










上一篇博客介绍了单隐层BP神经网络的优化:【Matlab智能算法】PSO优化(双隐层)BP神经网络算法,本篇博客将介绍双隐层BP神经网络的优化。
1.优化思路
BP神经网络的隐藏节点通常由重复的前向传递和反向传播的方式来决定,通过修改或构造训练方式改隐藏的节点数,相应的初始权重和偏置也会随之变化,从而影响网络的收敛和学习效率。为了减少权重和偏置对模型的影响,采用粒子群算法对BP神经网络模型的权重和偏置进行优化,从而加快网络的收敛速度和提高网络的学习效率。
优化的重点在于如何构造关于模型权重和偏置的目标函数,即PSO的适应度函数的编写。将PSO(粒子群优化算法)的适应度函数设为预测效果和测试输出的误差绝对值,通过BP神经网络训练得到不同权重和偏置对应的适应度,当寻找的权重和偏置使得适应度最小,即误差最小时,则为最优权值和偏置,再将最优值返回用于构建BP神经网络。
双隐层神经网络相比于单隐层神经网络不仅增多了一个隐含层,权重和偏置的数量也增多,确定权重和偏置的数量尤为重要。关于权重和偏置的设定,可以参考:MATLAB中多层网络的net.lw{i,j}和net.b{k}的含义:
先假设神经网络结构,{ 9 [80 50 20] 1 };9为输入层,[80 50 20]为隐层,1为输出层。
net.iw{1,1} 表示 输入层 到 第1层隐层 的权重,为80*9的矩阵;
net.lw{2,1} 表示 第1层隐层 到 第2层隐层 的权重,为50*80的矩阵;
net.lw{3,2} 表示 第2层隐层 到 第3层隐层 的权重,为20*50的矩阵;
net.lw{4,3} 表示 第3层隐层 到 输出层 的权重,为1*20的矩阵;
net.b{1} 表示 第1层隐层 的偏置,为80*1的矩阵;
net.b{2} 表示 第2层隐层 的偏置,为50*1的矩阵;
net.b{3} 表示 第3层隐层 的偏置,为20*1的矩阵;
net.b{4} 表示 输出层 的偏置,为1*1的矩阵;
2.测试函数
y
=
x
1
2
+
x
2
2
y = x_1^2+x_2^2
y=x12+x22
要求:拟合未知模型(预测)。
条件:已知模型的一些输入输出数据。
已知一些输入输出数据(用rand函数生成输入,然后代入表达式生成输出):
for i=1:4000
input(i,:)=10*rand(1,2)-5;
output(i)=input(i,1)^2+input(i,2)^2;
end
3.完整代码
data.m
for i=1:4000
input(i,:)=10*rand(1,2)-5;
output(i)=input(i,1)^2+input(i,2)^2;
end
output=output';
save data input output
H55PSOBP_fun.m
function error = H55PSOBP_fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn)
%提取
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1);
w3=x(inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum);
B3=x(inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum+outputnum);
%网络进化参数
net.trainParam.epochs=20;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00001;
net.trainParam.show=100;
net.trainParam.showWindow=0;
%网络权值赋值
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,hiddennum1,hiddennum);
net.lw{3,2}=reshape(w3,outputnum,hiddennum1);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=reshape(B2,hiddennum1,1);
net.b{3}=B3;
%网络训练
net=train(net,inputn,outputn);
an=sim(net,inputn);
error=sum(abs(an-outputn));
H55PSOBP.m
BP神经网络结构为 2-5-5-1
%% 清空环境
clc
tic
%读取数据
load data input output
%节点个数
inputnum=2;
hiddennum=5;
hiddennum1=5;
outputnum=1;
opnum=inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum+outputnum;
% 需要优化的参数个数
%% 训练数据预测数据提取及归一化
%从1到4000间随机排序
k=rand(1,4000);
[m,n]=sort(k);
%划分训练数据和预测数据
input_train=input(n(1:3900),:)';
output_train=output(n(1:3900),:)';
input_test=input(n(3901:4000),:)';
output_test=output(n(3901:4000),:)';
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
%构建网络
net=newff(inputn,outputn,[hiddennum, hiddennum1]);
% 参数初始化
%粒子群算法中的两个参数
c1 = 1.49445;
c2 = 1.49445;
maxgen=100; % 进化次数
sizepop=30; %种群规模
%个体和速度最大最小值
Vmax=1;
Vmin=-1;
popmax=5;
popmin=-5;
for i=1:sizepop
pop(i,:)=5*rands(1,opnum);
V(i,:)=rands(1,opnum);
fitness(i)=H55PSOBP_fun(pop(i,:),inputnum,hiddennum,hiddennum1,outputnum,net,inputn,outputn);
end
% 个体极值和群体极值
[bestfitness bestindex]=min(fitness);
zbest=pop(bestindex,:); %全局最佳
gbest=pop; %个体最佳
fitnessgbest=fitness; %个体最佳适应度值
fitnesszbest=bestfitness; %全局最佳适应度值
%% 迭代寻优
for i=1:maxgen
i;
for j=1:sizepop
%速度更新
V(j,:) = V(j,:) + c1*rand*(gbest(j,:) - pop(j,:)) + c2*rand*(zbest - pop(j,:));
V(j,find(V(j,:)>Vmax))=Vmax;
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.2*V(j,:);
pop(j,find(pop(j,:)>popmax))=popmax;
pop(j,find(pop(j,:)<popmin))=popmin;
%自适应变异
pos=unidrnd(opnum);
if rand>0.95
pop(j,pos)=5*rands(1,1);
end
%适应度值
fitness(j)=H55PSOBP_fun(pop(j,:),inputnum,hiddennum,hiddennum1,outputnum,net,inputn,outputn);
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnessgbest(j)
gbest(j,:) = pop(j,:);
fitnessgbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnesszbest
zbest = pop(j,:);
fitnesszbest = fitness(j);
end
end
yy(i)=fitnesszbest;
end
%% PSO结果分析
plot(yy)
title(['适应度曲线 ' '终止代数=' num2str(maxgen)]);
xlabel('进化代数');ylabel('适应度');
x=zbest;
%% 把最优初始阈值权值赋予网络预测
% %用PSO优化的BP网络进行值预测
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1);
w3=x(inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum);
B3=x(inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum+1: ...
inputnum*hiddennum+hiddennum+hiddennum*hiddennum1+hiddennum1+hiddennum1*outputnum+outputnum);
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,hiddennum1,hiddennum);
net.lw{3,2}=reshape(w3,outputnum,hiddennum1);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=reshape(B2,hiddennum1,1);
net.b{3}=B3;
%% PSO-BP网络训练
%网络进化参数
net.trainParam.epochs=120;
net.trainParam.lr=0.005;
net.trainParam.goal=4e-8;
%网络训练
[net,per2]=train(net,inputn,outputn);
%% BP网络训练
% %初始化网络结构
net1=newff(inputn,outputn,[hiddennum,hiddennum1]); % BP网络
net1.trainParam.epochs=120;
net1.trainParam.lr=0.005;
net1.trainParam.goal=4e-8;
%网络训练
net1=train(net1,inputn,outputn);
%% PSO-BP网络预测
%数据归一化
inputn_test=mapminmax('apply',input_test,inputps);
inputn_train=mapminmax('apply',input_train,inputps);
an=sim(net,inputn_test);
an1=sim(net,inputn_train);
test_PSOBP=mapminmax('reverse',an,outputps);
train_PSOBP=mapminmax('reverse',an1,outputps);
%% BP网络预测
%网络预测输出
an2=sim(net1,inputn_test);
an3=sim(net1,inputn_train);
test_BP=mapminmax('reverse',an2,outputps);
train_BP=mapminmax('reverse',an3,outputps);
%% PSO-BP误差输出
error_PSOBP=test_PSOBP-output_test;
disp('PSO-BP results:');
errorsum_PSOBP=sum(abs(error_PSOBP))
%% PSO-BP结果绘图
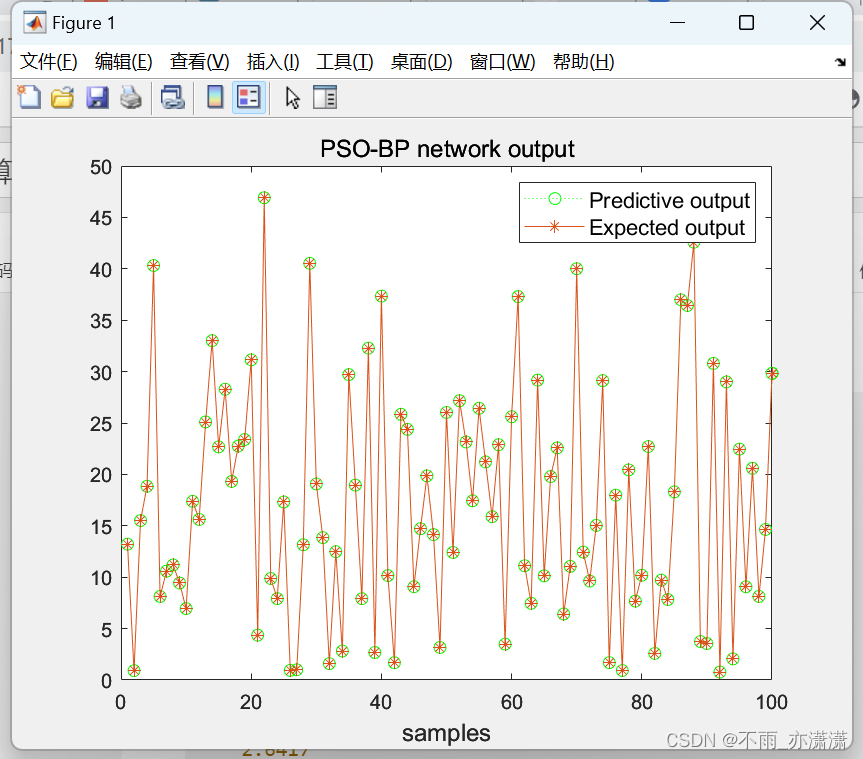
figure(1);
plot(test_PSOBP,':og');
hold on
plot(output_test,'-*');
legend('Predictive output','Expected output','fontsize',10.8);
title('PSO-BP network output','fontsize',12);
xlabel("samples",'fontsize',12);
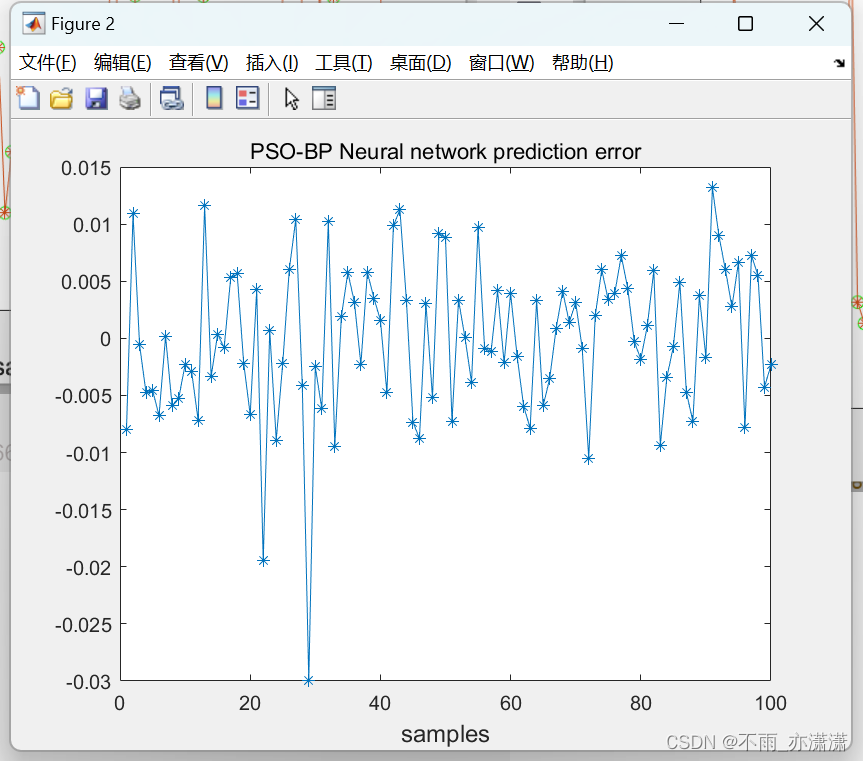
figure(2);
plot(error_PSOBP,'-*');
title('PSO-BP Neural network prediction error');
xlabel("samples",'fontsize',12);
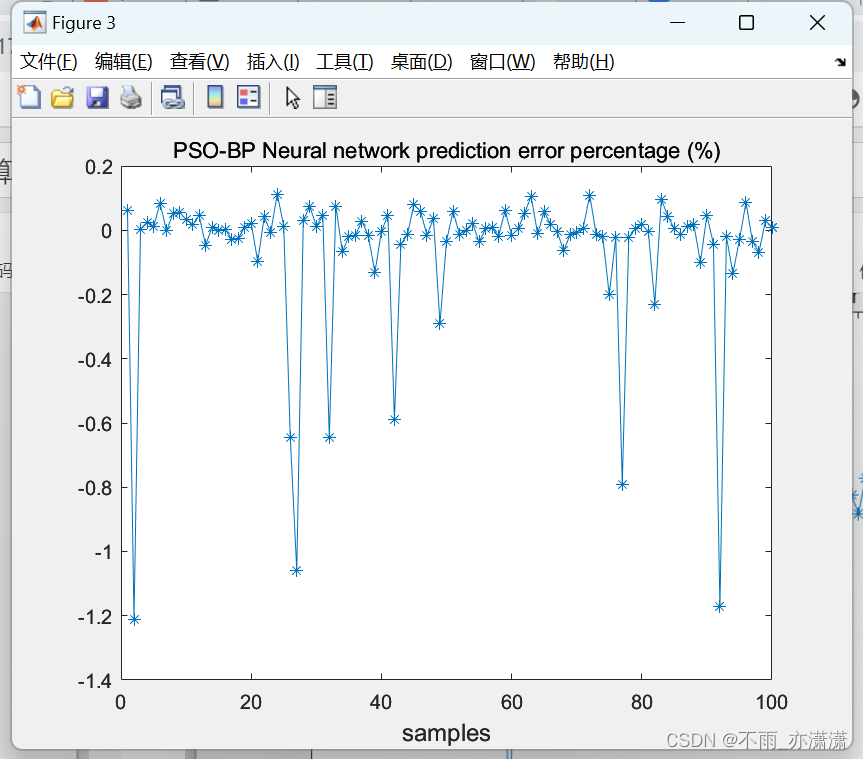
figure(3);
plot(100*(output_test-test_PSOBP)./output_test,'-*');
title('PSO-BP Neural network prediction error percentage (%)');
xlabel("samples",'fontsize',12);
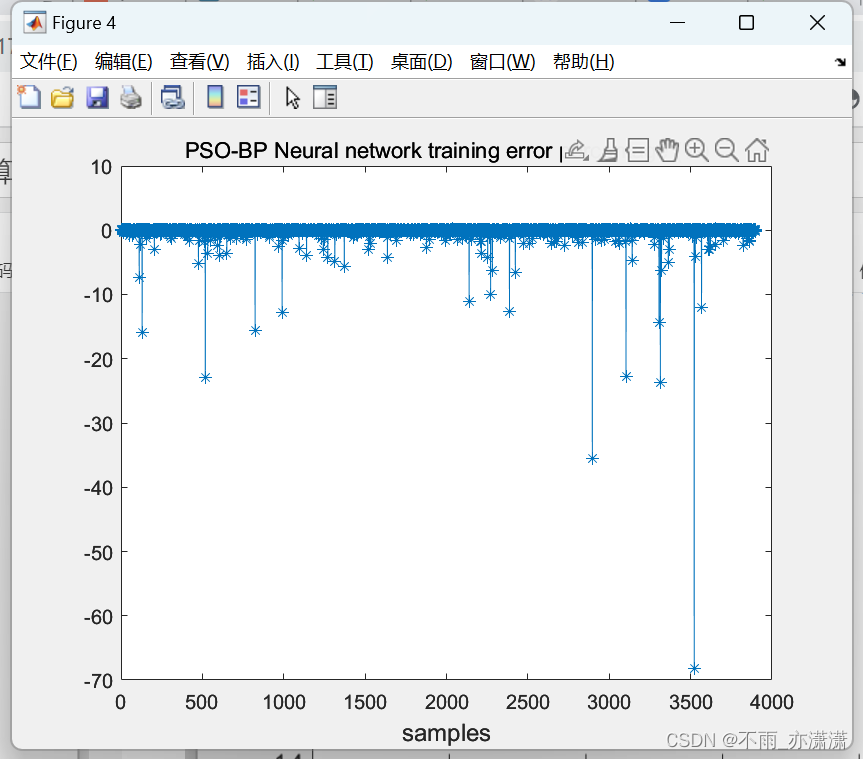
figure(4);
plot(100*(output_train-train_PSOBP)./output_train,'-*');
title('PSO-BP Neural network training error percentage (%)');
xlabel("samples",'fontsize',12);
%% BP误差输出
error_BP=test_BP-output_test;
disp('BP results:');
errorsum_BP=sum(abs(error_BP))
%% BP结果绘图
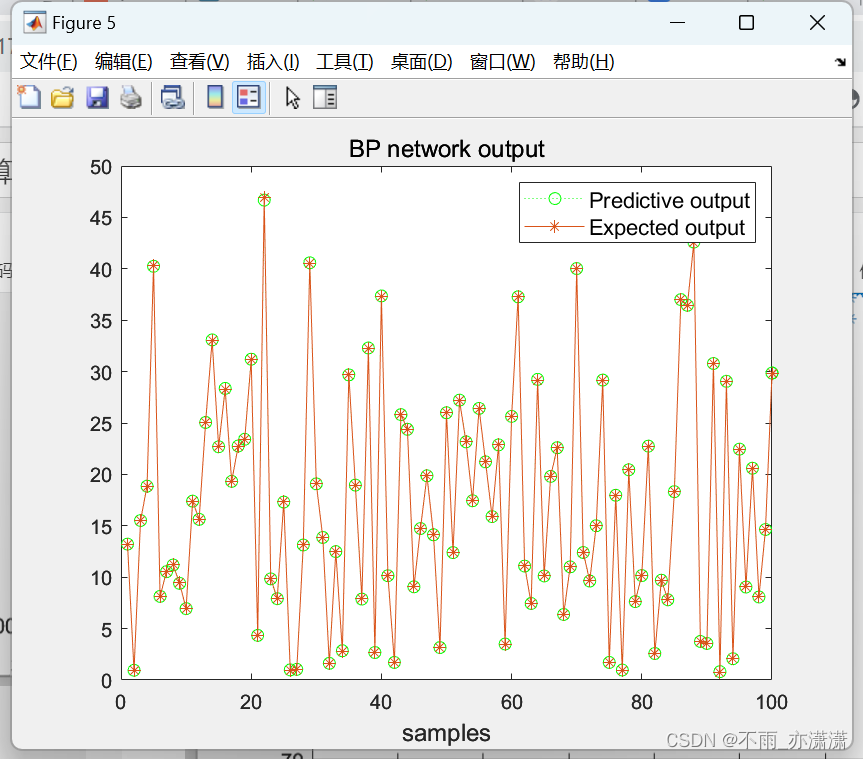
figure(5);
plot(test_BP,':og');
hold on
plot(output_test,'-*');
legend('Predictive output','Expected output','fontsize',10.8);
title('BP network output','fontsize',12);
xlabel("samples",'fontsize',12);
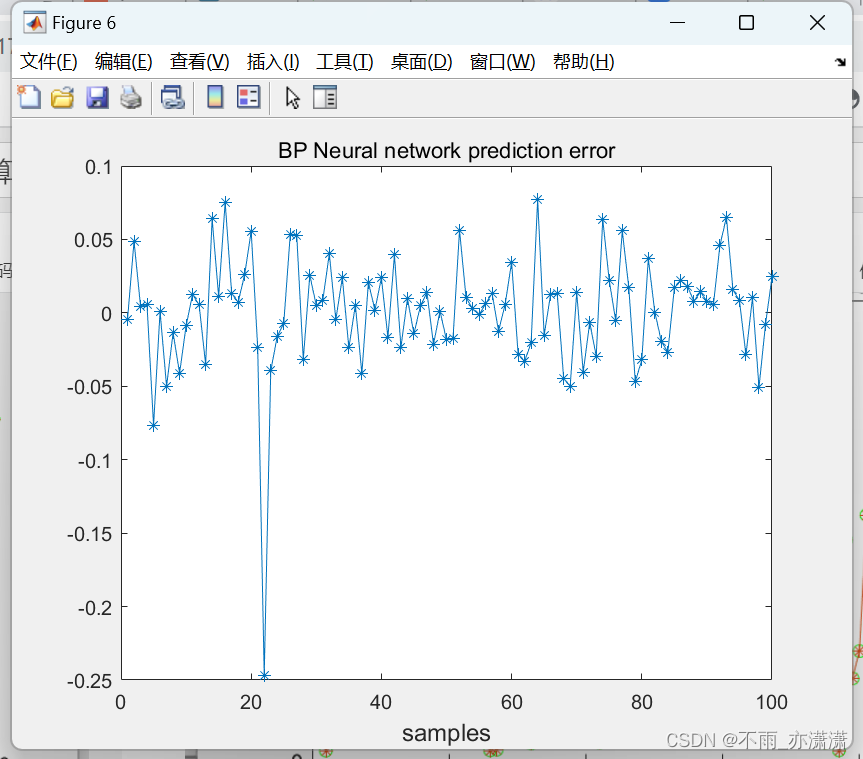
figure(6);
plot(error_BP,'-*');
title('BP Neural network prediction error');
xlabel("samples",'fontsize',12);
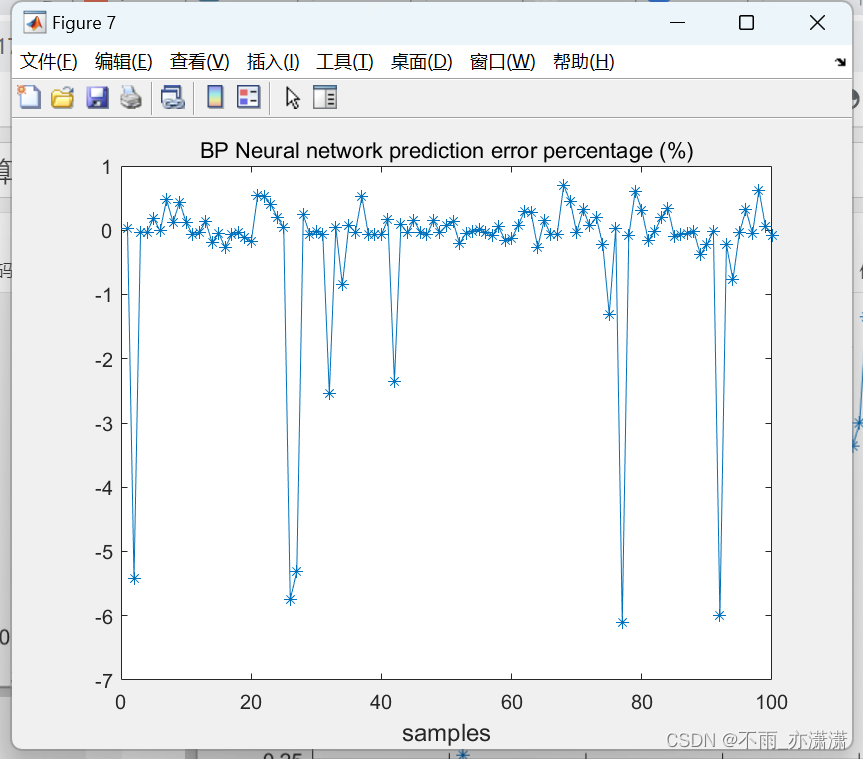
figure(7);
plot(100*(output_test-test_BP)./output_test,'-*');
title('BP Neural network prediction error percentage (%)');
xlabel("samples",'fontsize',12);
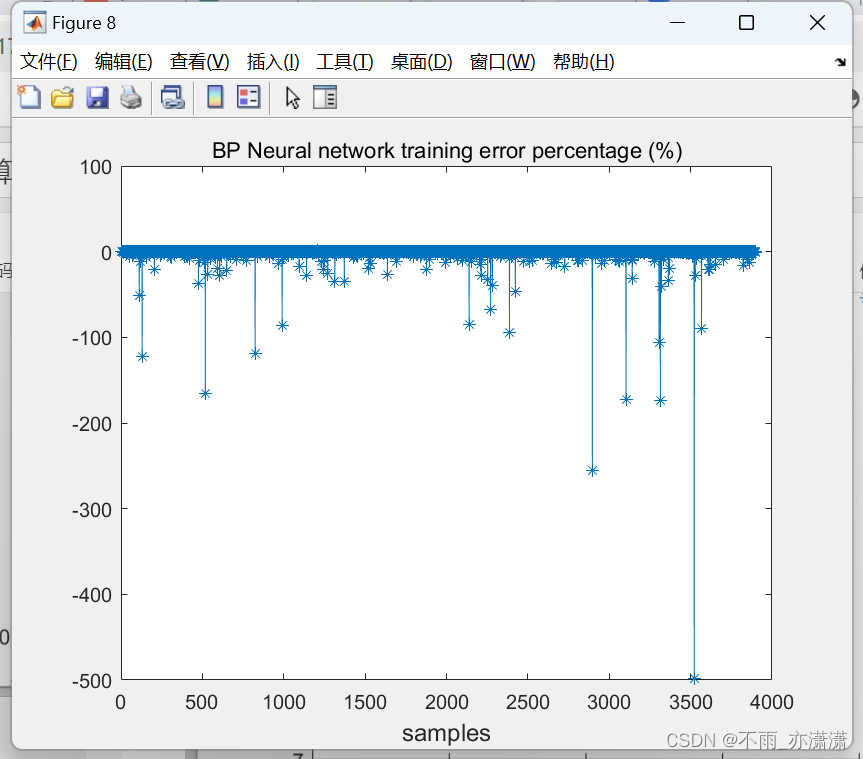
figure(8);
plot(100*(output_train-train_BP)./output_train,'-*');
title('BP Neural network training error percentage (%)');
xlabel("samples",'fontsize',12);
toc
4.运行效果
输出:
PSO-BP results:
errorsum_PSOBP =
0.5269
BP results:
errorsum_BP =
2.6417
历时 217.421716 秒。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











