







笔记_5
特征点匹配
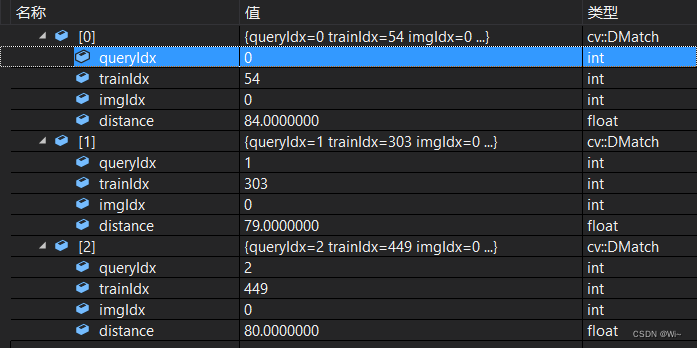
DMatch 存放匹配结果

DMatch类是OpenCV库中用于描述特征匹配结果的数据结构之一。它提供了用于表示匹配结果的成员变量和方法。以下是DMatch类的详细解释:
class DMatch {
public:
int queryIdx; // 查询图像中的描述子索引
int trainIdx; // 训练图像中的描述子索引
int imgIdx; // 描述子所属的图像索引
float distance; // 描述子之间的距离
DMatch(); // 默认构造函数
DMatch(int _queryIdx, int _trainIdx, int _imgIdx, float _distance); // 构造函数
};
DMatch类有四个成员变量:
-
queryIdx:表示查询图像中的描述子索引。在特征匹配中,通常会有一个查询图像和一个训练图像,queryIdx表示匹配结果中的查询图像中的描述子的索引。 -
trainIdx:表示训练图像中的描述子索引。在特征匹配中,trainIdx表示匹配结果中的训练图像中的描述子的索引。 -
imgIdx:表示描述子所属的图像索引。在某些特定的场景中,可能会涉及多个图像的特征匹配,imgIdx用于指示描述子属于哪个图像。 -
distance:表示描述子之间的距离。在特征匹配中,通常使用某种距离度量来衡量描述子之间的相似性,distance就表示了这个距离。
DMatch类还提供了两个构造函数:
- 默认构造函数
DMatch():创建一个未初始化的DMatch对象。 - 构造函数
DMatch(int _queryIdx, int _trainIdx, int _imgIdx, float _distance):创建一个具有给定queryIdx、trainIdx、imgIdx和distance的DMatch对象。
DMatch类用于存储特征匹配的结果,可以通过创建和操作DMatch对象来管理和处理描述子之间的匹配信息。
DescriptorMatcher::match 特征点描述子(一对一)匹配
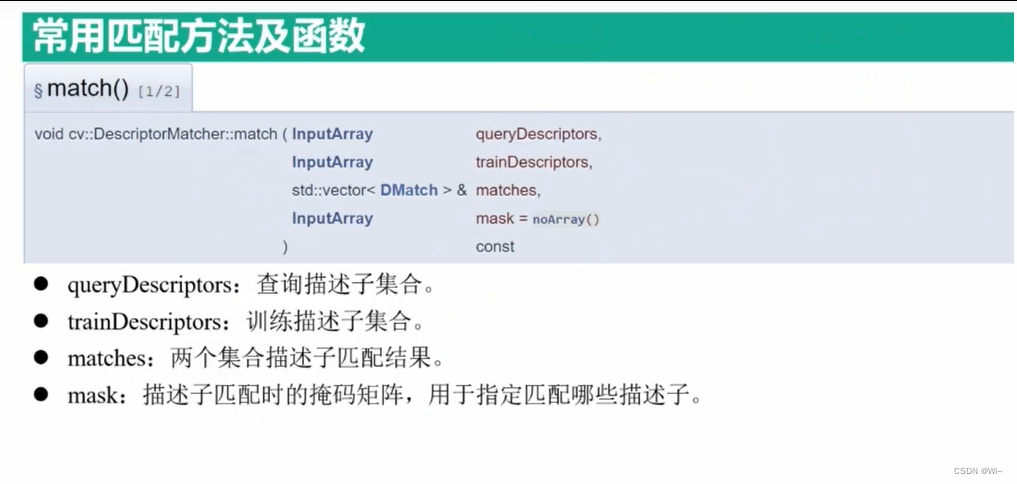
cv::DescriptorMatcher::match是OpenCV中的一个函数,用于在给定的两组特征描述符之间进行匹配。它可以帮助找到在不同图像或点云之间具有相似特征的对应关系。
以下是函数的详细解释:
void DescriptorMatcher::match(
InputArray queryDescriptors, // 输入的查询描述符(特征)数组
InputArray trainDescriptors, // 输入的训练描述符(特征)数组
std::vector<DMatch>& matches, // 输出的匹配结果数组
InputArray mask = noArray() // 可选的掩码数组,用于指定哪些查询描述符应该与训练描述符进行匹配
)
参数说明:
queryDescriptors:输入的查询描述符(特征)数组。通常来自于查询图像或点云。trainDescriptors:输入的训练描述符(特征)数组。通常来自于训练图像或点云。matches:输出的匹配结果数组。matches是一个std::vector<DMatch>类型的引用,其中DMatch是一个包含匹配对应关系的结构体。每个DMatch包含以下信息:queryIdx:查询描述符的索引。trainIdx:训练描述符的索引。imgIdx:表示描述子所属的图像索引。distance:描述符之间的距离或相似度度量。
mask:可选的掩码数组,用于指定哪些查询描述符应该与训练描述符进行匹配。它的大小必须与查询描述符的数量相同,类型为CV_8UC1。如果不需要使用掩码,可以将其设置为默认值noArray()。
下面为BFMatcher 暴力匹配的结果matches,可以发现queryDescriptors(查询描述符:比如大小为n)每个索引都要和trainDescriptors(训练描述符:比如大小为m)的索引匹配一次,所以时间复杂度为 n*m
DescriptorMatcher::knnMatch 特征点描述子(一对多)匹配
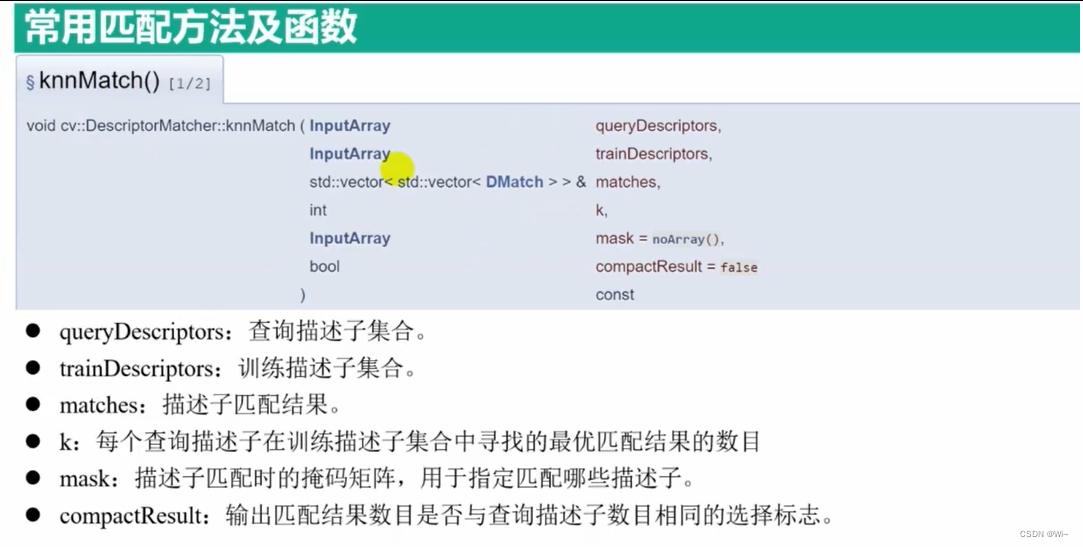
DescriptorMatcher::knnMatch 是 OpenCV 中用于特征匹配的函数之一。它可以用来匹配图像或特征点的描述符。
以下是对 knnMatch 函数的详细解释:
void DescriptorMatcher::knnMatch(
InputArray queryDescriptors,
InputArray trainDescriptors,
std::vector<std::vector<DMatch>>& matches,
int k,
InputArray mask = noArray(),
bool compactResult = false
)
参数:
queryDescriptors:查询图像或特征点的描述符。通常是一个特征点检测器(如SIFT、SURF等)提取的描述符矩阵。trainDescriptors:训练图像或特征点的描述符。通常是一个特征点检测器提取的描述符矩阵。matches:输出的匹配结果,是一个二维向量。queryDescriptors[i]一对多trainDescriptors。遍历匹配。k:指定要返回的最佳匹配数。对于每个查询描述子,函数将返回与之最匹配的前k个训练描述子。masks:可选的掩码向量,用于过滤匹配。如果提供了掩码,则只有与掩码对应位置为非零的描述子才会被匹配。compactResult:只针对掩码使用的参数。如果compactResult为false,则匹配向量的大小与queryDescriptors的行大小相同。如果compactResult为true,则匹配向量的大小和掩码大于0的行数一致。
一个布尔值,用于指示是否以紧凑形式存储匹配结果。如果为true,则每个查询描述子只返回k个最佳匹配,而不是所有可能的匹配。函数使用 k 最近邻算法来找到最佳匹配。匹配结果按照距离的升序排列,最佳匹配在前。
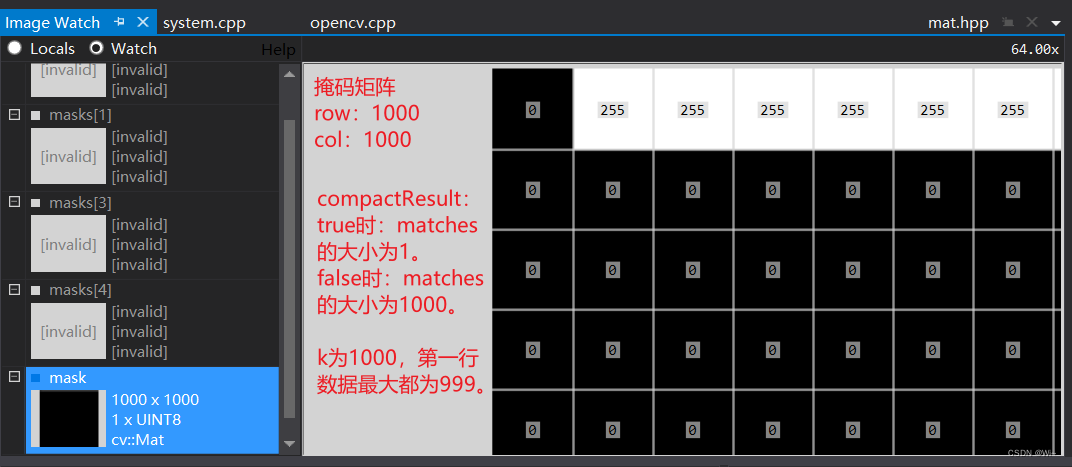
cv::Mat mask(descriptors1.rows, descriptors2.rows, CV_8U, cv::Scalar(0));
mask.row(0) = 255;
vector<vector<DMatch>> matches, matches1;//定义存放匹配结果的变量
BFMatcher matcher(NORM_HAMMING);//定义特征点匹配的类-暴力匹配,使用汉明距离
matcher.knnMatch(descriptors1, descriptors2,matches, 200, mask,true);//进行特征点匹配
matcher.knnMatch(descriptors1, descriptors2, matches1, 200, mask, false);//进行特征点匹配

DescriptorMatcher::radiusMatch 特征点描述子(一对多)特定范围匹配

DescriptorMatcher::radiusMatch是OpenCV中的一个函数,用于在给定的描述子集中进行半径匹配(radius matching)。该函数的主要作用是找到与每个查询描述子最接近的训练描述子,并且距离小于或等于给定的半径值。
以下是DescriptorMatcher::radiusMatch函数的详细解释:
void DescriptorMatcher::radiusMatch(
InputArray queryDescriptors, // 查询描述子集
InputArray trainDescriptors,
std::vector<std::vector<DMatch>>& matches, // 存储匹配结果的二维向量
float maxDistance, // 最大距离阈值
InputArrayOfArrays masks = noArray(), // 可选的掩码
bool compactResult = false // 是否只存储最佳匹配
) const;
参数解释:
queryDescriptors:一个输入数组,包含查询描述子的集合。每个查询描述子是一个浮点型向量,通常由特征检测器生成。trainDescriptors:训练图像或特征点的描述符。通常是一个特征点检测器提取的描述符矩阵。matches:一个二维向量,用于存储匹配结果。每个查询描述子的匹配结果将存储为一个DMatch对象的向量,表示匹配到的训练描述子的索引和距离。maxDistance:最大距离阈值。只有距离小于或等于此值的匹配才会被接受。masks(可选参数):一个可选的掩码数组,用于指定哪些查询和训练描述子对参与匹配。如果提供了掩码,只有与非零掩码对应的描述子才会被匹配。compactResult(可选参数):一个布尔值,用于指定是否只存储每个查询描述子的最佳匹配(距离最近的匹配)。如果为true,matches向量的大小将与查询描述子的数量相同;如果为false,matches向量的大小将与查询描述子的数量不一定相同,取决于在给定的最大距离内有多少匹配。
`maxDistance`是`DescriptorMatcher::radiusMatch`函数的一个参数,它表示最大距离阈值。在执行半径匹配时,只有距离小于或等于`maxDistance`的匹配才会被接受。
具体来说,对于每个查询描述子,`radiusMatch`函数会在训练描述子集中找到所有距离小于或等于`maxDistance`的匹配。匹配结果将存储在`matches`参数指定的二维向量中。
通过调整`maxDistance`的值,可以控制匹配的严格程度。较小的`maxDistance`值将导致更严格的匹配条件,只有非常相似的描述子才会被匹配。较大的`maxDistance`值则允许更宽松的匹配条件,更多的描述子对可能被认为是匹配的。
需要根据具体应用场景和描述子的特点来选择合适的`maxDistance`值。一般来说,可以通过试验和调整来找到适合的阈值,以达到最佳的匹配效果。
BFMatcher 暴力匹配 -在(特征点Feature2D类介绍)这篇文章中有介绍
drawMatches 绘制特征点匹配结果
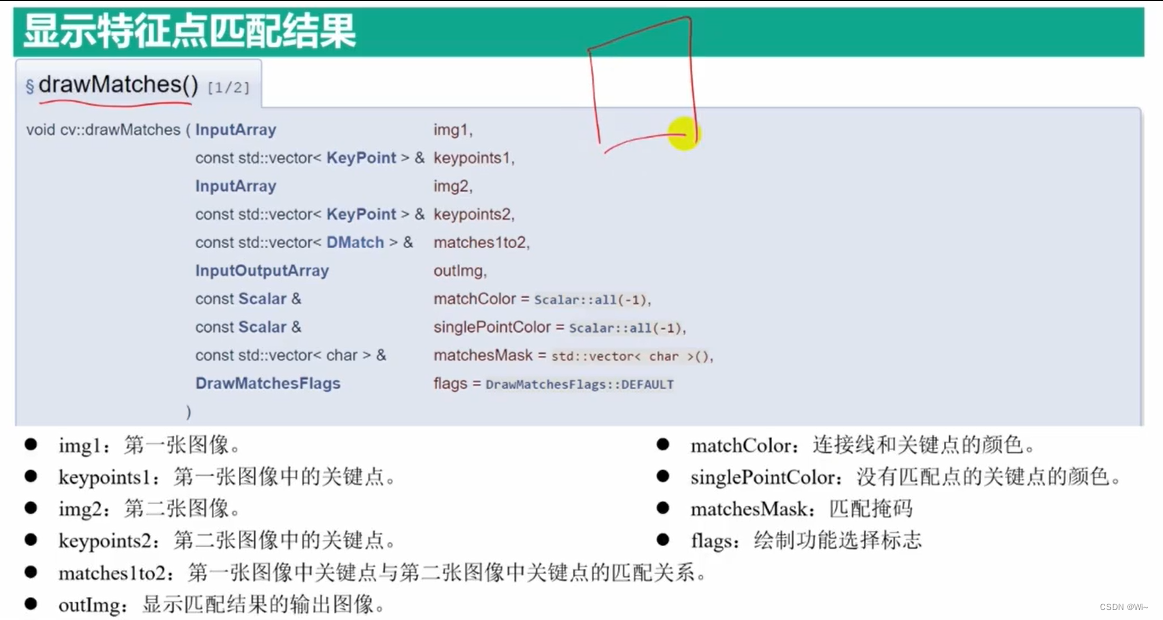
drawMatches函数是OpenCV中用于绘制两个图像之间匹配特征点的函数。它将两个图像中的特征点连接起来,并在结果图像中绘制这些连接线。
函数原型如下:
void drawMatches(
InputArray img1, // 第一幅图像
const std::vector<KeyPoint>& keypoints1, // 第一幅图像的特征点
InputArray img2, // 第二幅图像
const std::vector<KeyPoint>& keypoints2, // 第二幅图像的特征点
const std::vector<DMatch>& matches, // 特征点匹配结果
OutputArray outImg, // 输出的匹配结果图像
const Scalar& matchColor = Scalar::all(-1), // 连接线的颜色
const Scalar& singlePointColor = Scalar::all(-1), // 特征点的颜色
const std::vector<char>& matchesMask = std::vector<char>(), // 特征点匹配掩码
int flags = DrawMatchesFlags::DEFAULT // 绘制匹配特征点的标志
);
参数说明:
img1:第一幅图像(可以是灰度图像或彩色图像)keypoints1:第一幅图像的特征点,类型为std::vector<KeyPoint>,每个特征点包含其坐标和其他属性。img2:第二幅图像(与img1具有相同的类型)keypoints2:第二幅图像的特征点,与keypoints1具有相同的类型。matches:特征点匹配结果,类型为std::vector<DMatch>,表示两幅图像之间的特征点匹配。outImg:输出的匹配结果图像,类型为OutputArray。matchColor:连接线的颜色,可以指定为Scalar类型的值,默认为Scalar::all(-1)表示随机颜色。singlePointColor:特征点的颜色,可以指定为Scalar类型的值,默认为Scalar::all(-1)表示随机颜色。matchesMask:掩码向量,用于标识哪些匹配是有效的。长度应与matches1to2的长度相同,默认为空。flags:绘制匹配的标志,可以是以下值的组合:DrawMatchesFlags::DEFAULT:默认标志,显示所有匹配。DrawMatchesFlags::DRAW_OVER_OUTIMG:在outImg上绘制匹配,默认是在空白图像上绘制。DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS:不绘制单个特征点。DrawMatchesFlags::DRAW_RICH_KEYPOINTS:绘制特征点的大小和方向。
使用drawMatches函数可以方便地将特征点匹配结果可视化,帮助我们分析和理解特征点匹配的效果。
代码演示:
void features(Mat &img, vector<KeyPoint> &keypoints, Mat &descriptors)
{
Ptr<ORB> orb = ORB::create(1000);
orb->detectAndCompute(img, Mat(), keypoints, descriptors);
//cv::Ptr<cv::SIFT> detector = cv::SIFT::create();
//detector->detectAndCompute(img, cv::noArray(), keypoints, descriptors);
}
Mat img1 = imread("box_in_scene.jpg");
Mat img2 = imread("box.jpg");
if (!(img1.data && img2.data))
{
cout << "图像打开失败。。。" << endl;
return -1;
}
//提取ORB特征点和描述子
vector<KeyPoint> keypoints1, keypoints2;
Mat descriptors1, descriptors2;
//计算特征点
features(img1, keypoints1, descriptors1);
features(img2, keypoints2, descriptors2);
//特征点匹配
vector<DMatch> matches;//定义存放匹配结果的变量
BFMatcher matcher(NORM_HAMMING);//定义特征点匹配的类-暴力匹配,使用汉明距离
matcher.match(descriptors1, descriptors2, matches);//进行特征点匹配
//cv::Mat mask(descriptors1.rows, descriptors2.rows, CV_8U, cv::Scalar(0));
//mask.row(0) = 255;
//mask.at<uchar>(0, 0) = 0;
//vector<vector<DMatch>> matches, matches1;//定义存放匹配结果的变量
//BFMatcher matcher(NORM_HAMMING);//定义特征点匹配的类-暴力匹配,使用汉明距离
//matcher.knnMatch(descriptors1, descriptors2,matches, 1000, mask,true);//进行特征点匹配
//matcher.knnMatch(descriptors1, descriptors2, matches1, 1000, mask, false);//进行特征点匹配
cout << "matches:" << matches.size() << endl;
double min_dist = 1000, max_dist = 0;
for (int i = 0; i < matches.size(); ++i)
{
double dist = matches[i].distance;
if (dist < min_dist)
min_dist = dist;
else if (dist > min_dist)
max_dist = dist;
}
//输出所有匹配结果中最大汉明距离和最小汉明距离
cout << "min_dist:" << min_dist << endl;
cout << "max_dist:" << max_dist << endl;
vector<DMatch> good_matches;
//将汉明距离最大的匹配点对删除
for (int i = 0; i < matches.size(); ++i)
{
if (matches[i].distance <= max(2 * min_dist, 20.0))
{
good_matches.push_back(matches[i]);
}
}
//剩余特征点数目
cout << "good_min:" << good_matches.size() << endl;
//绘制匹配结果
Mat outimg1, outimg2;
drawMatches(img1, keypoints1, img2, keypoints2, matches, outimg1);
drawMatches(img1, keypoints1, img2, keypoints2, good_matches, outimg2);
namedWindow("未删选结果",WINDOW_NORMAL);
namedWindow("最小汉明距离筛选", WINDOW_NORMAL);
imshow("未删选结果", outimg1);
imshow("最小汉明距离筛选", outimg2);

RANSAC 优化特征点算法

findHmomography 单应性变换 :优化特征点
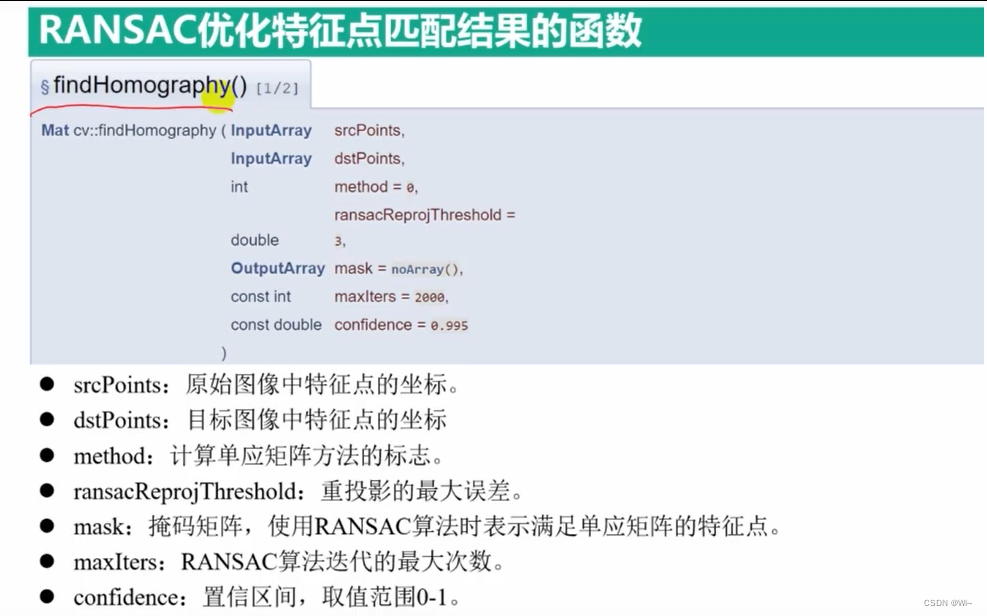
cv::findHomography函数是OpenCV库中用于计算单应性矩阵(homography)的函数。单应性矩阵是一个3x3的矩阵,用于描述两个平面之间的投影变换关系。在计算机视觉中,单应性矩阵常用于图像校正、特征匹配和图像拼接等任务中。
下面是cv::findHomography函数的详细解释:
cv::Mat cv::findHomography(
InputArray srcPoints, // 输入源点的坐标,可以是一个单通道浮点型点集,或者一个包含点集的矩阵
InputArray dstPoints, // 输入目标点的坐标,与srcPoints有相同的数据类型和大小
int method, // 单应性矩阵计算方法的标志位,常用的有RANSAC和LMEDS ,默认值为0:最小二乘法
double ransacReprojThreshold = 3, // RANSAC算法中的重投影阈值,用于判断内点和外点
OutputArray mask = noArray(), // 输出的掩码矩阵,标记计算出的内点和外点
const int maxIters = 2000, // 最大迭代次数,用于RANSAC和LMEDS算法
const double confidence = 0.995 // RANSAC和LMEDS算法的置信度
);
参数解释:
srcPoints和dstPoints:分别是源图像中的点和目标图像中的对应点。这些点可以通过特征匹配算法(如SIFT、SURF等)获得。srcPoints和dstPoints的数据类型可以是单通道浮点型点集或包含点集的矩阵。method:单应性矩阵计算方法的标志位。常用的方法有两种:cv::RANSAC和cv::LMEDS。RANSAC方法基于随机采样一致性算法,而LMEDS方法使用最小中值差估计。ransacReprojThreshold:RANSAC算法的重投影阈值,用于判断内点和外点。当一个点的重投影误差小于该阈值时,认为该点是内点,否则为外点。默认值是3。mask:输出的掩码矩阵,用于标记计算出的内点和外点。内点对应掩码矩阵中的非零值,外点对应零值。如果不需要这个掩码矩阵,可以将其设置为cv::noArray()。maxIters:RANSAC和LMEDS算法的最大迭代次数。默认值是2000。confidence:RANSAC和LMEDS算法的置信度。该值表示计算得到的单应性矩阵的正确性的置信度。默认值是0.995,表示置信度为99.5%。
返回值:
- 函数返回一个3x3的双精度浮点型矩阵,即计算得到的单应性矩阵。如果无法计算出单应性矩阵,则返回一个空矩阵。
method
cv::findHomography函数中的method参数指定了单应性矩阵计算的方法。OpenCV提供了四种常用的方法,下面对这四种方法进行介绍:
-
0使用所有点的常规方法,即最小二乘法(默认值) -
cv::RANSAC = 8(RANdom SAmple Consensus):
RANSAC是一种基于统计的迭代算法,用于估计数学模型参数。在计算单应性矩阵时,RANSAC方法会随机选择一小组点对,然后根据这些点对计算出单应性矩阵。然后,它会计算其他点的重投影误差,并根据重投影误差和阈值,判断点是否属于内点或外点。算法会不断迭代,直到找到一组内点数目最多的单应性矩阵估计。 -
cv::LMEDS = 4(Least Median of Squares):
LMEDS方法也是一种迭代算法,用于估计数学模型参数。与RANSAC不同的是,LMEDS方法使用中值差来估计模型参数,而不是均方差。中值差可以更好地抵抗异常值的干扰。LMEDS方法会随机选择一小组点对,并根据这些点对计算出单应性矩阵。然后,它会计算其他点的重投影误差,并根据中值差和阈值,判断点是否属于内点或外点。算法会不断迭代,直到找到一组内点数目最多的单应性矩阵估计。 -
cv::RHO = 16(Randomized HOmography):
RHO方法是一种改进的随机采样一致性算法,用于估计数学模型参数。它在RANSAC算法的基础上进行了优化,通过随机选择更少的点对进行估计。这样可以加快计算速度,同时保持较好的精度。RHO方法在计算单应性矩阵时与RANSAC方法类似,但使用了不同的采样策略。
mask
内点的元素值为非零值为1,对应于外点的元素值为0
在cv::findHomography函数中,mask参数是一个输出参数,用于标记计算得到的内点和外点。它是一个掩码矩阵,与输入的源点和目标点对应,标记了哪些点是内点,哪些点是外点。
掩码矩阵是一个与源点和目标点相同大小的矩阵,其中的元素值为0或非零值。对应于内点的元素值为非零值为1,对应于外点的元素值为0。通过检查掩码矩阵中的元素值,可以确定哪些点是内点,哪些点是外点。
在使用cv::findHomography函数时,如果需要获取内点和外点的信息,可以传递一个cv::Mat类型的参数作为mask。例如:
cv::Mat mask;
cv::Mat homography = cv::findHomography(srcPoints, dstPoints, cv::RANSAC, 3.0, mask);
在上述示例中,mask就是输出的掩码矩阵,用于标记计算得到的内点和外点。对应于内点的mask矩阵中的元素值为非零值,对应于外点的元素值为0。
需要注意的是,如果不需要获取内点和外点的信息,可以将mask参数设置为cv::noArray(),即不指定输出的掩码矩阵。
在得到掩码矩阵后,可以根据掩码矩阵提取内点和外点,进行后续的处理和分析。
什么数内点和外点
在计算单应性矩阵时,内点(inliers)和外点(outliers)是根据重投影误差与阈值的比较来确定的。
内点是指重投影误差小于给定阈值的点,它们与计算得到的单应性矩阵具有一致性,可以被认为是正确匹配的点对。内点对应于图像中具有良好对应关系的特征点或关键点。
外点是指重投影误差大于或等于给定阈值的点,它们与计算得到的单应性矩阵不一致,可能是匹配错误或存在噪声的点对。外点对应于图像中没有正确对应关系的特征点或关键点。
在cv::findHomography函数中,通过指定重投影阈值(ransacReprojThreshold参数),函数会计算每个点的重投影误差,并将重投影误差与阈值进行比较。如果重投影误差小于阈值,则将该点标记为内点,否则标记为外点。
计算得到的内点和外点信息可以通过输出的掩码矩阵(mask参数)来获取。掩码矩阵中对应于内点的元素值为非零值,对应于外点的元素值为0。通过检查掩码矩阵中的元素值,可以确定哪些点是内点,哪些点是外点。
内点和外点的区分对于后续的图像处理和分析非常重要,可以排除外点的干扰,提高算法的准确性和鲁棒性。
RANSAC 是什么样的算法,它和最小二乘法有什么不一样
RANSAC(RANdom SAmple Consensus)是一种基于统计的迭代算法,用于估计数学模型参数。RANSAC算法适用于数据集中存在异常值(outliers)的情况,可以有效地抵抗异常值的干扰。
RANSAC算法的基本思想是通过随机采样一小组数据点来估计模型参数,然后根据估计的模型参数计算其他数据点的拟合程度,并根据预设的阈值(重投影阈值)判断数据点是属于内点(inliers)还是外点(outliers)。算法会迭代执行以上过程,直到找到内点数目最多的模型参数估计。
与RANSAC相比,最小二乘法(Least Squares)是一种经典的优化方法,用于拟合数据和估计参数。最小二乘法通过最小化数据点与模型之间的误差平方和来求解最优参数。最小二乘法假设数据中没有异常值,其目标是找到能够最小化误差的参数值。
最小二乘法的一个主要特点是对异常值非常敏感,即单个异常值可以对拟合结果产生较大影响。在数据集中存在异常值时,最小二乘法可能会导致模型拟合不准确。而RANSAC算法通过随机采样和内点外点判断的策略,可以在存在异常值的情况下,仍能够得到较为鲁棒的模型参数估计。
因此,RANSAC算法和最小二乘法在处理带有异常值的数据时有所不同。RANSAC通过迭代和内点外点判断来选择最优模型参数,可以更好地抵抗异常值的干扰,而最小二乘法则会受到异常值的影响,容易导致拟合结果偏离真实模型。
RANSAC实现
RANSAC算法的实现步骤如下:
- 从数据集中随机选择一小部分数据点作为样本,通常称为抽样(sampling)步骤。
- 根据选取的样本,估计模型参数。
- 对于其他未被选取的数据点,计算它们与估计模型之间的误差,并将其与预设的阈值进行比较。如果误差小于阈值,则将该数据点标记为内点;否则标记为外点。
- 统计内点数量。
- 重复执行上述步骤多次,选择具有最多内点的模型参数作为最终估计结果。
下面是一个简单的伪代码示例,演示了RANSAC算法的实现:
输入: 数据集 D,迭代次数 N,样本数量 K,阈值 T
bestModel = null
bestInliersCount = 0
for i = 1 to N do
// 1. 从数据集中随机选择样本
sample = 随机从数据集 D 中选择 K 个数据点
// 2. 估计模型参数
model = 根据样本计算模型参数
inliersCount = 0
inliers = 空集合
for each 数据点 p in 数据集 D do
// 3. 计算数据点与估计模型之间的误差
error = 计算数据点 p 与模型之间的误差
if error < T then
// 4. 将误差小于阈值的数据点标记为内点
inliersCount = inliersCount + 1
inliers.add(p)
if inliersCount > bestInliersCount then
// 保存内点最多的模型参数
bestModel = model
bestInliersCount = inliersCount
if inliersCount > 阈值(例如,大于数据集的一定百分比) then
// 提前结束迭代,达到一定置信度
// 返回具有最多内点的模型参数
返回 bestModel
上述伪代码只是一个简单的示例,实际实现中可能需要根据具体情况进行适当的修改和优化。RANSAC算法的核心思想是通过随机采样和内点外点判断来选择最优模型参数,可以根据具体的问题和数据集特点进行适当的调整和改进。
以下是一个使用C++实现RANSAC算法的示例代码,以估计一条二维直线的参数为例:
#include <iostream>
#include <vector>
#include <cmath>
#include <random>
struct Point {
double x;
double y;
};
struct Line {
double a;
double b;
};
Line estimateLineRANSAC(const std::vector<Point>& points, int iterations, double threshold) {
std::random_device rd;
std::default_random_engine gen(rd());
std::uniform_int_distribution<int> dist(0, points.size() - 1);
Line bestLine;
int bestInliersCount = 0;
for (int i = 0; i < iterations; i++) {
// Step 1: Randomly select two points
int index1 = dist(gen);
int index2 = dist(gen);
const Point& p1 = points[index1];
const Point& p2 = points[index2];
// Step 2: Estimate line parameters
double a = (p2.y - p1.y) / (p2.x - p1.x);
double b = p1.y - a * p1.x;
int inliersCount = 0;
// Step 3: Count inliers
for (const Point& p : points) {
double distance = std::abs(a * p.x - p.y + b) / std::sqrt(a * a + 1);
if (distance < threshold) {
inliersCount++;
}
}
if (inliersCount > bestInliersCount) {
// Update best line parameters
bestLine.a = a;
bestLine.b = b;
bestInliersCount = inliersCount;
}
}
return bestLine;
}
int main() {
// Generate some sample points
std::vector<Point> points = {{1.0, 1.2}, {2.0, 2.8}, {3.0, 3.6}, {4.0, 4.4}, {5.0, 5.2},
{6.0, 6.8}, {7.0, 7.6}, {8.0, 8.4}, {9.0, 9.2}, {10.0, 10.8},
{11.0, 11.6}, {12.0, 12.4}, {13.0, 13.2}, {14.0, 14.8}, {15.0, 15.6},
{16.0, 16.4}, {17.0, 17.2}, {18.0, 18.8}, {19.0, 19.6}, {20.0, 20.4}};
// Estimate line parameters using RANSAC
int iterations = 1000;
double threshold = 0.5;
Line line = estimateLineRANSAC(points, iterations, threshold);
// Print the estimated line parameters
std::cout << "Estimated line: y = " << line.a << "x + " << line.b << std::endl;
return 0;
}
在上述示例代码中,首先定义了Point结构表示二维点,Line结构表示直线参数。然后,通过estimateLineRANSAC函数实现了RANSAC算法来估计直线的参数。在main函数中,生成了一组样本点,并调用estimateLineRANSAC函数来估计直线的参数。最后,输出估计得到的直线参数。
这个示例代码中的RANSAC算法用于估计一条二维直线的参数。在实际应用中,你可以根据具体的问题和数据类型进行相应的修改和适配。
请注意,这只是一个简单的示例代码,实际应用中可能需要进行更多的参数调整和错误处理。另外,该示例中的RANSAC算法只考虑了单条直线的情况,对于其他模型的估计可能需要进行适当的修改。
代码演示:
void features(Mat &img, vector<KeyPoint> &keypoints, Mat &descriptors)
{
Ptr<ORB> orb = ORB::create(1000);
orb->detectAndCompute(img, Mat(), keypoints, descriptors);
//cv::Ptr<cv::SIFT> detector = cv::SIFT::create();
//detector->detectAndCompute(img, cv::noArray(), keypoints, descriptors);
}
void ransac(vector<DMatch> matches, vector<KeyPoint> queryKeyPoint,
vector<KeyPoint> trainKeyPoint, vector<DMatch> &matches_ransac)
{
//定义保存匹配点坐标
vector<Point2f> srcPoints(matches.size()), dstPoints(matches.size());
//保存从关键点中提取到的匹配点对坐标
for (int i = 0; i < matches.size(); ++i)
{
srcPoints[i] = queryKeyPoint[matches[i].queryIdx].pt;
dstPoints[i] = trainKeyPoint[matches[i].trainIdx].pt;
}
//匹配点对进行RANSAC过滤
vector<int> inliersMask(srcPoints.size());
findHomography(srcPoints, dstPoints, RANSAC, 5, inliersMask);
//Mat inliersMask;
//findHomography(srcPoints, dstPoints, RANSAC, 5, inliersMask);
for(int i=0;i<inliersMask.size();++i)
{
if (inliersMask[i])
{
matches_ransac.push_back(matches[i]);
}
}
}
int main()
{
Mat img1 = imread("box_in_scene.jpg");
Mat img2 = imread("box.jpg");
if (!(img1.data && img2.data))
{
cout << "图像打开失败。。。" << endl;
return -1;
}
//提取ORB特征点和描述子
vector<KeyPoint> keypoints1, keypoints2;
Mat descriptors1, descriptors2;
//计算特征点
features(img1, keypoints1, descriptors1);
features(img2, keypoints2, descriptors2);
//特征点匹配
vector<DMatch> matches;//定义存放匹配结果的变量
BFMatcher matcher(NORM_HAMMING);//定义特征点匹配的类-暴力匹配,使用汉明距离
matcher.match(descriptors1, descriptors2, matches);//进行特征点匹配
//cv::Mat mask(descriptors1.rows, descriptors2.rows, CV_8U, cv::Scalar(0));
//mask.row(0) = 255;
//mask.at<uchar>(0, 0) = 0;
//vector<vector<DMatch>> matches, matches1;//定义存放匹配结果的变量
//BFMatcher matcher(NORM_HAMMING);//定义特征点匹配的类-暴力匹配,使用汉明距离
//matcher.knnMatch(descriptors1, descriptors2,matches, 1000, mask,true);//进行特征点匹配
//matcher.knnMatch(descriptors1, descriptors2, matches1, 1000, mask, false);//进行特征点匹配
cout << "matches:" << matches.size() << endl;
double min_dist = 1000, max_dist = 0;
for (int i = 0; i < matches.size(); ++i)
{
double dist = matches[i].distance;
if (dist < min_dist)
min_dist = dist;
else if (dist > min_dist)
max_dist = dist;
}
//输出所有匹配结果中最大汉明距离和最小汉明距离
cout << "min_dist:" << min_dist << endl;
cout << "max_dist:" << max_dist << endl;
vector<DMatch> good_matches;
//将汉明距离最大的匹配点对删除
for (int i = 0; i < matches.size(); ++i)
{
if (matches[i].distance <= max(2 * min_dist, 20.0))
{
good_matches.push_back(matches[i]);
}
}
//剩余特征点数目
cout << "good_min:" << good_matches.size() << endl;
vector<DMatch> good_ransac;
ransac(good_matches, keypoints1, keypoints2, good_ransac);
//绘制匹配结果
Mat outimg1, outimg2,outimg3;
drawMatches(img1, keypoints1, img2, keypoints2, matches, outimg1);
drawMatches(img1, keypoints1, img2, keypoints2, good_matches, outimg2);
drawMatches(img1, keypoints1, img2, keypoints2, good_ransac, outimg3);
namedWindow("未删选结果",WINDOW_NORMAL);
namedWindow("最小汉明距离筛选", WINDOW_NORMAL);
namedWindow("ransac筛选", WINDOW_NORMAL);
imshow("未删选结果", outimg1);
imshow("最小汉明距离筛选", outimg2);
imshow("ransac筛选", outimg3);
waitKey(0);
return 0;
}

单目相机标定
findChessboardCorners 标定板角点提取 – 棋盘格角点查找
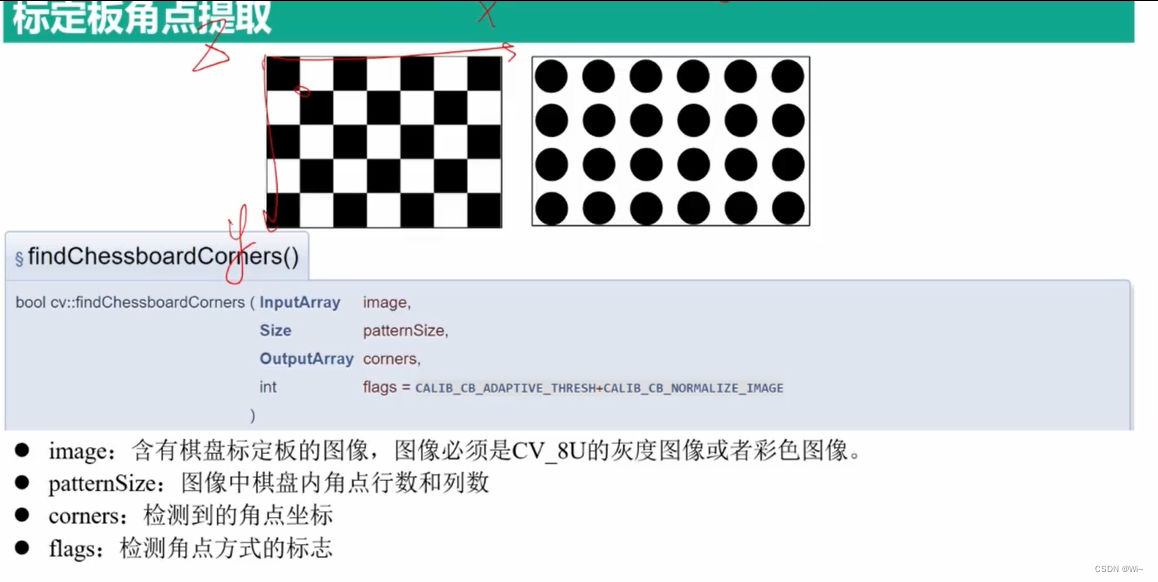
函数 findChessboardCorners 是 OpenCV 库中的一个函数,用于在给定图像中检测并定位棋盘格的角点。它是在 C++ 中实现的,并且可以用于计算机视觉和图像处理应用中的相机标定和姿态估计等任务。下面是对该函数的详细解释:
bool findChessboardCorners(InputArray image,
Size patternSize,
OutputArray corners,
int flags = CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE
);
参数:
image:输入图像,通常为灰度图像(单通道)。patternSize:棋盘格内角点的行数和列数。Size对象中的patternSize.width表示列数,patternSize.height表示行数。corners:输出参数,检测到的角点的坐标。它是一个包含角点坐标的Point2f类型的矢量数组。flags(可选):附加标志,用于修改函数的行为。可以是以下标志的组合:CALIB_CB_ADAPTIVE_THRESH = 1:使用自适应阈值来进行角点检测。CALIB_CB_NORMALIZE_IMAGE = 2:对输入图像进行归一化处理。CALIB_CB_FILTER_QUADS = 4:使用方形过滤器对角点进行过滤。
在 OpenCV 的findChessboardCorners函数中,flags参数可以是以下标志的组合:
CALIB_CB_ADAPTIVE_THRESH = 1:使用自适应阈值来进行角点检测。这意味着函数会根据每个像素周围的局部像素值自动调整阈值,以增强角点的检测。CALIB_CB_NORMALIZE_IMAGE = 2:对输入图像进行归一化处理。通过对图像进行归一化,函数可以在不同光照条件下提高角点检测的稳定性。CALIB_CB_FILTER_QUADS = 4:使用方形过滤器对角点进行过滤。这个标志可以用于过滤掉不符合棋盘格特征的角点,从而提高角点检测的准确性。CALIB_CB_FAST_CHECK = 8:使用快速检查策略。这个标志可以加快角点检测的速度,但会牺牲一些准确性。CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE:使用自适应阈值和归一化图像两个标志的组合。CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_FILTER_QUADS:使用自适应阈值和方形过滤器两个标志的组合。CALIB_CB_NORMALIZE_IMAGE + CALIB_CB_FILTER_QUADS:使用归一化图像和方形过滤器两个标志的组合。CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE + CALIB_CB_FILTER_QUADS:使用自适应阈值、归一化图像和方形过滤器三个标志的组合。
这些标志可以根据实际需求进行组合,以调整 findChessboardCorners 函数的行为,以获得最佳的角点检测结果。
返回值:
- 如果成功找到了棋盘格的角点,则返回
true,否则返回false。
功能:
该函数用于在给定图像中检测棋盘格的角点,并将其坐标输出到 corners 参数中。它使用角点检测算法来寻找图像中的棋盘格,并返回检测结果。
在使用该函数之前,通常需要对输入图像进行预处理,例如转换为灰度图像。然后,通过提供棋盘格的大小,该函数将尝试在图像中找到具有相应大小的棋盘格。
如果函数成功找到了棋盘格的角点,它将把这些角点的坐标存储在 corners 参数中,并返回 true。否则,如果找不到角点,它将返回 false。
在进行相机标定等任务时,一般会使用多个图像来进行角点检测,以提高检测的准确性和稳定性。
findCirclesGrid 标定板角点提取 – 圆形中心查找

findCirclesGrid 是 OpenCV 库中的一个函数,用于检测给定图像中的圆网格。它通常用于在相机标定和机器视觉应用中,以便检测圆形棋盘格或其他类型的圆形目标。
下面是该函数的详细解释:
bool findCirclesGrid(InputArray image, Size patternSize, OutputArray centers,
int flags = CALIB_CB_SYMMETRIC_GRID,
const Ptr<FeatureDetector>& blobDetector = SimpleBlobDetector::create(),
const Ptr<CirclesGridFinderParameters>& parameters = Ptr<CirclesGridFinderParameters>()
)
参数:
image:输入图像,可以是灰度图像或彩色图像。patternSize:期望的圆网格大小,即圆的行数和列数。centers:输出参数,检测到的圆心位置的二维点向量。每个元素都是一个包含检测到的一个圆心坐标的Point2f对象。flags:标志参数,用于指定网格类型和其他选项。可以是以下标志之一:CALIB_CB_SYMMETRIC_GRID:检测对称圆网格。CALIB_CB_ASYMMETRIC_GRID:检测非对称圆网格。
parameters:可选参数,用于指定圆网格检测的参数。可以为空,默认参数将被使用。blobDetector:可选参数,用于指定用于检测圆的特征检测器。可以为空,默认的简单 Blob 检测器将被使用。
返回值:- 如果成功检测到圆网格,则返回
true,否则返回false。
异常: - 如果图像无效或没有检测到足够数量的圆,则可能会引发异常。
`flags` 可以是以下三个选项之一:
1. `CALIB_CB_SYMMETRIC_GRID`:该标志指定要检测的圆网格是对称的。在对称圆网格中,每个圆周围都有相同数量的圆。例如,棋盘格就是一种对称圆网格。
2. `CALIB_CB_ASYMMETRIC_GRID`:该标志指定要检测的圆网格是非对称的。在非对称圆网格中,每个圆周围的圆的数量可以不同。例如,在一些标定模式中,中心的圆周围可能没有圆。
3. `CALIB_CB_CLUSTERING`:该标志指定使用聚类算法进行圆网格的检测。聚类算法可以在噪声较大或检测到的圆点数量较少的情况下提供更稳定的检测结果。使用该标志时,应将圆网格图像转换为灰度图像。
示例用法:
```cpp
bool patternFound = findCirclesGrid(image, patternSize, centers, CALIB_CB_SYMMETRIC_GRID);
在上述示例中,我们使用 `CALIB_CB_SYMMETRIC_GRID` 标志来指定检测对称圆网格。你可以根据你的需求选择适当的标志。
`findCirclesGrid` 函数的第六个参数是 `blobDetector`,它是一个可选参数,用于指定用于检测圆的特征检测器。`blobDetector` 是一个 `FeatureDetector` 类型的指针,用于在图像中检测圆。
OpenCV 提供了几种特征检测器,例如 `SimpleBlobDetector`,可以用于检测圆形目标。你可以使用默认的 `SimpleBlobDetector`,也可以创建自定义的特征检测器。
示例用法:
Ptr<SimpleBlobDetector> blobDetector = SimpleBlobDetector::create();
bool patternFound = findCirclesGrid(image, patternSize, centers, CALIB_CB_SYMMETRIC_GRID, nullptr, blobDetector);
在上述示例中,我们使用默认的 `SimpleBlobDetector` 创建了一个特征检测器,并将其传递给 `findCirclesGrid` 函数。你还可以根据需要创建自定义的特征检测器,并将其传递给函数。
请注意,如果你不提供 `blobDetector` 参数,`findCirclesGrid` 函数将使用默认的简单 Blob 检测器。
`findCirclesGrid` 函数的第五个参数是 `parameters`,它是一个可选参数,用于指定圆网格检测的参数。`parameters` 是一个 `CirclesGridFinderParameters` 类型的指针,用于控制检测算法的行为。
`CirclesGridFinderParameters` 类提供了以下可用参数:
1. `CirclesGridFinderParameters::densityNeighborhoodSize`:密度邻域大小。用于设置圆网格点密度的邻域大小,以决定是否在该区域内检测到圆点。默认值为 11。
2. `CirclesGridFinderParameters::minDistanceToAddKeypoint`:最小添加关键点距离。在添加关键点时,该参数指定新关键点与已添加关键点之间的最小距离。默认值为 1.0。
3. `CirclesGridFinderParameters::keypointScale`:关键点尺度。用于设置关键点的尺度,以便在不同尺度的图像中检测圆点。默认值为 1.0。
4. `CirclesGridFinderParameters::minGraphConfidence`:最小图形置信度。用于设置图形(圆网格)在计算中的最小置信度。默认值为 0.85。
5. `CirclesGridFinderParameters::doCornerRefinement`:是否进行角点细化。设置为 `true` 以启用角点细化,默认为 `false`。
6. `CirclesGridFinderParameters::cornerRefinementWinSize`:角点细化窗口大小。用于设置角点细化的窗口大小,默认为 5。
7. `CirclesGridFinderParameters::cornerRefinementMaxIterations`:角点细化的最大迭代次数。用于设置角点细化的最大迭代次数,默认为 30。
8. `CirclesGridFinderParameters::cornerRefinementMinAccuracy`:角点细化的最小准确度。用于设置角点细化的最小准确度阈值,默认为 0.1。
9. `CirclesGridFinderParameters::useDiamondDetection`:是否使用钻石检测。设置为 `true` 以启用钻石检测算法,默认为 `false`。
示例用法:
Ptr<CirclesGridFinderParameters> parameters = CirclesGridFinderParameters::create();
parameters->densityNeighborhoodSize = 15;
parameters->doCornerRefinement = true;
bool patternFound = findCirclesGrid(image, patternSize, centers, CALIB_CB_SYMMETRIC_GRID, parameters);
在上述示例中,我们创建了一个 `CirclesGridFinderParameters` 对象,并设置了 `densityNeighborhoodSize` 和 `doCornerRefinement` 参数。然后,我们将该对象传递给 `findCirclesGrid` 函数,以便使用自定义参数执行圆网格的检测。你可以根据需要设置其他参数。
find4QuadCornerSubpis 角点位置优化
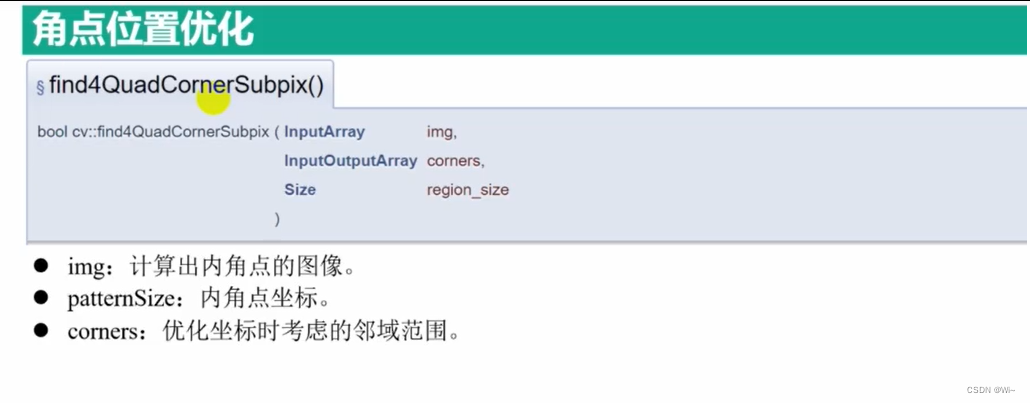
find4QuadCornerSubpix() 是 OpenCV 库中的一个函数,用于在给定的二进制图像中查找四边形的角点的亚像素级别精度。该函数的 C++ 接口定义如下:
void find4QuadCornerSubpix(InputArray img, InputOutputArray corners, Size region_size)
参数说明:
img:输入的二进制图像。必须是一个单通道(灰度)图像,数据类型为CV_8UC1。corners:输入和输出参数,包含四边形角点的像素坐标。在输入时,必须提供初始的角点估计,输出时会被更新为亚像素级别的角点坐标。这是一个CV_32FC2类型的矩阵,每一行包含一个角点的(x, y)坐标。region_size:定义亚像素搜索区域的大小。它是一个Size对象,指定搜索区域的宽度和高度。
例如,Size(5, 5)表示搜索区域的宽度和高度都是 5 个像素。亚像素搜索区域的大小决定了在搜索过程中考虑的像素范围。较大的搜索区域可以提供更准确的亚像素级别角点估计,但计算成本也会增加。通常情况下,搜索区域的大小应根据具体的应用场景进行调整。
find4QuadCornerSubpix() 函数的主要作用是对粗略估计的角点坐标进行亚像素级别的修正。通常,在使用角点检测算法(如 goodFeaturesToTrack())获取初始角点估计后,可以使用该函数来提高角点坐标的准确性。
函数的工作原理如下:
- 首先,函数将输入图像转换为浮点型图像,并计算水平和垂直方向上的梯度。
- 对于每个初始角点估计,函数在亚像素级别上进行迭代搜索,以找到更精确的角点位置。搜索区域的大小由
region_size参数定义。 - 在搜索过程中,函数使用图像梯度来估计角点位置的亚像素偏移量。这个偏移量表示从初始角点位置开始的亚像素偏移量。
- 函数迭代地应用亚像素偏移量来更新角点位置,直到达到最大迭代次数或收敛为止。
- 最终,修正后的角点坐标将存储在输出参数
corners中,可以在函数调用后访问它们。
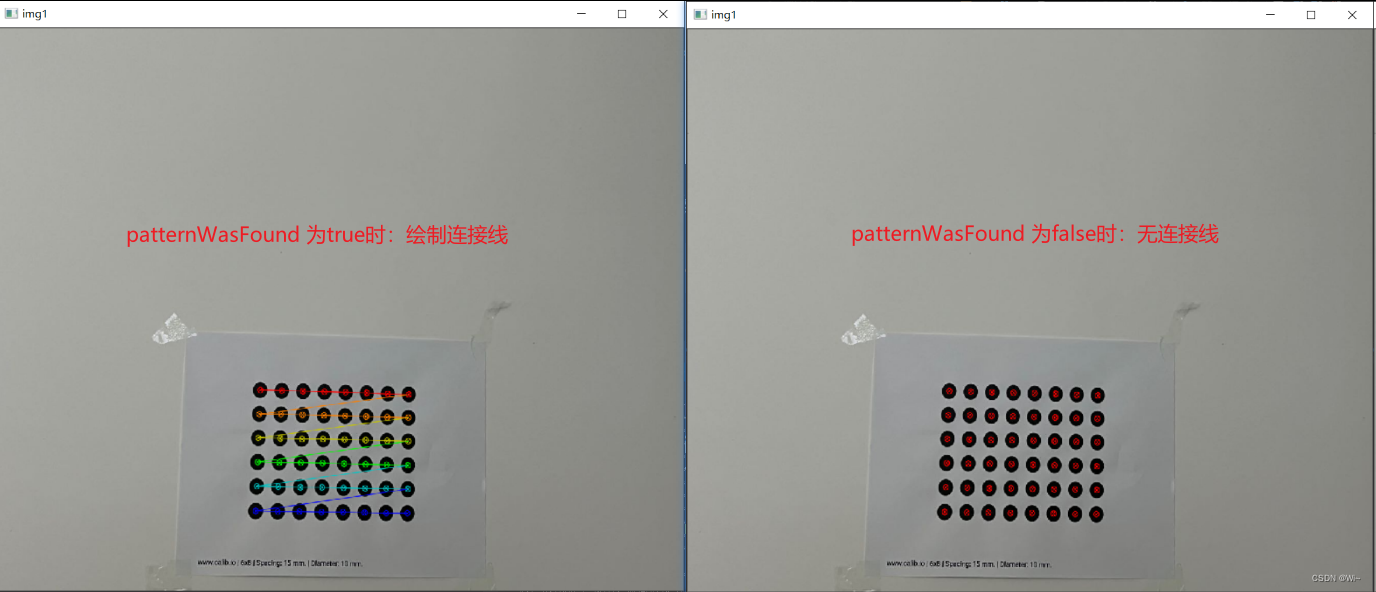
drawChessboardCorners 绘制标定板内角点
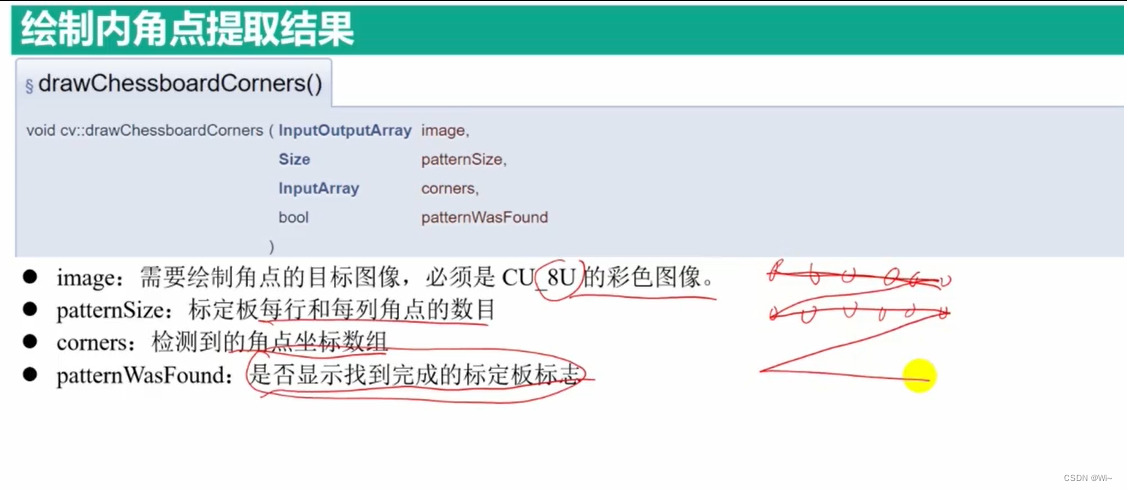
drawChessboardCorners 是 OpenCV 库中的一个函数,用于在棋盘图像上绘制角点。它的函数原型如下:
void drawChessboardCorners(InputOutputArray image, Size patternSize, InputArray corners, bool patternWasFound)
参数解释如下:
image:输入/输出图像,必须是一个8位彩色图像。patternSize:棋盘图像中每个维度的内部角点数(例如,如果棋盘为7x6,则patternSize应设置为Size(7, 6))。corners:输入的角点数组,通常是通过findChessboardCorners函数检测得到的结果。它是一个Point2f类型的向量,其中包含检测到的角点坐标。patternWasFound:设置为true时:绘制连接线,否则,设置为false:无连接线。
calibrateCamera 相机标定函数
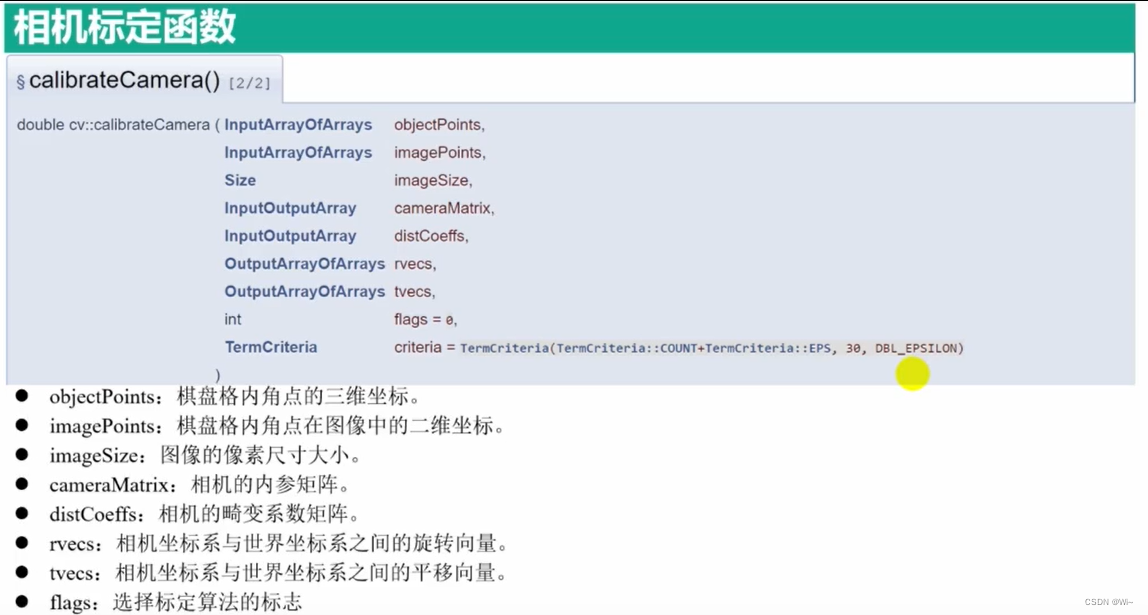
calibrateCamera 是 OpenCV 中用于相机标定的函数。相机标定是确定相机的内部参数和外部参数的过程,以便在图像中进行准确的测量和分析。
函数原型如下:
double cv::calibrateCamera(
InputArrayOfArrays objectPoints, // 世界坐标系中的三维点
InputArrayOfArrays imagePoints, // 图像中的二维点
Size imageSize, // 图像尺寸
InputOutputArray cameraMatrix, // 输出的相机内部参数矩阵
InputOutputArray distCoeffs, // 输出的畸变系数
OutputArrayOfArrays rvecs, // 输出的旋转矢量
OutputArrayOfArrays tvecs, // 输出的平移矢量
int flags = 0, // 可选标志
TermCriteria criteria = TermCriteria(TermCriteria::COUNT + TermCriteria::EPS, 30, DBL_EPSILON) // 迭代终止条件
)
//double calibrateCamera(const vector<vector<Point3f>>& objectPoints,// 世界坐标系中的三维点
// const vector<vector<Point2f>>& imagePoints, // 图像中的二维点
// const Size& imageSize, // 图像尺寸
// Mat& cameraMatrix, // 输出的相机内部参数矩阵
// Mat& distCoeffs, // 输出的畸变系数
// vector<Mat>& rvecs, // 输出的旋转矢量
// vector<Mat>& tvecs, // 输出的平移矢量
// int flags = 0, // 可选标志
// TermCriteria criteria = TermCriteria(TermCriteria::COUNT + TermCriteria::EPS, 30, DBL_EPSILON) // 迭代终止条件
// );
参数:
objectPoints:物体空间中的三维点坐标。它是一个vector<vector<Point3f>>类型的参数,其中每个元素是一个包含多个Point3f类型点的向量。每个Point3f表示物体坐标系中的一个点。imagePoints:图像平面中对应于objectPoints的二维点坐标。它是一个vector<vector<Point2f>>类型的参数,其中每个元素是一个包含多个Point2f类型点的向量。每个Point2f表示图像平面上的一个点。imageSize:输入图像的尺寸(宽度和高度),可以使用Size类型传递。cameraMatrix:相机的内部参数矩阵。它是一个Mat类型的输出参数,包含相机的内部参数,如焦距、图像原点等。distCoeffs:相机的畸变系数。它是一个Mat类型的输出参数,包含径向和切向畸变系数。rvecs:输出参数,包含每个图像的旋转向量。它是一个vector<Mat>类型的参数,每个元素是一个旋转向量。tvecs:输出参数,包含每个图像的平移向量。它是一个vector<Mat>类型的参数,每个元素是一个平移向量。flags:标定的附加选项。可以使用以下常量进行设置:CALIB_USE_INTRINSIC_GUESS:使用输入的cameraMatrix作为内部参数的初始猜测。CALIB_FIX_PRINCIPAL_POINT:固定图像原点的位置。CALIB_FIX_ASPECT_RATIO:固定焦距的纵横比。CALIB_ZERO_TANGENT_DIST:将切向畸变系数设为零。CALIB_FIX_K1,CALIB_FIX_K2,CALIB_FIX_K3,CALIB_FIX_K4,CALIB_FIX_K5,CALIB_FIX_K6:固定径向畸变系数。CALIB_RATIONAL_MODEL:使用理性径向畸变模型。CALIB_THIN_PRISM_MODEL:使用薄透镜模型进行标定。CALIB_FIX_S1_S2_S3_S4:固定薄透镜模型的参数。CALIB_FIX_INTRINSIC:固定相机的内部参数。CALIB_FIX_FOCAL_LENGTH:固定焦距。
CALIB_NINTRINSIC = 18,
CALIB_USE_INTRINSIC_GUESS = 0x00001,
CALIB_FIX_ASPECT_RATIO = 0x00002,
CALIB_FIX_PRINCIPAL_POINT = 0x00004,
CALIB_ZERO_TANGENT_DIST = 0x00008,
CALIB_FIX_FOCAL_LENGTH = 0x00010,
CALIB_FIX_K1 = 0x00020,
CALIB_FIX_K2 = 0x00040,
CALIB_FIX_K3 = 0x00080,
CALIB_FIX_K4 = 0x00800,
CALIB_FIX_K5 = 0x01000,
CALIB_FIX_K6 = 0x02000,
CALIB_RATIONAL_MODEL = 0x04000,
CALIB_THIN_PRISM_MODEL = 0x08000,
CALIB_FIX_S1_S2_S3_S4 = 0x10000,
CALIB_TILTED_MODEL = 0x40000,
CALIB_FIX_TAUX_TAUY = 0x80000,
CALIB_USE_QR = 0x100000, //!< use QR instead of SVD decomposition for solving. Faster but potentially less precise
CALIB_FIX_TANGENT_DIST = 0x200000,
// only for stereo
CALIB_FIX_INTRINSIC = 0x00100,
CALIB_SAME_FOCAL_LENGTH = 0x00200,
// for stereo rectification
CALIB_ZERO_DISPARITY = 0x00400,
CALIB_USE_LU = (1 << 17), //!< use LU instead of SVD decomposition for solving. much faster but potentially less precise
CALIB_USE_EXTRINSIC_GUESS = (1 << 22) //!< for stereoCalibrate
当将 `flags` 参数设置为 0 时,表示没有额外的标志被应用,即标定过程将使用默认设置进行。这意味着相机的内部参数和畸变系数将在优化过程中被调整,以获得最佳的标定结果。默认情况下,所有的内部参数和畸变系数都是可调的,以便在标定过程中进行优化。
使用标志为 0 的默认设置时,`calibrateCamera` 函数将尝试估计相机的内部参数矩阵、畸变系数以及每个图像的旋转向量和平移向量。这将通过最小化重投影误差来完成,以使投影点与实际图像点之间的差异最小化。
当您不需要应用任何特定的约束或限制时,将 `flags` 参数设置为 0 是常见的做法。这样可以利用完整的标定过程,并得到相机的准确内部参数和畸变系数的估计结果。
criteria:迭代过程的终止准则。可以使用TermCriteria类型传递,其中包括迭代次数和收敛条件。- 返回值:该函数返回一个双精度值,表示标定的重投影误差。
在使用 calibrateCamera 函数进行相机标定时,需要提供一组已知的物体点坐标和对应的图像点坐标。这些点可以通过使用棋盘格等已知形状的物体进行测量获得。通过对多个图像的点进行标定,函数将估计出相机的内部参数矩阵、畸变系数以及每个图像的旋转向量和平移向量。
相机标定的过程是通过最小化重投影误差来优化相机参数。重投影误差是指将三维点重新投影到图像平面上得到的投影点与实际图像点之间的距离。
使用 calibrateCamera 函数后,相机的内部参数和畸变系数将被存储在 cameraMatrix 和 distCoeffs 中,而每个图像的旋转向量和平移向量将存储在 rvecs 和 tvecs 中。
注意:在进行相机标定之前,需要确保提供的物体点和图像点之间有足够的对应关系,并且这些点的顺序是一致的。
calibrateCamera 函数的工作流程如下:
- 收集用于标定的图像和对应的物体点坐标。
- 定义一个
vector<vector<Point3f>>类型的变量objectPoints,其中每个元素是一个Point3f类型的物体点向量。这些物体点是已知的,通常通过测量实际物体或使用已知形状的标定板(如棋盘格)来获得。 - 定义一个
vector<vector<Point2f>>类型的变量imagePoints,其中每个元素是一个Point2f类型的图像点向量。这些图像点是通过在每个图像中检测到的特征点(例如棋盘格角点)获得的。 - 初始化相机内部参数矩阵
cameraMatrix和畸变系数矩阵distCoeffs。 - 调用
calibrateCamera函数,并将objectPoints、imagePoints、图像尺寸imageSize、cameraMatrix、distCoeffs、rvecs和tvecs作为参数传递。 - 函数执行标定过程,估计相机的内部参数和畸变系数,并计算每个图像的旋转向量和平移向量。
- 返回标定的重投影误差。
- 在函数执行完成后,
cameraMatrix和distCoeffs中将包含相机的内部参数和畸变系数,rvecs和tvecs中将包含每个图像的旋转向量和平移向量。
相机标定是一个复杂的过程,它需要足够的数据和准确的标定板图像。通过准确标定相机,可以在图像中进行准确的测量和计算,例如计算物体的实际尺寸或进行三维重建等应用。
在调用 calibrateCamera 函数后,您可以使用返回的结果来进行进一步的相机校正和图像处理。下面是一些可能的后续步骤:
- 重投影误差分析:通过计算标定的重投影误差,您可以评估标定的质量。重投影误差是将标定的物体点重新投影到图像上并计算与实际图像点之间的差异。较低的重投影误差表示标定的准确性较高。
- 相机矫正:使用得到的相机内部参数矩阵
cameraMatrix和畸变系数矩阵distCoeffs,您可以对其他图像进行矫正。通过应用畸变校正,可以去除图像中的畸变,使物体的形状更接近实际情况。 - 三维重建:使用标定的相机参数,您可以将图像中的二维点转换为物体坐标系中的三维点。通过匹配多个图像的点,可以进行三维重建和点云生成,从而实现三维测量和场景重建。
- 相机姿态估计:使用得到的旋转向量
rvecs和平移向量tvecs,您可以估计相机在不同图像中的姿态(位置和方向)。这对于基于视觉的导航、姿态估计和增强现实等应用非常有用。 - 视频校正:如果您有一个视频流,您可以对每个帧应用相机校正,以实现实时的畸变校正和图像处理。
这些是使用 calibrateCamera 函数进行相机标定后的一些典型的后续步骤。具体的应用取决于您的需求和所处理的图像数据。根据具体情况,您可能需要进一步了解和使用 OpenCV 中的其他函数和技术来完成特定的任务。
// 定义标定参数
int calibration_flags =
cv::CALIB_FIX_ASPECT_RATIO |
cv::CALIB_FIX_PRINCIPAL_POINT |
cv::CALIB_ZERO_TANGENT_DIST |
cv::CALIB_FIX_FOCAL_LENGTH;
// 进行相机标定
cv::Mat camera_matrix, distortion_coeffs;
std::vector<cv::Mat> rvecs, tvecs;
double ret = cv::calibrateCamera(
object_points, image_points, image.size(), camera_matrix, distortion_coeffs,
rvecs, tvecs, calibration_flags
);
projectPoints 模型投影 – 根据世界坐标 根据 内参和畸变系数 投影到图像坐标
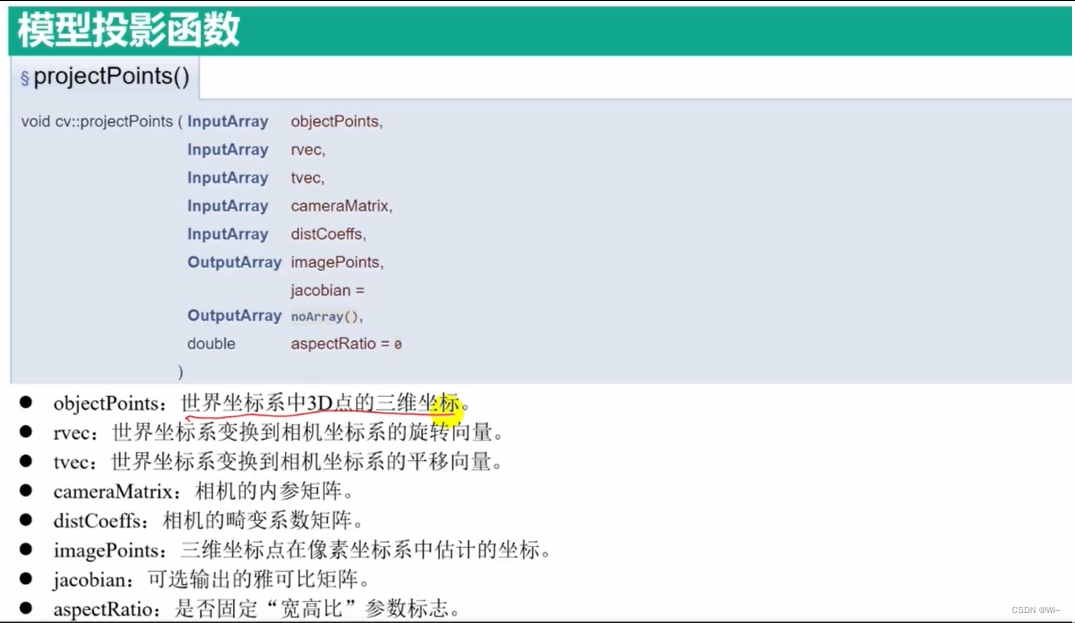
projectPoints 是 OpenCV 中的一个函数,用于将三维点投影到二维平面上。它主要用于计算相机投影模型中的点的位置。
以下是 projectPoints 函数的详细解释和示例:
void cv::projectPoints(
InputArray objectPoints, // 输入的三维点坐标,类型为CV_32FC3或CV_64FC3
InputArray rvec, // 旋转向量(旋转矩阵的罗德里格斯表示),类型为CV_32F或CV_64F,大小为3x1
InputArray tvec, // 平移向量,类型为CV_32F或CV_64F,大小为3x1
InputArray cameraMatrix, // 相机内参数矩阵,类型为CV_32F或CV_64F,大小为3x3
InputArray distCoeffs, // 畸变系数,类型为CV_32F或CV_64F,大小为4x1或5x1
OutputArray imagePoints, // 输出的二维点坐标,类型为CV_32FC2或CV_64FC2
OutputArray jacobian = noArray(), // 可选参数,输出的Jacobi矩阵
double aspectRatio = 0 // 可选参数,焦距的y和x方向的比例因子
)
objectPoints是一个输入参数,表示三维空间中的点坐标。它的类型可以是CV_32FC3或CV_64FC3,即每个点有3个浮点数或双精度浮点数分量。rvec是旋转向量,表示相机坐标系到目标坐标系的旋转变换。它的类型可以是CV_32F或CV_64F,大小为 3x1。tvec是平移向量,表示相机坐标系到目标坐标系的平移变换。它的类型可以是CV_32F或CV_64F,大小为 3x1。cameraMatrix是相机内参数矩阵,表示相机的内部参数,例如焦距和主点。它的类型可以是CV_32F或CV_64F,大小为 3x3。distCoeffs是畸变系数,用于校正图像中的畸变。它的类型可以是CV_32F或CV_64F,大小为 4x1 或 5x1。imagePoints是输出参数,表示投影到二维图像平面上的点坐标。它的类型可以是CV_32FC2或CV_64FC2,即每个点有2个浮点数或双精度浮点数分量。jacobian是可选的输出参数,表示 Jacobi 矩阵,用于计算反向求导数。aspectRatio是一个可选参数,用于调整焦距的 y 和 x 方向的比例因子。默认值为 0,表示不考虑比例因子。
projectPoints 函数的作用是将三维点坐标从世界坐标系投影到相机图像平面上的二维点坐标。它使用相机的内参数矩阵、畸变系数、旋转向量和平移向量来执行投影计算。
undistort 去畸变函数

OpenCV库提供了undistort函数用于对图像进行去畸变操作。这个函数的目的是根据相机的内部参数和畸变系数,将畸变图像转换为无畸变的图像。
以下是undistort函数的C++接口:
void cv::undistort(
InputArray src, // 输入图像
OutputArray dst, // 输出图像
InputArray cameraMatrix, // 相机内部参数矩阵
InputArray distCoeffs, // 畸变系数
InputArray newCameraMatrix = noArray() // 新的相机内部参数矩阵
)
接下来是这些参数的详细说明:
-
src:输入图像,可以是单通道或多通道的图像。 -
dst:输出图像,与输入图像具有相同的尺寸和类型。 -
cameraMatrix:相机的内部参数矩阵,通常由相机标定得到。它是一个3x3的浮点型矩阵。 -
distCoeffs:畸变系数,通常也是通过相机标定得到的。它是一个1xN或Nx1的浮点型向量,N表示畸变系数的数量。 -
newCameraMatrix(可选):新的相机内部参数矩阵。如果提供了新的相机内部参数矩阵,那么函数将使用它来重新投影图像,从而得到新的视角。如果没有提供新的相机内部参数矩阵,函数将使用默认的参数,保持图像的原始视角。
函数根据相机内部参数和畸变系数,将输入图像中的像素位置转换为无畸变的像素位置,并将结果存储在输出图像中。
请注意,undistort函数只能去除镜头的径向畸变,而不能去除切向畸变。如果图像存在切向畸变,需要先进行相机标定,然后使用其他函数(如initUndistortRectifyMap和remap)来进行更复杂的畸变矫正操作。
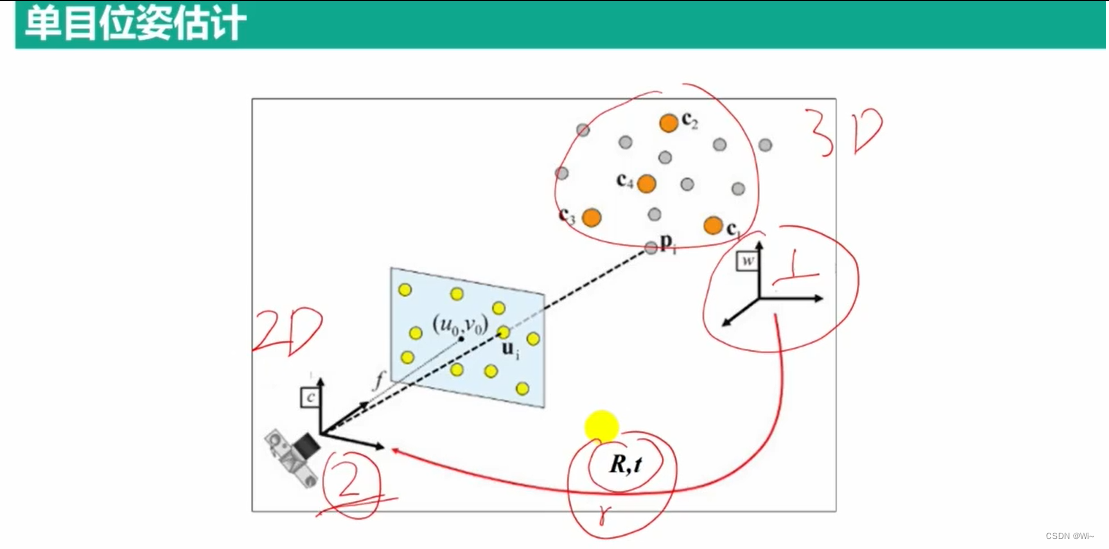
solvePnP 位姿估计函数 – 估计 旋转向量和平移向量
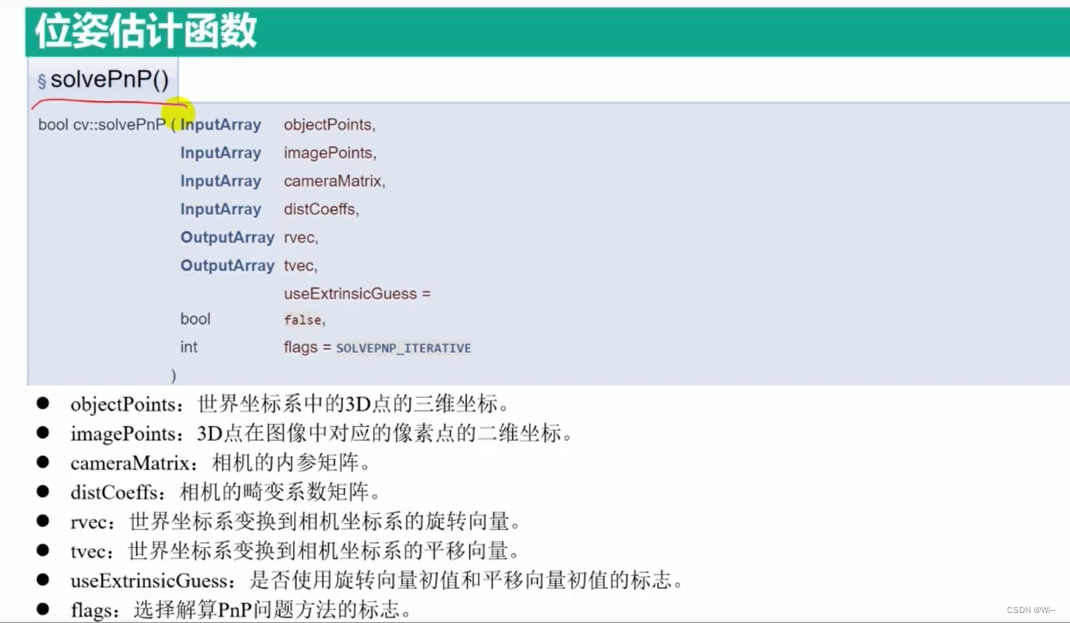
solvePnP是OpenCV中的一个函数,用于求解相机的位姿问题。它可以根据已知的3D点和对应的2D图像点,计算出相机的旋转和平移向量,从而确定相机在世界坐标系中的位置和朝向。
下面是solvePnP函数的详细说明:
bool solvePnP(InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix,
InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess = false,
int flags = SOLVEPNP_ITERATIVE);
参数说明:
objectPoints:3D点的坐标,可以是一个单独的Mat对象,也可以是一个std::vector<Point3f>。imagePoints:对应的2D图像点的坐标,可以是一个单独的Mat对象,也可以是一个std::vector<Point2f>。cameraMatrix:相机的内参矩阵,3x3的浮点型矩阵。distCoeffs:相机的畸变系数,可以是一个单独的Mat对象,也可以是一个std::vector<double>。 畸变系数的输入向量(k1,k2,p1,p2[,k3[,k4,k5,k6[,s1,s2,s3,s4[,τx,τy]]]])4、5、8、12 或 14 个元素.如果向量为空,则假定畸变系数为零。rvec:输出的旋转向量,3x1的浮点型矩阵。tvec:输出的平移向量,3x1的浮点型矩阵。useExtrinsicGuess:是否使用外部估计的旋转和平移向量作为初始值,默认为false。flags:求解PnP问题的方法,可以是SOLVEPNP_ITERATIVE或SOLVEPNP_EPNP,默认为SOLVEPNP_ITERATIVE。- 函数返回值为bool类型,表示求解是否成功。
solvePnP函数的工作原理是通过将3D点的坐标和对应的2D图像点的坐标映射到归一化相机坐标系(齐次坐标),然后使用迭代或EPnP等方法计算相机的旋转向量和平移向量。这些向量可以进一步转换为旋转矩阵和相机中心的世界坐标。
注意事项:
objectPoints和imagePoints的数量必须相同,并且至少需要4对匹配点。cameraMatrix和distCoeffs参数必须与实际使用的相机参数相匹配,否则计算结果可能不准确。flags参数的选择取决于具体的需求和场景,一般情况下SOLVEPNP_ITERATIVE(默认值)已经可以满足大多数需求。
当使用OpenCV中的solvePnP函数时,flags参数用于指定求解PnP问题的方法和选项。下面是这些标志参数的详细概述:
SOLVEPNP_ITERATIVE:使用迭代方法求解PnP问题。这是默认选项,适用于大多数情况。它在计算精度和计算效率之间取得了平衡。SOLVEPNP_EPNP:使用EPnP方法求解PnP问题。EPnP是一种非迭代方法,通过使用额外的摄像机内参矩阵信息来提高计算效率。它在相机姿态恢复方面表现出色,并且通常比迭代方法更快。SOLVEPNP_P3P:使用P3P方法求解PnP问题。P3P是一种基于四个点的算法,需要至少四个点的匹配对。它在计算精度和计算速度上都非常高效,但对于点对的数量有限制。SOLVEPNP_DLS:使用DLS(Damped Least Squares)方法求解PnP问题。DLS是一种数值稳定的方法,通过引入阻尼项来处理问题的奇异情况。它在存在测量误差或多个解的情况下表现良好。SOLVEPNP_UPNP:使用UPnP方法求解PnP问题。UPnP是一种基于非线性优化的方法,能够处理较大的视角变化和较多的点对。它在计算精度和计算效率上都有很好的表现。SOLVEPNP_AP3P:使用AP3P(Absolute Pose Problem with Planar Targets)方法求解PnP问题。AP3P是一种改进的P3P算法,特别适用于平面目标的位姿估计问题。SOLVEPNP_IPPE:使用IPPE(Inverse Perspective-n-Point)方法求解PnP问题。IPPE是一种基于迭代的方法,通过反投影误差最小化来估计相机位姿。它适用于近景应用和相机视场较小的情况。SOLVEPNP_IPPE_SQUARE:使用IPPE方法并假设目标为正方形形状的情况下求解PnP问题。该选项适用于正方形目标的位姿估计,提供了更高的计算精度。SOLVEPNP_SQPNP:使用SQPnP(Sequential Quadratic Programming for PnP)方法求解PnP问题。SQPnP是一种数值优化方法,通过迭代求解非线性最小化问题来估计相机的位姿。它能够处理复杂的场景和大量的点对,并且对于噪声和误匹配有一定的鲁棒性。然而,它通常比其他方法更耗时,因为需要进行迭代优化。SOLVEPNP_MAX_COUNT:使用最大计数方法求解PnP问题。该方法将迭代次数限制为指定的最大计数值,可以用于控制计算时间。
这些标志参数可以根据具体的需求和场景进行选择。通常情况下,SOLVEPNP_ITERATIVE是一个合理的默认选择,它在大多数情况下都能提供良好的计算精度和效率。其他方法如EPnP、P3P、DLS、UPnP、AP3P、IPPE等则针对特定的问题具有更好的性能或适用性。
代码演示:
int main()
{
//读取所有图像
vector<Mat> imgs;
string imgName;
ifstream fin("calibdata1.txt");
while (getline(fin, imgName))
{
Mat img = imread(imgName);
if (img.empty())
{
cout << "图像打开失败。。。" << endl;
return -1;
}
imgs.push_back(img);
}
//定义角点大小和图像上的角点一致
Size boardSize = Size(8, 6);
vector<vector<Point2f>> imgsPoints;
//获取n张图像像素角点
for (int i = 0; i < imgs.size(); ++i)
{
Mat img1 = imgs[i];
Mat gray1;
cvtColor(img1, gray1, COLOR_BGR2GRAY);
vector<Point2f> img1Points;
//计算棋盘格角点
bool patternFound = findChessboardCorners(gray1, boardSize, img1Points);
//计算圆心
//bool patternFound = findCirclesGrid(gray1, boardSize, img1Points);
cout << patternFound << endl;
//优化角点,精确到亚像素
find4QuadCornerSubpix(gray1, img1Points, Size(5, 5));
//绘制角点
bool isOK = true;
drawChessboardCorners(img1, boardSize, img1Points, isOK);
cout << "isOK:"<< isOK << endl;
namedWindow("img1", WINDOW_NORMAL);
imshow("img1", img1);
waitKey(0);
imgsPoints.push_back(img1Points);
}
//生成棋盘格每个内角点三维坐标
Size squareSize = Size(15, 15);
vector<vector<Point3f>> objectPoints;
vector<Point3f> tempPoints;
for (int j = 0; j < boardSize.height; ++j)
{
for (int k = 0; k < boardSize.width; ++k)
{
Point3f realPoint;
//假设标定板为世界坐标系的z平面,即z=0
realPoint.x = k * squareSize.width;
realPoint.y = j * squareSize.height;
realPoint.z = 0;
tempPoints.push_back(realPoint);
}
}
for (int i = 0; i < imgsPoints.size(); ++i)
{
objectPoints.push_back(tempPoints);
}
//图像尺寸
Size imageSize(imgs[0].cols,imgs[0].rows);
//相机内参 , 畸变系数
Mat cameraMatrix , distCoeffs;
//每张图形的旋转向量
vector<Mat> rvecs;
//每张图像的平移向量
vector<Mat> tvecs;
double reprojError = calibrateCamera(objectPoints, imgsPoints, imageSize, cameraMatrix, distCoeffs, rvecs, tvecs, 0);
cout << "重投影误差:" << reprojError << endl;
cout << "相机内参矩阵:" << endl << cameraMatrix << endl;
cout << "相机畸变系数:" << endl << distCoeffs << endl;
cout << "旋转向量:" << endl;
for (int i = 0; i < rvecs.size(); ++i)
{
cout << rvecs[i] << endl;
}
cout << "平移向量:" << endl;
for (int i = 0; i < tvecs.size(); ++i)
{
cout << tvecs[i] << endl;
}
vector<Point2f> imgPoints;
Mat Jac;
//模型投影 -- 根据世界坐标 根据 内参和畸变系数 投影到图像坐标
projectPoints(tempPoints, rvecs[0], tvecs[0], cameraMatrix, distCoeffs, imgPoints, Jac);
//cout << "雅可比矩阵:" << endl << Jac << endl;
//根据内参和畸变系数对图像去畸变
for (int i = 0; i < imgs.size(); ++i)
{
Mat srcImg = imgs[i];
Mat dstImg;
undistort(srcImg, dstImg, cameraMatrix, distCoeffs);
//显示每一个图像
string srcS = "srcImg" + to_string(i);
string dstS = "dstImg" + to_string(i);
namedWindow(srcS, WINDOW_NORMAL);
namedWindow(dstS, WINDOW_NORMAL);
imshow(srcS, srcImg);
imshow(dstS, dstImg);
}
//求世界坐标和当前图像坐标的相机的位姿
//旋转向量
Mat rvecs1;
//平移向量
Mat tvecs1;
solvePnP(objectPoints[0], imgsPoints[0], cameraMatrix, distCoeffs, rvecs1, tvecs1);
//solvePnP(objectPoints[0], imgsPoints[0], cameraMatrix, distCoeffs, rvecs[0], tvecs[0], true);
cout << "单个旋转向量:" << rvecs1<<endl;
cout << "单个平移向量:" << tvecs1 << endl;
waitKey(0);
return 0;
}
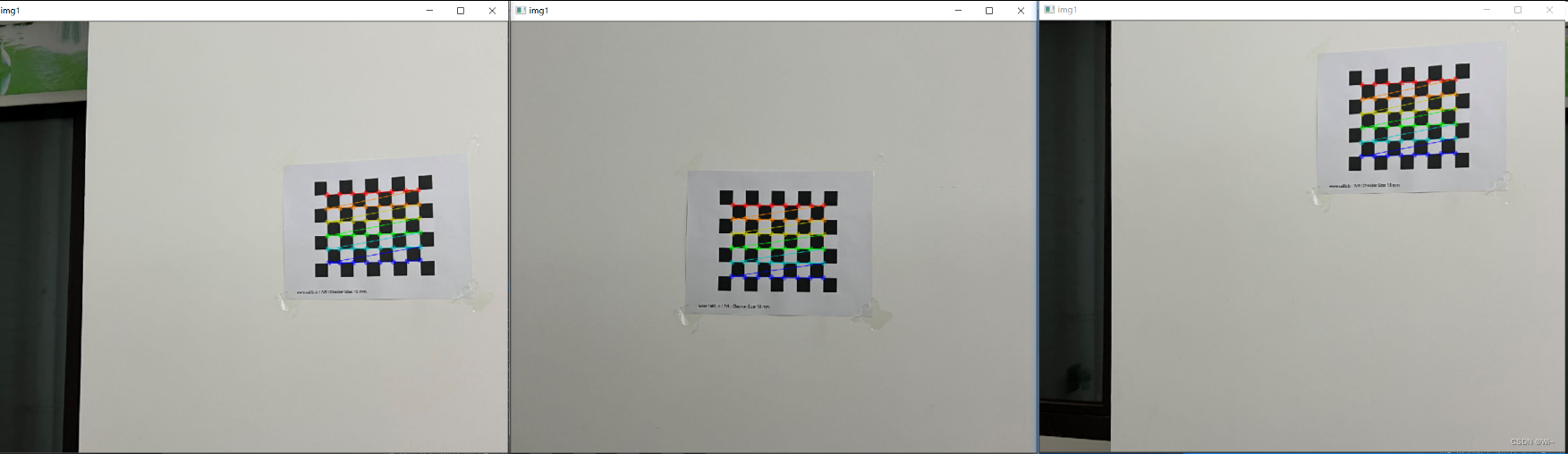

重投影误差:0.446279
相机内参矩阵:
[1380.047335439607, 0, 585.4103520906031;
0, 1379.989355210238, 475.9677047375;
0, 0, 1]
相机畸变系数:
[0.2036744384549596, -0.508938131816573, -0.01576823311387853, -0.02936405545649798, 0.4166020102554809]
旋转向量:
[-0.09129932211443254;
0.2662418807908897;
-0.01557101796559691]
平移向量:
[137.7743795996079;
-34.53398471523743;
652.9504462173998]
单个旋转向量:[-0.09127154819176657;
0.266243519517998;
-0.01557500307480123]
单个平移向量:[137.7742898976761;
-34.53403038353336;
652.9500732855978]
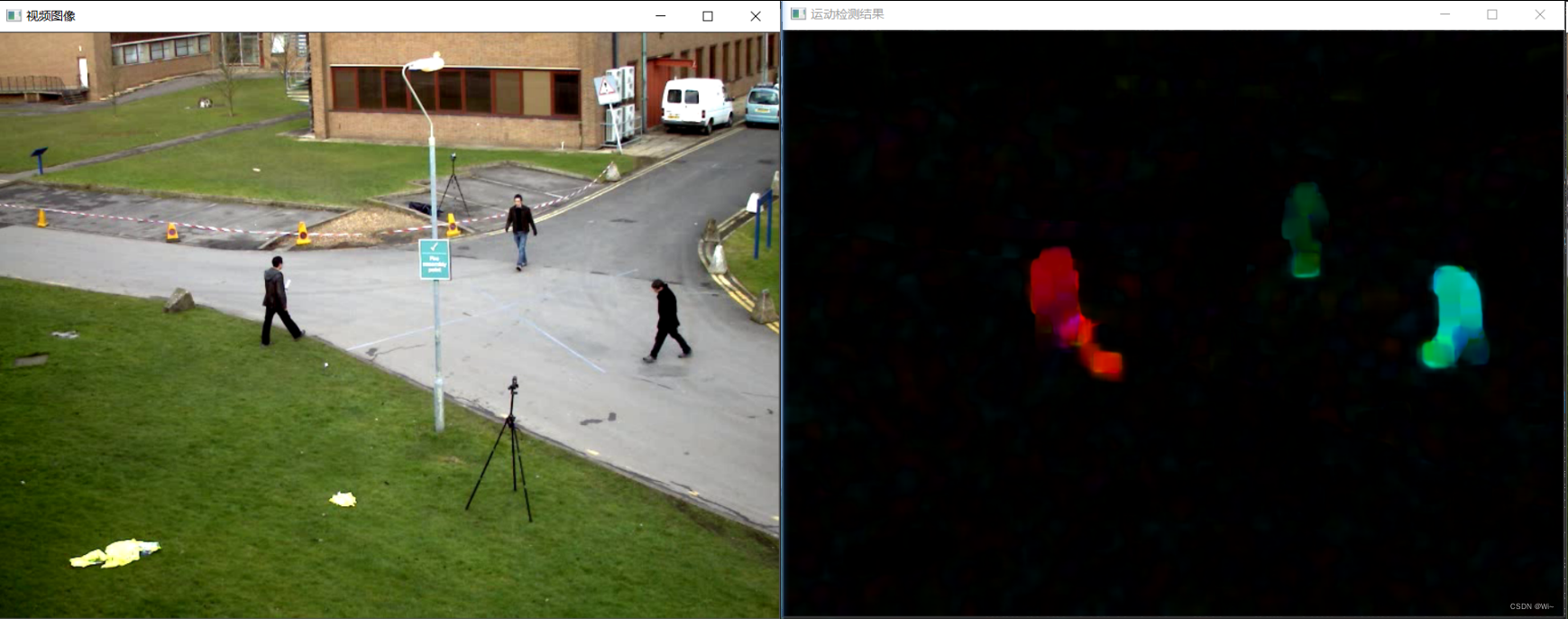
移动物体检测
光流法介绍
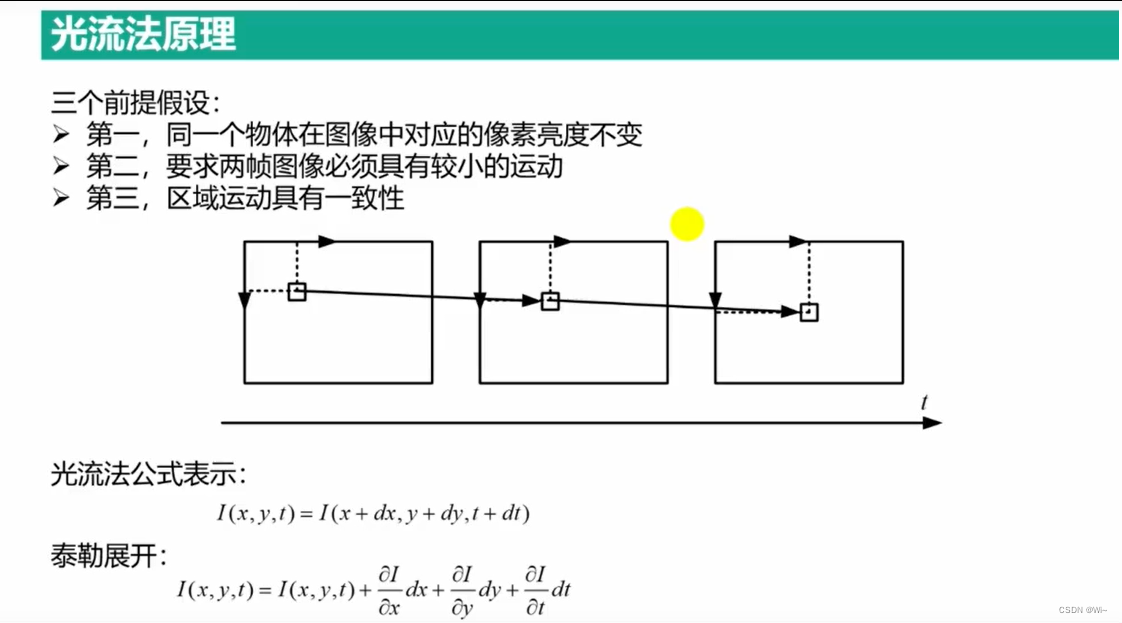


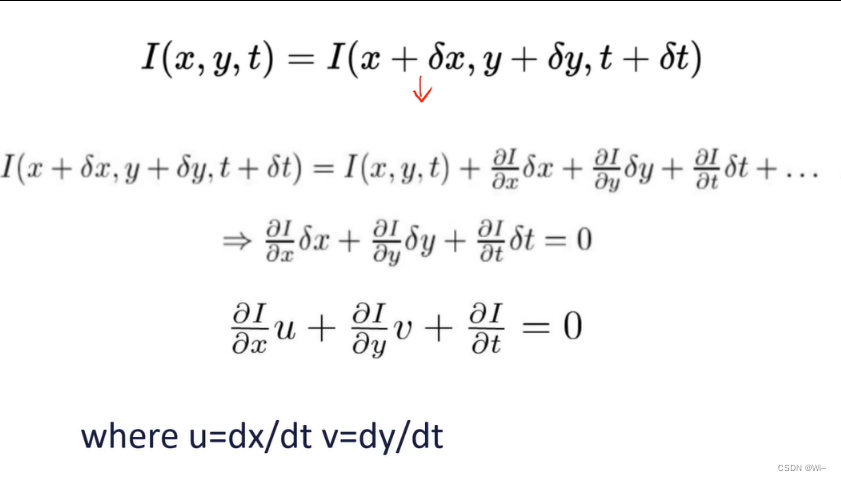
差值法
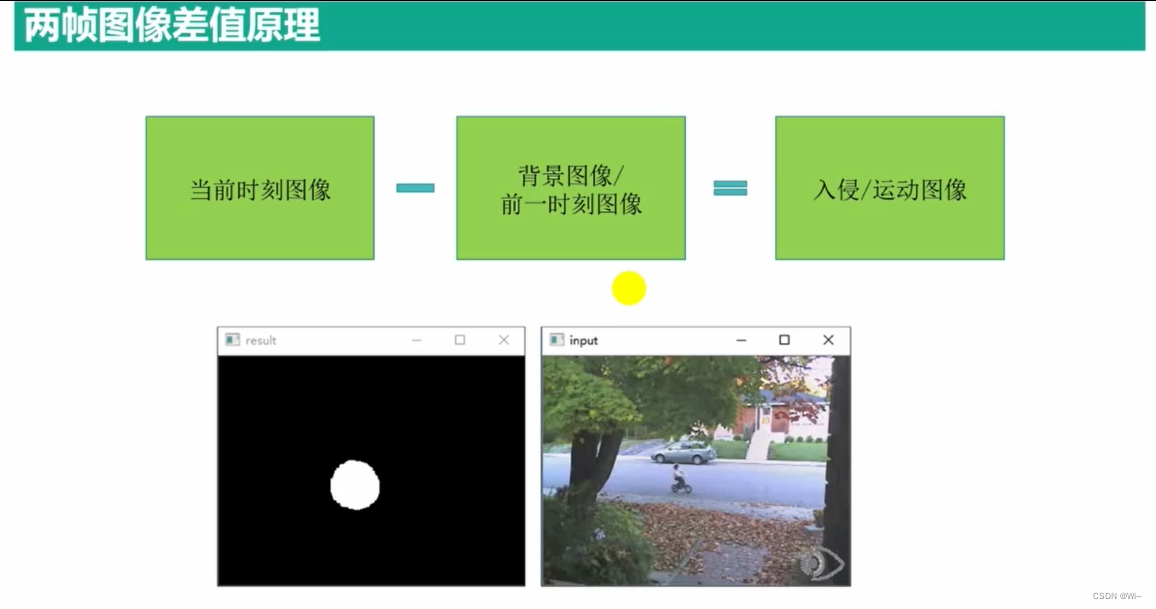
差值法(Differencing Method)是一种常用的图像移动检测方法,它通过计算当前帧与前一帧之间的差异来检测图像中的运动。下面是差值法检测图像移动的一般流程:
- 读取视频帧或图像序列:首先,你需要读取视频文件或图像序列作为输入数据。可以使用OpenCV库中的函数进行视频的读取,例如
cv::VideoCapture。 - 转换为灰度图像:对于每一帧图像,通常将其转换为灰度图像。可以使用
cv::cvtColor函数将彩色图像转换为灰度图像。 - 差值计算:将当前帧与前一帧进行差值计算。可以使用
cv::absdiff函数来计算两个灰度图像之间的差异图像。 - 阈值化:对差异图像应用阈值操作,将图像中的运动区域与静止区域分离开。可以使用
cv::threshold函数来进行阈值化操作。 - 运动区域提取:对于阈值化后的图像,可以通过形态学操作(如膨胀、腐蚀)来进一步提取运动区域的连通分量。可以使用
cv::dilate进行膨胀操作,cv::erode进行腐蚀操作。 - 绘制边界框或标记运动区域:根据需求,你可以在原始图像上绘制边界框或标记运动区域,以可视化显示检测到的移动。可以使用OpenCV的绘制函数(如
cv::rectangle)来实现。 - 循环处理:对于视频序列,重复执行以上步骤,直到处理完所有的帧。
absdiff 差值绝对值函数

absdiff 是 OpenCV 库中的一个函数,用于计算两个图像的差异。它将两个输入图像的对应像素值相减,并返回一个新的图像,该图像的每个像素值表示对应位置上两个输入图像像素值的差的绝对值。
以下是 absdiff 函数的详细说明:
void absdiff(InputArray src1, InputArray src2, OutputArray dst);
参数说明:
-
src1:第一个输入图像,可以是单通道或多通道图像,数据类型可以是CV_8U、CV_16U、CV_16S、CV_32F或CV_64F。 -
src2:第二个输入图像,与src1的尺寸和通道数必须相同。 -
dst:输出图像,与输入图像的尺寸和通道数相同,数据类型为CV_8U。
注意事项: -
输入图像的尺寸和通道数必须相同,否则会引发错误。
-
输出图像的数据类型为
CV_8U,即无符号8位整数,这是为了确保输出图像的像素值能够表示差异的绝对值。
下面是一个简单的示例代码,演示了使用差值法检测图像移动的基本流程:
int main()
{
VideoCapture capture("vtest.avi");
Mat prevFrame, prevGray;
if (!capture.read(prevFrame))
{
cout << "请确认视频文件名称是否正确" << endl;
return -1;
}
int fps = capture.get(CAP_PROP_FPS);
int width = capture.get(CAP_PROP_FRAME_WIDTH);
int height = capture.get(CAP_PROP_FRAME_HEIGHT);
int num_of_frames = capture.get(CAP_PROP_FRAME_COUNT);
cout << "fps:" << fps << endl;
cout << "视频宽度:" << width << endl;
cout << "视频高度:" << height << endl;
cout << "视频总帧数:" << num_of_frames << endl;
capture.read(prevFrame);
cvtColor(prevFrame, prevGray, COLOR_BGR2GRAY);
GaussianBlur(prevGray, prevGray, Size(0, 0), 15);
Mat binary;
Mat frame, gray;
//形态学操作的矩形模板
Mat k = getStructuringElement(MORPH_RECT, Size(7, 7));
while (capture.read(frame)) //读取完结束
{
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
GaussianBlur(gray, gray, Size(0, 0), 15);
//计算当前帧与前一帧的差值的绝对值
cv::absdiff(prevGray, gray, binary);
//二值化 -- 使用大津法自动阈值
double th = cv::threshold(binary, binary, 0, 255, cv::THRESH_BINARY | THRESH_OTSU);
cout << "th:" << th << endl;
//并进行开运算 - 消除小的噪点
morphologyEx(binary, binary, MORPH_OPEN, k);
cv::imshow("input", frame);
cv::imshow("result", binary);
cv::waitKey(0);
prevFrame = gray;
}
waitKey(0);
return 0;
}
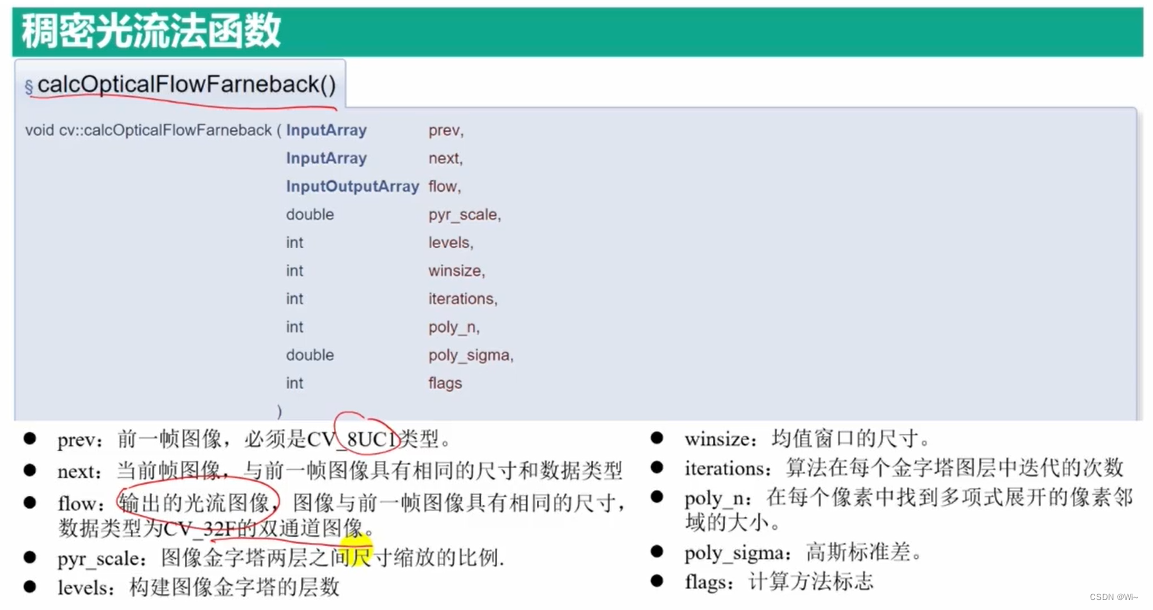
calcOpticalFlowFarneback 稠密光流法函数
calcOpticalFlowFarneback是OpenCV库中的一个函数,用于计算光流。光流是描述图像中物体运动的模式,通过分析相邻帧之间的像素强度变化来估计物体的运动。
以下是calcOpticalFlowFarneback函数的详细解释:
void calcOpticalFlowFarneback(InputArray prev,
InputArray next,
InputOutputArray flow,
double pyr_scale,
int levels,
int winsize,
int iterations,
int poly_n,
double poly_sigma,
int flags);
参数说明:
prev:输入的前一帧图像(单通道灰度图像)。next:输入的后一帧图像(与前一帧相对应的图像,同样是单通道灰度图像)。flow:计算得到的光流(两个通道的浮点型向量图像)。pyr_scale:图像金字塔的缩放因子,用于构建图像金字塔。通常设为0.5。levels:图像金字塔的层数。winsize:光流算法中窗口的大小。较大的窗口可以处理更大的运动,但可能导致运动的细节丢失。一般情况下,值为13-21。iterations:每个金字塔层中迭代的次数。poly_n:用于扩展像素邻域的多项式展开的阶数。常用的值为5或7。poly_sigma:多项式展开中高斯函数的标准差。通常设为1.1。flags:附加的计算标志,可以是以下值的组合:OPTFLOW_USE_INITIAL_FLOW:使用flow参数作为初始光流。OPTFLOW_FARNEBACK_GAUSSIAN:使用高斯滤波来平滑图像。
函数说明:
calcOpticalFlowFarneback函数使用了基于Gunnar Farneback的算法来计算光流。它利用了图像金字塔和多项式展开来估计前一帧图像中每个像素点到后一帧图像中的对应位置的运动矢量。
光流计算的基本思想是,在时间上相邻的两帧图像中,相同物体上的像素点在空间上会发生位移。该函数将输入的前一帧图像和后一帧图像作为输入,通过计算像素点的强度变化来估计每个像素点的位移向量。
光流计算的结果是一个两通道的浮点型图像,其中每个像素点的位移向量存储在相应位置的像素值中。根据需要,可以进一步处理这些位移向量,例如可视化运动接上文:
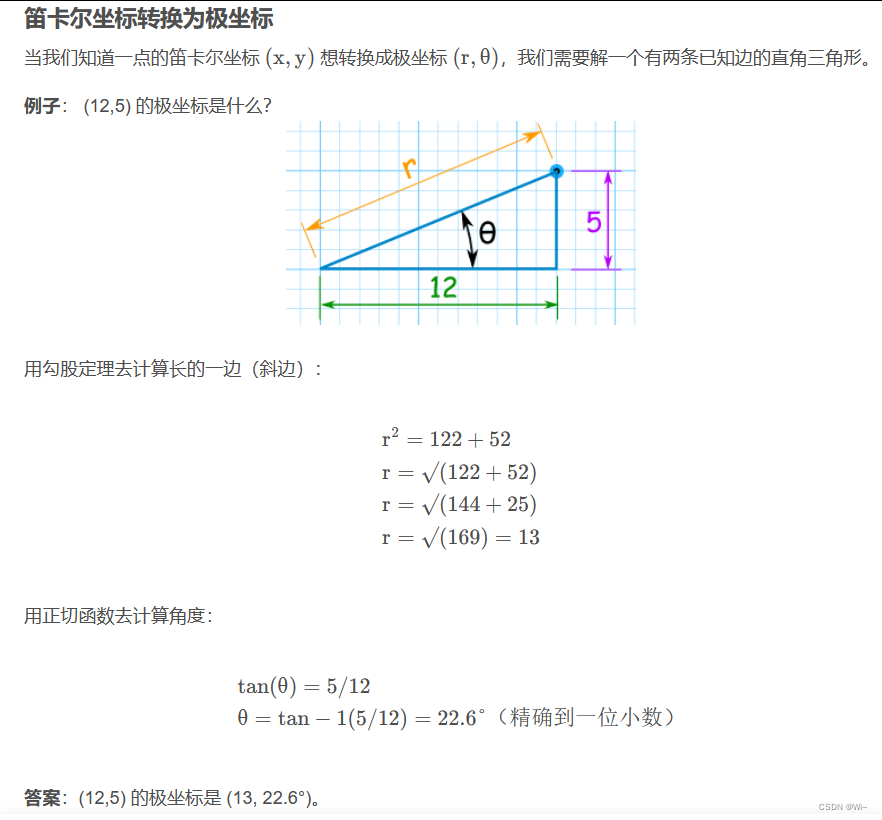
cartToPolar 笛卡尔坐标系中的坐标转换为极坐标系

cv::cartToPolar 是 OpenCV 中的一个函数,用于将笛卡尔坐标系中的坐标转换为极坐标系。它的函数原型如下:
void cv::cartToPolar(
InputArray x,
InputArray y,
OutputArray magnitude,
OutputArray angle,
bool angleInDegrees = false
)
函数参数:
x:输入的 x 坐标数组,类型为InputArray。可以是一个单通道的浮点型数组(例如CV_32FC1)或双通道的复数数组(例如CV_32FC2)。y:输入的 y 坐标数组,类型为InputArray,和x具有相同的要求。magnitude:输出的极坐标中的矢量大小(也称为模长或幅度),类型为OutputArray。与输入数组具有相同的大小和类型。angle:输出的极坐标中的矢量角度(也称为相位角),类型为OutputArray。与输入数组具有相同的大小和类型。angleInDegrees:一个布尔值,指示角度是否以度数(true)或弧度(false)表示。默认值为 false,表示角度以弧度表示。
这个函数将输入的 x 和 y 坐标数组视为图像中的像素位置,并将它们转换为极坐标系中的矢量大小和角度。如果输入的数组是复数数组,函数将使用实部作为 x 坐标,虚部作为 y 坐标。
代码演示:
int main()
{
VideoCapture capture("vtest.avi");
Mat prevFrame, prevGray;
if (!capture.read(prevFrame))
{
cout << "请确认视频文件名称是否正确" << endl;
return -1;
}
//将彩色图像转换成灰度图像
cvtColor(prevFrame, prevGray, COLOR_BGR2GRAY);
while (1)
{
Mat nextFrame, nextGray;
//所有图像处理完成后退出程序
if (!capture.read(nextFrame))
{
break;
}
imshow("视频图像", nextFrame);
//计算稠密光流
cvtColor(nextFrame, nextGray, COLOR_BGR2GRAY);
//Mat_是个模板类继承Mat 每个元素是Point2f类型
//Mat_<Point2f> flow;//两个方向的运动速度
//双通道
Mat flow;
calcOpticalFlowFarneback(prevGray, nextGray, flow, 0.5, 3, 15, 3, 5, 1.2, 0);
vector<Mat> xyV;
split(flow, xyV);
//x方向移动速度
Mat xV = xyV[0];
//y方向移动速度
Mat yV = xyV[1];
x方向移动速度
//Mat xV = Mat::zeros(prevFrame.size(), CV_32FC1);
y方向移动速度
//Mat yV = Mat::zeros(prevFrame.size(), CV_32FC1);
提取两个方向的速度
//for (int row = 0; row < flow.rows; ++row)
//{
// for (int col = 0; col < flow.cols; ++col)
// {
// const Point2f& flow_xy = flow.at<Point2f>(row, col);
// xV.at<float>(row, col) = flow_xy.x;
// yV.at<float>(row, col) = flow_xy.y;
// }
//}
//计算向量角度和赋值
Mat magnitude, angle;
//笛卡尔坐标转极坐标
cartToPolar(xV, yV, magnitude, angle,true);
//对于HSV颜色空间中的色调(H),OpenCV使用范围为0到179,而不是0到360。
//在将HSV颜色转换为BGR颜色时,需要将H值除以2。
angle /= 2.0;
//cartToPolar(xV, yV, magnitude, angle, false);
//angle = angle * 180 / CV_PI / 2.0;
//把幅值归一化到0-255,便于显示结果
normalize(magnitude, magnitude, 0, 255, NORM_MINMAX);
//计算角度和幅值的绝对值 输出类型CV_8U整数
convertScaleAbs(magnitude, magnitude);
convertScaleAbs(angle, angle);
//运动的幅值和角度生成HSV颜色空间的图像
Mat HSV = Mat::zeros(prevFrame.size(), prevFrame.type());
vector<Mat> result;
split(HSV, result);
//角度决定颜色
result[0] = angle;
//饱和度设置最深
//在OpenCV中,当我们使用8位无符号整数(`CV_8U`)来表示像素值时,通常将其缩放到0到255范围内。
//这是因为8位无符号整数的范围是0到255,所以将0到1的浮点数映射到这个范围内。
result[1] = Scalar(255);
//用幅值(模长)来充当亮度
result[2] = magnitude;
merge(result, HSV);
Mat rgbImg;
cvtColor(HSV, rgbImg, COLOR_HSV2BGR);
imshow("运动检测结果", rgbImg);
int ch = waitKey(0);
if (ch == 27)
{
break;
}
}
waitKey(0);
return 0;
}
calcOpticalFlowPyrLK 稀疏光流法函数
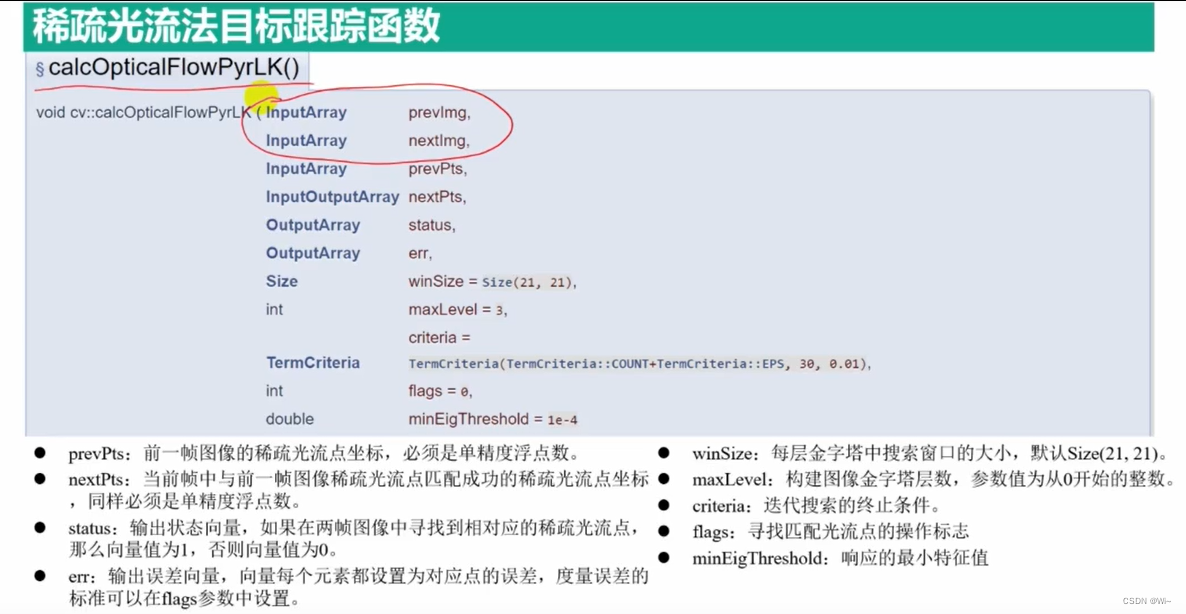
calcOpticalFlowPyrLK是OpenCV中的一个函数,用于计算图像中的光流。光流是描述图像中像素在连续帧之间的运动模式的方法。calcOpticalFlowPyrLK使用金字塔Lucas-Kanade方法来估计光流。
下面是calcOpticalFlowPyrLK函数的详细解释,包括函数的参数和使用方法。
cv::calcOpticalFlowPyrLK(
cv::InputArray prevImg, // 先前的图像帧
cv::InputArray nextImg, // 下一个图像帧
cv::InputArray prevPts, // 先前图像中的特征点
cv::InputOutputArray nextPts, // 下一个图像中的特征点(输出)
cv::OutputArray status, // 跟踪状态(输出)
cv::OutputArray err, // 跟踪误差(输出)
cv::Size winSize = cv::Size(21, 21), // 窗口大小
int maxLevel = 3, // 金字塔层数
cv::TermCriteria criteria = cv::TermCriteria(
cv::TermCriteria::COUNT + cv::TermCriteria::EPS, 30, 0.01),
int flags = 0, // 额外标志
double minEigThreshold = 1e-4 // 最小特征值阈值
);
参数解释:
prevImg:先前的图像帧,一般为灰度图像。nextImg:下一个图像帧,与prevImg对应。prevPts:先前图像中的特征点,通常使用goodFeaturesToTrack等函数提取的角点。nextPts:下一个图像中的特征点,函数将在此参数中输出跟踪到的特征点的位置。status:输出的状态数组,指示特征点的跟踪状态。如果特征点成功跟踪,则对应的状态值为1,否则为0。err:输出的跟踪误差数组,表示每个特征点的跟踪误差。winSize:用于计算光流的窗口大小。maxLevel:金字塔的层数,用于进行多尺度光流计算。criteria:迭代终止准则,用于控制算法的停止条件。flags:额外的标志参数,可以选择使用cv::OPTFLOW_USE_INITIAL_FLOW来使用prevPts作为初始跟踪位置。
- 在`calcOpticalFlowPyrLK`函数中,`flags`是一个额外的标志参数,用于控制光流计算的行为。该参数可以使用以下常量进行设置:
- `cv::OPTFLOW_USE_INITIAL_FLOW`:使用`prevPts`作为初始跟踪位置。如果将该标志设置为`flags`参数的值,函数将使用`prevPts`作为初始特征点位置,并计算它们在`nextImg`中的新位置。默认情况下,该标志为0,表示不使用初始流。
- `cv::OPTFLOW_LK_GET_MIN_EIGENVALS`:计算特征点的最小特征值。如果将该标志设置为`flags`参数的值,函数将计算特征点的最小特征值并存储在`err`参数中。默认情况下,该标志为0,表示不计算最小特征值。
可以通过按位或运算符`|`将多个标志组合在一起。例如,如果想同时使用初始流和计算最小特征值,可以将`flags`设置为`cv::OPTFLOW_USE_INITIAL_FLOW | cv::OPTFLOW_LK_GET_MIN_EIGENVALS`。
minEigThreshold:最小特征值阈值,用于判断特征点是否可靠。
nextPts输出的个数不一定与prevPts的个数一致。具体取决于算法在计算光流时能否成功跟踪到所有的先前特征点。
- 成功跟踪:特征点在下一个图像中找到了对应的位置,
calcOpticalFlowPyrLK会将对应的下一个图像中的特征点位置存储在nextPts中,而且对应的状态数组status中的值为1。这意味着特征点成功跟踪到了下一个图像。 - 未成功跟踪:特征点在下一个图像中没有找到对应的位置,
calcOpticalFlowPyrLK会将nextPts中对应的位置设置为一个无效值(可能为NaN或其他默认值),而且对应的状态数组status中的值为0。这表示特征点未能成功跟踪到下一个图像。
代码演示:
//绘制所有直线
void draw_lines(Mat& image, vector<Point2f> pt1, vector<Point2f> pt2)
{
RNG rng(1008);
vector<Scalar> color_lut;
if (color_lut.size() < pt1.size())
{
for (int t = 0; t < pt1.size(); ++t)
{
color_lut.push_back(Scalar(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255)));
}
}
for (int t = 0; t < pt1.size(); ++t)
{
arrowedLine(image, pt1[t], pt2[t], color_lut[t], 2, 8, 0);
}
}
int main()
{
VideoCapture capture("vtest.avi");
Mat prevFrame, prevGray;
if (!capture.read(prevFrame))
{
cout << "请确认视频文件名称是否正确" << endl;
return -1;
}
int fps = capture.get(CAP_PROP_FPS);
int width = capture.get(CAP_PROP_FRAME_WIDTH);
int height = capture.get(CAP_PROP_FRAME_HEIGHT);
int num_of_frames = capture.get(CAP_PROP_FRAME_COUNT);
cout << "fps:" << fps << endl;
cout << "视频宽度:" << width << endl;
cout << "视频高度:" << height << endl;
cout << "视频总帧数:" << num_of_frames << endl;
cvtColor(prevFrame, prevGray, COLOR_BGR2GRAY);
//角点检测
vector<Point2f> points;
goodFeaturesToTrack(prevGray, points, 2000, 0.01, 10);
//稀疏光流检测相关参数设置
vector<Point2f> prevPts;//前一帧图像角点坐标
vector<Point2f> nextPts;//当前帧图像角点坐标
vector<uchar> status;//角点检测到的状态
vector<float> err;
//初始状态的角点
vector<Point2f> initPoints;
initPoints.insert(initPoints.end(), points.begin(), points.end());
prevPts.insert(prevPts.end(), points.begin(), points.end());
while (true)
{
Mat nextFrame, nextGray;
if (!capture.read(nextFrame))
{
break;
}
imshow("nextFrame", nextFrame);
cvtColor(nextFrame, nextGray, COLOR_BGR2GRAY);
//光流跟踪
calcOpticalFlowPyrLK(prevGray, nextGray, prevPts, nextPts, status, err);
size_t i, k;
for (i = k = 0; i < nextPts.size(); ++i)
{
//距离与状态测量
double dist = abs(prevPts[i].x - nextPts[i].x) + abs(prevPts[i].y - nextPts[i].y);
//cout << "status:" << to_string( status[i] )<< " " << nextPts[i].x << nextPts[i].y << endl;
//筛选出有效特征点
if (status[i] && dist > 2)
{
prevPts[k] = prevPts[i];
initPoints[k] = initPoints[i];
nextPts[k] = nextPts[i];
++k;
circle(nextFrame, nextPts[i], 3, Scalar(0, 255, 0), -1, 8);
}
}
//重置数组大小 --- 更新移动角点数目
nextPts.resize(k);
prevPts.resize(k);
initPoints.resize(k);
draw_lines(nextFrame, initPoints, nextPts);
imshow("result", nextFrame);
char c = waitKey(50);
if (c == 27)
{
break;
}
//更新角点坐标和前一帧图像
std::swap(nextPts, prevPts);
nextGray.copyTo(prevGray);
//如果角点数目少于300,就重新检测角点
if (initPoints.size() < 300)
{
goodFeaturesToTrack(prevGray, points, 2000, 0.01, 10);
initPoints.insert(initPoints.end(), points.begin(), points.end());
prevPts.insert(prevPts.end(), points.begin(), points.end());
printf("total feature points:%d\n", prevPts.size());
}
}
return 0;
}

监督学习算法
TraninData::create 训练数据存储类 – 被其他学习类调用使用
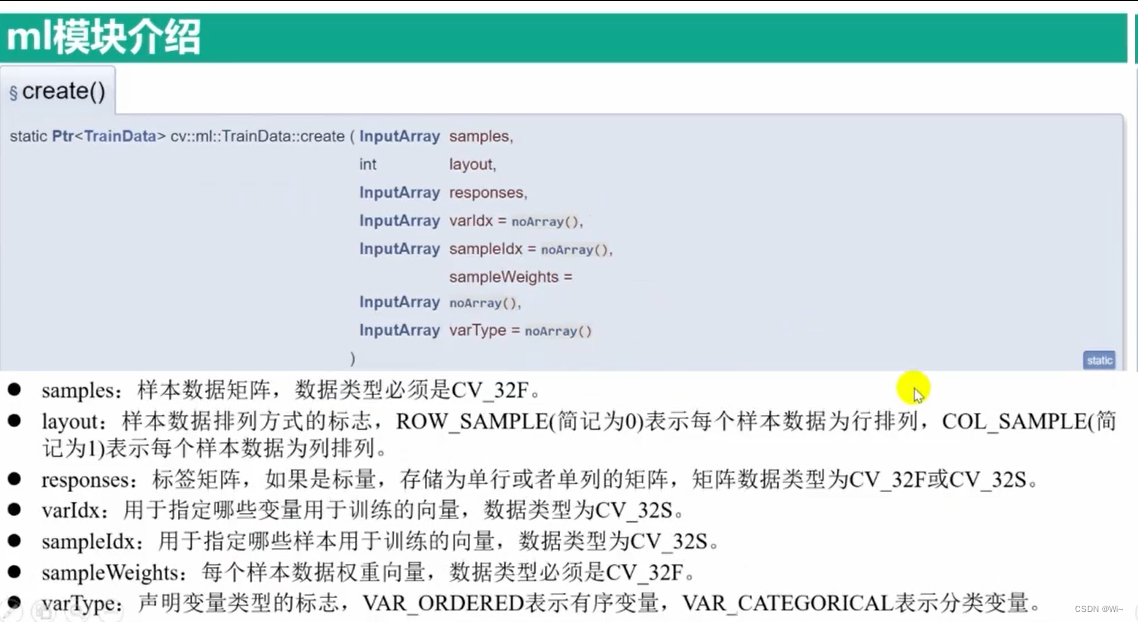
在OpenCV中,cv::ml::TrainData::create是一个静态函数,用于创建cv::ml::TrainData对象。它提供了一种简便的方式来初始化和组织用于训练机器学习模型的数据集。create函数的签名如下:
cv::Ptr<cv::ml::TrainData> cv::ml::TrainData::create(
const cv::Mat& samples,
int layout,
const cv::Mat& responses,
const cv::Mat& varIdx = cv::Mat(),
const cv::Mat& sampleIdx = cv::Mat(),
const cv::Mat& sampleWeights = cv::Mat(),
const cv::Mat& varType = cv::Mat());
该函数接受的参数和意义与TrainData类的构造函数相同,详细说明如下:
samples:包含训练样本的矩阵。每一行代表一个样本,每一列代表一个特征。数据类型必须是CV_32F。layout:指定samples矩阵的布局,可以是cv::ml::ROW_SAMPLE或cv::ml::COL_SAMPLE。cv::ml::ROW_SAMPLE表示每一行是一个样本,cv::ml::COL_SAMPLE表示每一列是一个样本。responses:包含训练样本对应的响应值的矩阵。每一行或每一列对应于一个样本的响应。数据类型是CV_32F或CV_32S。varIdx:可选参数,指定要使用的特征索引。它是一个1行或1列的整数矩阵,每个元素是样本特征的索引。数据类型是CV_32S。sampleIdx:可选参数,指定要使用的样本索引。它是一个1行或1列的整数矩阵,每个元素是样本的索引。数据类型是CV_32S。sampleWeights:可选参数,指定每个样本的权重。它是一个1行或1列的浮点数矩阵,每个元素对应于样本的权重。数据类型是CV_32F。varType:可选参数,指定每个特征的类型。它是一个1行或1列的整数矩阵,每个元素对应于特征的类型。
cv::ml::TrainData::create函数返回一个指向cv::ml::TrainData对象的智能指针(cv::Ptr<cv::ml::TrainData>)。
cv::ml::StatModel::train 训练的函数
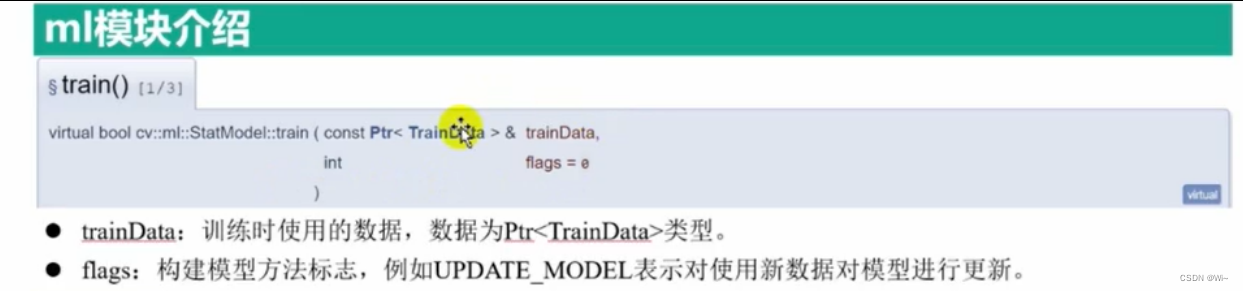
cv::ml::StatModel::train函数是OpenCV中机器学习模型训练的函数,用于训练统计模型。这个函数的完整定义如下:
bool cv::ml::StatModel::train(const cv::Ptr<cv::ml::TrainData>& trainData, int flags = 0)
该函数接受两个参数:
trainData:训练数据,通常是一个cv::Ptr<cv::ml::TrainData>类型的对象,其中包含了样本数据和标签数据等训练所需的信息。flags:训练标志,用于设置训练过程中的一些选项和参数。
函数返回一个布尔值,表示训练是否成功。
`flags`参数是用于设置训练过程中的选项和标志的整数参数。以下是一些常用的`flags`选项:
- `cv::ml::StatModel::RAW_OUTPUT`:用于返回原始输出,而不是进行概率估计。对于某些模型,可以通过设置此标志来获取原始输出。
- `cv::ml::StatModel::UPDATE_MODEL`:用于更新现有模型,而不是重新训练。如果你已经有一个训练好的模型,并希望使用新的数据来更新模型,可以使用此标志。
- `cv::ml::StatModel::COMPRESSED_INPUT`:用于指示输入数据是否压缩。当输入数据较大且内存有限时,可以使用此标志以减少内存消耗。
- `cv::ml::StatModel::PREPROCESSED_INPUT`:用于指示输入数据是否已经进行了预处理。如果输入数据已经进行了特征提取或其他预处理步骤,可以使用此标志来跳过预处理步骤。
- `cv::ml::StatModel::UPDATE_MODEL`:用于更新现有模型,而不是重新训练。如果你已经有一个训练好的模型,并希望使用新的数据来更新模型,可以使用此标志。
这些标志可以根据具体的模型和训练需求进行组合使用。你可以通过按位或(`|`)操作符将多个标志组合在一起,例如:`int flags = cv::ml::StatModel::RAW_OUTPUT | cv::ml::StatModel::UPDATE_MODEL`。
另外,如果不需要使用任何标志选项,可以将`flags`参数设置为默认值0。
bool cv::ml::StatModel::train(cv::InputArray samples, int layout, cv::InputArray responses)
该函数接受三个参数:
samples:输入样本数据,通常是一个cv::Mat类型的二维数组,每一行代表一个样本,每一列代表样本的一个特征。数据类型必须是CV_32F。layout:数据布局参数,表示输入样本数据的布局方式。常用的布局有两种:cv::ml::ROW_SAMPLE:每一行代表一个样本。cv::ml::COL_SAMPLE:每一列代表一个样本。
responses:响应变量数据,通常是一个cv::Mat类型的一维数组,包含了与每个样本相关联的输出或标签。数据类型是CV_32F或CV_32S。
函数返回一个布尔值,表示训练是否成功。
cv::ml::StatModel::predict 预测函数

cv::ml::StatModel::predict 是 OpenCV 中机器学习模型的预测函数,它用于对输入样本进行预测。这个函数的详解如下:
float StatModel::predict(InputArray samples, OutputArray results, int flags = 0) const;
参数:
samples:输入的样本数据,类型为cv::InputArray。可以是一个样本(单个输入样本)或者是一个样本集(多个输入样本)。数据类型必须是CV_32F。results:输出的预测结果,类型为cv::OutputArray。对于单个输入样本,结果是一个浮点数;对于样本集,结果是一个浮点数向量。flags:预测的标志位,可选参数。它可以影响预测的行为和输出结果的格式。默认值为 0,表示无特殊标志。
`flags`参数是用于设置训练过程中的选项和标志的整数参数。以下是一些常用的`flags`选项:
- `cv::ml::StatModel::RAW_OUTPUT`:用于返回原始输出,而不是进行概率估计。对于某些模型,可以通过设置此标志来获取原始输出。
- `cv::ml::StatModel::UPDATE_MODEL`:用于更新现有模型,而不是重新训练。如果你已经有一个训练好的模型,并希望使用新的数据来更新模型,可以使用此标志。
- `cv::ml::StatModel::COMPRESSED_INPUT`:用于指示输入数据是否压缩。当输入数据较大且内存有限时,可以使用此标志以减少内存消耗。
- `cv::ml::StatModel::PREPROCESSED_INPUT`:用于指示输入数据是否已经进行了预处理。如果输入数据已经进行了特征提取或其他预处理步骤,可以使用此标志来跳过预处理步骤。
- `cv::ml::StatModel::UPDATE_MODEL`:用于更新现有模型,而不是重新训练。如果你已经有一个训练好的模型,并希望使用新的数据来更新模型,可以使用此标志。
这些标志可以根据具体的模型和训练需求进行组合使用。你可以通过按位或(`|`)操作符将多个标志组合在一起,例如:`int flags = cv::ml::StatModel::RAW_OUTPUT | cv::ml::StatModel::UPDATE_MODEL`。
另外,如果不需要使用任何标志选项,可以将`flags`参数设置为默认值0。
返回值:
float:预测结果的置信度或距离。具体的返回值含义取决于使用的机器学习模型和预测的标志位。
cv::Algorithm::save 用于将算法对象的状态保存到文件中
cv::Algorithm::save 是 OpenCV 中的一个函数,用于将算法对象的状态保存到文件中。它是 OpenCV 中的基类 cv::Algorithm 的成员函数之一。
void cv::Algorithm::save(const cv::String& filename) const;
参数:
filename:保存文件的路径和名称。
函数说明:
cv::Algorithm::save函数用于将算法对象的状态保存到文件中,以便在将来的某个时间点可以恢复该状态。- 保存的文件包含了算法对象的所有参数和内部状态。
- 保存的文件使用了 OpenCV 特定的 XML 或 YAML 格式。
cv::Algorithm::load 从文件加载算法模型并返回一个指向加载的对象的智能指针
在OpenCV中,cv::Algorithm::load函数用于从文件加载算法模型并返回一个指向加载的对象的智能指针。
函数的原型如下:
cv::Ptr<cv::Algorithm> cv::Algorithm::load(const cv::String& filename, const cv::String& objname = cv::String())
参数说明:
filename:要加载的文件的路径和名称。objname(可选):要加载的对象的名称。对于大多数情况,可以忽略这个参数。在某些特定情况下,例如当文件中包含多个模型时,可以使用此参数来指定要加载的对象。
当使用`cv::Algorithm::load`函数加载包含多个对象的文件时,可以使用`objname`参数来指定要加载的对象的名称。这在以下情况下特别有用:
假设你有一个XML文件,其中包含多个对象,如人脸检测器和眼睛检测器。你可以使用`objname`参数来指定要加载的对象。以下是一个示例:
cv::Ptr<cv::CascadeClassifier> faceDetector = cv::Algorithm::load<cv::CascadeClassifier>("path/to/model.xml", "face");
if (faceDetector.empty())
{
// 加载人脸检测器失败,处理错误
}
else
{
// 人脸检测器加载成功,可以使用它进行人脸检测
}
cv::Ptr<cv::CascadeClassifier> eyeDetector = cv::Algorithm::load<cv::CascadeClassifier>("path/to/model.xml", "eye");
if (eyeDetector.empty())
{
// 加载眼睛检测器失败,处理错误
}
else
{
// 眼睛检测器加载成功,可以使用它进行眼睛检测
}
在这个示例中,我们假设XML文件中有两个对象:一个是人脸检测器,另一个是眼睛检测器。我们通过在`cv::Algorithm::load`函数中使用`objname`参数来指定要加载的对象的名称。对于人脸检测器,我们将`objname`设置为"face",对于眼睛检测器,我们将`objname`设置为"eye"。通过这种方式,我们可以选择性地加载文件中的特定对象,并将它们赋值给适当的变量进行进一步的操作。
请注意,具体的`objname`值取决于文件中对象的命名。你需要查看文件中对象的名称,然后在`cv::Algorithm::load`函数中提供正确的`objname`值来加载所需的对象。
对于YAML文件的加载,objname参数在大多数情况下是不需要的,因为YAML文件通常只包含一个对象的信息。objname参数主要在加载包含多个对象的文件时使用,例如保存了多个算法模型的YAML文件。
该函数返回一个指向加载的算法对象的智能指针(cv::Ptr<cv::Algorithm>)。如果加载失败或文件中找不到指定的对象,则返回空指针。
Ptr<SVM> svm = Algorithm::load<SVM>("my_svm_model.xml");
K近邻原理介绍
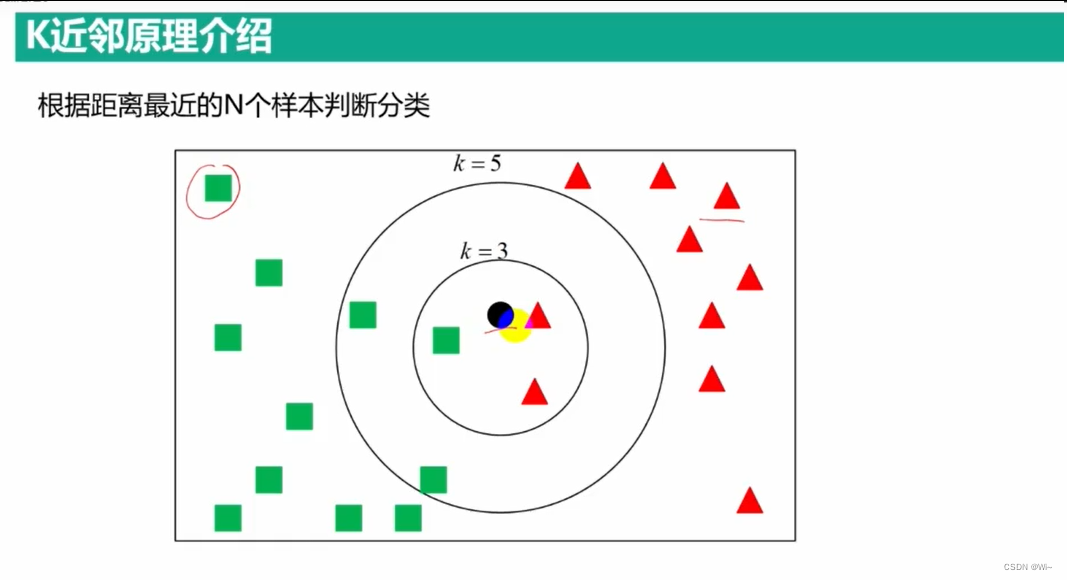
cv::ml::KNearest::findNearest 查找K 个邻居的标签 — K 最近邻(监督学习)
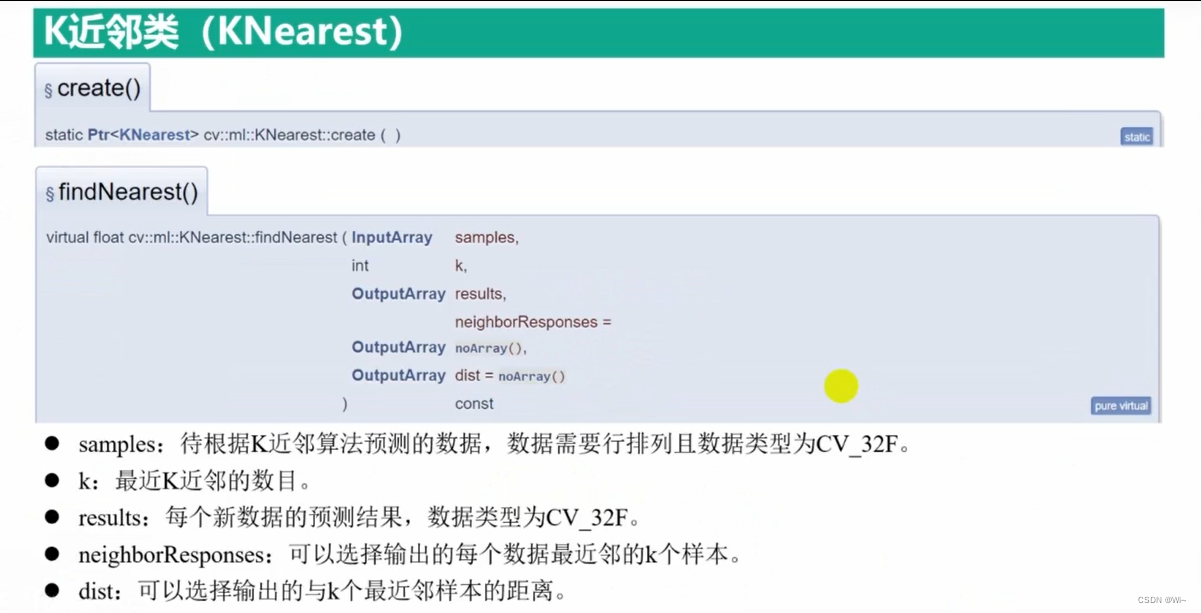
cv::ml::KNearest::findNearest 是 OpenCV 中 K 最近邻(K-Nearest Neighbors)分类器的成员函数之一。它用于对给定的输入样本进行分类,并返回最接近的 K 个邻居的标签。
下面是函数的详细解释:
float cv::ml::KNearest::findNearest(
InputArray samples,
int k,
OutputArray results = noArray(),
OutputArray neighborResponses = noArray(),
OutputArray dist = noArray()
)
参数说明:
samples:输入样本。可以是一个单独的样本或包含多个样本的矩阵。每个样本都是一个包含特征向量的浮点型矩阵。k:指定要找到的最近邻居的数量。results:可选参数,用于存储分类结果的输出矩阵。如果不需要结果,则可以传递noArray()。neighborResponses:可选参数,用于存储每个最近邻居的响应标签的输出矩阵。如果不需要最近邻居的响应标签,则可以传递noArray()。dist:可选参数,用于存储每个最近邻居与输入样本之间的距离的输出矩阵。如果不需要距离信息,则可以传递noArray()。
返回值:
float:如果results参数不为空,该函数返回分类结果的误差;否则返回负数。
使用 cv::ml::KNearest::findNearest 的基本流程如下:
- 创建 K 最近邻分类器对象,并使用
train函数对其进行训练,设置训练数据和标签。 - 准备要进行分类的输入样本数据。
- 调用
findNearest函数,并传递输入样本以及其他可选参数。 - 根据需要,从输出参数中获取分类结果、最近邻居的响应标签和距离信息。
knn->setDefaultK(K); // 设置K值,即选择K个最近邻居进行投票
knn->setIsClassifier(true); // 设置为分类器
knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); // 设置算法类型
BRUTE_FORCE和KDTREE是KNearest算法中的两种不同的算法类型。它们在计算最近邻居时使用不同的策略和数据结构。
1. BRUTE_FORCE(暴力法):
BRUTE_FORCE算法类型是KNearest的默认算法类型。它采用了一种简单直接的方法,在计算最近邻居时遍历训练数据集中的所有样本,并计算它们与待分类数据之间的距离。然后根据距离选择最近的K个邻居进行投票决策。这种算法类型适用于数据集较小的情况,但对于大规模数据集,它的计算效率较低。
2. KDTREE(KD树):
KDTREE算法类型采用了一种基于树结构的方法来加速最近邻居的搜索。它将训练数据集构建成一个KD树(也称为K维树),其中每个节点代表一个样本,根据样本在特征空间中的划分选择合适的分割超平面。在进行最近邻搜索时,通过比较待分类数据与KD树节点的划分超平面的距离,可以有效地减少搜索空间,加速搜索过程。KDTREE适用于高维数据集和大规模数据集,它的计算效率相对较高。
在使用KNearest算法时,你可以根据数据集的规模和维度选择适合的算法类型。对于小型数据集或低维数据,使用默认的BRUTE_FORCE算法即可。对于大型数据集或高维数据,使用KDTREE算法能够提供更高的搜索效率。
支持向量机原理介绍
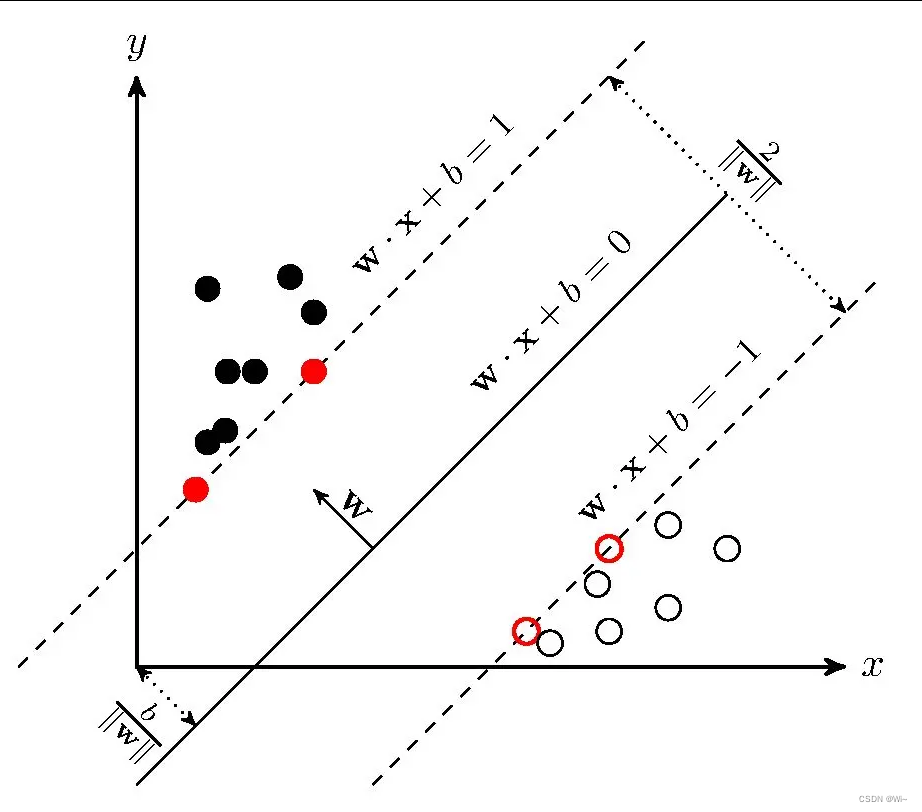
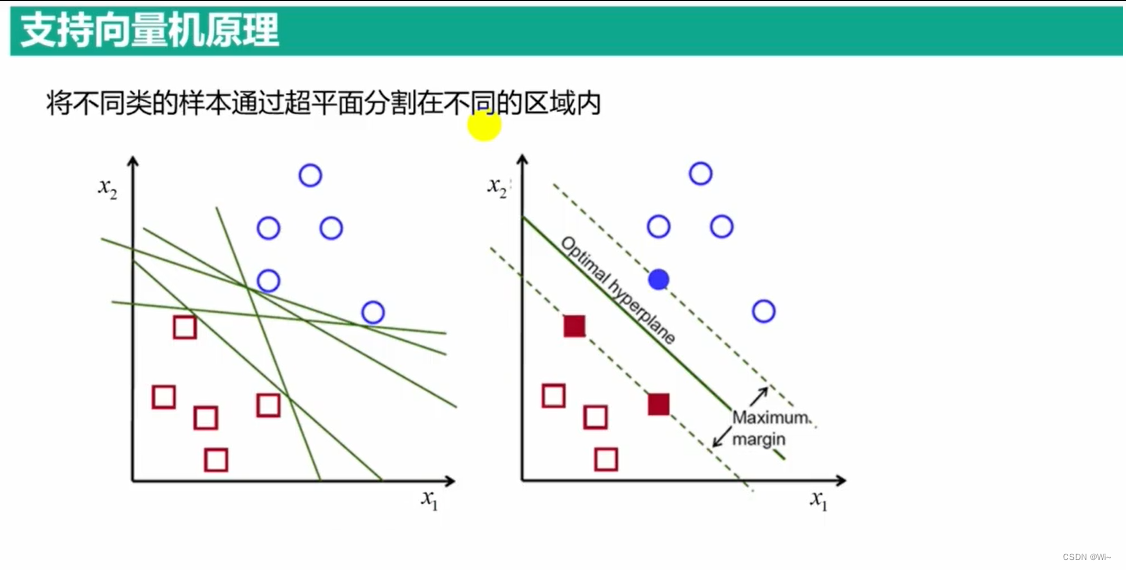
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。说白了就是在一个空间中,怎么把空间中的数据一分为二。
//SVM类型
svm1->setType(cv::ml::SVM::C_SVC);
//内核模型
svm1->setKernel(cv::ml::SVM::CHI2);
cv::ml::SVM::Types
-
cv::ml::SVM::C_SVC:- C-Support向量分类(C-SVC)是一种常见的支持向量机分类算法。
- 它通过寻找最优超平面将训练数据分为不同的类别。
- C-SVC使用正则化参数C来控制误分类的惩罚程度,C值越大,模型对误分类的容忍度越低。
-
cv::ml::SVM::NU_SVC:- Nu-Support向量分类(Nu-SVC)也是一种支持向量机分类算法。
- 它使用一个参数nu来控制支持向量的选择。
- Nu-SVC相对于C-SVC,支持向量的选择更加自适应,可以在一定程度上处理不均衡数据集。
-
cv::ml::SVM::ONE_CLASS:- One-Class SVM是一种支持向量机算法,用于异常检测或单类别分类问题。
- 它的目标是将数据限制在一个超平面内,将正常样本与异常样本分开。
- One-Class SVM不依赖于类别标签,只关注数据的分布情况。
-
cv::ml::SVM::EPS_SVR:- ε-Support向量回归(ε-SVR)是一种支持向量机回归算法。
- 它通过寻找最优超平面来逼近训练数据的输出值。
- ε-SVR使用正则化参数C和容错参数ε来控制模型的复杂度和容错程度。
-
cv::ml::SVM::NU_SVR:- Nu-Support向量回归(Nu-SVR)也是一种支持向量机回归算法。
- 它使用参数nu来控制支持向量的选择。
- Nu-SVR相对于ε-SVR,在支持向量的选择上更加自适应。
这些不同的类型代表了支持向量机在分类和回归任务中的不同变体和应用场景。根据具体的问题需求和数据特性,选择合适的类型可以优化模型的性能和泛化能力。
cv::ml::SVM::KernelTypes


-
线性内核函数 (
cv::ml::SVM::KernelTypes::LINEAR):- 线性内核函数是最简单的内核函数。
- 它在特征空间中实现了线性映射,适用于线性可分的问题。
- 线性内核函数在处理高维数据时效果较好。
- 线性内核函数的数学公式为:K(x, y) = x^T * y,其中 x 和 y 分别是输入样本的特征向量,^T 表示转置操作。
-
多项式内核函数 (
cv::ml::SVM::KernelTypes::POLY):- 多项式内核函数通过多项式映射将数据映射到高维特征空间。
- 它可以处理非线性问题,但多项式的阶数需要通过参数进行设置。
- 多项式内核函数在一些非线性问题中表现良好,但在过高的阶数下容易过拟合。
- 多项式内核函数的数学公式为:K(x, y) = (gamma * x^T * y + coef0)^degree,其中 x 和 y 分别是输入样本的特征向量,gamma 是内核参数,coef0 是常数项,degree 是多项式的阶数。
-
径向基函数(RBF)内核函数 (
cv::ml::SVM::KernelTypes::RBF):- RBF内核函数是常用的非线性内核函数。
- 它通过将数据映射到无限维的特征空间来处理非线性问题。
- RBF内核函数具有平滑的决策边界,可以适用于复杂的分类问题。
- RBF内核函数的一个重要参数是gamma,用于控制决策边界的灵活性。
- RBF内核函数的数学公式为:K(x, y) = exp(-gamma * ||x - y||^2),其中 x 和 y 分别是输入样本的特征向量,gamma 是内核参数,||.|| 表示欧几里德范数(Euclidean norm)。
-
Sigmoid内核函数 (
cv::ml::SVM::KernelTypes::SIGMOID):- Sigmoid内核函数是一种非线性内核函数。
- 它模拟了神经网络中的Sigmoid激活函数。
- Sigmoid内核函数在某些特定的问题中可能有用,但在一般情况下往往不如其他内核函数表现好。
- Sigmoid内核函数的数学公式为:K(x, y) = tanh(gamma * x^T * y + coef0),其中 x 和 y 分别是输入样本的特征向量,gamma 是内核参数,coef0 是常数项,tanh 表示双曲正切函数。
-
卡方内核函数 (
cv::ml::SVM::KernelTypes::CHI2):- 卡方内核函数基于卡方统计量,常用于处理直方图数据的分类问题。
- 数学公式:K(x, y) = exp(-gamma * D(x, y))
- 其中,x 和 y 是输入样本的特征向量,gamma 是内核函数的参数,D(x, y) 是卡方统计量。
-
内插内核函数 (
cv::ml::SVM::KernelTypes::INTER):- 内插内核函数是一种自定义的内核函数类型,用于SVM的交叉训练策略。
代码演示:
int main()
{
system("color F0");
{
Mat img = imread("digits.png");
Mat gray;
cvtColor(img, gray, COLOR_BGR2GRAY);
//分割为5000个cells 20×20
Mat images = Mat::zeros(5000, 400, CV_8UC1);
Mat labels = Mat::zeros(5000, 1, CV_8UC1);
int index = 0;
for (int row = 0; row < 50; row++)
{
//从图像中分割出20×20的图像作为独立数字图像
int label = row / 5;
int datay = row * 20;
for (int col = 0; col < 100; col++)
{
int datax = col * 20;
//Mat number = Mat::zeros(Size(20, 20), CV_8UC1);
//for (int x = 0; x < 20; x++)
//{
// for (int y = 0; y < 20; y++)
// {
// number.at<uchar>(x, y) = gray.at<uchar>(x + datay, y + datax);
// }
//}
//抠图 20*20
Mat number = Mat(gray, Range(datay, datay + 20), Range(datax, datax + 20));
Mat temp;
number.copyTo(temp);
//将二维图像数据转成行数据 1通道1行
Mat tempRow = temp.reshape(1, 1);
cout << "提取第" << index + 1 << "个数据" << endl;
tempRow.copyTo(images(Range(index, index + 1), Range(0, 400)));
labels.at<uchar>(index, 0) = label;
++index;
}
}
imwrite("所有数据按行排列结果.png", images);
imwrite("标签.png", labels);
//加载训练数据集
images.convertTo(images, CV_32FC1);
labels.convertTo(labels, CV_32SC1);
Ptr<ml::TrainData>tdata = ml::TrainData::create(images, ml::ROW_SAMPLE, labels);
//创建K近邻类
Ptr<ml::KNearest> knn = KNearest::create();
//每个类别拿出5个数据
knn->setDefaultK(5);
//进行分类
knn->setIsClassifier(true);
//设置算法 -KD树
//knn->setAlgorithmType(cv::ml::KNearest::KDTREE);
//训练数据
//knn->train(images, cv::ml::ROW_SAMPLE, labels);
knn->train(tdata);
//保存训练结果
knn->save("knn_model.yml");
waitKey(0);
//加载KNN分类器
Mat data = imread("所有数据按行排列结果.png", IMREAD_ANYDEPTH);
labels = imread("标签.png", IMREAD_ANYDEPTH);
bool isss = data.isContinuous();
data.convertTo(data, CV_32F);
labels.convertTo(labels, CV_32SC1);
knn = Algorithm::load<KNearest>("knn_model.yml");
//查看分类结果
Mat result;
knn->findNearest(data, 5, result);
//统计分类结果与真实结果相同的数目
int count = 0;
for (int row = 0; row < result.rows; row++)
{
if (labels.at<int>(row, 0) == result.at<float>(row, 0))
++count;
}
//正确比率
float rate = 1.0*count / result.rows;
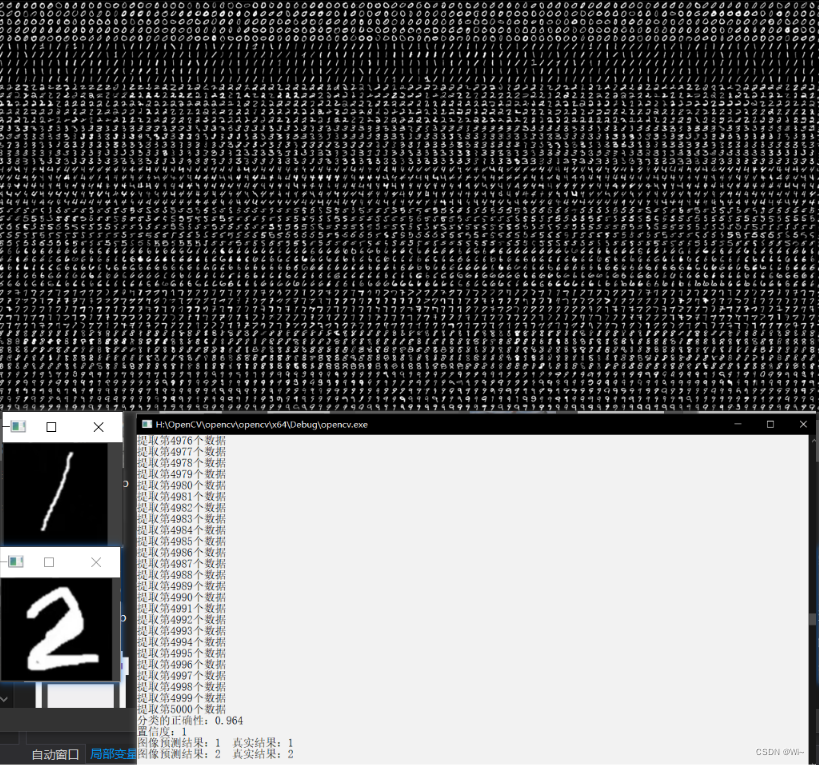
cout << "分类的正确性:" << rate << endl;
//测试新图像是否能够识别数字
Mat testImg1 = imread("handWrite01.png", IMREAD_GRAYSCALE);
Mat testImg2 = imread("handWrite02.png", IMREAD_GRAYSCALE);
imshow("testImg1", testImg1);
imshow("testImg2", testImg2);
//缩放到20*20的尺寸
resize(testImg1, testImg1, Size(20, 20));
resize(testImg2, testImg2, Size(20, 20));
Mat testdata = Mat::zeros(2, 400, CV_8UC1);
Rect rect;
rect.x = 0;
rect.y = 0;
rect.height = 1;
rect.width = 400;
Mat oneData = testImg1.reshape(1, 1);
Mat twoData = testImg2.reshape(1, 1);
oneData.copyTo(testdata(rect));
rect.y = 1;
twoData.copyTo(testdata(rect));
//数据类型转换
testdata.convertTo(testdata, CV_32F);
//进行估计识别
Mat result2;
float confidence = knn->findNearest(testdata, 5, result2);
//查看预测结果 0 - 1.0,越高越好
cout << "置信度:" << confidence << endl;
int predict1 = result2.at<float>(0, 0);
cout << "图像预测结果:" << predict1 << " 真实结果:" << 1 << endl;
int predict2 = result2.at<float>(1, 0);
cout << "图像预测结果:" << predict2 << " 真实结果:" << 2 << endl;
}
Mat samples, labls;
FileStorage fread("point.yml", FileStorage::READ);
fread["samples"] >> samples;
fread["responses"] >> labls;
fread.release();
//不同种类坐标点拥有不同的颜色
vector<Vec3b> colors;
colors.push_back(Vec3b(0, 255, 0));
colors.push_back(Vec3b(0, 0, 255));
//创建空白图像用于显示坐标点
Mat img(480, 640, CV_8UC3, Scalar(255, 255, 255));
Mat img2;
img.copyTo(img2);
//在空白图像中绘制坐标点
for (int i = 0; i < samples.rows; ++i)
{
Point2f point;
point.x = samples.at<float>(i, 0);
point.y = samples.at<float>(i, 1);
Scalar color = colors[labls.at<int>(i, 0)];
circle(img, point, 3, color, -1);
circle(img2, point, 3, color, -1);
}
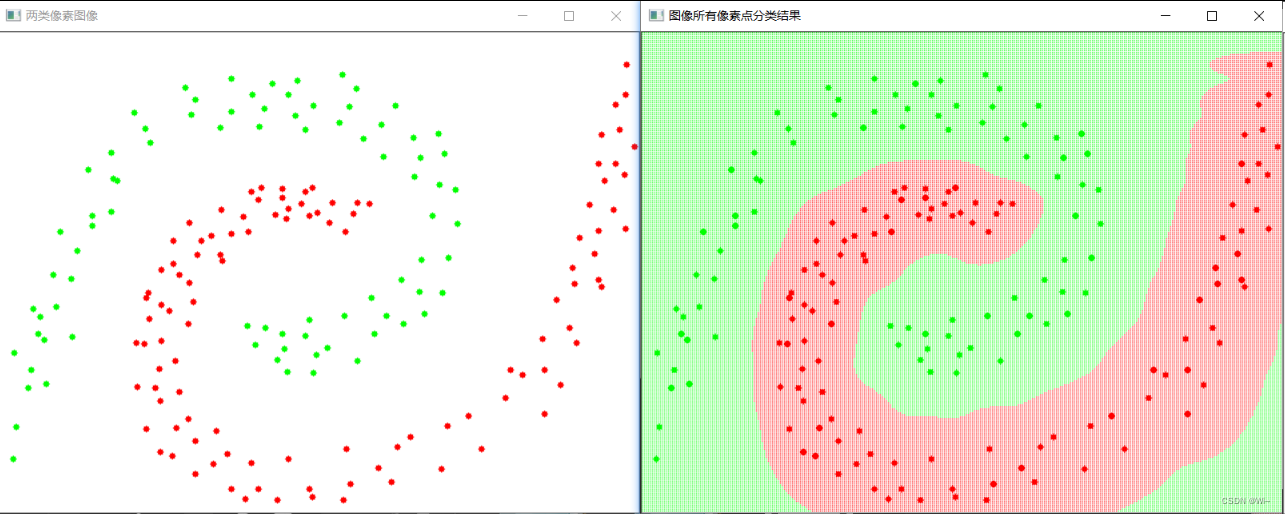
imshow("两类像素图像", img);
// 创建SVM对象 -- 解决二分类问题
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
// 设置参数
//SVM类型
svm->setType(cv::ml::SVM::C_SVC);
//内核模型 -- CHI2(用于处理直方图类型数据)
svm->setKernel(cv::ml::SVM::CHI2);
//svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER + TermCriteria::EPS, 100, 0.01));
//svm->setC(1);
//svm->setGamma(0.50625);
//svm->setDegree(3);
// 训练SVM模型
svm->train(TrainData::create(samples, ROW_SAMPLE, labls));
// 保存模型
svm->save("svm_model.yml");
Ptr<SVM> svm1 = Algorithm::load<SVM>("svm_model.yml");
// 设置参数
//SVM类型
svm1->setType(cv::ml::SVM::C_SVC);
//内核模型
svm1->setKernel(cv::ml::SVM::CHI2);
//用模型对图像中全部像素点进行分类
Mat imagePoint(1, 2, CV_32FC1);
for (int y = 0; y < img2.rows; y += 2)
{
for (int x = 0; x < img2.cols; x += 2)
{
imagePoint.at<float>(0) = (float)x;
imagePoint.at<float>(1) = (float)y;
Mat result; //保存0或1
int colorIndex = (int)svm1->predict(imagePoint, result);
img2.at<Vec3b>(y, x) = colors[(int)result.at<float>(0, 0)];
}
}
imshow("图像所有像素点分类结果", img2);
waitKey(0);
return 0;
}
最近邻分类knn
支持向量机SVM
无监督学习算法
聚类和分类的区别: 最大区别是:聚类是无监督的;分类是有监督学习。

算法步骤
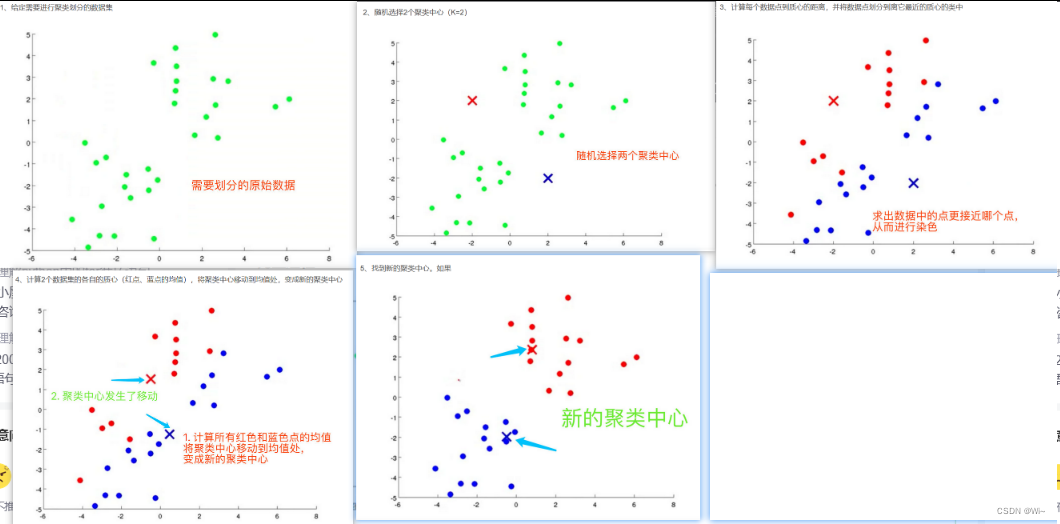
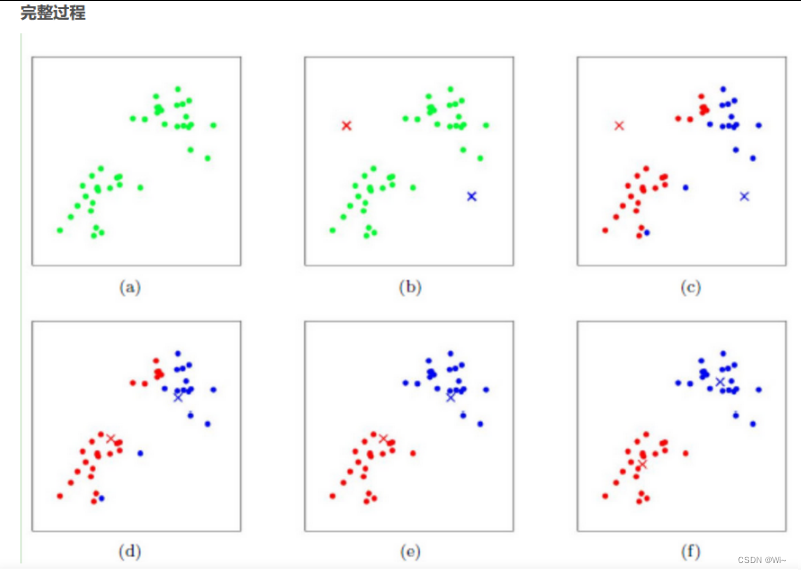
K-Means算法的具体步骤如下:
- 首先我们需要确定一个k值(随机),即我们希望数据经过聚类得到k个不同的集合
- 从给定的数据集中随机选择K个数据点作为质心
- 对数据集中的每个点计算其与每一个质心的距离(比如欧式距离);数据点离哪个质心近,就划分到那个质心所属的集合
- 第一轮将所有的数据归号集合后,一共有K个集合,然后重新计算每个集合的质心
- 如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值,则表示重新计算的质心的位置变化不大,数据整体趋于稳定,或者说数据已经收敛。在这样的情况下,我们认为聚类效果已经达到了期望的结果,算法可终止。
- 反之,如果新质心和原来质心的距离变化很大,需要重复迭代3-5步骤,直至位置变化不大,达到收敛状态。
在K-Means算法中一般采用的是欧式距离
算法优缺点
优点
1. 原理很简单,实现起来也是非常容易,算法收敛速度也很快
2. 聚类效果优,可解释性强。当数据最终收敛之后,我们最终能够很清晰的看到聚类的效果
3. 约束条件少。算法中需要控制的参数只有簇数k。通过对k的不断调节才能得到最好的聚类效果
缺点
1. k值的选取不好把握,很多情况下K值的估计是非常困难的,有时候通过交叉验证来获取。
2. 迭代的方法得到的结果只能是局部最优解,而不能得到全局最优解。
3. 对噪音和异常点很敏感。异常点对质心的确定影响很大的。可以用来检测异常值。
kmeans K均值聚类算法
OpenCV是一个流行的计算机视觉库,它提供了各种图像处理和分析功能。其中之一是k-means聚类算法,该算法可以用于图像分割、特征提取等任务。在C++中,OpenCV提供了一个函数kmeans来执行k-means聚类。
下面是关于OpenCV kmeans函数的详细解释:
void cv::kmeans(
InputArray data, // 输入数据,可以是N行M列的浮点型矩阵(N个样本,M维特征)
int K, // 聚类的数目
InputOutputArray bestLabels, // 输出的聚类标签
TermCriteria criteria, // 算法终止的条件
int attempts = 3, // 重复尝试次数,以获得最佳结果
int flags = KMEANS_RANDOM_CENTERS, // 初始化聚类中心的方法
OutputArray centers = noArray() // 输出的聚类中心
);
参数说明:
data:输入数据,可以是一个N行M列的浮点型矩阵,每一行表示一个样本,每一列表示一个特征。
Mat points(count, 2, CV_32F);
Mat points(count, 1, CV_32FC2);
Mat points(1, count, CV_32FC2);
std::vector<cv::Point2f> points(sampleCount);
K:聚类的数目,即期望得到的聚类中心的个数。bestLabels:输出的聚类标签,一个Nx1的整数型矩阵,表示每个样本所属的聚类。序号从0开始,比如 K=3,那么bestLabels为:0,1,2这三个。criteria:算法终止的条件,可以通过cv::TermCriteria结构体指定,常用的是通过设置cv::TermCriteria::MAX_ITER和cv::TermCriteria::EPS来控制迭代次数和收敛精度。 算法终止标准,即最大迭代次数和/或所需的精度。精度指定为 criteria.epsilon。一旦每个聚类中心在某个迭代中移动小于 criteria.epsilon,算法就会停止。attempts:重复尝试次数,算法会执行多次并返回最佳结果。
attempts是kmeans函数的一个可选参数,用于指定重复尝试的次数以获得最佳结果。
k-means算法的初始聚类中心对最终的聚类结果具有影响。为了得到更好的聚类结果,可以多次运行k-means算法,每次使用不同的初始聚类中心,并选择最佳的聚类结果。
参数`attempts`指定了重复尝试的次数,默认值为3。这意味着算法将运行3次,并返回其中最佳的聚类结果。可以根据实际情况适当调整这个参数的值。
在每次尝试中,算法使用不同的初始聚类中心。具体的初始聚类中心选择方法由参数`flags`指定,可以是`cv::KMEANS_RANDOM_CENTERS`(随机选取数据点)或`cv::KMEANS_PP_CENTERS`(k-means++算法选择)。
通过多次尝试并选择最佳结果,可以减少k-means算法受初始聚类中心选择的影响,提高聚类结果的准确性。但请注意,较大的`attempts`值会增加计算时间。因此,需要在时间和结果质量之间做出权衡。
flags:初始化聚类中心的方法,可以是以下值之一:
`flags`是`kmeans`函数的一个可选参数,用于指定初始化聚类中心的方法。下面是`flags`参数的三个常用标志:
1. `cv::KMEANS_RANDOM_CENTERS`:
- 值:0
- 含义:使用随机选取的数据点作为初始聚类中心。
- 说明:该方法是一种简单而快速的初始化聚类中心的方式,它随机选择输入数据中的K个样本作为初始聚类中心。
2. `cv::KMEANS_PP_CENTERS`:
- 值:2
- 含义:使用k-means++算法选择初始聚类中心。
- 说明:k-means++算法通过迭代地选择与已选中聚类中心距离较远的数据点作为下一个聚类中心,从而更好地初始化聚类中心。这种方法通常能够得到比随机选取更好的聚类结果。
3. `cv::KMEANS_USE_INITIAL_LABELS`:
- 值:1
- 含义:使用提供的初始聚类标签来初始化聚类中心。
- 说明:当使用该标志时,函数会根据提供的初始聚类标签计算每个聚类的中心,并将其作为初始聚类中心。这可以用于进一步优化聚类结果,尤其是在已经有一些关于聚类的先验知识或已经进行了一些预处理的情况下。
centers:输出的聚类中心,一个K行M列的浮点型矩阵,表示每个聚类的中心点。
使用kmeans函数的一般步骤如下:
- 准备输入数据,构建一个N行M列的浮点型矩阵,其中N是样本数,M是特征数。
- 创建一个输出矩阵
bestLabels,用于保存每个样本的聚类标签。 - 定义算法终止的条件,例如通过设置最大迭代次数和收敛精度。
- 调用
kmeans函数,传入输入数据、聚类数目、聚类标签、终止条件等参数。 - 检6. 检查函数返回值,确保聚类操作成功完成。如果返回值为负数,则表示发生了错误。
- 如果需要获取聚类中心,可以创建一个输出矩阵
centers,将其作为参数传入kmeans函数中。 - 检查
bestLabels和centers的结果,可以根据聚类标签将样本分组,并使用聚类中心进行进一步的分析和处理。
int main()
{
//生成一个500*500的图像用于显示特征点和分类结果
Mat img(500, 500, CV_8UC3, Scalar(255, 255, 255));
RNG rng(10000);
//设置三种颜色
Scalar colorLut[3]=
{
Scalar(0,0,255),
Scalar(0,255,0),
Scalar(255,0,0)
};
//设置三个点集,并且每个点集中点的数目随机
int number = 3;
int Points1 = rng.uniform(20, 200);
int Points2 = rng.uniform(20, 200);
int Points3 = rng.uniform(20, 200);
cout << "Points1: " << Points1 << endl;
cout << "Points2: " << Points2 << endl;
cout << "Points3: " << Points3 << endl;
Mat Points(Points1 + Points2 + Points3, 1, CV_32FC2);
int i = 0;
for (; i < Points1; ++i)
{
Point2f pts;
pts.x = rng.uniform(100, 200);
pts.y = rng.uniform(100, 200);
Points.at<Point2f>(i, 0) = pts;
}
for (; i < Points1+Points2; ++i)
{
Point2f pts;
pts.x = rng.uniform(300, 400);
pts.y = rng.uniform(100, 300);
Points.at<Point2f>(i, 0) = pts;
}
for (; i < Points1 + Points2+Points3; ++i)
{
Point2f pts;
pts.x = rng.uniform(100, 200);
pts.y = rng.uniform(390, 490);
Points.at<Point2f>(i, 0) = pts;
}
//每个点所属的种类
Mat labels;
//每类点的中心位置坐标
Mat centers;
kmeans(Points, number, labels, TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1), 3, KMEANS_PP_CENTERS, centers);
//根据分类为每个点设置不同的颜色
img = Scalar::all(255);
for (int i = 0; i < Points1 + Points2 + Points3; i++)
{
int index = labels.at<int>(i);
Point point = Points.at<Point2f>(i);
circle(img, point, 2, colorLut[index], -1, 4);
}
for (int i = 0; i < centers.rows; i++)
{
int x = centers.at<float>(i, 0);
int y = centers.at<float>(i, 1);
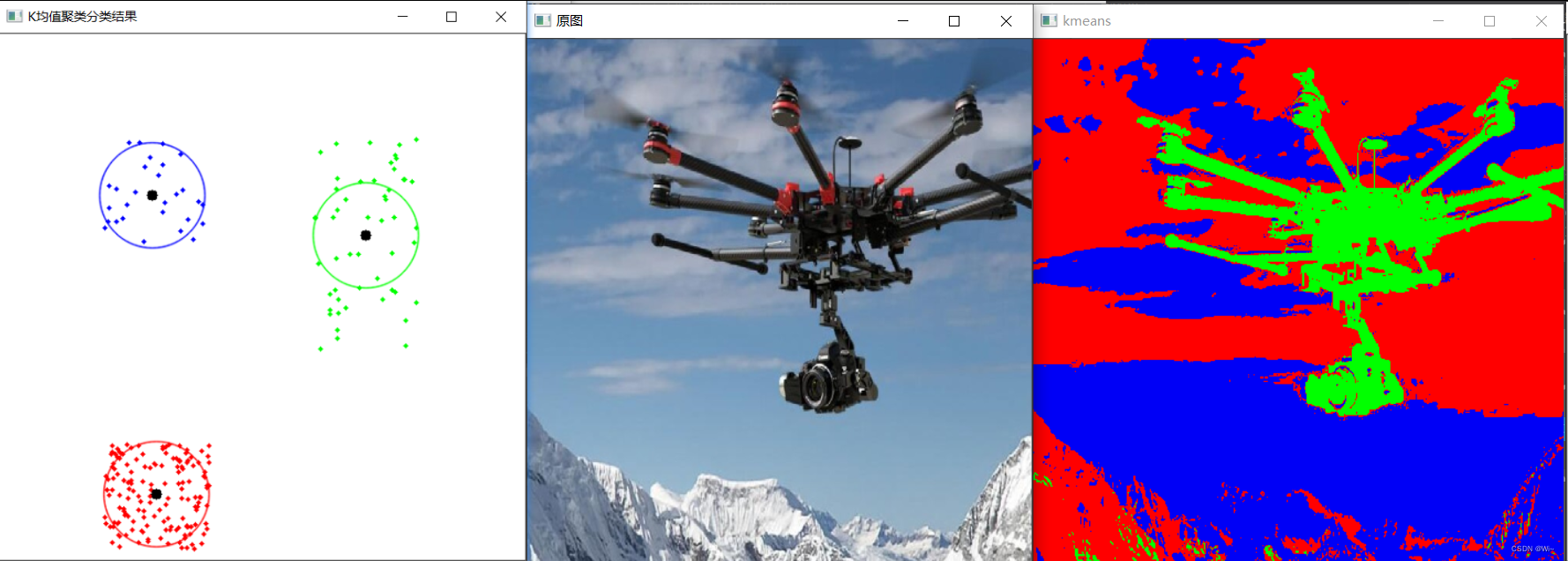
cout << "第" << i + 1 << "类的中心坐标:x=" << x << " y=" << y << endl;
circle(img, Point(x, y), 50, colorLut[i], 1, LINE_AA);
circle(img, Point(x, y), 5,Scalar(0,0,0), -1);
}
imshow("K均值聚类分类结果", img);
waitKey(0);
//kmeans 用于图像分割处理
Mat img2 = imread("fly.jpg");
if (!img2.data)
{
cout << "请确认图像文件是否输入正确";
return -1;
}
//k这里选值 0-5
Vec3b colorLut2[5] =
{
Vec3b(0,0,255),
Vec3b(0,255,0),
Vec3b(2550,0,0),
Vec3b(0,255,255),
Vec3b(255,0,255)
};
//图像尺寸,用于计算图像中像素点的数目
int width = img2.cols;
int height = img2.rows;
//初始化定义
int sampleCount = width * height;
//将图像矩阵数据成每行数据的特征形式,用于k均值聚类处理
Mat sample_data = img2.reshape(0, sampleCount);
Mat data;
sample_data.convertTo(data, CV_32F);
//k均值聚类
int number2 = 3;
Mat labels2;
kmeans(data,number2,labels2, TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1), 3, KMEANS_PP_CENTERS, centers);
//图像显示分割结果
Mat result = Mat::zeros(sample_data.size(), img2.type());
for (int row = 0; row < height*width; row++)
{
int label = labels2.at<int>(row, 0);
result.at<Vec3b>(row, 0) = colorLut2[label];
}
result = result.reshape(0, height);
namedWindow("原图", WINDOW_NORMAL);
imshow("原图", img2);
namedWindow("kmeans", WINDOW_NORMAL);
imshow("kmeans", result);
waitKey(0);
return 0;
}
深度神经网络
cv::dnn::readNet 读取深度学习模型
cv::dnn::readNet 是 OpenCV 中用于加载深度学习模型的函数。它可以从文件中读取训练好的模型,并返回一个可用于推断(inference)的网络对象。
函数原型如下:
cv::dnn::Net cv::dnn::readNet(
const cv::String& model,
const cv::String& config = "",
const cv::String& framework = ""
);
参数说明:
model:指定要加载的模型的路径。通常是模型的权重文件(如.caffemodel、.pb、.t7等)。config:指定模型的配置文件路径。对于某些框架,模型的结构信息可能会单独存储在一个配置文件中,此参数用于指定该配置文件的路径。对于其他框架,可以为空字符串。framework:指定用于训练模型的框架。通常情况下,OpenCV 可以自动检测框架类型,所以这个参数可以为空字符串。如果模型是用 Caffe 训练的,则可以指定"Caffe";如果模型是用 TensorFlow 训练的,则可以指定"TensorFlow"。根据不同的框架类型,函数将使用相应的后端来加载模型。
-返回值是一个 cv::dnn::Net 对象,表示加载的深度学习网络模型。
使用 cv::dnn::readNet 函数加载模型的示例如下:
cv::dnn::Net net = cv::dnn::readNet("model.weights", "model.cfg", "Caffe");
这将加载 model.weights 和 model.cfg 文件,并使用 Caffe 后端构建深度学习网络。
加载模型后,你可以使用 cv::dnn::Net 对象进行图像推断(inference),例如通过前向传播(forward pass)将图像输入网络,并获取网络的输出结果。
请注意,在使用 cv::dnn::readNet 函数之前,你需要确保 OpenCV 的深度学习模块已经正确安装并配置。
cv::dnn::blobFromImage 图像转换为深度学习网络接受的输入格式(单个图片)
cv::dnn::blobFromImages(多张图片)
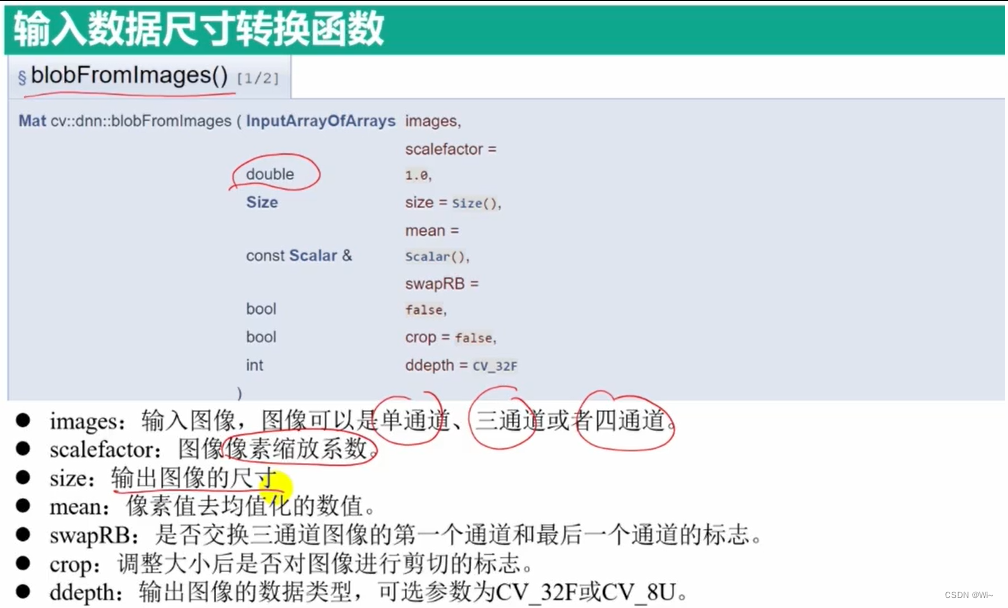
cv::dnn::blobFromImage 是 OpenCV 中深度学习模块(dnn)中的一个函数,用于将图像转换为深度学习网络接受的输入格式,即 blob(Binary Large Object)。它的详细解释如下:
Mat cv::dnn::blobFromImage(
InputArray image, // 输入单个图像
double scalefactor=1.0, // 缩放因子
const Size& size=Size(), // 目标大小
const Scalar& mean=Scalar(),// 均值
bool swapRB=false, // 交换红蓝通道
bool crop=false , // 裁剪图像
int ddepth = CV_32F // 输出 blob 的深度
)
Mat cv::dnn::blobFromImages(
InputArrayOfArrays images, // 输入n张图像
double scalefactor=1.0, // 缩放因子
const Size& size=Size(), // 目标大小
const Scalar& mean=Scalar(),// 均值
bool swapRB=false, // 交换红蓝通道
bool crop=false , // 裁剪图像
int ddepth = CV_32F // 输出 blob 的深度
)
image: 输入图像。可以是cv::Mat类型或者cv::UMat类型的对象,表示要进行处理的原始图像。scalefactor: 缩放因子。通过该因子对输入图像进行缩放,默认为1.0,表示不进行缩放。如果想要对图像进行缩放,可以设置一个小于1的值,例如0.5表示缩小一半,2.0表示放大一倍。size: 目标大小。指定图像的目标尺寸,该函数会将输入图像调整到指定的尺寸。如果未指定目标尺寸(默认构造的cv::Size()),则函数不会调整图像的尺寸。。对于大多数当前最先进的神经网络,这是 224×224、227×227 或 299×299。mean: 这是我们要减去的均值,可以是R,G,B均值三元组,或者是一个值,每个通道都减这值。如果执行减均值,通道顺序是R、G、B。 如果,输入图像通道顺序是B、G、R,那么请确保swapRB = True,交换通道。如果未指定均值(默认构造的cv::Scalar()),则函数不会对图像进行均值处理。swapRB: 交换红蓝通道。默认情况下,OpenCV认为图像 通道顺序是B、G、R,而减均值时顺序是R、G、B,为了解决这个矛盾,设置swapRB=True即可。crop: 裁剪图像。默认情况下,函数会对图像进行中心裁剪,以使其适应网络的输入尺寸。如果crop裁剪为真,则调整输入图像的大小,使调整大小后的一侧等于相应的尺寸,另一侧等于或大于。然后,从中心进行裁剪。如果“裁剪”为“假”,则直接调整大小而不进行裁剪并保留纵横比。ddepth:可选参数,指定输出 blob 的深度。默认值为 CV_32F,表示输出 blob 的深度为 32 位浮点数。
函数返回4D矩阵(没有定义行/列值,因此这些值为-1)。表示转换后的 blob。
返回的blob是一个四维矩阵,其形状为 `(N, C, H, W)`,其中:
- `N` 表示 blob 的数量,通常为 1。
- `C` 表示通道数,即图像的颜色通道数,例如 RGB 图像的通道数为 3。
- `H` 表示 blob 的高度(或行数)。
- `W` 表示 blob 的宽度(或列数)。
这个函数的作用是将输入图像进行预处理,并将其转换为适合深度学习模型输入的格式。它执行以下操作:
1. 图像的大小调整:根据指定的 `size` 参数,将图像的尺寸调整为指定大小。
2. 图像的均值减法:根据指定的 `mean` 参数,对图像的每个像素进行均值减法操作。
3. 图像的像素值缩放:根据指定的 `scalefactor` 参数,对图像的像素值进行缩放操作。
4. 图像的通道交换:根据指定的 `swapRB` 参数,交换图像的颜色通道。
这样处理后的图像被存储在返回的blob中,可以直接作为深度学习模型的输入。通常情况下,将返回的blob作为输入传递给深度学习模型的`forward`函数进行推理或训练。
注意:
-
当同时进行scalefactor,size,mean,swapRB操作时,优先按swapRB交换通道,其次按scalefactor比例缩放,然后按mean求减,最后按size进行resize操作
-
当进行减均值操作时,ddepth不能选取CV_8U,否则报错:
OpenCV(4.1.2) D:\Build\OpenCV\opencv-4.1.2\modules\dnn\src\dnn.cpp:251: error: (-215:Assertion failed) mean_ == Scalar() && "Mean subtraction is not supported for CV_8U blob depth" in function 'cv::dnn::dnn4_v20190902::blobFromImages' -
当crop=True时,先等比例缩放,直至宽高尺寸一个等于对应的size尺寸,另一个大于或者等于对应的size尺寸,然后再从中心进行裁剪
使用 blobFromImage 函数可以将输入图像转换为深度学习网络接受的输入格式,便于进行预测或推理。转换后的 blob 可以作为深度学习模型的输入传递给 cv::dnn::Net::forward 函数进行预测。
注意:在使用该函数之前,需要确保已经加载了相应的深度学习模型,并使用 cv::dnn::Net 类进行初始化。
Net 类
cv::dnn::Net::setInput 输入数据设置为神经网络模型的输入
在OpenCV中,cv::dnn::Net::setInput函数用于将输入数据设置为神经网络模型的输入。它有几个不同的重载形式,但主要的作用是将输入数据加载到网络中进行推理。
下面是cv::dnn::Net::setInput函数的C++函数签名和参数详解:
void cv::dnn::Net::setInput(InputArrayOfArrays blob, const std::string& name = "")
参数解释:
blob:输入数据的blob(Binary Large Object)。它可以是多个blob的数组。blob是OpenCV中一种多维数组,用于存储图像、特征等数据。name:(可选参数)指定输入层的名称。如果模型有多个输入层,可以使用该参数指定要设置输入的特定层。
使用cv::dnn::Net::setInput函数的步骤如下:
- 创建一个
cv::dnn::Net对象,表示神经网络模型。 - 加载训练好的模型文件(如Caffe模型、TensorFlow模型等)到
cv::dnn::Net对象中。 - 准备输入数据,将其转换为适当的格式,如blob。
- 调用
cv::dnn::Net::setInput函数,将输入数据设置为网络模型的输入。
以下是一个示例,展示如何使用cv::dnn::Net::setInput函数将图像加载到神经网络模型中进行推理:
#include <opencv2/opencv.hpp>
int main()
{
// 创建网络模型
cv::dnn::Net net;
// 加载训练好的模型文件
net = cv::dnn::readNetFromCaffe("model.prototxt", "model.caffemodel");
// 加载图像
cv::Mat image = cv::imread("image.jpg");
// 将图像转换为blob
cv::Mat blob = cv::dnn::blobFromImage(image, 1.0, cv::Size(224, 224), cv::Scalar(104, 117, 123));
// 设置输入数据
net.setInput(blob);
// 执行推理
cv::Mat output = net.forward();
// 处理输出结果...
return 0;
}
在这个示例中,我们首先创建了一个cv::dnn::Net对象,然后加载了一个Caffe模型文件。接下来,我们使用cv::imread函数加载了一张图像,并使用cv::dnn::blobFromImage函数将图像转换为blob格式。最后,我们调用cv::dnn::Net::setInput函数将blob设置为网络模型的输入。然后,我们可以调用cv::dnn::Net::forward函数执行推理,并对输出结果进行处理。

cv::dnn::Net::forward 前向传播
cv::dnn::Net::forward是OpenCV中用于执行深度神经网络(DNN)前向传播的函数。它将输入数据传递给网络,并返回网络输出。以下是该函数的详细说明:
cv::Mat cv::dnn::Net::forward(const cv::String &outputName = cv::String())
参数:
outputName(可选):指定要检索的网络输出层的名称。如果未提供outputName,则返回所有输出层的结果。
返回值:
cv::Mat:返回一个cv::Mat对象,其中包含网络的输出结果。
函数返回的是一个四维矩阵(或称为四维张量)。
这个四维矩阵通常表示卷积神经网络(Convolutional Neural Network, CNN)的输出,也被称为特征图(feature maps)。
四维矩阵的维度通常被定义为`(batch_size, num_channels, height, width)`,其中:
- `batch_size`表示批处理的大小,即一次输入的样本数量。(如果为1 表示1个样本)
- `num_channels`表示特征图的通道数,也可以理解为特征图的深度或特征提取器的数量。
- `height`和`width`表示特征图的高度和宽度。
这样的四维矩阵可以同时处理多个输入样本,并且每个样本可以有多个通道的特征图。你可以通过对返回的四维矩阵使用相应的索引来获取特定样本和通道的特征图数据。
在最后一维,开始依次是:图片序号,标签、置信度、目标位置的4个坐标信息[xmin ymin xmax ymax]
包含了以下信息:
- 类别标签(label):表示检测到的目标所属的类别。这通常是一个整数值,对应于模型所识别的不同类别。
- 置信度(confidence):表示模型对于该检测结果的置信度或概率得分。一般情况下,该值介于0和1之间。
- 目标位置的边界框信息(bounding box):表示检测到的目标在图像中的位置。这通常由四个坐标值描述,即边界框的左上角和右下角的坐标[xmin, ymin, xmax, ymax]。
如果你使用的是一个特定的目标检测模型,你可以参考该模型的文档或网络结构来了解每个特定输出维度的含义。不同的模型可能会有不同的输出格式和含义。
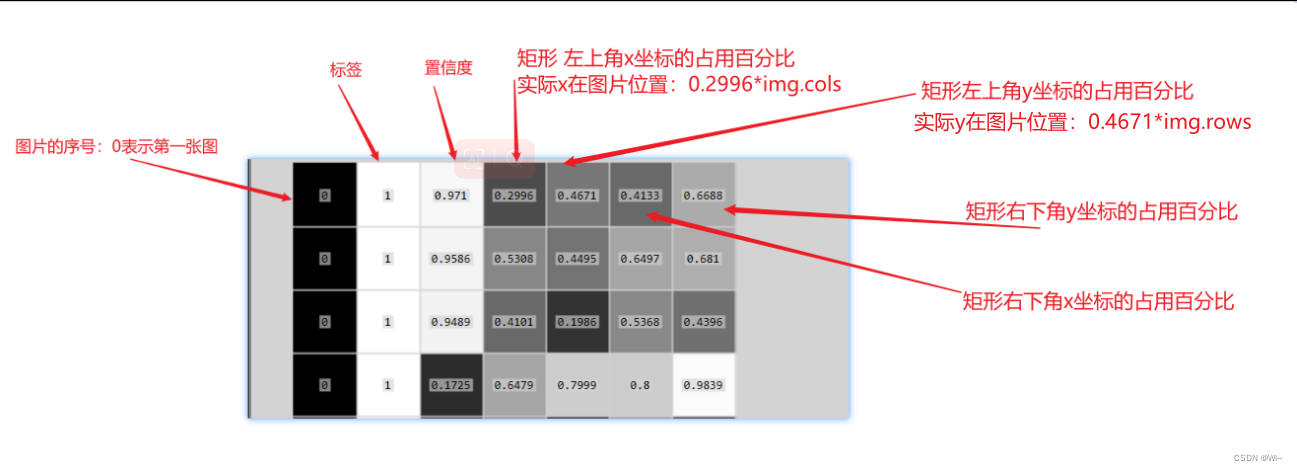
功能:
- 执行网络的前向传播,并返回网络输出。
在使用cv::dnn::Net::forward函数之前,必须先加载和构建网络模型。这通常包括加载模型的配置文件和权重文件,并使用它们来构建网络。一旦网络加载和构建完成,就可以使用forward函数来进行前向传播。
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/opencv.hpp>
#include <fstream>
#include <opencv2/ximgproc.hpp> // 需要添加OpenCV扩展库
#include <opencv2/ml.hpp>
#include <cmath>
#include <locale>
#include <codecvt>
#include <string>
using namespace cv;
using namespace std;
using namespace ml;
using namespace cv::dnn;
int main()
{
system("color F0");
string model = "age_net.caffemodel";
string config = "age_deploy.prototxt";
//加载模型
Net net = dnn::readNet(model, config);
if (net.empty())
{
cout << "请确认是否输入空的模型文件" << endl;
return -1;
}
//获取各层信息
vector<String> layerNames = net.getLayerNames();
for (int i = 0; i < layerNames.size(); i++)
{
//读取每层网络的ID
int ID = net.getLayerId(layerNames[i]);
//读区每层网络的信息
Ptr<Layer> layer = net.getLayer(ID);
//权重 和 偏置 vector<Mat> ddd = layer->blobs;
//Mat weights = net.getParam(layerNames[i], 0);
//Mat biases = net.getParam(layerNames[i], 1);
cout << "网络层数:" << ID << "网络层名称:" << layerNames[i] << endl;
cout << "网络层类型:" << layer->type << endl;
vector<Mat> ddd = layer->blobs;
}
waitKey(0);
return 0;
}
网络层数:1网络层名称:conv1
网络层类型:Convolution
网络层数:2网络层名称:relu1
网络层类型:ReLU
网络层数:3网络层名称:pool1
网络层类型:Pooling
网络层数:4网络层名称:norm1
网络层类型:LRN
网络层数:5网络层名称:conv2
网络层类型:Convolution
网络层数:6网络层名称:relu2
网络层类型:ReLU
网络层数:7网络层名称:pool2
网络层类型:Pooling
网络层数:8网络层名称:norm2
网络层类型:LRN
网络层数:9网络层名称:conv3
网络层类型:Convolution
网络层数:10网络层名称:relu3
网络层类型:ReLU
网络层数:11网络层名称:pool5
网络层类型:Pooling
网络层数:12网络层名称:fc6
网络层类型:InnerProduct
网络层数:13网络层名称:relu6
网络层类型:ReLU
网络层数:14网络层名称:drop6
网络层类型:Dropout
网络层数:15网络层名称:fc7
网络层类型:InnerProduct
网络层数:16网络层名称:relu7
网络层类型:ReLU
网络层数:17网络层名称:drop7
网络层类型:Dropout
网络层数:18网络层名称:fc8
网络层类型:InnerProduct
网络层数:19网络层名称:prob
网络层类型:Softmax
代码演示:
int main()
{
system("color F0");
Mat img = imread("face.jpg");
Mat img1 = imread("persons.png");
Mat img2 = imread("master.jpg");
if (img.empty() || img1.empty() || img2.empty())
{
cout << "请确定是否输入正确的图像文件" << endl;
return -1;
}
//读取人脸识别模型
string model = "face_model/res10_300x300_ssd_iter_140000_fp16.caffemodel";
string config = "face_model/deploy.prototxt";
//加载模型
Net faceNet = dnn::readNet(model, config);
if (faceNet.empty())
{
cout << "请确认是否输入空的模型文件" << endl;
return -1;
}
vector<Mat> imgs;
imgs.push_back(img);
imgs.push_back(img1);
imgs.push_back(img2);
//对整幅图像进行人脸检测
Mat blobImage = blobFromImages(imgs, 1.0, Size(300, 300), Scalar(), false, false);
/*
返回的blob是一个四维矩阵,其形状为 `(N, C, H, W)`,其中:
- `N` 表示 blob 的数量,通常为 1。1 :表示1张图片,3:表示3张图片
- `C` 表示通道数,即图像的颜色通道数,例如 RGB 图像的通道数为 3。
- `H` 表示 blob 的高度(或行数)。
- `W` 表示 blob 的宽度(或列数)。
*/
//std::cout << "size[0]:" << blobImage.size[0] << std::endl;//3张图片
//std::cout << "size[1]:" << blobImage.size[1] << std::endl;//3个通道
//std::cout << "size[2]:" << blobImage.size[2] << std::endl;//300高度
//std::cout << "size[3]:" << blobImage.size[3] << std::endl;//300宽度
faceNet.setInput(blobImage, "data");
Mat detect = faceNet.forward("detection_out");
std::cout << "size[0]:" << detect.size[0] << std::endl;//1
std::cout << "size[1]:" << detect.size[1] << std::endl;//1
std::cout << "size[2]:" << detect.size[2] << std::endl;//200
std::cout << "size[3]:" << detect.size[3] << std::endl;//7
//detect.ptr<float>(0) == detect.ptr<float>();
//人脸概率 人脸矩形区域的位置 ; 提取detect中的数据
Mat detectionMat(detect.size[2], detect.size[3], CV_32F, detect.ptr<float>(0));
//对每个人脸区域进行性别检测
int exBoundray = 25;//对每个人脸区域四个方向扩充的尺寸
float confidenceThreshold = 0.5; //判定为人脸的概率阈值,阈值越大准确性越高
//人脸数据个数
for (int i = 0; i < detectionMat.rows; i++)
{
//检测为人脸的概率
float confidence = detectionMat.at<float>(i, 2);
//只检测概率大于阈值区域的性别
if (confidence > confidenceThreshold)
{
//imgs[(int)detectionMat.at<float>(i, 1)] 获取目前判断的图片
//网络检测人脸区域的大小
//矩形的左上角
int imgsSerial = (int)detectionMat.at<float>(i, 0);
int topLx = static_cast<int>(detectionMat.at<float>(i, 3) * imgs[imgsSerial].cols);
int topLy = static_cast<int>(detectionMat.at<float>(i, 4) * imgs[imgsSerial].rows);
//矩形的右上角
int bottomRx = static_cast<int>(detectionMat.at<float>(i, 5) * imgs[imgsSerial].cols);
int bottomRy = static_cast<int>(detectionMat.at<float>(i, 6) * imgs[imgsSerial].rows);
//矩形
Rect faceRect(topLx, topLy, bottomRx - topLx, bottomRy - topLy);
rectangle(imgs[imgsSerial], faceRect, Scalar(0, 0, 255), 2, 8, 0);
}
}
//显示结果
for (int i = 0; i < imgs.size(); i++)
{
imshow("检测结果"+to_string(i), imgs[i]);
}
waitKey(0);
return 0;
}



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









