







论文链接: https://arxiv.org/abs/1804.01622.
GitHub代码: https://github.com/google/sg2im.
对于文本生成图片(Text-to-Image)的任务,如果一开始将scene layout(场景布局)作为中间媒介,连接text domain 和 image domain,将会取得很好的结果。但是这个想法实现起来需要很多方面难题要解决,比如数据集、场景布局的处理、场景图(scene graph)的生成以及场景图的处理等等。
在这篇CVPR 2018的文章中,使用Visual Geome 和COCO-Stuff数据集,由Scene Graph生成与文本一致的图像。关于这两个数据集详细介绍就不说了,但是Visual Geome有现成的scene graph拿来使用,而COCO-Stuff数据集在论文中要对其处理后拿来使用。
创新点有:
- 提出graph convolution 模块处理输入的scene graph。
- 提出两个判别器网络Dimg和Dobj。
与以往方法的流程有所不同,主要与stackgan作的对比

整个网络结构:
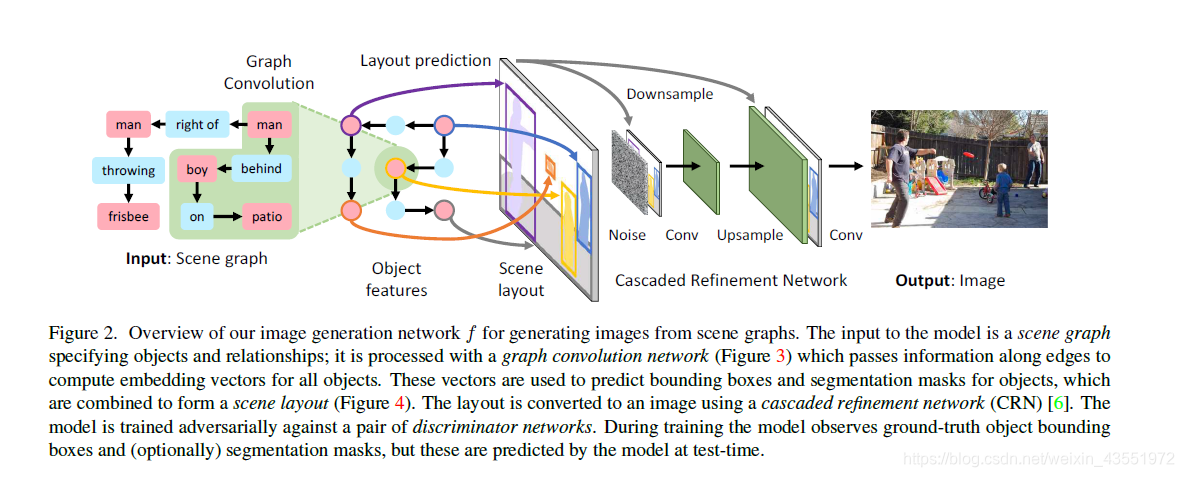
主要有三方面的挑战:
- 必须要有一个处理场景图的方法
- 确保生成的图像中个物体正确及位置关系的合理性
- 确保生成的图像质量好
输入scene graph G和噪音 z ,输出图片 I ^ \hat{I} I^
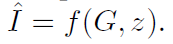
Scene Graphs
场景图的node(点)表示object(物体),edge(边)表示个点间的相互关系。用数学公式表达是:
C是物体集合,R是关系集合,一个场景图就是一个元组(O,E),O={o1,……,on},oi ∈ C,E ⊆ O x R x O是边(oi,ri,oj)的集合,r ∈ R。
Graph Convolution Network
为了以end-to-end的方式处理场景图,我们需要一个神经网络模型,就是graph convolution network,它是由多个single graph convolution layer(看下图)组成的。

vi</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









