







1.图像的语义信息、高层和底层特征
对图像中语义信息、高层和底层特征的理解_Brucechows的博客-CSDN博客_高层特征和底层特征
早在之前上NLP的课上,老师就多久强调文字的语义信息,之前一直是模糊的概念,而图像同样也具有这个信息内容,近期为了能想出一些比较好的点子,必须对一些细致的内容进行深刻的理解。
图像的语义分为视觉层、对象层和概念层:
图像底层特征指的是:轮廓、边缘、颜色、纹理和形状特征。
早期都是人为进行信息提取边缘和轮廓能反映图像内容;如果能对边缘和关键点进行可靠提取的话,很多视觉问题就基本上得到了解决。图像的低层的特征语义信息比较少,但是目标位置准确;
中间层包含:属性特征(就是某一对象在某一时刻的状态);
图像的高层语义特征值得是我们所能看的东西,比如对一张人脸提取低层特征我们可以提取到连的轮廓、鼻子、眼睛之类的,那么高层的特征就显示为一张人脸。高层的特征语义信息比较丰富,但是目标位置比较粗略。
愈深层特征包含的高层语义性愈强、分辨能力也愈强。我们把图像的视觉特征称为视觉空间。
2.在vscode上运行时总是会出现找不到包
一般情况下,如果模块都是在一个文件下,是不会有大问题的,但是如果在不同的文件下,也就是sys.path中是没有你想要导入的包的路径,这时候我们就需要进行添加!
import sys
sys.path.append("你想要导入的包的目录")即可实现!
3.LSTM
果然只有学习别人的代码,才能少走弯路!!!
nn.LSTM
该模块一次构造完若干层的LSTM。
Bi-LSTM 双向LSTM
class BidrectionalLSTM(nn.Module):#双向lstm
def __init__(self, size: int, layers: int):
"""Bidirectional LSTM used to generate fully conditional embeddings (FCE) of the support set as described
in the Matching Networks paper.
# Arguments
size: Size of input and hidden layers. These are constrained to be the same in order to implement the skip
connection described in Appendix A.2
layers: Number of LSTM layers
"""
super(BidrectionalLSTM, self).__init__()
self.num_layers = layers
self.batch_size = 1
# Force input size and hidden size to be the same in order to implement
# the skip connection as described in Appendix A.1 and A.2 of Matching Networks
self.lstm = nn.LSTM(input_size=size,
num_layers=layers,
hidden_size=size,
bidirectional=True)
def forward(self, inputs):
# Give None as initial state and Pytorch LSTM creates initial hidden states
output, (hn, cn) = self.lstm(inputs, None)
forward_output = output[:, :, :self.lstm.hidden_size]
backward_output = output[:, :, self.lstm.hidden_size:]
# g(x_i, S) = h_forward_i + h_backward_i + g'(x_i) as written in Appendix A.2
# AKA A skip connection between inputs and outputs is used
output = forward_output + backward_output + inputs
return output, hn, cnnn.LSTMCell
该模块构建LSTM中的一个Cell,同一层会共享这一个Cell,但要手动处理每个时刻的迭代计算过程。如果要建立多层的LSTM,就要建立多个nn.LSTMCell。
class AttentionLSTM(nn.Module):
def __init__(self, size: int, unrolling_steps: int):
"""Attentional LSTM used to generate fully conditional embeddings (FCE) of the query set as described
in the Matching Networks paper.
# Arguments
size: Size of input and hidden layers. These are constrained to be the same in order to implement the skip
connection described in Appendix A.2
unrolling_steps: Number of steps of attention over the support set to compute. Analogous to number of
layers in a regular LSTM
"""
super(AttentionLSTM, self).__init__()
self.unrolling_steps = unrolling_steps
self.lstm_cell = nn.LSTMCell(input_size=size,
hidden_size=size)
def forward(self, support, queries):
# Get embedding dimension, d
if support.shape[-1] != queries.shape[-1]:
raise(ValueError("Support and query set have different embedding dimension!"))
batch_size = queries.shape[0]
embedding_dim = queries.shape[1]
h_hat = torch.zeros_like(queries).cuda().double()
c = torch.zeros(batch_size, embedding_dim).cuda().double()
for k in range(self.unrolling_steps):
# Calculate hidden state cf. equation (4) of appendix A.2
h = h_hat + queries
# Calculate softmax attentions between hidden states and support set embeddings
# cf. equation (6) of appendix A.2
attentions = torch.mm(h, support.t())
attentions = attentions.softmax(dim=1)
# Calculate readouts from support set embeddings cf. equation (5)
readout = torch.mm(attentions, support)
# Run LSTM cell cf. equation (3)
# h_hat, c = self.lstm_cell(queries, (torch.cat([h, readout], dim=1), c))
h_hat, c = self.lstm_cell(queries, (h + readout, c))
h = h_hat + queries
return h4.loss()
nn.NLLLoss的结果就是把输出与Label对应的那个值拿出来,再去掉负号,再求均值。
softmax(x)+log(x)+nn.NLLLoss====>nn.CrossEntropyLoss
5.model.train() model.eval()

目前只有 Dropout 和 BatchNorm 关心 self.training 标志。
要注意其在训练和测试的时候,作用是不同的!
6.运行知识蒸馏代码的时候,发现出现run python test in 的问题
解决方案:
File--->Settings--->python integrated Tools
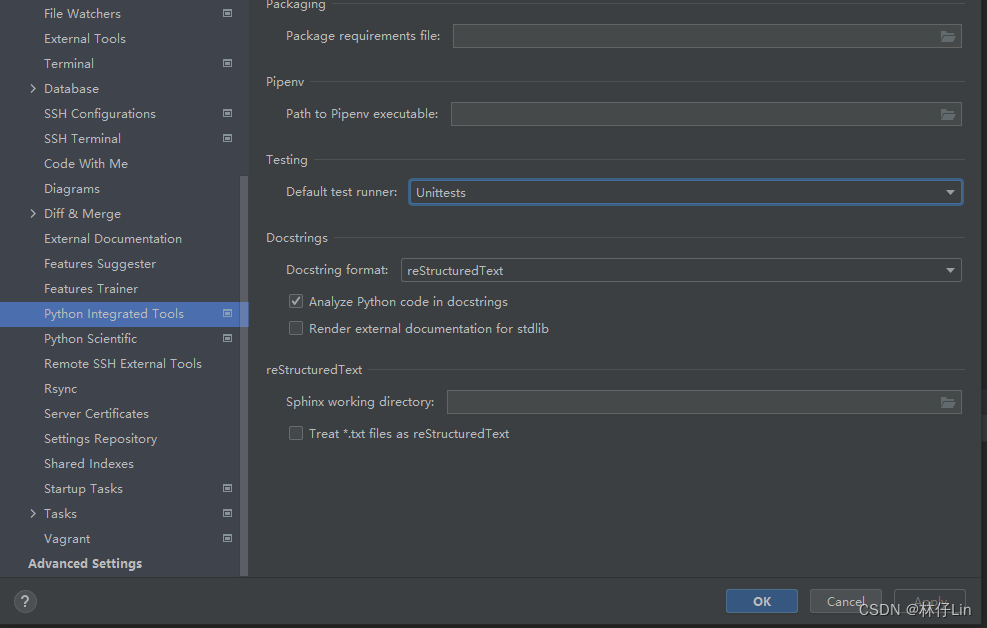 Testing那一栏修改成Unittests即可
Testing那一栏修改成Unittests即可
7.Pytorch to(device)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)用于将数据放在GPU中计算















 2897
2897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









