






导包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
数据概览
file_path = '/home/mw/input/tnb9321/diabetes.csv'
diabetes_data = pd.read_csv(file_path)
diabetes_data.head()
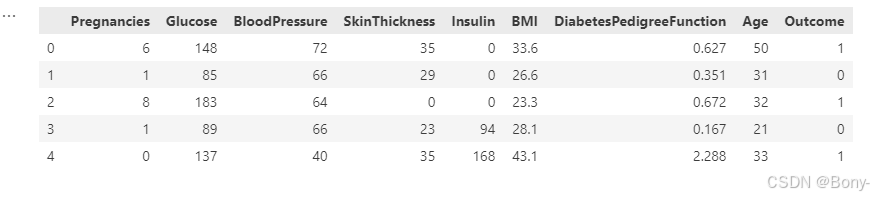
数据集包含以下列:
- Pregnancies:怀孕次数
- Glucose:血糖水平
- BloodPressure:血压
- SkinThickness:皮肤厚度
- Insulin:胰岛素
- BMI:体重指数
- DiabetesPedigreeFunction:糖尿病遗传函数
- Age:年龄
- Outcome:结果(1表示有糖尿病,0表示没有)
基本统计分析
diabetes_data.describe()
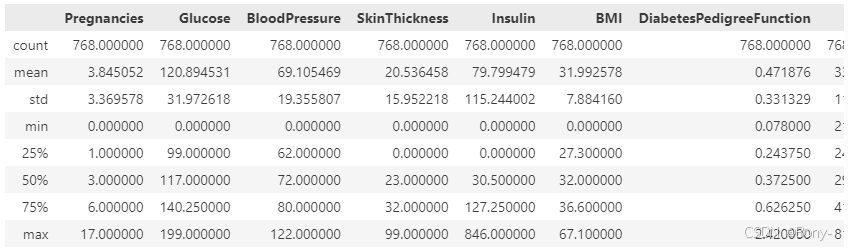
从统计数据中,我们可以看到一些现象:
- 孕娠次数的范围是0到17次,平均值为3.85次。
- 血糖水平的平均值约为120.89,但标准差较大,达到31.97,表明数据分布较广。
- 血压的平均值为69.11,标准差为19.36。
- 皮肤厚度的最小值为0,这可能意味着有缺失值或测量误差。
- 胰岛素的范围很广,从0到846,平均值约为79.80。
- 体重指数(BMI)的平均值为31.99,标准差为7.88。
- 糖尿病遗传函数的平均值为0.47,标准差为0.33。
- 年龄的范围是21到81岁,平均值为33.24岁。
- 结果(Outcome)列表示患者是否患有糖尿病,其中1表示有糖尿病,0表示没有。数据集中大约有34.90%的样本患有糖尿病。
检查数据集中是否存在缺失值
missing_values = diabetes_data.isnull().sum()
missing_values
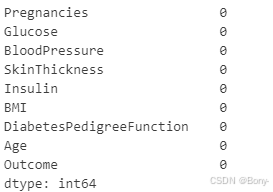
数据集中没有缺失值,我们可以直接进行分析而无需进行缺失值处理。
数据的分布和特征之间的关系
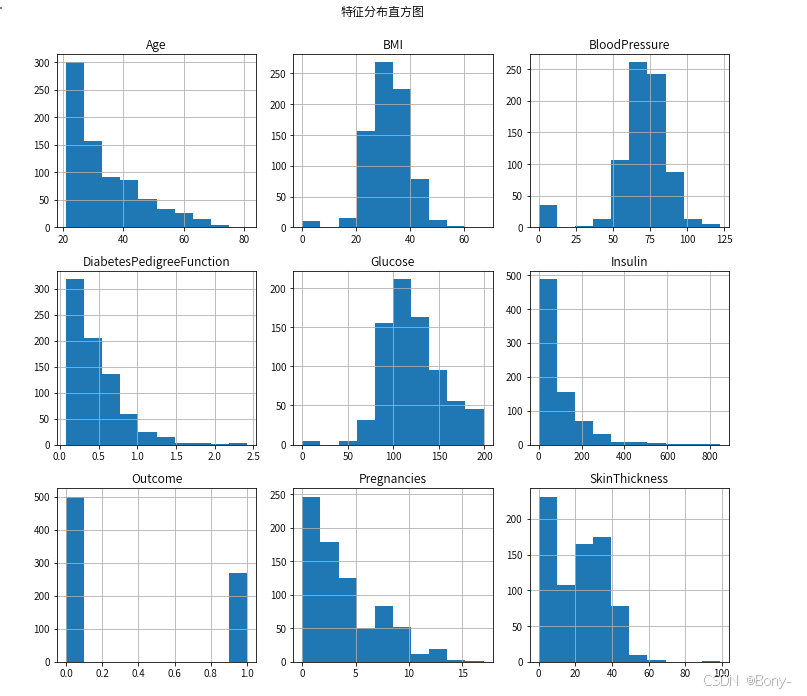
diabetes_data.hist(figsize=(10, 10))
plt.suptitle('特征分布直方图')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
plt.figure(figsize=(8, 6))
sns.scatterplot(data=diabetes_data, x='Glucose', y='BMI', hue='Outcome', palette=['blue', 'red'])
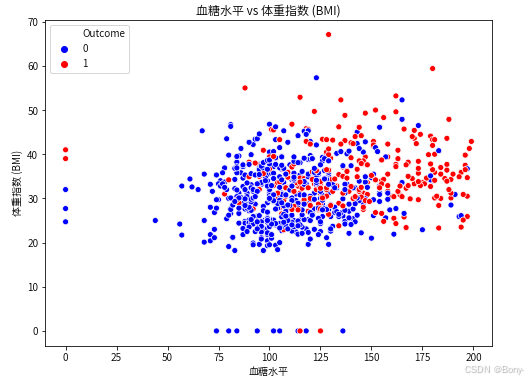
plt.title('血糖水平 vs 体重指数 (BMI)')
plt.xlabel('血糖水平')
plt.ylabel('体重指数 (BMI)')
plt.show()
plt.figure(figsize=(10, 8))
correlation_matrix = diabetes_data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
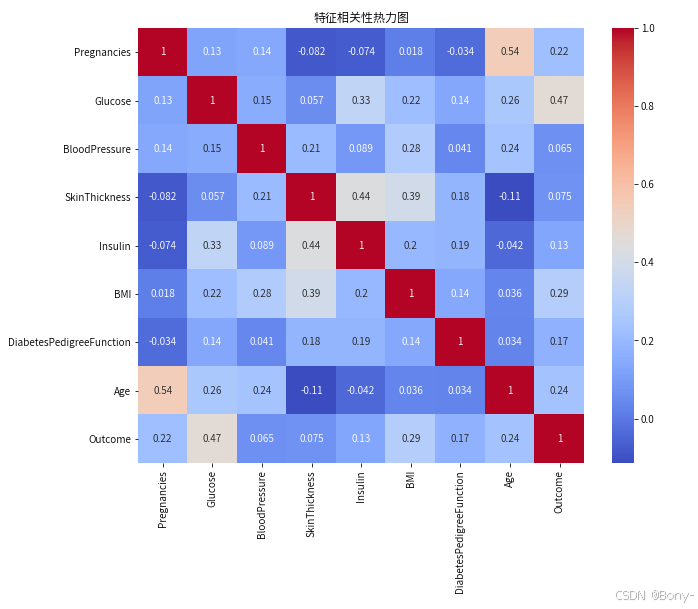
plt.title('特征相关性热力图')
plt.show()
- 从直方图中,我们可以观察到以下特点:
- 孕娠次数分布:大多数患者的妊娠次数在0到6次之间。
- 血糖水平分布:血糖水平的分布呈现出右偏态,大多数患者的血糖水平在100以下,但也有一部分患者的血糖水平较高。
- 血压分布:血压的分布相对均匀,大多数患者的血压在60到80之间。
- 皮肤厚度分布:大部分患者的皮肤厚度在0到40之间,但也有一些极端值。
- 胰岛素分布:胰岛素的分布呈现出明显的右偏态,大多数患者的胰岛素水平在0到200之间,但也有一部分患者的胰岛素水平较高。
- BMI分布:BMI的分布相对均匀,大多数患者的BMI在20到40之间。
- 糖尿病遗传函数分布:糖尿病遗传函数的分布呈现出右偏态,大多数患者的遗传函数值在0到1之间。
- 年龄分布:年龄的分布呈现出右偏态,大多数患者的年龄在20到40岁之间。
- 从血糖水平与BMI的散点图中,我们可以看到:
- 血糖水平较高的患者往往具有更高的BMI。
- 红色点表示患有糖尿病的患者,蓝色点表示没有糖尿病的患者。从这个图中可以看出,血糖水平较高且BMI较高的患者更有可能患有糖尿病。
- 从特征相关性热力图中,我们可以观察到以下特点:
- 血糖水平与BMI、年龄和糖尿病遗传函数之间存在较强的正相关关系。
- 血压与皮肤厚度、年龄之间存在较强的正相关关系。
- 胰岛素与血糖水平、BMI之间存在较强的正相关关系。
机器学习模型的选择
选择适合的机器学习模型通常取决于数据集的特性以及我们想要解决的问题。对于这个糖尿病数据集,可以考虑以下几种模型:
- 逻辑回归(Logistic Regression):
- 适用于二分类问题,如本数据集的糖尿病预测(有糖尿病或没有糖尿病)。
- 简单、易于实现,且结果易于解释。
- 决策树(Decision Tree):
- 可以处理非线性关系,易于理解。
- 但可能容易过拟合,需要适当的剪枝。
- 随机森林(Random Forest):
- 是决策树的集成方法,可以减少过拟合,通常性能较好。
- 但模型相对复杂,计算成本较高。
- 支持向量机(SVM):
- 在高维空间中寻找最佳分离超平面,适用于中小型数据集。
- 需要选择合适的核函数和惩罚参数。
- 梯度提升机(Gradient Boosting Machine, GBM):
- 是一种强大的集成学习算法,通常性能很好。
- 但需要调优多个参数,且训练时间可能较长。
- 神经网络(Neural Networks):
- 适用于复杂的数据分布,可以通过添加隐藏层来捕捉复杂的特征关系。
- 需要大量的数据来训练,且训练过程可能较慢。
对于这个数据集,由于它相对较小且特征数量不多,我们可以先尝试使用逻辑回归和决策树作为初步的模型,然后根据性能考虑是否需要使用更复杂的模型。
逻辑回归和决策树模型的使用’
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 将数据集拆分为训练集和测试集
X = diabetes_data.drop('Outcome', axis=1)
y = diabetes_data['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化模型
logistic_regression_model = LogisticRegression()
decision_tree_model = DecisionTreeClassifier(random_state=42)
# 训练模型
logistic_regression_model.fit(X_train, y_train)
decision_tree_model.fit(X_train, y_train)
# 进行预测
logistic_regression_predictions = logistic_regression_model.predict(X_test)
decision_tree_predictions = decision_tree_model.predict(X_test)
# 评估模型
logistic_regression_accuracy = accuracy_score(y_test, logistic_regression_predictions)
decision_tree_accuracy = accuracy_score(y_test, decision_tree_predictions)
logistic_regression_cm = confusion_matrix(y_test, logistic_regression_predictions)
decision_tree_cm = confusion_matrix(y_test, decision_tree_predictions)
logistic_regression_report = classification_report(y_test, logistic_regression_predictions)
decision_tree_report = classification_report(y_test, decision_tree_predictions)
print("逻辑回归模型评估结果:")
print(f"准确率: {logistic_regression_accuracy:.2f}")
print("混淆矩阵:")
print(logistic_regression_cm)
print("分类报告:")
print(logistic_regression_report)
print("\n决策树模型评估结果:")
print(f"准确率: {decision_tree_accuracy:.2f}")
print("混淆矩阵:")
print(decision_tree_cm)
print("分类报告:")
print(decision_tree_report)

- 从模型评估结果来看,逻辑回归和决策树模型在这个数据集上的性能相似,准确率都约为75%。
- 混淆矩阵显示,两种模型在预测没有糖尿病的样本时表现较好,但在预测有糖尿病的样本时性能相对较差。
- 分类报告提供了更详细的评估指标,包括精确度、召回率和F1分数。逻辑回归和决策树在这些指标上的表现也相似。
- 考虑到模型的简洁性和易于解释性,逻辑回归可能是一个更好的选择,尤其是对于临床应用来说。
注意
# 若需要完整数据集以及代码请点击以下链接
https://mbd.pub/o/bread/mbd-Z5ycm5dq


















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











