







引言
在数字化时代,文档处理和理解是企业、科研机构以及个人工作流程中的重要环节。然而,传统的光学字符识别(OCR)技术往往难以应对复杂文档中的多语言、多模态内容。近日,法国 AI 明星创企 Mistral AI 推出了一款名为 Mistral OCR 的光学字符识别 API,以其卓越的性能和广泛的应用场景,被誉为“世界最强 OCR 模型”。
一、Mistral OCR 的核心优势
1. 高精度文档解析
Mistral OCR 能够精准提取文本、图片、表格、数学公式等复杂元素,特别适用于科学论文、技术手册等高密度信息文档。它不仅支持多种语言,还能识别手写体和不同字体,满足全球用户的需求。
2. 多语言支持
在多语言基准测试中,Mistral OCR 的表现超越了 Google Document AI 和 Azure OCR,识别率接近 99%。这一特性使其在国际化的文档处理场景中具有显著优势。
3. 极高处理速度
Mistral OCR 是同类中最快的 OCR 模型,每分钟可处理高达 2000 页文档,远超同类解决方案。这种超高效能使其适用于需要快速处理大量文档的场景,如科研机构和企业档案管理。
4. 结构化输出
Mistral OCR 支持结构化输出(如 JSON),能够将复杂文档转换为易于集成的格式,方便下游应用的开发和使用。
5. 数据安全与隐私
Mistral OCR 支持在企业私有服务器上运行,满足严格的数据安全和隐私合规要求。这对于需要处理敏感信息的机构尤为重要。
二、应用场景
1. 科研助力
Mistral OCR 能将科学论文和期刊转化为 AI 能处理的格式,加快科研工作流程,促进团队协作。
2. 文物保护
通过数字化历史文献和文物,Mistral OCR 既保证了珍贵资料的保存,又让更多人能够接触和研究。
3. 客服提效
Mistral OCR 可将手册和文档转化为可搜索的知识库,缩短响应时间,提升客户满意度。
4. 文献索引升级
Mistral OCR 能将技术文档、工程图纸等多种资料转化为可索引、查询的格式,显著提高工作效率。
三、用户反馈与市场表现
Mistral OCR 的发布引发了广泛的关注和积极的用户反馈。用户 @alwriterla 称其为“革命性的光学字符识别 API”,并指出其在科学文献、历史档案和客户服务等场景中的广泛适用性。此外,Mistral OCR 的定价策略(1000 页/美元)也使其在市场中具有极高的性价比。
四、未来展望
Mistral OCR 的推出不仅重新定义了文档理解的技术标准,还为企业和研究机构提供了强大的工具支持。随着 AI 技术的不断发展,Mistral OCR 有望在更多领域发挥其潜力,推动文档处理和理解的全面升级。
如果你对 Mistral OCR 感兴趣,可以访问其官方网站或开发者平台了解更多,并开启你的使用之旅。
五、如何使用
1、通过网页端
官方地址:Mistral AI
使用方法很简单,通过邮箱注册登陆即可
2、api调用
参考api文档

官方提供了不同语言调用脚本
OCR and Document Understanding
参考当前网页的调用脚本,但是当前需要先创建自己的api_key
(1)先登陆La Plateforme,然后点击API keys
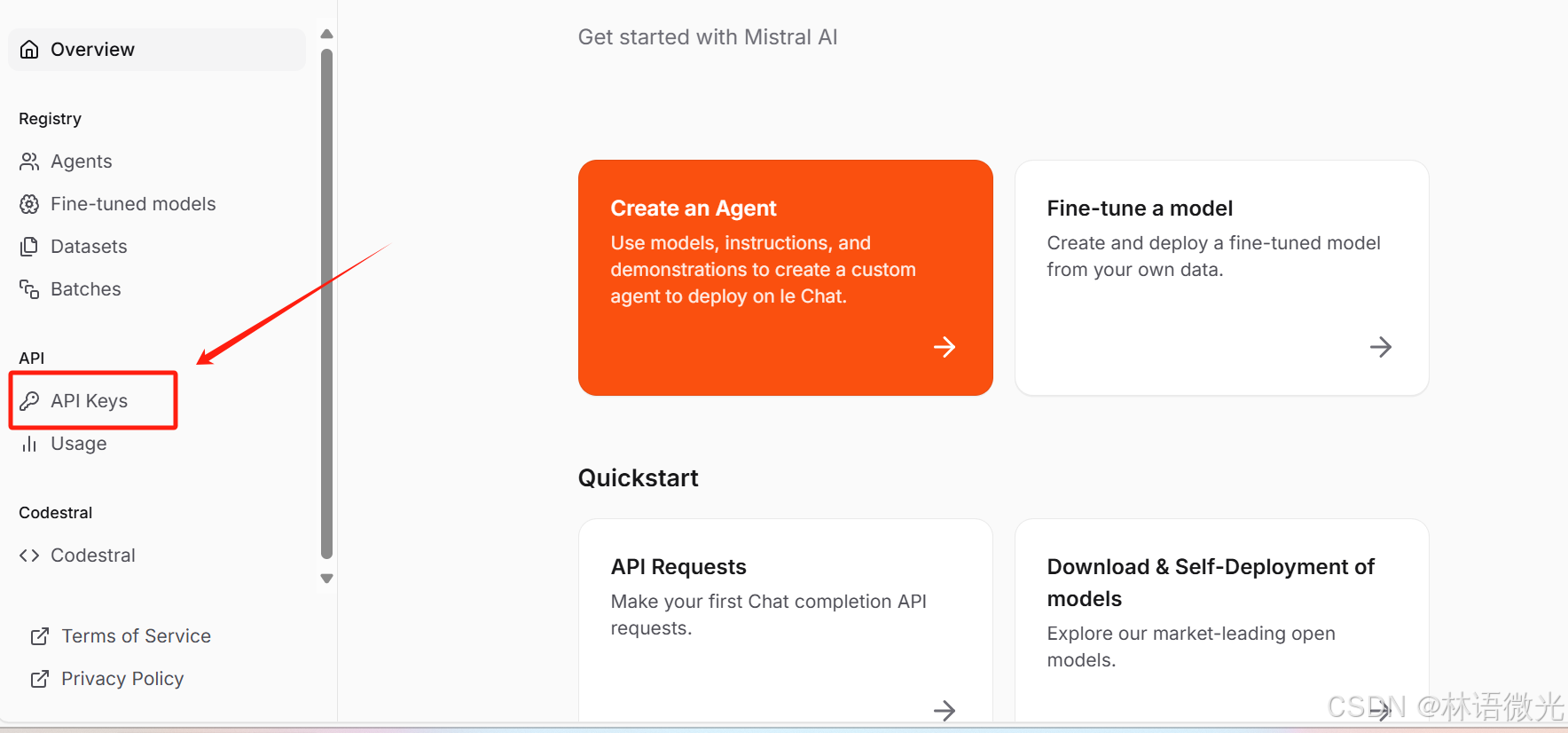
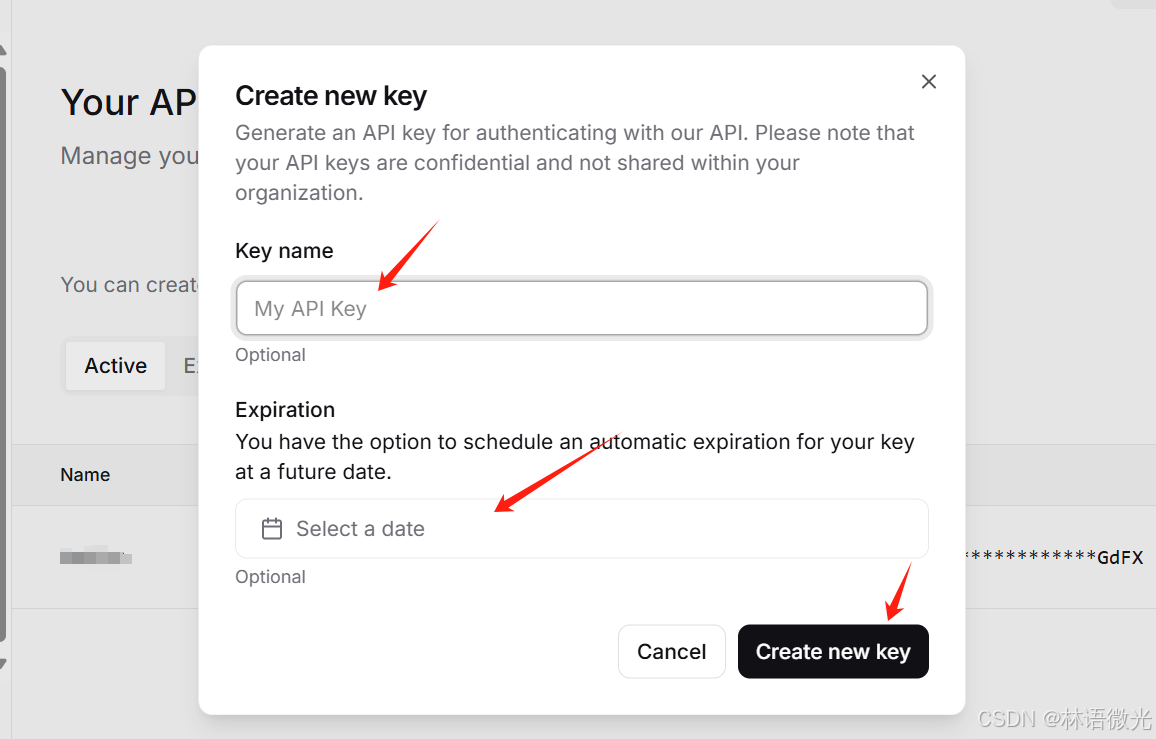
(2)创建api_key,记得保存
采用官方提供的api调用工具,当前以python为例(以图片测试为例,pdf也支持)
import base64
import requests
import os
from mistralai import Mistral
def encode_image(image_path):
"""Encode the image to base64."""
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except FileNotFoundError:
print(f"Error: The file {
image_path} was not found.")
return None
except Exception as e: # Added general exception handling
print(f"Error: {
e}")
return None
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{
base64_image}"
}
)
按照官方提供的代码,总是报错,于是参考提供的ocr_api:ocr_v1_ocr_post
接口调用说明修改后的完整代码如下所示:
import requests
import base64
import os
import json
def encode_image(image_path):
"""Encode the image to base64."""
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except FileNotFoundError:
print(f"Error: The file {
image_path} was not found.")
return None
except Exception as e: # Added general exception handling
print(f"Error: {
e}")
return None
def call_mistral_api(api_key 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











