







 本文提出了一种名为SA-NET的混洗注意力模块,有效地结合了空间和通道注意力机制,降低了计算负担。SA模块通过通道分割、注意力处理和聚合,实现了高效的信息交流。在ImageNet-1k、MS COCO等任务上,SA-NET在提高性能的同时保持了较低的模型复杂度,优于当前SOTA方法。
本文提出了一种名为SA-NET的混洗注意力模块,有效地结合了空间和通道注意力机制,降低了计算负担。SA模块通过通道分割、注意力处理和聚合,实现了高效的信息交流。在ImageNet-1k、MS COCO等任务上,SA-NET在提高性能的同时保持了较低的模型复杂度,优于当前SOTA方法。

论文名称:《SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS》
注意力机制允许神经网络准确聚焦于输入的所有相关元素,已成为提高深度神经网络性能的重要组成部分。计算机视觉研究中主要有两种常用的注意力机制,分别是空间注意力和通道注意力,旨在分别捕捉像素级的成对关系和通道依赖关系。虽然将它们融合在一起可能比单独实现能取得更好的性能,但这不可避免地增加了计算负担。在本文中,我们提出了一种有效的混洗注意力 (Shuffle Attention,SA) 模块来解决这个问题,它采用混洗单元 (Shuffle Units) 有效地结合了这两种注意力机制。
具体而言,SA 首先将通道维度分成多个子特征,然后并行处理它们。然后,对于每个子特征,SA 使用一个混洗单元来描述在空间和通道维度上的特征依赖关系。接着,所有子特征被聚合,并采用“通道混洗”操作符,以促进不同子特征之间的信息交流。所提出的 SA 模块高效且有效,例如,与 ResNet50 主干网络相比,SA 的参数和计算量分别为 300 对 25.56M 和 0.00276 GFLOPs 对 4.12 GFLOPs,而 Top-1 准确率的性能提升超过 1.34%。在常用基准测试上的广泛实验结果,包括 ImageNet-1k 用于分类、MS COCO 用于目标检测和实例分割,显示出所提出的 SA 在提高准确度的同时具有较低的模型复杂度,显著优于当前最先进的方法。

最近在ImageNet-1k上使用ResNet作为主干进行的最新SOTA注意力模型的比较,包括SENet、CBAM、ECA-Net、SGE-Net和SA-Net,比较的方面有准确率、网络参数和GFLOPs。圆圈的大小表示GFLOPs的数量。显然,所提出的SA-Net在保持较低模型复杂度的同时,获得了更高的准确率。
问题背景
注意力机制在深度学习中备受关注,因为它可以帮助神经网络准确地关注输入中的相关元素,从而显著提高性能。在计算机视觉研究中,主要有两种常见的注意力机制:空间注意力和通道注意力。空间注意力主要关注像素级的关系,而通道注意力则侧重于捕捉通道间的依赖性。然而,融合这两者通常会导致计算开销的增加,这使得模型的复杂度变高。本文提出了一种高效的Shuffle Attention (SA)模块,通过Shuffle Units有效地结合两种注意力机制,解决了这个问题。
核心概念
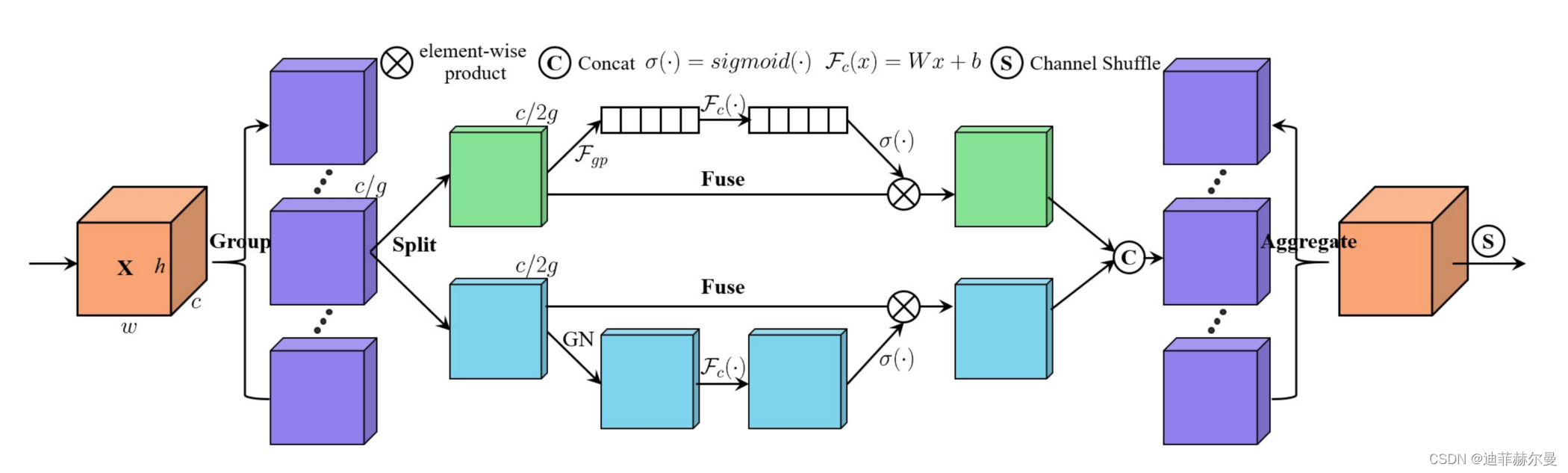
所提出的SA模块概览。它采用“通道分割”来并行处理每个组的子特征。在通道注意力分支中,使用GAP生成通道级统计数据,然后使用一对参数对通道向量进行缩放和偏移。在空间注意力分支中,采用组归一化生成空间级统计数据,然后创建一个与通道分支相似的紧凑特征。接着,这两个分支被连接在一起。然后,所有子特征被汇总,最后我们使用“通道打乱”操作符来实现不同子特征之间的信息传递。
SA模块的核心概念在于将通道维度分组成多个子特征,然后并行处理它们。每个子特征都采用Shuffle Unit,以同时在空间和通道维度上描述特征依赖性。然后,所有子特征被聚合,最后通过“通道洗牌”(channel shuffle)操作来实现不同子特征之间的信息沟通。SA模块采用这种方式来实现轻量级但高效的注意力机制,既能够提升性能,又不会显著增加计算负担。
模块的操作步骤
SA模块的操作步骤包括四个主要环节:特征分组、通道注意力、空间注意力和聚合。
- 在特征分组步骤中,
SA模块将输入特征图按通道维度分成多个子特征,每个子特征代表不同的语义响应。 - 在通道注意力步骤中,
SA模块通过全局平均池化生成通道统计数据,然后使用一对参数来调整通道向量。 - 在空间注意力步骤中,
SA模块采用组规范化(Group Norm)生成空间统计数据,利用这些数据创建类似通道注意力的紧凑特征。 - 在聚合步骤中,所有子特征被聚合,然后通过“通道洗牌”操作来实现不同子特征之间的信息交流。
文章贡献
本文的主要贡献在于提出了一种轻量级但高效的注意力模块,SA模块可以将通道维度分组成多个子特征,然后使用Shuffle Unit有效地结合通道和空间注意力机制。SA模块在保持低模型复杂度的同时,显著提高了网络的性能。本文通过在ImageNet-1k、MS COCO等常用基准上进行实验,展示了SA模块在分类、目标检测和实例分割等任务上的卓越性能。
实验结果与应用
实验结果显示,SA模块在ImageNet-1k分类任务中可以显著提升性能,特别是与其他SOTA方法相比,SA模块的模型复杂度更低,但准确性更高。在MS COCO上的目标检测和实例分割实验中,SA模块也表现出色。这些结果表明,SA模块不仅能提高模型性能,而且在计算成本上非常高效。
对未来工作的启示
SA模块的成功启示了在深度CNN中采用轻量级但高效的注意力机制的潜力。未来的研究可以进一步探索SA模块在其他类型的CNN架构中的应用,以及如何将其与其他注意力机制相结合。此外,由于SA模块的轻量级特征,它在移动设备和嵌入式系统中的应用前景也非常广阔。这种模块化的设计理念可以启发研究人员进一步研究高效注意力机制在深度学习中的应用。
代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
# group into subfeatures
x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w
# channel_split
x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w
# channel attention
x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1
x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1
x_channel = x_0 * self.sigmoid(x_channel)
# spatial attention
x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w
x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w
x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w
# concatenate along channel axis
out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w
out = out.contiguous().view(b, -1, h, w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
if __name__ == "__main__":
input = torch.randn(64, 256, 8, 8)
model = ShuffleAttention(channel=256, G=8)
output = model(input)
print(output.shape)


















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











