







本文参考知乎:古月居
梯度下降是机器学习中的常用算法,通过不断迭代计算函数的梯度,判断该点的某一方向和目标之间的距离,最终求得最小的损失函数后反推相关参数,为建立线性模型提供支持。
简单说就是:构建一个误差函数,求这个误差函数的最小值,使用梯度下降可以实现

这个图是误差函数的图像,我们要找出最低点
方法:梯度下降
具体过程:
预测模型:
u为偏差值,也是真实值和预测值的误差
损失函数:求u的最小值
在求最小值(利用求导)的过程中|u|没有优良性,所以我们通常用u²代替。
定义一个损失函数
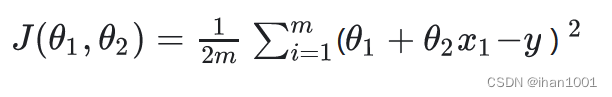
2是为了求导后没有常数。
此时,利用梯度下降的方法为
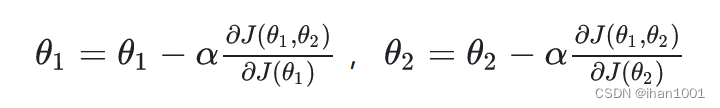


梯度下降的详细算法:
代数表示法
假设预测模型是
hθ(x1,x2,…xn)=θ0+θ1x1+…+θnxn, 其中θi (i = 0,1,2… n)为模型参数,xi (i = 0,1,2… n)为每个样本的n个特征值。这个表示可以简化,我们增加一个特征x0=1
预测函数:

损失函数为:

梯度下降更新函数:

整合(样本中没有x0上式中令所有的xj0为1)

从这个例子可以看出当前点的梯度方向是由所有的样本决定的。
不同的梯度下降方法
1.批量梯度下降法
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新,也就是上面的例子
2.随机梯度下降法
仅仅选取一个样本j来求梯度。对应的更新公式是:

随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。
对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度太慢
对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
于是提出
小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样本来迭代,1<x<m。根据样本的数据,可以调整这个x的值。对应的更新公式是:

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









