







核心思路
本文构建了一个基于深度学习的端到端的多视角深度估计网络,用来实现MVS
- 在图像上提取深度图像特征,并且在基于相机锥体上进构建3D cost volume ,通过可微的单映变换将reference camera的参数编码到网络中进行训练
- 使用3D的Unet进行正则化,回归得到深度概率分布,通过在深度方向上计算深度期望来初步生成深度图,再用原来的reference image进行jump connection改进深度over smooth
- 该网络结构可以允许任意的N-view输入,使用基于方差的cost metric将多个特这个映射到一个cost feature中。基于方差可以更好的比较不同特征图之间的差异
Main Idea
传统的MVS方法通常使用NCC或者其他的图像匹配算法进行稠密匹配,恢复3D点云,这些方法在理想的朗伯体上表现良好,但是在弱纹理区域或者反射区域表现欠佳。而且她们虽然都在数值上很出色,但是实际运行结果(reconstruction completeness)上不好
本文提出使用CNN进行图像件匹配来替代以前的图像匹配算法。
MVSNet比其他网络速度快的原因是它每次只计算一张深度图而不是计算整个3D场景。在应用过程中,MVSNet输入一张reference image和若干张source images,输出reference image的深度图像关键的部分是可微的单映变换,将相机参数隐式的编码进网络中,从而将2D图像特征转换成为3Dcost volumes
同时基于方差将多个特征映射到一个cost feature中,再通过3D卷机和回归生成初始的深度图。3Dcost volume是基于相机椎体空间的,而不是传统的欧式空间。

训练评估数据集:DTU数据集
泛化测试:Tanks and Temples
网络结构

整个网络还是深度估计的方向,同时由传统方法的原图进行特征匹配更改到了在特征图层面。在特征提取模块,目的已经是提取深度了,类似原来的单目深度估计。但是由于仅使用每张照片进行估计,没有考虑到图像彼此间的关联,有些点的深度可信度并不是很高。因此后面的代价体正则化就是更新每个像素深度预测的可信度,但显然这种方法的消耗是很大的,由于3DCNN的巨大参数量和各种遮挡、光照问题,即使通过多视图预测的深度值依旧存在问题。包括在后面进行深度假设,在所有的图像都进行0-192的假设没有进行自适应处理,消耗的内存过大。
本质来说,FPN模块就是用来提取深度的。通过下采样将图像放在一个较小的尺度,包含的语义信息更多。
数据流分析
训练时,使用一张ref和三张src作为辅助。输入尺度B*3*H*W
特征提取后,两个stride=2的卷积,第二维被加深,包含邻域特征信息,B*32*H/4*W/4
之后用单应变换将src投射到ref上,投影后构建出代价体,进行深度假设,此时在ref上,B,32,192,H,W,在src上,通过homowarping将src投影到ref上,进行相加,得到最初代价体B,32,192,H,W,在此基础上在每个通道计算方差。
经过3DUnet,在最后有一个prob层,类似soft argmin,得到一个B,1,192,H,W的图像,此时每个pixel代表在某个深度的概率值。
在每个深度上应用softmax,将每个深度的概率值归一化在0-1之间,通过文中的期望公式计算深度,再将第1维删除,最后得到B,H,W的深度图。
Image Features
图像的特征提取是第一步,两个步长为2的卷积操作将原始图像分成了三个大小,再通过步长为1的卷积提取特征,特征提取金字塔。虽然图像被缩小了四倍,但是每个相邻像素之间的信息都被编码到了32维中,这防止密集匹配中丢失上下文信息。
Cost Volume
第二步是由提取到的feature map构建3D cost volume。其中:
- I i I_i Ii代表source image
- K代表相机内参数矩阵
- R代表旋转矩阵
- t代表平移矩阵
- N代表source image的数量
所有的特征图被变换到了reference camera的不同正面平行平面中,形成N个feature volumes。就是对每个source image生成的feature map做一个变换成为平行于reference camera的平面吗(有点不理解,见上图的相机椎体模型,代表平行于相机平面但距离不同的平面)从每个图片变换后的坐标V i到原始的Fi的变化。Vi(d)指的是在深度d处的变换后的第i视角的feature map。用H代表单映矩阵,本质上还是一个坐标变化,从source image的坐标通过公式转换到reference image上。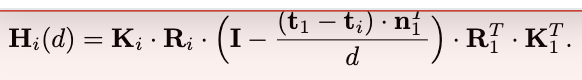
上公式存在问题,这篇帖子关于此公式的问题
这里和以往的方法不同的是在feature级别而不是pixel级别了。
Cost Metric
将多个feature volumes转换成一个cost volume。为了适应任意数量的输入views,本文设计了基于方差的一致性衡量方法。具体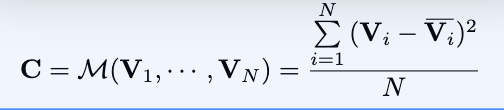
就是用每个Vi减去平均值的平方和。
所有的视角贡献权重是一样的
Cost Volume Regularization
对cost volume进行3D conv来正则化处理,结构类似3DUnet,从图像特征图计算得到的初始代价体很有可能是包含噪声的(由于非朗伯体表面的存在或者视线遮挡的问题),为了预测深度图还需要进行光滑处理。正则化的步骤是对上面的代价体进行优化(refine)以得到概率体。受SurfaceNet等工作的启发,我们使用一个多尺度的3D-CNN网络用于代价体正则化。4个尺度的网络类似于3D版本的UNet,使用编码-解码的结构方式,以相对较小的存储/计算代价在一个大的感受野范围内进行邻域信息聚合。为了减轻网络的计算代价,在第一个3D卷积层后,我们将32通道的代价体缩减为为8通道,将每个尺度的卷积从3层降为2层。最后卷积层的输出为1通道的体(Volume)。最终在深度方向上使用softmax操作进行概率值的归一化。同时还生成一个probability volume P来进行深度推算。
Depth Map
Initial Estimation
使用概率体生成深度图像,一开始采用winner-take-all策略,但是这种方法unable to produce sub-pixel estimation,同时不能进行反向。用每个深度的概率分布乘以实际深度计算得期望深度。其中P(d)代表在深度d处所有的图像推算出的概率。
Probability Map
当深度假设沿摄像机截锥离散采样时,我们只需取最近的四个深度假设的概率和来衡量估计质量。
Depth Map Refinement
concatenate操作+参差网络用来防止过度平滑,主要是把原图像和初始深度图进行连接
Loss
L1方法对GT和refine前后的深度图进行比较。
Limitation
1)提供的地面真实网格不是100%完整的,因此前景后面的一些三角形会被错误地渲染到深度图上作为有效像素,这可能会恶化训练过程。
2)如果一个像素在所有其他视图中都被遮挡,则不能用于训练,但是,如果没有完整的网格表面,我们就不能正确地识别被遮挡的像素。我们希望未来的MVS数据集能够提供具有完整遮挡和背景信息的地面真实深度图。
训练时使用的GT都是自己生成的,深度值的准确性有待考量。
3D卷积资源消耗大,训练成本高















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









