







论文介绍
生成对抗神经网络GAN开山之作论文。
论文作者为“生成对抗网络之父”Ian Goodfellow和图灵奖得主Youshua Bengio。
GAN近年来成为人工智能和深度学习的热门研究领域。GAN广泛应用于图像生成、风格迁移、AI艺术、黑白老照片上色修复。你可以使用GAN实现照片转成油画、野马转成斑马、黑夜转成白天,简笔画的猫转成真猫,模糊图像转成高清图像等酷炫好玩的应用。
题目:Generative Adversarial Nets
EID:arXiv:1406.2661
DOI:10.5555/2969033.2969125
时间:2014-06-10上传于arxiv
期刊:2014 27th International Conference on Neural Information Processing Systems(NIPS)
作者:Ian J. Goodfellow(加拿大-蒙特利尔大学)
论文链接:https://arxiv.org/abs/1406.2661
代码链接:http://www.github.com/goodfeli/adversarial
作者主页:https://www.iangoodfellow.com/GAN Lab网页:https://poloclub.github.io/ganlab/
OpenMMLab图像生成开源算法库MMGeneration:https://github.com/open-mmlab/mmgeneration
基本原理
生成器网络和判别器网络的彼此博弈。
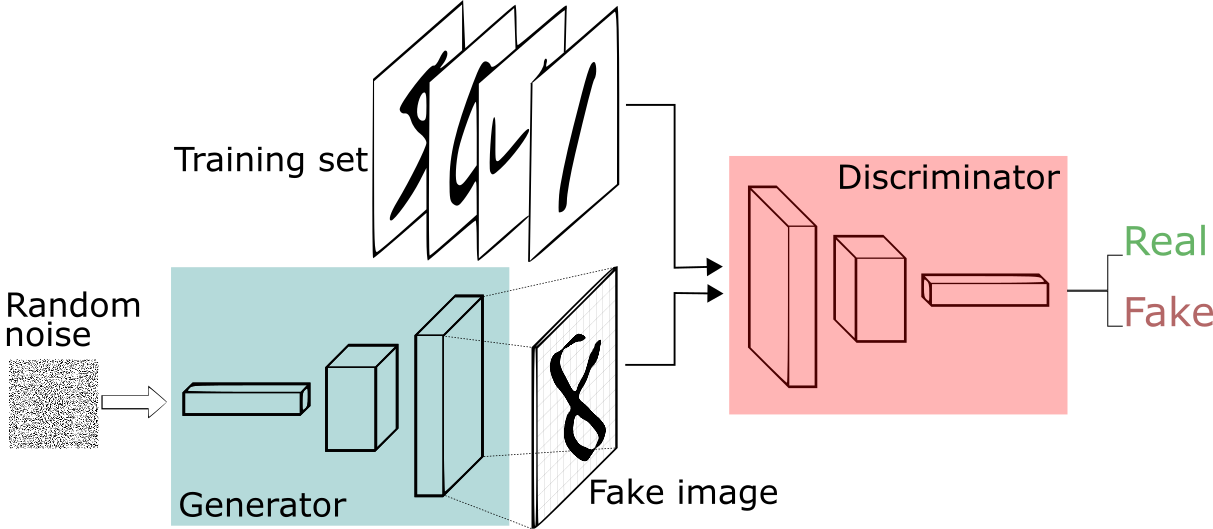
GAN 主要就是两个网络组成,生成器网络(Generator)和判别器网络(Discriminator),通过这两个网络的互相博弈,让生成器网络最终能够学习到输入数据的分布,这也就是 GAN 想达到的目的--学习输入数据的分布。
D 是判别器,负责对输入的真实数据和由 G 生成的假数据进行判断,其输出是 0 和 1,即它本质上是一个二值分类器,目标就是对输入为真实数据输出是 1,对假数据的输入,输出是 0;
G 是生成器,它接收的是一个随机噪声,并生成图像。
在训练的过程中,G 的目标是尽可能生成足够真实的数据去迷惑 D,而 D 就是要将 G 生成的图片都辨别出来,这样两者就是互相博弈,最终是要达到一个平衡,也就是纳什均衡。
GAN网络模型
生成对抗网络 (GAN)将训练过程视为两个独立网络之间的游戏:判别器试图将样本分类为来自真实分布的样本p(x)或模型分布P(x),每次判别器注意到两个分布之间的差异时,生成器都会稍微调整其参数以使其消失,直到最后(理论上)生成器准确地再现了真实的数据分布,使判别器无法找到一个区别。
对输入图像进行迭代的梯度下降修改,生成一些噪声加在原来图像,使神经网络的输出结果指鹿为马。
- GAN模型设计是一个可微分函数。
- 通过一个对抗过程来估计生成过程。
- 同时训练2个模型:一个生成模型G用于捕捉数据分布,一个判别模型D用于估计训练数据的概率。
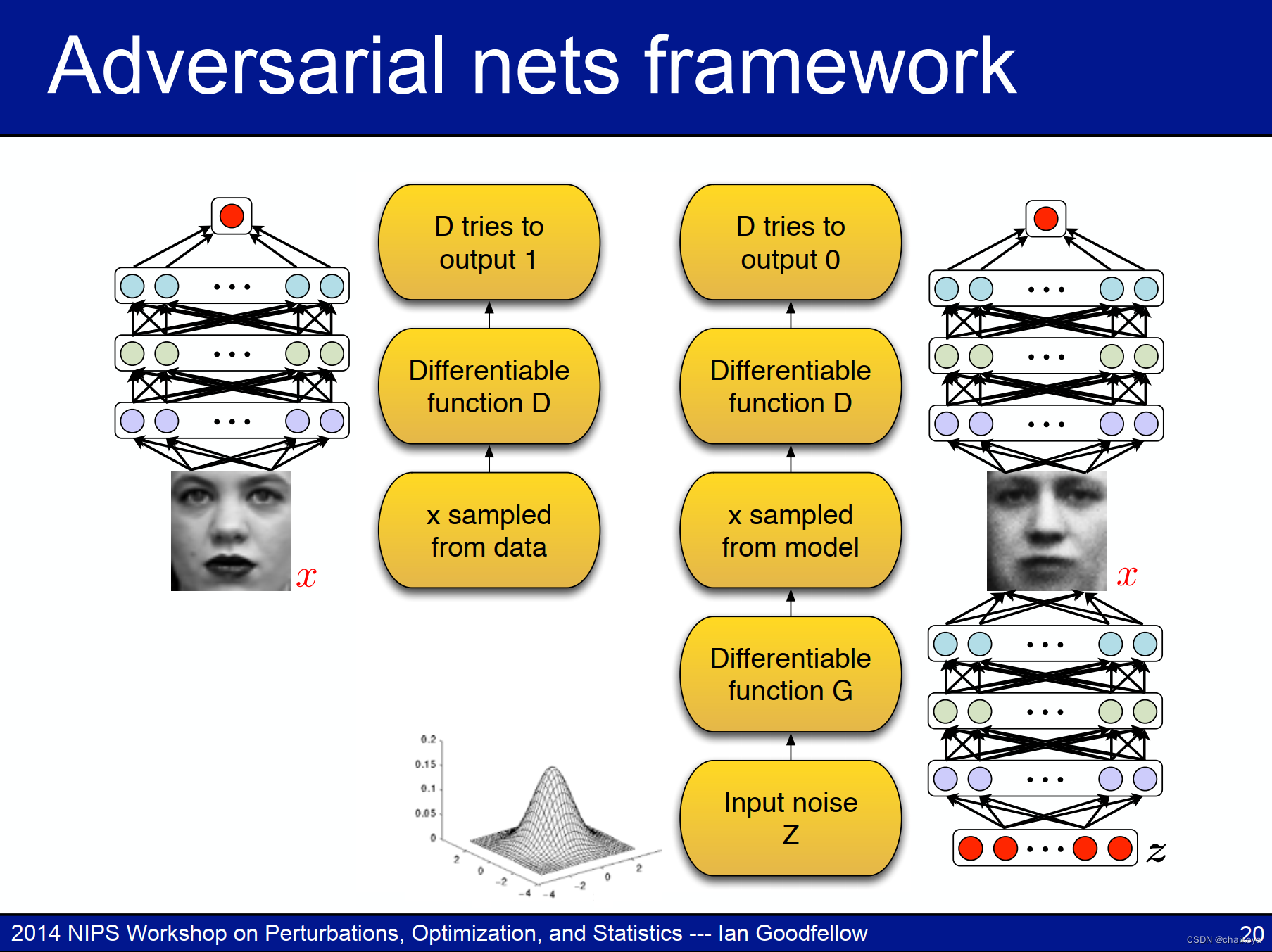
生成模型:


对抗网络框架:
G试图通过生成D难以与数据区分开来的样本来“欺骗”D。
- 训练K次判别器,训练一次生成器。
- 判别器引导生成器生成更逼真的图像。
- 生成器试图最大化使鉴别器将其输入误认为是真实的概率。
- 生成器不是直接用原始数据拟合,而是用判别器间接训练(避免过拟合)。
- 生成器和判别器一起训练,否则会出现“the Helvetica scenario”模式崩溃的现象(G尝到甜头,不再进化,生成的图像都一样)。
- 生成器不是要真的生成假数据而是要欺骗判别器D(举例:枯叶蝶)

最大最小函数:
通过生成过程反向传播导数,生成过程参考以下观测函数:
左边:maxD 给定G找到使V最大化的D,minG 给定D找到使V最小化的G;
前项:判别器输入真实数据时,输出越大越好;
后项:判别器输入假数据时,输出越小越好。

y=log(1-x)函数图像(默认底数为10)
在x[0,1]的范围内,x越接近1,y越小。
把x替换成D(G(x)),意味着,D(G(x))越接近1(生成器生成的假图被判别器误认为真图的概率越大),y越小(minG:给定D找到使V最小化的G)。
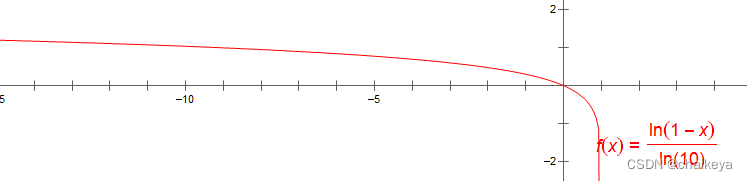
最优判别器:
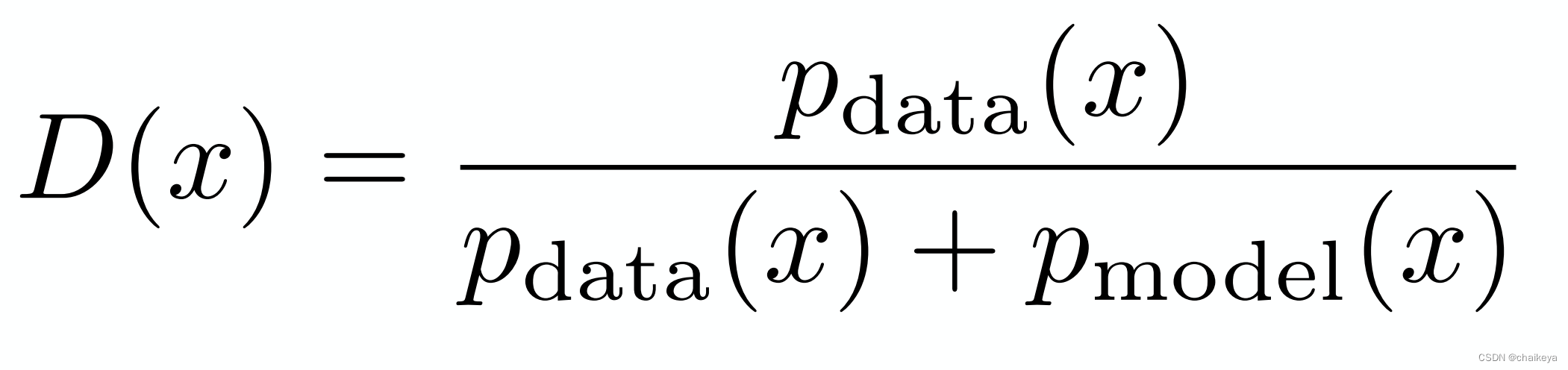
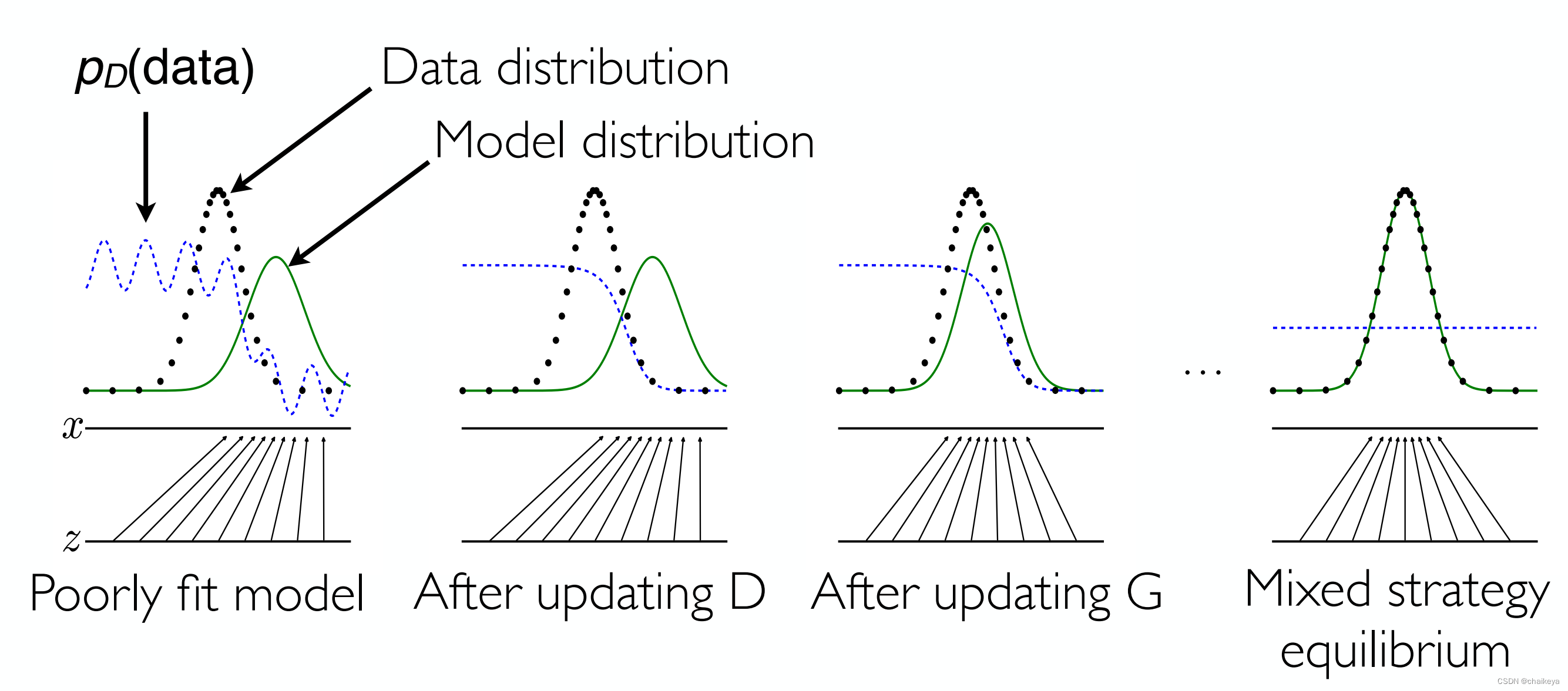
学习过程:
pD(data):判别器判别数据为真实数据的概率;
Data distribution:真实数据的分布;
Model distribution:生成器生成数据的分布;
- 噪声空间Z(均匀分布随机数)生成的假图像与真图像在判别器下的分布概率pD(data)。
- 在算法的内环中,D被用于训练区分样本和数据,趋同于最优判别器D(x)。
- 在对G进行更新后,D的梯度引导G(z)流向更有可能被分类为数据的区域。
- 经过几个步骤的训练后,如果G和D有足够的能力,此时他们将达到一个点,在该点处两者均不能提高,因为p g=p data。此时判别器不能够去区分这两个分布,因为D(x)=1/2。
实验结果
图2:模型样本的可视化。
第五列:GAN生成的数据(生成的数据是非常逼真的)
第六列:和GAN生成最接近的训练数据,以证明模型尚未记住训练集。

输入噪声渐变,生成图像也跟着渐变。
一维:图3-通过在完整模型的 z 空间中的坐标之间进行线性插值而获得的数字。

二维:Learned 2-D manifold of MNIST的可视化轨迹

Quantitative likelihood results:
在两个不同的数据集上生成数据的逼真程度(均值越大越好),均值+方差,本文Adversarial nets
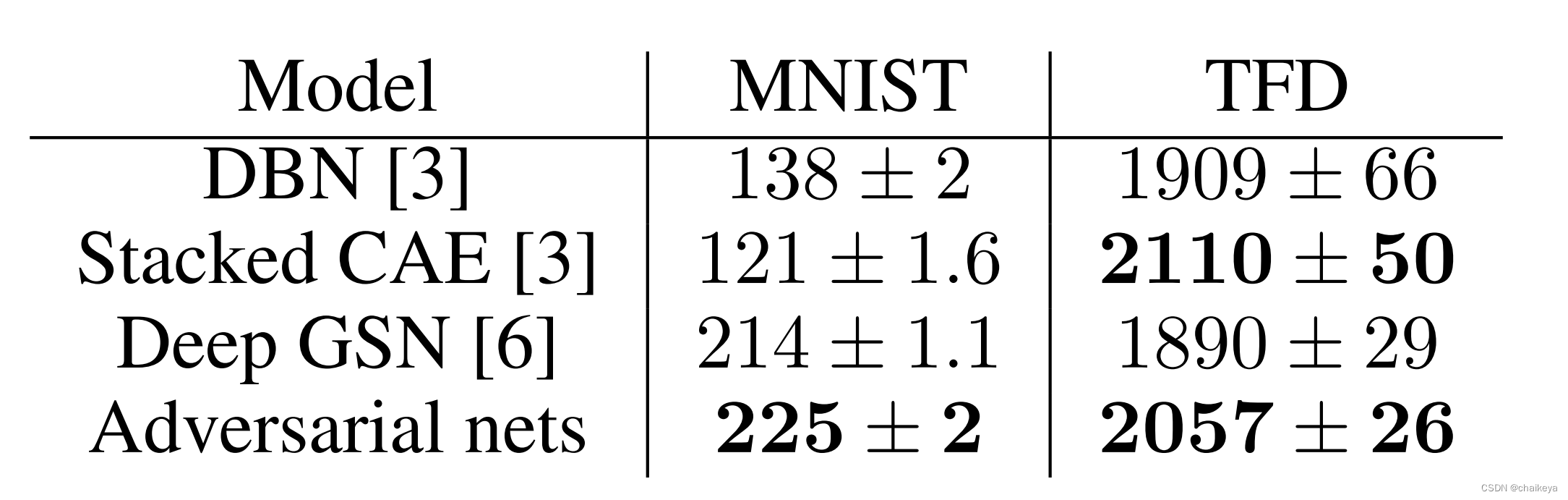
1、GAN和对抗样本的区别:
GAN:对输入图像进行迭代修改,误导分类神经网络“指鹿为马”;
对抗样本:只修改输入图像,不用于训练网络。
2、GAN和VAE(变分自动编码器)的区别:

GAN优势:
- 根据实际的结果,它们看上去可以比其它模型产生了更好的样本(图像更锐利、清晰)。
- GAN 模型只用到了反向传播,而不需要马尔科夫链反复采样,回避了近似计算棘手的概率的难题。
- 训练时不需要对隐变量做推断
- 理论上,只要是可微分函数都可以用于构建 D 和 G ,因为能够与深度神经网络结合做深度生成式模型
- G 的参数更新不是直接来自数据样本,而是使用来自 D 的反向传播
- 相比其他生成模型(VAE、玻尔兹曼机),可以生成更好的生成样本
- GAN 是一种半监督学习模型,对训练集不需要太多有标签的数据;
- 没有必要遵循任何种类的因子分解去设计模型,所有的生成器和鉴别器都可以正常工作
GAN存在问题:
- 解决不收敛(non-convergence)的问题
- 难以训练:崩溃问题(collapse problem):生成器开始退化
- 无需预先建模,模型过于自由不可控
参考资料:
反向传播:Neural networks and deep learning
生成模型:Generative Models
参考博客:A Short Introduction to Generative Adversarial Networks - Thalles' blog
作者演讲:https://www.iangoodfellow.com/slides/2015_icml_gans_wkshp_invited.pdf
参考博客:https://blog.csdn.net/solomon1558/article/details/52549409
论文精读:生成对抗网络GAN开山之作论文精读_哔哩哔哩_bilibili
知乎讲解:[GAN学习系列] 初识GAN - 知乎

















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









