








目录
4、将Masked patches输入到transformer
文献地址:MultiMAE: Multi-modal Multi-task Masked Autoencoders
代码地址:https://github.com/EPFL-VILAB/MultiMAE
1、摘要
这篇MultiMAE是在MAE的基础上提出的改进方法,主要区别在于:
(1)在输入RGB图像,同时增加了附加信息(semantic和depth);
(2)训练目标除了预测 RGB 图像之外,还包括semantic和depth的多个输出(“多任务”);
这个方法适用于:图像分类、语义分割、深度估计
上图的Depth图像的获取途径:通过传感(深度传感器)或伪标记(预训练的深度估计网络)。

2、MultiMAE的总流程
MultiMAE是一种简单有效的掩码自动编码方法,包括多种模式和任务(上图2)。 通过添加密集场景深度以捕获几何信息(Depth),以及添加分割图以包含有关场景语义内容的信息(Semantic)。 然后在 ImageNet-1K 上对这些任务进行伪标记来创建多任务数据集。 这样的好处是,为了训练 MultiMAE,只需要一个没有注释的大型非结构化 RGB 数据集,并且只需要现成的神经网络来执行伪标记。
伪标签法的构建过程:
step 1:通过稀少而昂贵的ground turth,训练模型Ti。
step 2:应用模型Ti,标注一些未标记样本成为伪样本。
step 3:混合伪样本和ground turth,基于Ti增量训练模型Ti+1。
重复2、3步置验证集收敛。
最好的情况下,由易到难地喂合适的数据,使得每个阶段模型都能正确标记样本。
那么最终模型的效果等同于curriculum learning模式下大量样本的训练。
这也可以看作对抗学习的一个变体,或者对抗学习是该trick的一个变体。
----------------------------------------------------------------------------------------------------------------------
作者:aluea
链接:https://zhuanlan.zhihu.com/p/415280783
来源:知乎
3、从原始图像获得Masked image patches
对三种模式的图像:RGB、Depth和Semantic,从中随机选择所有 16×16 图像块中的 1/6,并在此基础上学习并重建剩余的 5/6 掩码块。

4、将Masked patches输入到transformer
将Masked image patches经过linear projection到指定的维度,然后将不同模式图像的线性映射拼接输入到Transformer Encoder中:

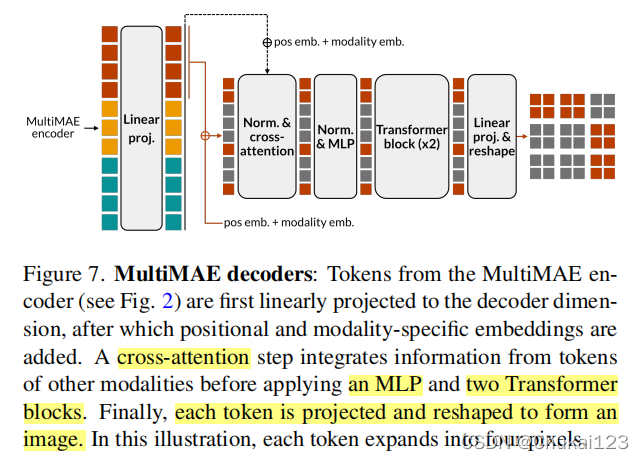
5、Decoder部分
解码器通过首先执行从查询到编码标记的交叉注意力,然后采用浅层 Transformer 来重建Masked Image patches得到Masked targets。
decoder组成:单个交叉注意力层和 MLP,然后是两个Transformer模块

注:具体细节请看原文!















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











