







文章目录
Motivation
但从题目就知道:类别很重要,细粒度的对抗预适应分割方法。还是讲一个问题,大部分对抗方法是从整体去对齐,并没有考虑class-level的特征对齐,对于语义分割来说,class-level的结构很重要。第二,传统的对抗性方法只追求最大化边缘分布对齐,而忽略了域间语义结构的不一致性(并没有去关注类与类之间结构究竟怎么样,讲白了,就是说每个类别的条件分布也应该对齐)。出发点自然是怎样才能达到更好的class-level alignment 。

上图就表达了一个意思:(a)是对抗方法做的事情,它的判别器输出0/1,最终能够实现Global feature的aligment,讲白了,它只能做到让两个分布一股脑的对齐,没法增强target域特征判别性,所以在分类器边界出,容易对target域的样本错误判别。(b)是更加细粒度的对抗对齐,它的判别器输出包含各个类别概率,最终能够保证两个域全局和具体类别的对齐,效果更好。
思路
把类别信息融入到判别器中,保证更加细粒度的特征对齐,即在特征对齐时,是针对具体类别来做。有几个方面需要考虑:类与类之间的关系,如何把类别信息融入到判别器中。

总结下作者的做法,
分割loss还是一样,标准的交叉熵;原来的对抗方法中,判别器做二分类,源域是0,目标域是1;作者把类别信息加入到判别器中。看label就可以知道它们区别,原来源域label是[1, 0], 目标域是[0,1];修改后,源域label是**[a; 0], 目标域是[0; a],总共2K维度。具体来说:原来Domain Discriminator是做binary classifier,现在把它的每个输出改为K通道,总共2K个通道,这样类与类之间的结构关系也就知道了,保证了class-level alignment 。关键这里a是什么,论文称为类别知识(class knowledge )**。
传统判别器 :
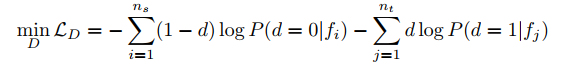
判别器融入类别信息 :
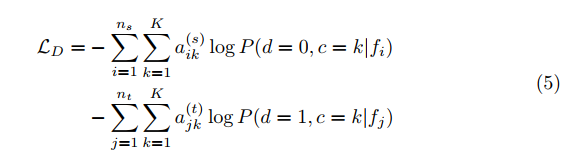
















 2776
2776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









