







GAN
2014年提出GAN的概念,里面有很多复杂的公式推导,简单分析一下。
在GAN里面训练两个MLP,一个是生成器G,一个是判别器D。整个网络输入是一个随机噪声,通过真实值来进行监督,让生成器把这段随机噪声变成和真实值相似的分布。其中,D用来对生成器的质量进行评估。形象来说,生成器就像印假钞的团队,判别器像警官。首先训练警官,团队想要把白纸变成钞票,钞票上有花纹水印数字等等。第一次团队把白纸给警官看,警官发现显然和真钞不一样,于是团队回去印刷数字,给警官看,警官发现有数字,但是没有花纹,于是警官知道需要有花纹,判断没有花纹,团队加工花纹,再拿给警察,警察学习到没有水印,发现没有水印之后团队加工水印。直到警察发现不出团队制作的钞票和真钞有什么区别,团队也就成功将白纸变成了钞票。
在两者训练的过程中,G尽可能让D做出更多错误的判断,同时G尽可能少的做出改变,这样G做得少,D严格,生产出的值才是最真实的。这也是文中提出的minimax问题。D输出一个二分类0/1,尽可能让生成器产生的数据真实性接近二分之一。G和D都是MLP。
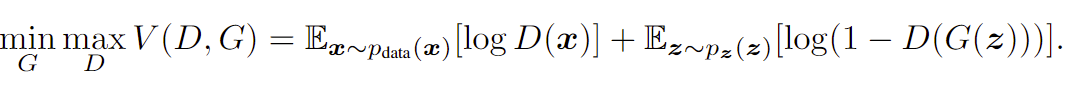
在文中最重要的公式是这个。这两个酷似交叉熵损失函数。其中两个E是两个期望,第一个是真实的x分布趋近于生成的x分布,判别器试图将他们区分开来,第二个是生成器的部分,将原始的随机样本z分布化成生成的样本pz,使用判别器判断错误的概率,也就是1-D(生成器生成的样本)这样就可以看出,判别器想要使得生成的样本和真是样本相似,而生成器尽量减少判别器出错的概率。这样就可以理解。具体算法如下

训练一个GAN可能很困难,它经常会遇到各种问题,其中最主要的问题有以下三点:
- 消失梯度:这种情况经常发生,特别是当判别器太好时,这会阻碍生辰器的改进。使用最佳的判别器时,由于梯度的消失,训练可能失败,因此无法提供足够的信息给生成器改进。
- 模式塌缩:这是指生成器开始反复产生相同的输出(或一小组输出)的现象。如果判别器陷入局部最小值,那么下一个生成器迭代就很容易找到判别器最合理的输出。判别器永远无法学会走出陷阱。
- 收敛失败:由于许多因素(已知和未知),GANs经常无法收敛。
WGAN做了一个简单的修改,用Wasserstein距离(也称为推土机(EM)距离)代替GAN中的Jensen-Shannon散度损失函数。不要忽视这一修改的意义:这是自GAN诞生以来本课题最重要的进展之一,因为EM距离的使用有效地解决了基于散度的GAN的一些突出缺点,从而可以减轻GANs训练中常见的故障模式。
后面也有还能多文章是根据WGAN进行修改的。
StyleGAN
看了stylegan,有点难
解决的问题
在图片合成中的很多方面的理解例如随机特征是缺失的.
生成器将输入的隐码z嵌入一个中间的隐空间。因为输入的隐空间Z必须服从训练数据的概率密度,这在一定程度上导致了不可避免的纠缠,而嵌入的中间的隐空间W不受这个限制,因此可以被解耦。
总之就是输入的latent code容易纠缠,一个特征的变化容易引起其他特征的改变,本文构建了latent space来解耦特征
解决方法
无监督地分离高级属性(人脸姿势、身份)和随机变化(例如雀斑,头发)
实现对生成图像中特定尺度的属性的控制。
引入了风格迁移的思路,将latent code通过FCN映射成为不同的向量控制不同的特征.
同时引入感知路径长度和线性可分性概念.新的生成器允许更线性,更解耦的表示不同的变化因素.

传统的生成器如左图,就是不断地上采样卷积.取消传统的左侧的输入方式,采用右面,使用mapping network f进行投影,将z投影到W空间内,再通过W映射到各个可适应的归一化实例输入,在每一维都有输入(AdaIN),用来添加到每个卷积后面.A是预学习的affine 变化,B是噪声输入每个通道上的扩展参数
由于z是符合均匀分布或者高斯分布的随机变量,所以变量之间的耦合性比较大。举个例子,比如特征:头发长度和男子气概,如果按照z的分布来说,那么这两个特征之间就会存在交缠紧密的联系,头发短了你的男子气概会降低或者增加,但其实现实情况来说,短发男子、长发男子都可以有很强的男子气概。所以我们需要将latent code z进行解耦,才能更好的后续操作,来改变其不同特征。
将latent code转换得到w后,然后经过仿射变换生成A,分别送入Synthesis network的每一层网络,进行控制特征,因为Synthesis network的网络层有18层,所以我们才会说通过w生成得到了18个控制向量,用于控制不同的视觉特征。
如果仅通过z来控制视觉特征,那么其能力十分有限,因为它必须遵循训练数据的概率密度。比如数据集中长头发的人很常见,那么更多的输入值便会映射到该特征上,那么z中其他变量也会向着该值靠近、无法更好地映射其他特征。
计算过程
①首先每个特征图xi(feature map)独立进行归一化(和高斯分布里面的含义一样,分别代表均值(期望)和方差(标准差)那种 特征图的均值和方差中带有图像的风格信息。所以在这一层中,特征图减去自己的均值除以方差,去掉自己的风格。再乘上新风格的方差加上均值,以实现转换的目的。StyleGAN的风格不是由图像的得到的,而是w生成的。) 。特征图中的每个值减去该特征图的均值然后除以方差
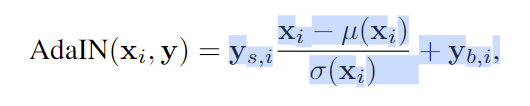
②一个可学习的仿射变换A(全连接层)将w转化为style中AdaIN的平移和缩放因子y =(ys,i,yb,i),
③然后对每个特征图分别使用style中学习到的的平移和缩放因子进行尺度和平移变换。
所以通过Mapping network,该模型可以生成一个不必遵循训练数据分布地向量w,减少了特征之间的相关性,完成解耦。
此处参考:原文链接
具体实现细节
初始化时,每个通道归一化成0-1标准高斯分布,零均值和1标准方差。每个style控制一个卷积,B是单通道噪声.
每个style在网络中是局部性的,例如修改某个style的子集,最终只会影响图像的特定某几个方面
用两个随机的latent code来生成图像而不是一个。在合成网络中随机选择点从一个code切换到另一个,叫做style mixing。例如让z1和z2生成图像,w1,w2控制style,那么让w1在交叉点之前应用,w2在之后应用,防止相邻的style发生关联。
由于只是了解该方法,并没有了解实验结果















 2481
2481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









