







DCGAN!
文章目录
论文结构
- Introduction
- Related work
2.1 Representation learning from unlabeled data
2.2 Generating natural images
2.3 Visualizing the internals of CNNs - Approach and model architecture
- Details of adversarial training
4.1 LSUN
4.1.1 Deduplication
4.2 Faces
4.3 Imagenet-1k - Empirical validation of DCGANs capabilities
5.1 Classifying CIFAR-10 using GANs as a feature extractor
5.2 Classifying SVHN digits using GANs as a feature
extractor - Investigating and visualizing the internals of the networks
6.1 Walking in the latent space
6.2 Visualizing the discriminator features
6.3 Manipulating the generator representation
6.3.1 Forgetting to draw certain objects
6.3.2 Vector arithmetic on face samples - Conclusion and future work
摘要
Abstract: In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations
摘要核心
- 希望能让CNN在无监督学习上,达到与监督学习一样的成功
- 通过架构约束,构建了深度卷积生成对抗网络(DCGAN)
- 证明了DCGAN是目前先进的无监督学习网络
- 证明了DCGAN的生成器和判别器学习到了从物体细节到整体场景的多层次表征
- 证明了DCGAN判别器提取的图像特征具有很好的泛化性
研究背景
表征学习
•表征(representation)、特征(feature)、编码(code)

-
好的表征
-
具有很强的表示能力,即同样大小的向量可以表示更多信息
-
使后续的学习任务变得简单,即需要包含更高层的语义信息
-
具有泛化性,可以应用到不同领域
-
-
表征学习的方式
- 无监督表征学习
- 有监督表征学习
模型可解释性
—— Interpretation is the process of giving explanations to Human
•
决策树就是一个具有良好可解释性的模型
•
使用特征可视化方法
•
使用数据分析,可以找到数据中一些具有代表性和不具代表性的样本
•
NIPS 2017会议上,Yann LeCun:人类大脑是非常有限的,我们没有那么多脑容量去研究所有东西的可解释性
研究成果
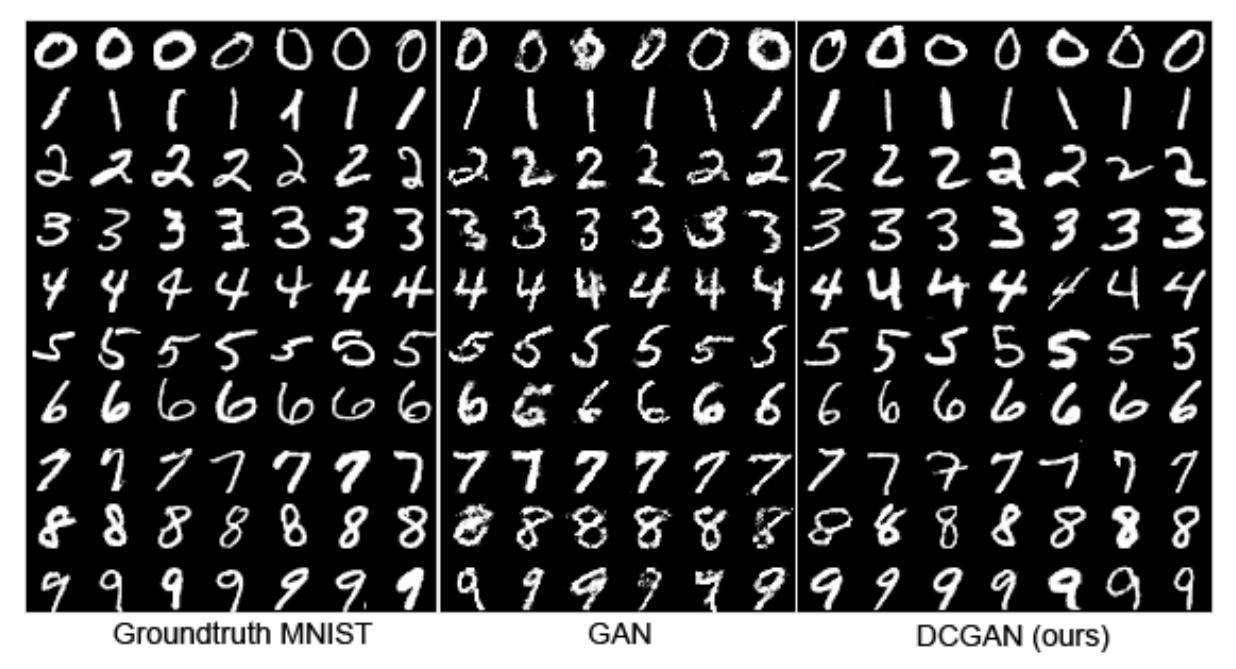


研究意义
- 早期的GAN在图像上仅局限MNIST这样的简单数据集中,DCGAN使GAN在图像生成任务上的效果大大提升
- DCGAN几乎奠定了GAN的标准架构,之后GAN的研究者们不用再过多关注模型架构和稳定性,可以把更多的精力放在任务本身上,从而促进了GAN在16年的蓬勃发展
- 开创了GAN在图像编辑上的应用
模型结构
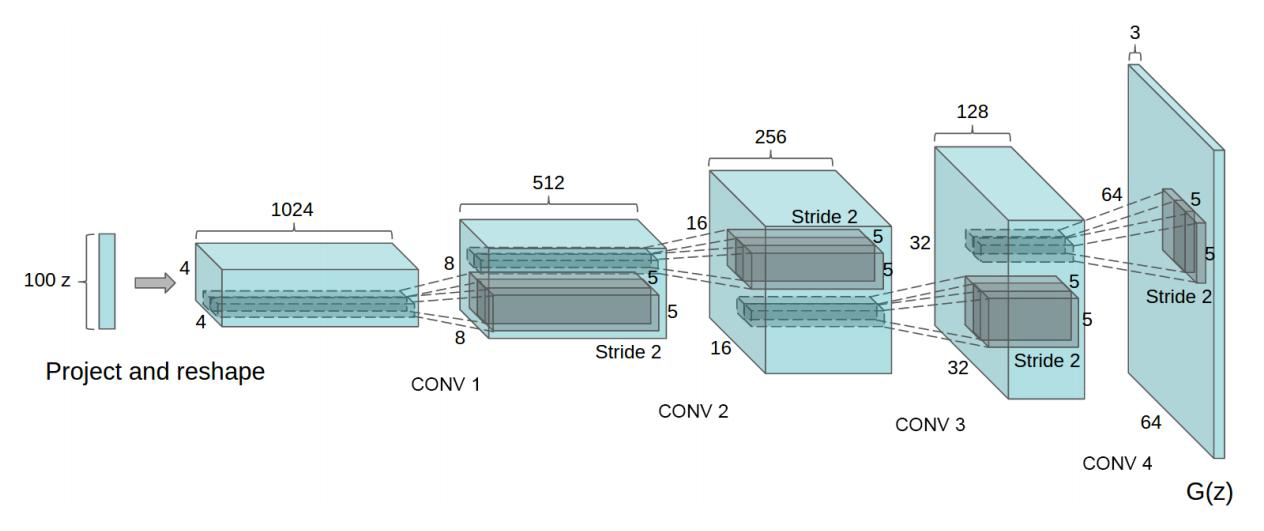
•
所有的pooling层使用strided卷积(判别器)和fractional-strided卷积(生成器)进行替换
•
使用Batch Normalization
•
移除全连接的隐层,让网络可以更深
•
在生成器上,除了输出层使用Tanh外,其它所有层的激活函数都使用ReLU
•
判别器所有层的激活函数都使用LeakyReLU
训练细节
•
训练图像的预处理,只做了到 [-1, 1] 的值域缩放
•
使用mini-batch随机梯度下降来训练网络, batch size大小为128
•
采用均值为0 标准差为0.02的正态分布,来对所有权重进行初始化
•
对于LeakyReLU激活函数,leak的斜率设置为0.2
•
优化器使用Adam,而不是此前GAN网络用的momentum
•
Adam的学习速率使用0.0002,而非原论文建议的0.001
•
Adam的参数momentum term β1,原论文建议的0.9会导致训练震荡和不稳定,将其减少至0.5可以让训练更加稳定
图像生成
LSUN

•
没有使用 Data Augmentation
•
在LSUN上训练一个3072-128-3072的自编码器,用它从图像中提取128维特征,再经过ReLU层激活后作为图像的语义hash值
•
对生成图像和训练集使用上面的编码器,提取128维的语义hash值,进行重复性检测
•
检测到了大约275000左右数量的重复数据(LSUN数据集大小为300多万)
FACES

- 从DBpedia上获取人名,并保证他们都是当代人
- 用这些人名在网络上搜索,收集其中包含人脸的图像,得到了来自1万人的300万张图像
- 使用OpenCV的人脸检测算法,截取筛选出较高分辨率的人脸,最终得到了大约35万张人脸图像
- 训练时没有使用 Data Augmentation
无监督表征学习
Unsupervised representation learning
CIFAR-10
•
在Imagenet-1k上训练DCGAN
•
使用判别器所有层的卷积特征,分别经过最大池化层,在每一层上得到一个空间尺寸为4*4的特征,再把这些特征做flattened和concatenated,最终得到28672维的向量表示
•
用一个SVM分类器,基于这些特征向量和类别label进行有监督训练

StreetView House Numbers(SVHN)
•
使用与CIFAR-10实验相同的处理流程
•
使用10000个样本来作为验证集,将其用在超参数和模型的选择上
•
随机选择1000个类别均衡的样本,用来训练正则化线性L2-SVM分类器
•
使用相同的生成器结构、相同的数据集,从头训练有监督CNN模型,并使用验证集进行超参数搜索
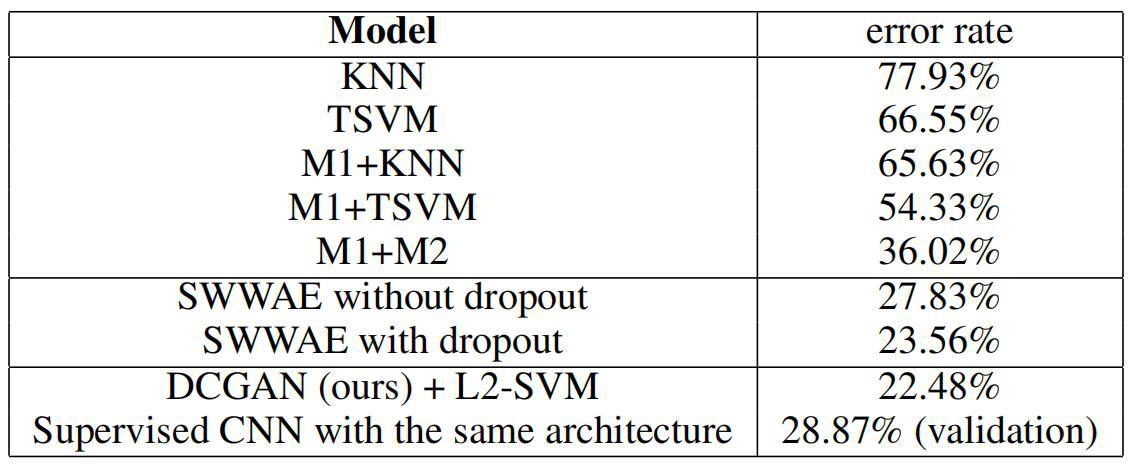
隐空间分析
隐变量空间漫游
•
在latent space上walking,可以判断出模型是否是单纯在记住输入(如果生成图像过渡非常sharp),以及模式崩溃的方式
•
如果在latent space中walking导致生成图像的语义变化(例如添加或删除了对象),我们可以推断模型已经学习到了相关和有趣的表征

去除特定的对象
•
为了研究模型是如何对图像中的特定物体进行表征的,尝试从生成图像中把窗口进行移除
•
选出150个样本,手动标注了52个窗口的bounding box
•
在倒数第二层的conv layer features中,训练一个简单的逻辑回归模型,来判断一个feature activation是否在窗口中
•
使用这个模型,将所有值大于0的特征(总共200个),都从空间位置中移除

人脸样本上的矢量运算
•
vector(”King”) - vector(”Man”) +vector(”Woman”)的结果和向量Queen很接近
•
对单个样本进行操作的结果不是很稳定,而如果使用三个样本的平均值,结果就会好很多

总结展望
• 提出了一套更稳定的架构来训练生成对抗性网络
• 展示了对抗性网络可以很好的学习到图像的表征,并使用在监督学习和生成式的建模上
• 模式崩溃问题仍然存在
• 可以再延伸应用到其他领域,例如视频(做帧级的预测)和声频(用于语音合成的预训练特征)
• 可以对latent space进行更进一步的研究
















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











