
nn_module = NN_Module()
x = torch.tensor(1.0)
output = nn_module(x)
print(output)
11. 卷积操作
import torch
import torch.nn.functional as F
# 构造数据图像
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 构造卷积核
kernel = torch.tensor([
[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 尺寸变换
'''
定义的是二维的灰度图像,是一通道的,
然后batch-size的大小是1(batch-size是指这批数据的数据个数,这里就一个矩阵,也就只有一个5*5的灰度图像,所以是1)
然后5*5
'''
#
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
padding:在图像的两边进行填充,![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vs0jSTF7-1657962781178)(F:\研究生\研0笔记\图片库\image-20220714180311848.png)]](https://img-blog.csdnimg.cn/69fd0de644824f02bf1b8399f2258d5c.png)
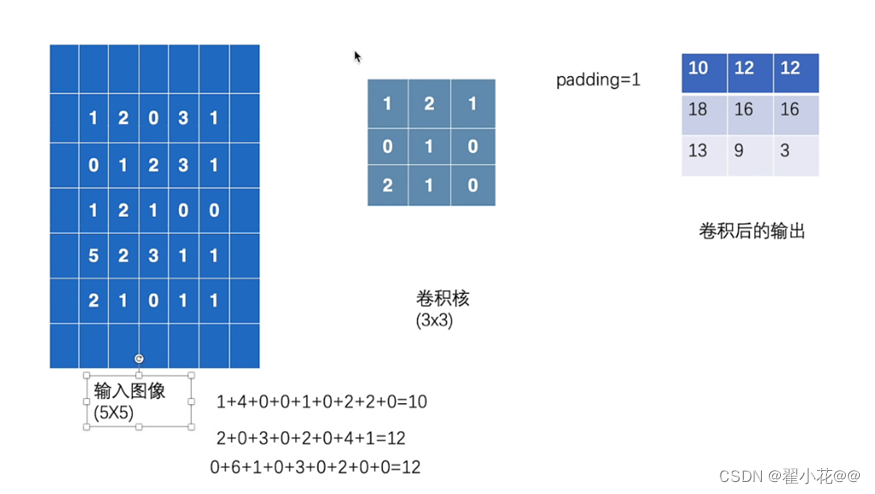
12. 神经网络-卷积层
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OAcCRKMd-1657962781179)(F:\研究生\研0笔记\图片库\image-20220714181407749.png)]](https://img-blog.csdnimg.cn/4138f1a50e2e4841bdee210da44d7d81.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ClItz3NO-1657962781179)(F:\研究生\研0笔记\图片库\image-20220714181625337.png)]](https://img-blog.csdnimg.cn/d0783030a5424db187ec73da318689d9.png)
使用卷积对图像进行操作
import torch
from torch import nn
import torch.nn.functional as F
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="./data/dataset", transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Nn_Conv2d(nn.Module):
# 初始化父类的初始化函数
def __init__(self):
super(Nn_Conv2d, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
nn_conv2d = Nn_Conv2d()
writer = SummaryWriter("nn_conv2d_logs")
step = 0
for data in dataloader:
imgs, targets = data
output = nn_conv2d(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
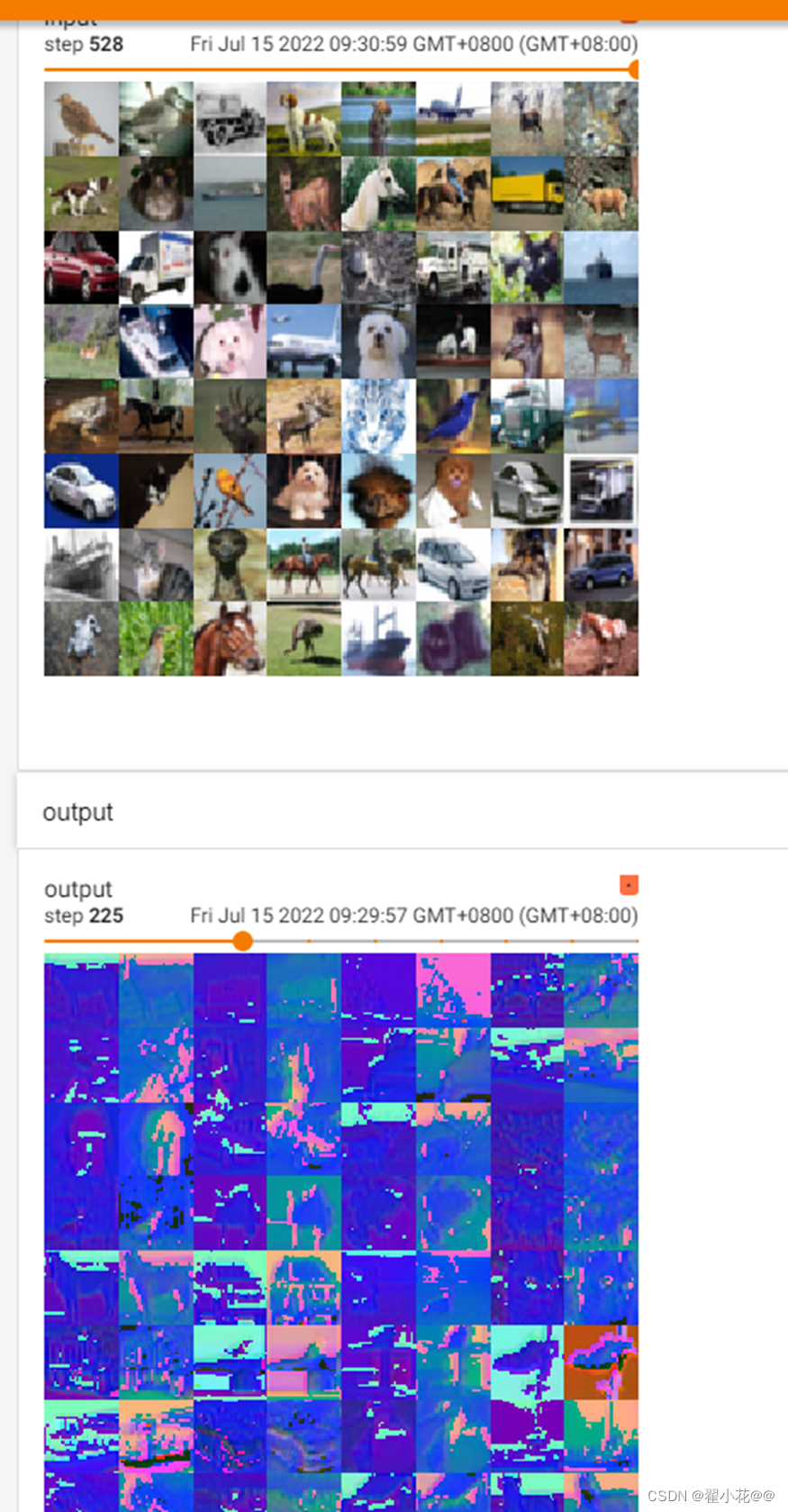
常用的:VGG16
13. 最大池化的作用
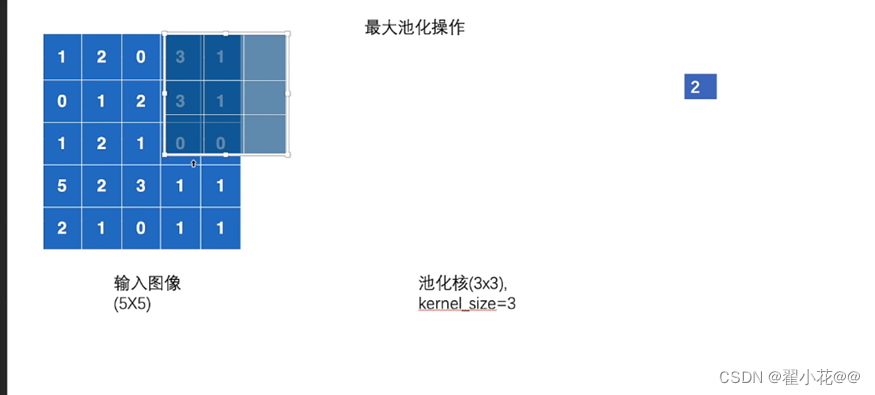
默认移动步长:池化核(kernel_size)
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./data/dataset", train=False, transform=torchvision.transforms.ToTensor())
# torchvision.datasets.CIFAR10("./data/dataset", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Poll(nn.Module):
def __init__(self):
super(Poll,self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,input):
output=self.maxpool1(input)
return output
poll=Poll()
writer=SummaryWriter("max_pool_log")
step=0
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
output=poll(imgs)
writer.add_images("output",output,step)
step=step+1
writer.close()
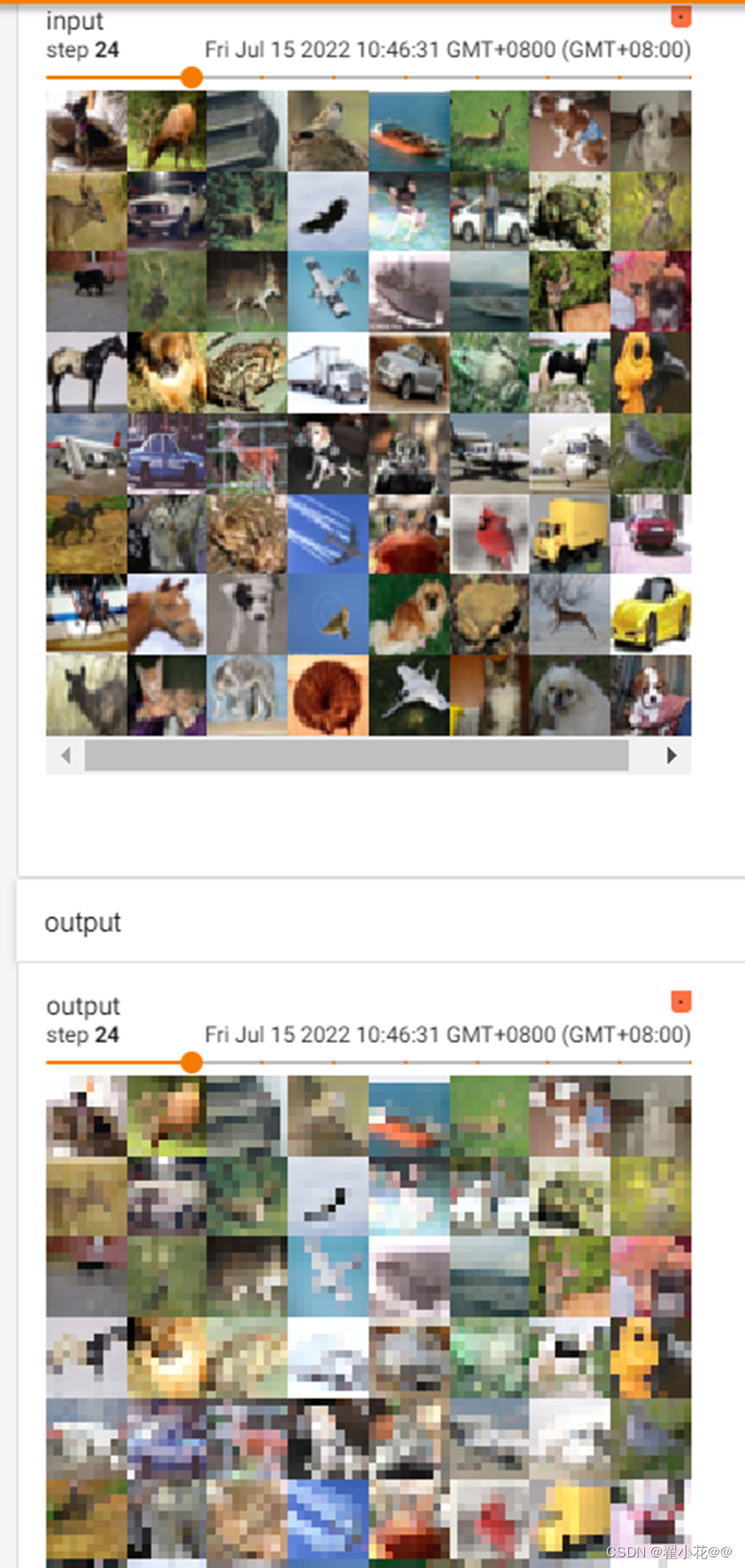
减少了数据量,加速
14. 非线性激活
常用ReLU
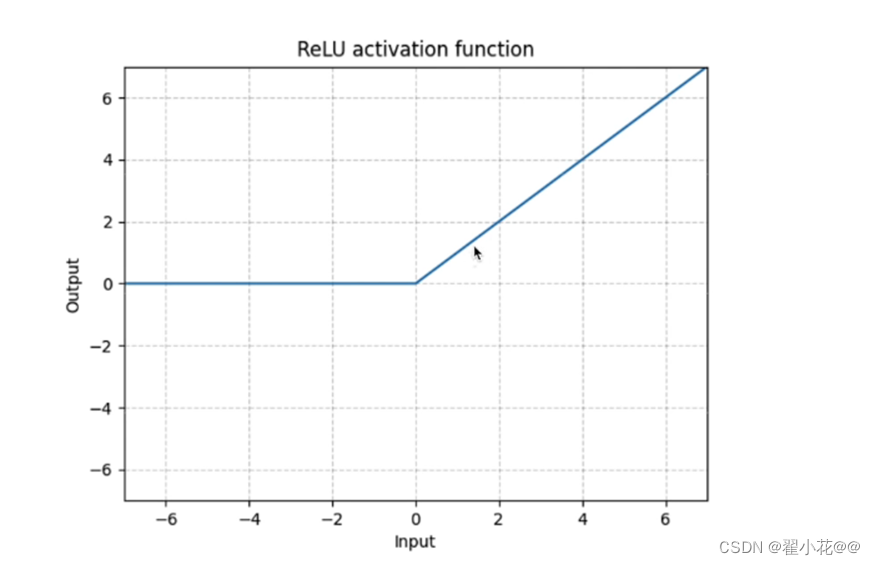
sigmoid
import torch
from torch import nn
from torch.nn import ReLU, Sigmoid
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("./data/dataset", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmod1=Sigmoid()
def forward(self, input):
output = self.sigmod1(input)
return output
tudui = Tudui()
writer=SummaryWriter("sigmoid_log")
step=0
for data in dataloader:
imgs, targets = data
writer.add_images("input",imgs,global_step=step)
output=tudui(imgs)
writer.add_images("output",output,step)
step=step+1
writer.close()
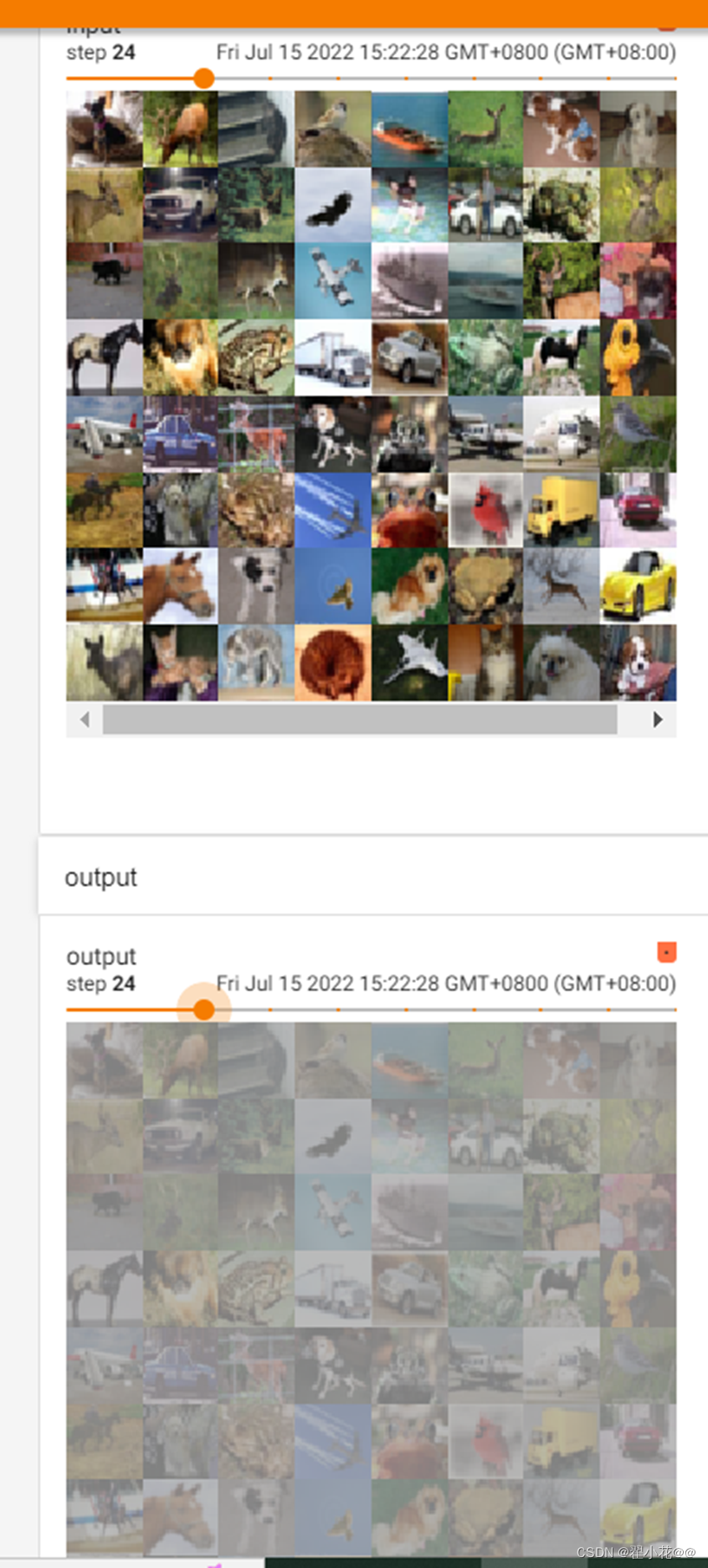
step从3开始,并且有图像没显示解决:在terminal 那里,最后面加一个–samples_per_plugin=images=1000
15. 神经网络-线性层及其他层介绍
正则化层:可以加快神经网络的训练速度
Recurrent层:多用于文字处理,有RNN,LSTM等
Dropout:防止过拟合等
Sparse层:有Embedding等,多用于自然语言处理
Distance:计算两个值之间的误差
Loss Functions:
Linear层:

import torch
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./data/dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
# 展平,将输入展成1行
output = torch.flatten(imgs)
print(output.shape)
output = tudui(output)
print(output.shape)
16. 神经网络-搭建小实战和Sequential的使用
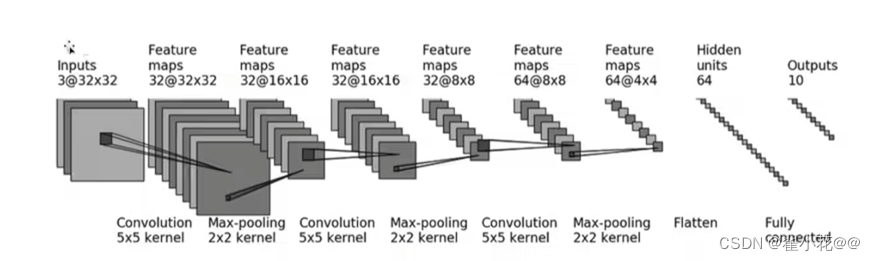
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.Linear1 = Linear(1024, 64)
# self.Linear2 = Linear(64, 10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.Linear1(x)
# x = self.Linear2(x)
x = self.model1(x)
return x
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
writer=SummaryWriter("logs_seq")
writer.add_graph(tudui,input)
writer.close()
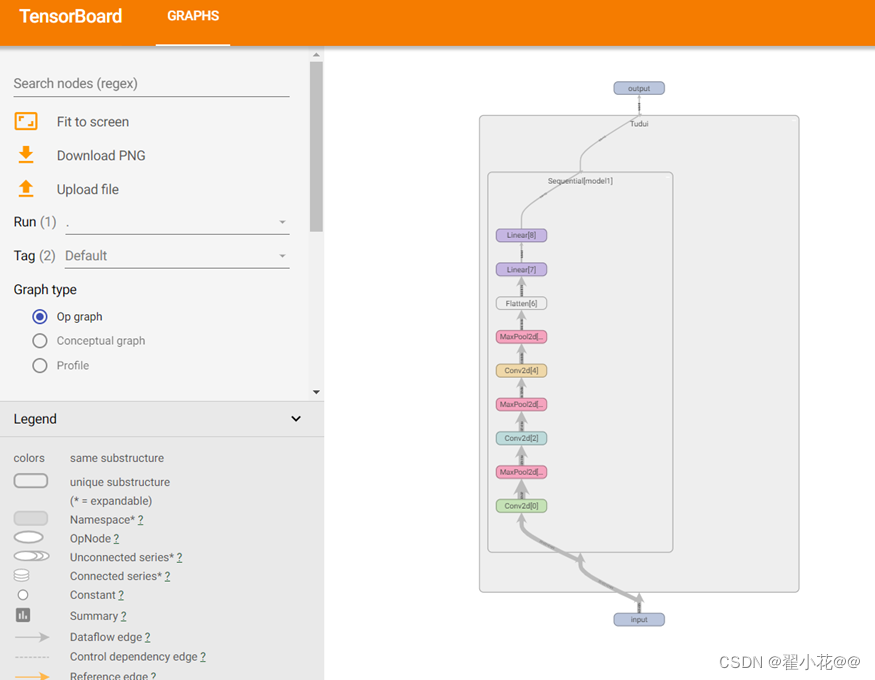















 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









