






CGAN-论文阅读笔记
论文地址:Conditional Generative Adversarial Nets-ReadPaper论文阅读平台
论文结构
- Introduction
- Related work
2.1 Multi-modal Learning For Image
Labelling - Conditional Adversarial Nets
3.1 Generative Adversarial Nets
3.2 Conditional Adversarial Nets - Experimental Results
4.1 Unimodal
4.2 Multimodal
5 Future Work
摘要
原文
Generative Adversarial Nets [8] were recently introduced as a novel way to train generative models. In this work we introduce the conditional version of generative adversarial nets, which can be constructed by simply feeding the data, y, we wish to condition on to both the generator and discriminator. We show that this model can generate MNIST digits conditioned on class labels. We also illustrate how this model could be used to learn a multi-modal model, and provide preliminary examples of an application to image tagging in which we demonstrate how this approach can generate descriptive tags which are not part of training labels.
摘要核心
- 提出了一个基于生成对抗网络的条件生成式模型
- 在原模型基础上,会输入额外的数据作为条件
- 在原模型基础上,对生成器和判别器都进行了修改
- 在MNIST数据集上,新模型可以生成以数字类别标签为条件的手写数字图像
- 新模型还可以用来做多模态学习,可以生成输入图像相关的描述标签
研究背景
GAN
•
由生成器和判别器组成
•
生成器和判别器由多层感知机实现
•
训练中同时优化生成器和判别器
•
不需要马尔可夫链
•
仅使用反向传播来获得梯度
•
在学习期间不需要推理
多模态学习
•
每一种信息的来源或者形式,都可以称为一种模态
•
多模态机器学习,旨在通过机器学习的方法实现处理和理解多源模态信息的能力
•
目前比较热门的研究方向是图像、视频、音频、语义之间的多模态学习
图像标记
•
用词语对图像中不同内容进行多维度表述
图像描述
•
把一幅图片翻译为一段描述文字
•
获取图像的标记词语
•
理解图像标记之间的关系
•
生成人类可读的句子
词向量模型
•
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型
•
通过词的上下文得到词的向量化表示,并使得语义上相似的单词在向量空间内距离也很近
•
来源于2013年的论文《Efficient Estimation of Word Representation in Vector Space》,有两种方法:CBOW(通过附近词预测中心词)、Skip-gram(通过中心词预测附近的词)
研究意义
Research Meaning
CGAN历史意义
•
提出了一个可用的条件GAN网络结构
•
开启了GAN在多模态学习中的应用
模型总览
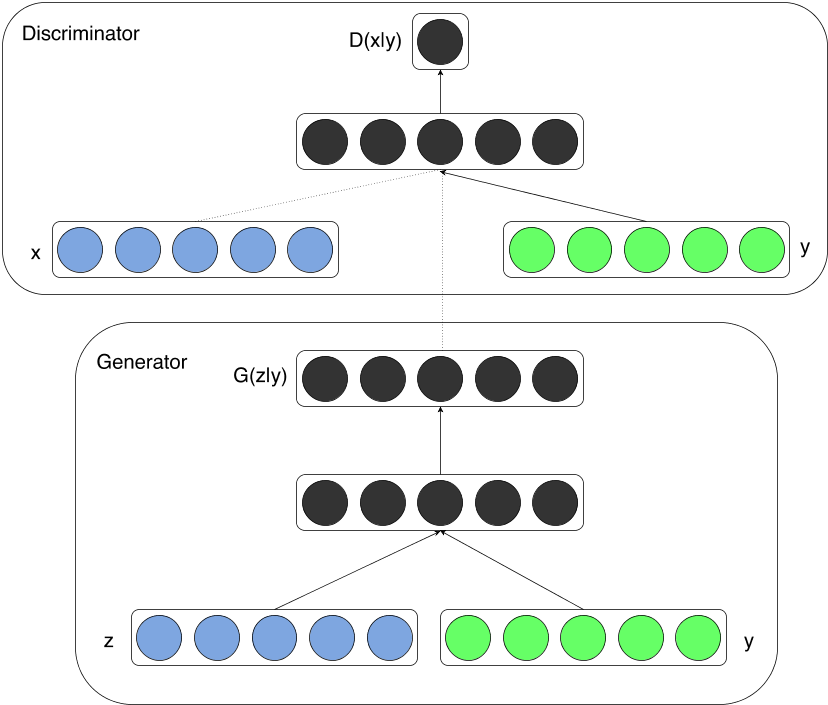
- 在生成器和判别器分别加入相同的条件输入y
- CGAN的网络相对于原始GAN网络并没有变化
- CGAN可以作为一种通用策略嵌入到其它的GAN网络中
价值函数
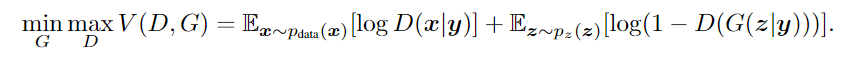
D:
判别器
G:
生成器
原文讲解
z:
随机噪声
data: 训练数据
y:
条件输入
数据集
MNIST
•
手写数字集,源自NIST;28*28的灰度图,训练集60000张,测试集10000张
http://yann.lecun.com/exdb/mnist/
MIRFLICKR-25000
•
源自雅虎Flickr网站的影像数据库,25000张图像,图像拥有多个描述tag
http://press.liacs.nl/mirflickr/mirdownload.html
YFCC 100M
•
源自雅虎Flickr网站的影像数据库,由1亿条产生于2004年至2014年间的多条媒体数据组成,包含了9920万的照片数据以及80万条视频数据,数据包括相应tag
单模态任务
•
采用随机梯度下降,batch size为100
•
初始学习率为0.1,指数衰减到1e-6,衰减系数为1.00004
•
使用初始值为0.5的初始动量,并逐渐增加到0.7
•
在生成器和判别器上都使用概率为0.5的Dropout
•
使用验证集上的最大对数似然估计作为停止点
多模态任务
•
从像Flickr这样的照片网站,可以获得丰富的带用户标记的图像数据
•
用户生成的元数据(UGM),比较接近人类用自然语言描述图像的方式
•
不同的用户会使用不同词汇来描述相同的概念
•
在ImageNet上训练一个类似AlexNet的图像分类模型,使用其最后一个全连接层的输出来提取图像特征
•
使用YFCC100M数据集,训练一个词向量长度为200的 skip-gram模型
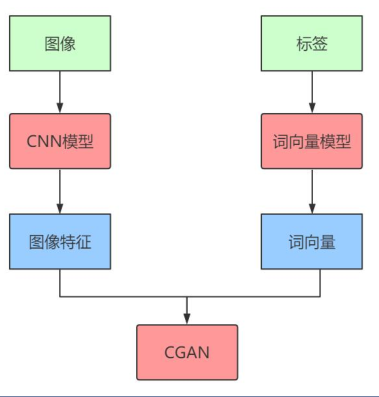
•
超参数和架构是结合使用交叉验证、随机网格搜索和手工选择来确定的
•
采用随机梯度下降,batch size为100
•
初始学习率为0.1,指数衰减至1e-6,衰减系数为1.00004
•
使用初始值为0.5的初始动量,并逐渐增加到0.7
•
在生成器和判别器上都使用概率为0.5的Dropout
论文总结
•
本文中显示的结果非常初步
•
展示了条件对抗网的潜力
•
展示了有趣并且有用的应用范围前景
•
提供更复杂的模型,对其性能和特征的更详细和彻底的分析
•
在多模态任务中,同时使用多个标签
•
•
使用初始值为0.5的初始动量,并逐渐增加到0.7
•
在生成器和判别器上都使用概率为0.5的Dropout
















 1587
1587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











