







 本文详细解析YOLOv5模型的yaml配置文件,包括参数部分、主干部分和头部部分,讲解如何根据yaml文件构建模型结构,添加检测头和减少检测头,以及如何修改yaml文件以适应不同改进。通过本文,读者将掌握yaml文件的读取机制,学会根据模型结构图写配置文件,并了解如何使用更深的网络。
本文详细解析YOLOv5模型的yaml配置文件,包括参数部分、主干部分和头部部分,讲解如何根据yaml文件构建模型结构,添加检测头和减少检测头,以及如何修改yaml文件以适应不同改进。通过本文,读者将掌握yaml文件的读取机制,学会根据模型结构图写配置文件,并了解如何使用更深的网络。


看完这篇你能学会什么?
- 掌握根据
yaml文件画出模型结构图的能力 - 掌握根据模型结构图写
yaml文件的能力 - 掌握添加模块后写配置文件
args参数的能力 - 掌握修改模型配置文件的能力
1. YOLOv5 模型yaml文件解析
| 模型 | 尺寸 (像素) | mAPval 50-95 | mAPval 50 | 推理速度 CPU b1 (ms) | 推理速度 V100 b1 (ms) | 速度 V100 b32 (ms) | 参数量 (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
YOLOv5提供了多个版本的网络模型,其中n, s, m, l, x模型是在输入尺寸为640x640的图像上训练得到的,最终会对输入图像进行32倍下采样,并输出3个预测特征层。
n6, s6, m6, l6, x6是在输入尺寸为1280x1280的图像上训练得到的,最终会对输入图像进行64倍下采样,并且会输出4个预测特征层。
除此之外,这些模型的结构是完全相同的,区别只在于网络的深度和宽度,网络的深度指的就是C3模块中Bottelneck的数量,网络的宽度指的就是网络每层的通道数。
不管是YOLOv5还是v7 v8,都是使用yaml文件来定义网络结构的,YOLOv5的yaml文件是下面这个样子的,我这里以最常用的yolov5s.yaml为例子说明,我们可以将这个配置文件划分成三个部分:

1.1 参数部分

首先我们来看参数部分,这里有nc,depth_multiple,width_multiple和anchors四个参数:
-
nc: 80指的就是你数据集中的类别数量。YOLOv5是在COCO数据集上训练的,COCO数据集正好80类,在我们训练自己的数据集时要将这个参数改为自己数据集的类别数。(但其实这里不改也不报错的,因为我们在数据集的yaml文件中已经写好了nc的数量) -
depth_multiple: 0.33指的是该网络模型的深度因子。这个是用来调整C3模块中的子模块Bottelneck重复次数的,在实际使用时,我们要用这个深度因子乘上主干部分C3模块的number系数的,比如主干中第一个C3模块的number系数是3,我们使用0.33x3并且向上取整就等于1了,这就代表第一个C3模块中Bottelneck只重复一次;第二个C3模块的number系数是6,我们使用0.33x6并且向上取整就等于2了,这就代表第二个C3模块中Bottelneck重复二次;第三个C3模块的number系数是9,我们使用0.33x9并且向上取整就等于3了,这就代表第三个C3模块中Bottelneck重复三次;n, s, m, l, x这些模型的深度因子都是不同的,但计算方式相同。 -
width_multiple: 0.50指的是该网络模型的宽度因子。这个是用来调整每层模块的通道数量的,比如yolov5s.yaml文件上第一个Conv模块的输出通道数写的是64,但是实际上这个通道数并不是64,而是使用宽度因子0.50x64得到的最终结果32;同理,C3模块的输出通道虽然在yolov5s.yaml文件上写的是128,但是在实际使用时依然要乘上宽度因子0.50,那么第一个C3模块最终的到实际通道数就是0.50x128 = 64。 -
anchors:指的是作用在每层特征图上的Anchor的尺寸。yolov5s.yaml最终会输出3个预测特征层,每个预测特征层上都会使用三个Anchor, 其中P3/8的意思是该层特征图缩放为输入图像尺寸的1/8,是第3特征层;P4/16的意思是该层特征图缩放为输入图像尺寸的1/16,是第4特征层;P5/32的意思是该层特征图缩放为输入图像尺寸的1/32,是第5特征层;[10,13, 16,30, 33,23]的含义就是三个Anchor的尺寸分别是10x13的,16x30的,33x23的;也就是说,3个预测特征层中,最大的预测特征层用到的Anchor的尺寸为10x13的,16x30的,33x23的;3个预测特征层中,中等大小的预测特征层用到的Anchor的尺寸为30x61的,62x45的,59x119的;3个预测特征层中,最小的预测特征层用到的Anchor的尺寸为116x90的,156x198的,373x326的。总的来说就是,大的特征图是用来检测小目标的,所以Anchor尺寸最小;小的特征图是用来检测大目标的,所以Anchor尺寸最大;


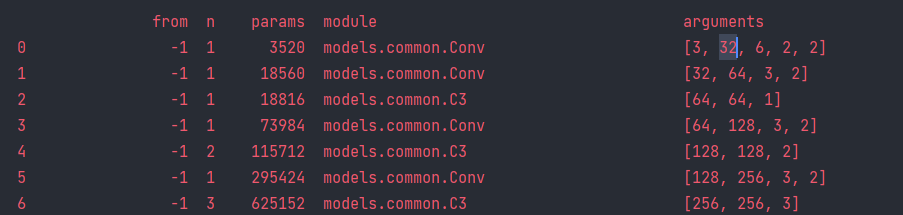
1.2 主干部分

主干部分有四个重要的参数,[from, number, module, args] ,我下面一一解释:
from,这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,第一层上一层 没有输入,后面我带大家精读代码后大家就理解了,我们就保持第一层的from是-1就好了。number,这个参数表示模块重复的次数,如果为3则表示该模块重复3次,这个有时候也并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数,具体看你代码怎么写的。对于C3模块来说,这个number就代表C3中Bottelneck模块重复的次数。module,这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第二层使用了C3模块,所有的模块都在common.py中可以看到。args,这个参数可以说是整个配置文件中最重要也是最难确定的参数了,这个参数的写法真的是难到了无数英雄豪杰,但是今天我就要把这个最难讲解的参数给大家彻底讲明白,如果你听明白了,记得一定要评论区给我评论一下🙏。我这里多给大家举几个例子,希望大家融会贯通自己思考一下,因为真的一个模块一个写法(其实大体上也就几种情况而已):这部分我拿出来放到第二章节单独讲解,我们先把头部的yaml文件讲解完成。
1.3 头部部分

头部部分参数依然是,[from, number, module, args] ,我只想在这部分说一下Concat和Detect,这是大家经常有问题的俩个地方,首先是Concat,-1代表上一层,6代表第六层(从第0层开始数),Concat要求的是拼接的两个特征图的尺寸是一样的,通道可以不一样!!Add操作是要求模型的通道和尺寸都相同!Add操作其实就是将两个特征图的相应像素相加,得到一个新的特征图。Concat操作则是将两个特征图在通道维度上连接起来,得到一个新的特征图。
Detect的from有三个数,17,20,23,这三个就是最终网络的输出特征图,分别对应P3,P4,P5。
2. yaml文件数据读取机制解析
2.1 parse_model 函数代码详解
讲到yaml文件数据读取机制就不得不讲解一下yolo.py文件了,这个文件主要包含三大部分: Detect类, Model类,和 parse_model 函数。我们着重讲解parse_model(d, ch)这个函数:
这个类的完整代码如下,我会把这个代码拆解开,手把手一个单词一个单词给你解释,新手不会Python也不用担心,记得点点赞👍
def parse_model(d, ch): # model_dict, input_channels(3)
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CARAFE, RepVGGBlock, nn.ConvTranspose2d]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C2f]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.ConvTranspose2d:
if len(args) >= 7:
args[6] = make_divisible(args[6] * gw, 8)
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
这段代码的作用就是解析模型的结构并构建模型。函数的输入参数是字典d和整数ch。该字典包含了模型的相关信息,如锚点、类别数、深度因子、宽度因子等。整数ch表示输入通道数,默认为3。
该函数的主要操作是对d中的每一个模块进行处理。对于每一个模块,首先通过eval函数将字符串形式的模块名转化为对应的类,然后对模块进行初始化,生成相应的层。同时,该函数会记录每个层的输出通道数,并将其存储在ch列表中,作为下一个模块的输入通道数。最终,该函数将所有层组合成一个Sequential模型,并返回该模型及需要进行保存的层的索引。在处理模块时,该函数也会输出相关信息,如模块的类型、参数数量等。
首先来看这段代码:
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
这几行代码提取出模型字典中的锚点信息anchors、类别数nc、深度因子gd和宽度因子gw,并计算出每个输出的通道数no。其中,anchors可以是一个列表或一个整数,na表示锚点的数量,no表示输出通道数。
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
这一行代码初始化三个变量layers、save和c2,分别表示模型的层列表、保存的列表和最后一层的通道数。
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
这一行代码遍历模型字典中的backbone和head部分,其中backbone是模型的主干部分,head是模型的头部分。
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
这几行代码将字符串类型的m和args转换为可执行代码,以便后面可以调用这些代码。如果转换失败则忽略该错误。
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
这一行代码根据深度因子gd调整每个模块的深度,如果深度小于等于1,则不做调整。
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, VoVGSCSP, C2f]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.ConvTranspose2d:
if len(args) >= 7:
args[6] = make_divisible(args[6] * gw, 8)
这段代码主要是根据不同的模块类型来确定该模块的输入和输出通道数,并进行相应的处理。
其中,模块类型包括Conv、GhostConv、Bottleneck等等,这些都是在模型构建中使用的不同类型的卷积模块。
c1和c2分别代表该模块的输入和输出通道数。如果该模块的输出通道数不等于no,即该模块不是输出层,那么会将该模块的输出通道数乘以gw(宽度因子),并将结果向下取整到最近的8的倍数。这是因为在构建模型时,宽度因子用于控制网络的宽度,以便在不影响精度的情况下减少模型大小和计算量。
args是该模块的其他参数,例如卷积核大小、步长、填充等。在这段代码中,会将c1、c2和args组合起来作为该模块的输入参数。如果该模块是BottleneckCSP、C3、C3TR、C3SPP或C3Ghost,则会将n插入到args列表的第三个位置,以表示该模块中的重复次数。如果该模块是nn.ConvTranspose2d,则会将其第7个参数乘以gw并向下取整到最近的8的倍数。
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
最后,该模块被添加到layers列表中,并且如果该模块的下标为0,则会清空ch列表。最后,该函数返回一个包含所有模块的nn.Sequential对象,以及一个已排序的保存列表save。到此位置,YOLOv5/v7/v8最核心,也是最有特点的通过yaml文件读取模型结构的原理就说完了。但是在实际使用中,我们要自己添加一些模块,那么当我们自己添加模块后,elif语句下面的c1,c2到底该怎么写呢?下面我演示一下不同种模块的添加方式!这里的不同指的是形参的不同,有的模块甚至不需要输入通道数的,也有的没有输出通道数的,这就要求我们通过下面的语句来控制。
-

首先我们来看这个
Conv模块,他有7个形参,其中后5个形参已经有了默认值,以yolov5s.yaml文件中第一个Conv模块为例子,他的args是[64, 6, 2, 2],这个64就代表的c2,6代表的就是k,2代表的就是s,最后一个2代表的就是p;不知道大家发现没有,args的赋值是按顺序的!我们再将
Conv这个模块的部分拆解出来,看一下到底是怎么计算的:if m in [Conv, C3]: c1, c2 = ch[f], args[0] if c2 != no: # if not output c2 = make_divisible(c2 * gw, 8) args = [c1, c2, *args[1:]] if m in [BottleneckCSP, C3, C3TR]: args.insert(2, n) # number of repeats n = 1这里我再讲一遍加深大家印象,这部分真的很重要!这段代码的目的是根据不同的模块类型对输入特征图的
channel数进行调整。首先,
c1和c2分别表示当前模块输入的特征图和输出的特征图的通道数。如果当前模块输出的不是最终输出,则通过make_divisible函数将c2乘上一个宽度倍数gw,然后将其向下取整为8的倍数。这个宽度倍数是在模型初始化的时候设定的那个。
接下来,将
c1和c2以及其他参数按顺序组成一个新的参数列表args。如果当前模块是BottleneckCSP、C3或者C3TR中的一种,则将重复次数n插入到参数列表的第三个位置,并将n设为1。这个重复次数也是在模型初始化的时候设定的那个。
最后,将更新后的参数列表
args传入当前模块,生成一个新的神经网络层,然后将其保存到一个层列表中。 -

接下来我们在看一下C3模块,当我们看完C3模块的形参后就可以判断,C3模块的额elif语句的书写方式是和Conv相同!
我下面介绍一些特殊模块的写法!!
2.2 自己添加模块后args到底怎么写?
ECA模块

elif m in [ECA]:
args = [*args[:]]
如果模块m在[ECA]中,则直接将args中的所有元素复制一遍。
CA模块

elif m in [CoordAtt]:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
如果模块m在[CoordAtt]中,则将模块对应的输入通道数和输出通道数分别赋值给c1和c2,然后对c2进行与之前相同的处理,接下来,将c1、c2以及args[1:]作为元素,组成新的列表,作为更新后的args。
SE模块

elif m in [SE]: # channels args
c1 = ch[f]
args = [c1, *args[0:]]
如果模块m在[SE]中,则将模块对应的输入通道数赋值给c1,将c1以及args[0:]作为元素,组成新的列表,作为更新后的args。
S2模块

elif m in [S2Attention]: # channels
c1 = ch[f]
args = [c1]
如果模块m在[S2Attention]中,则将模块对应的输入通道数赋值给c1,将c1作为唯一的元素,组成新的列表,作为更新后的args。这样,根据不同的模块类型,将参数组合成适当的列表,以便构建模型。
98%的模块都跑不出上面的几种情况,大家融会贯通一下,这是我个根据个人经验总结的几种情况,可能有奇葩模块我没见过吧。
3.如何通过yaml文件看模型结构?
这里我直接将原本的yaml文件和我画的结构图摆出来,大家对比一下很容易就找到了对应的关系,结合我上面讲的代码,可以很容易的将yaml文件还原成图像,也可以从图像还原成yam文件。

| 层数 | form | module | args | input | output |
|---|---|---|---|---|---|
| 0 | -1 | Conv | [3, 32, 6, 2, 2] | [3, 640, 640] | [32, 320, 320] |
| 1 | -1 | Conv | [32, 64, 3, 2] | [32, 320, 320] | [64, 160, 160] |
| 2 | -1 | C3 | [64, 64, 1] | [64, 160, 160] | [64, 160, 160] |
| 3 | -1 | Conv | [64, 128, 3, 2] | [64, 160, 160] | [128, 80, 80] |
| 4 | -1 | C3 | [128, 128, 2] | [128, 80, 80] | [128, 80, 80] |
| 5 | -1 | Conv | [128, 256, 3, 2] | [128, 80, 80] | [256, 40, 40] |
| 6 | -1 | C3 | [256, 256, 3] | [256, 40, 40] | [256, 40, 40] |
| 7 | -1 | Conv | [256, 512, 3, 2] | [256, 40, 40] | [512, 20, 20] |
| 8 | -1 | C3 | [512, 512, 1] | [512, 20, 20] | [512, 20, 20] |
| 9 | -1 | SPPF | [512, 512, 5] | [512, 20, 20] | [512, 20, 20] |
| 10 | -1 | Conv | [512, 256, 1, 1] | [512, 20, 20] | [256, 20, 20] |
| 11 | -1 | Upsample | [None, 2, ‘nearest’] | [256, 20, 20] | [256, 40, 40] |
| 12 | [-1, 6] | Concat | [1] | [1, 256, 40, 40],[1, 256, 40, 40] | [512, 40, 40] |
| 13 | -1 | C3 | [512, 256, 1, False] | [512, 40, 40] | [256, 40, 40] |
| 14 | -1 | Conv | [256, 128, 1, 1] | [256, 40, 40] | [128, 40, 40] |
| 15 | -1 | Upsample | [None, 2, ‘nearest’] | [128, 40, 40] | [128, 80, 80] |
| 16 | [-1, 4] | Concat | [1] | [1, 128, 80, 80],[1, 128, 80, 80] | [256, 80, 80] |
| 17 | -1 | C3 | [256, 128, 1, False] | [256, 80, 80] | [128, 80, 80] |
| 18 | -1 | Conv | [128, 128, 3, 2] | [128, 80, 80] | [128, 40, 40] |
| 19 | [-1, 14] | Concat | [1] | [1, 128, 40, 40],[1, 128, 40, 40] | [256, 40, 40] |
| 20 | -1 | C3 | [256, 256, 1, False] | [256, 40, 40] | [256, 40, 40] |
| 21 | -1 | Conv | [256, 256, 3, 2] | [256, 40, 40] | [256, 20, 20] |
| 22 | [-1, 10] | Concat | [1] | [1, 256, 20, 20],[1, 256, 20, 20] | [512, 20, 20] |
| 23 | -1 | C3 | [512, 512, 1, False] | [512, 20, 20] | [512, 20, 20] |
| 24 | [17, 20, 23] | Detect | [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]] | [1, 128, 80, 80],[1, 256, 40, 40],[1, 512, 20, 20] | [1, 3, 80, 80, 85],[1, 3, 40, 40, 85],[1, 3, 20, 20, 85] |
4.如何把多个改进写进一个yaml文件里?
有不少同学后台问过我这个问题,怎么把不同的改进写一个yaml文件里?
这个问题我真不知道怎么回答了,这无非不就是修改配置文件嘛。
虽然但是,我还是再讲解一下在yaml中添加了模块后,yaml文件该怎么修改吧。
比如说我们想在SPPF的上一层添加一个SE模块

此时我们首先在配置文件的SPPF上面加一个SE模块,我们上面讲过了各个参数的含义了,我这里只讲每次修改配置文件后我们要注意的几个地方
.....
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SE, [16]],
[-1, 1, SPPF, [1024, 5]], # 9
]
.....
Concat的from系数Detect的from系数
Concat的from系数要注意特征图的尺寸
Detect的from系数就是我们最终输出的预测特征图
当我们添加了模块后,注重修改这两个地方就行了,



修改完的yaml文件就是这样子的:
# by CSDN 迪菲赫尔曼
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SE, [16]],
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.1 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
7.如何添加检测头?
7.1 四头(P2, P3, P4, P5)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head with (P2, P3, P4, P5) outputs
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P2
[-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P3
[-1, 3, C3, [256, False]], # 24 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 27 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 30 (P5/32-large)
[[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
]
添加一个模块你会了,那添加多个不就是重复一次这个过程嘛。
7.2 四头(P3, P4, P5, P6)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [768, 3, 2]], # 7-P5/32
[-1, 3, C3, [768]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 11
]
# YOLOv5 v6.0 head with (P3, P4, P5, P6) outputs
head:
[[-1, 1, Conv, [768, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P5
[-1, 3, C3, [768, False]], # 15
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 19
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 23 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 20], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 26 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [768, False]], # 29 (P5/32-large)
[-1, 1, Conv, [768, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P6
[-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
[[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
]
7.3 四头BiFPN(P3, P4, P5, P6)
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [ 19,27, 44,40, 38,94 ] # P3/8
- [ 96,68, 86,152, 180,137 ] # P4/16
- [ 140,301, 303,264, 238,542 ] # P5/32
- [ 436,615, 739,380, 925,792 ] # P6/64
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[ [-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [768, 3, 2]], # 7-P5/32
[-1, 3, C3, [768]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 11
]
# YOLOv5 head
head:
[ [ -1, 1, Conv, [ 768, 1, 1 ] ], # 12 head
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 8 ], 1, BiFPN_Add2, [ 384,384] ], # cat backbone P5
[ -1, 3, C3, [ 768, False ] ], # 15
[ -1, 1, Conv, [ 512, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 6 ], 1, BiFPN_Add2, [ 256,256] ], # cat backbone P4
[ -1, 3, C3, [ 512, False ] ], # 19
[ -1, 1, Conv, [ 256, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 4 ], 1, BiFPN_Add2, [ 128,128] ], # cat backbone P3
[ -1, 3, C3, [ 256, False ] ], # 23 (P3/8-small)
[ -1, 1, Conv, [ 512, 3, 2 ] ],
[ [ -1, 6, 19 ], 1, BiFPN_Add3, [ 256 , 256 ] ], # cat head P4
[ -1, 3, C3, [ 512, False ] ], # 26 (P4/16-medium)
[ -1, 1, Conv, [ 768, 3, 2 ] ],
[ [ -1, 8, 15 ], 1, BiFPN_Add3, [ 384,384 ] ], # cat head P5
[ -1, 3, C3, [ 768, False ] ], # 29 (P5/32-large)
[ -1, 1, Conv, [ 1024, 3, 2 ] ], #30
[ [ -1, 11 ], 1, BiFPN_Add2, [ 512, 512] ], # cat head P6
[ -1, 3, C3, [ 1024, False ] ], # 32 (P6/64-xlarge)
[ [ 23, 26, 29, 32 ], 1, Detect, [ nc, anchors ] ], # Detect(P3, P4, P5, P6)
]
7.3 五头(P3, P4, P5, P6, P7)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [768, 3, 2]], # 7-P5/32
[-1, 3, C3, [768]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
[-1, 3, C3, [1024]],
[-1, 1, Conv, [1280, 3, 2]], # 11-P7/128
[-1, 3, C3, [1280]],
[-1, 1, SPPF, [1280, 5]], # 13
]
# YOLOv5 v6.0 head with (P3, P4, P5, P6, P7) outputs
head:
[[-1, 1, Conv, [1024, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 10], 1, Concat, [1]], # cat backbone P6
[-1, 3, C3, [1024, False]], # 17
[-1, 1, Conv, [768, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P5
[-1, 3, C3, [768, False]], # 21
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 25
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 29 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 26], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 32 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 22], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [768, False]], # 35 (P5/32-large)
[-1, 1, Conv, [768, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P6
[-1, 3, C3, [1024, False]], # 38 (P6/64-xlarge)
[-1, 1, Conv, [1024, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P7
[-1, 3, C3, [1280, False]], # 41 (P7/128-xxlarge)
[[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
]
8.如何减少检测头?
8.1 两头(P3, P4)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[ [ -1, 1, Conv, [ 64, 6, 2, 2 ] ], # 0-P1/2
[ -1, 1, Conv, [ 128, 3, 2 ] ], # 1-P2/4
[ -1, 3, C3, [ 128 ] ],
[ -1, 1, Conv, [ 256, 3, 2 ] ], # 3-P3/8
[ -1, 6, C3, [ 256 ] ],
[ -1, 1, Conv, [ 512, 3, 2 ] ], # 5-P4/16
[ -1, 9, C3, [ 512 ] ],
[ -1, 1, Conv, [ 1024, 3, 2 ] ], # 7-P5/32
[ -1, 3, C3, [ 1024 ] ],
[ -1, 1, SPPF, [ 1024, 5 ] ], # 9
]
# YOLOv5 v6.0 head with (P3, P4) outputs
head:
[ [ -1, 1, Conv, [ 512, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 6 ], 1, Concat, [ 1 ] ], # cat backbone P4
[ -1, 3, C3, [ 512, False ] ], # 13
[ -1, 1, Conv, [ 256, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 4 ], 1, Concat, [ 1 ] ], # cat backbone P3
[ -1, 3, C3, [ 256, False ] ], # 17 (P3/8-small)
[ -1, 1, Conv, [ 256, 3, 2 ] ],
[ [ -1, 14 ], 1, Concat, [ 1 ] ], # cat head P4
[ -1, 3, C3, [ 512, False ] ], # 20 (P4/16-medium)
[ [ 17, 20 ], 1, Detect, [ nc, anchors ] ], # Detect(P3, P4)
]
9.如何使用更深层的网络?
这个在models/hub里面自带了,一般是高分辨率图像适合使用的。里面很多版本,可自行选择。

这是零基础解析系列的第一篇文章,后续会继续带大家拆解YOLO项目,让大家彻底掌握YOLO算法,欢迎点赞哦~
原创声明!本教程为 CSDN博主迪菲赫尔曼 编写,禁止任何方式转载!违规必纠!


















 8242
8242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











