







一、SfM的认识
-
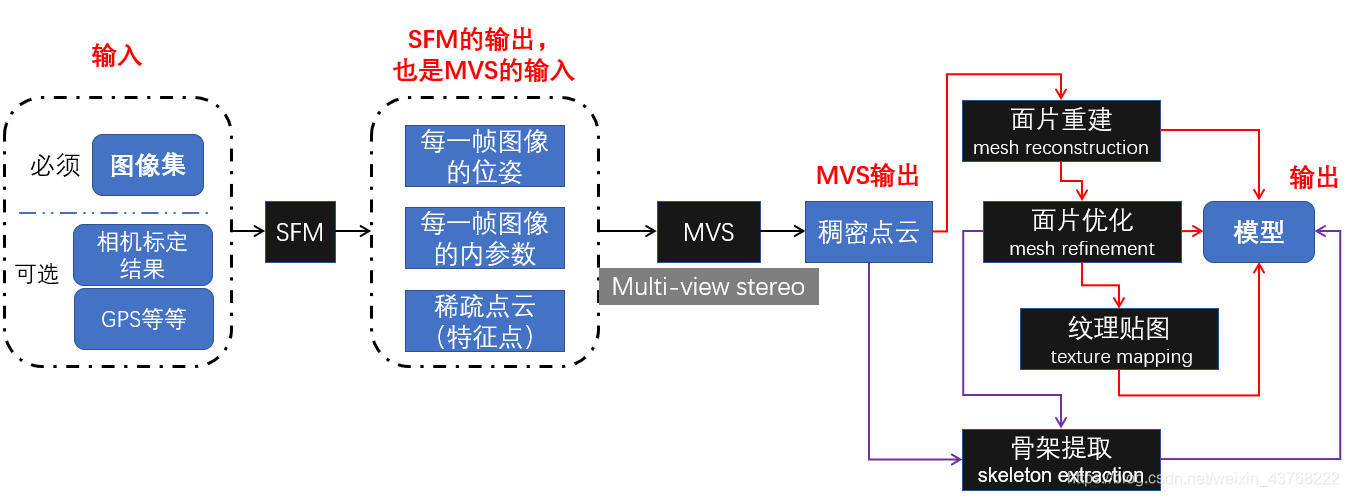
三维重建=图像序列+SfM+MVS+…
图像序列:拍摄多视图照片集
SfM:能求出每个图像的参数(包括内参和外参),还有稀疏三维结构
MVS:是基于SfM的输出下,进行稠密化。
还有后续的曲面重建等等。
三维重建:综述 链接1,链接2;项目链接
开源的sfm可以参考colmap,mvs可以参考openmvs,3D模型可视化可以用meshlab。
整体论文阅读入门综述:《Multi-View Stereo: A Tutorial》
三维重建,sfm、mvs等之间的关系图:
-
SfM,全称:structure from motion
意思就是运动能够恢复结构,1985年由Hartley等人提出,能够从图像序列中恢复场景或对象的结构信息。以下针对可见光RGB相机。 -
两种情况
主要分为两种情况:a)相机运动、场景(物体)不动,b)相机不动、场景(物体)运动。前者效果会更好些,因为如果场景或物体是非刚性的情况下,自身运动会带来扭曲偏移等。例如,重建植物时,植物的叶子可能会抖动,非常不利于三维重建。 -
现状
目前,SfM已经应用很多,重建结果也不错。也有难点:细节(硬件是个主要因素;也看过一些关于细长枝条的重建,很强)、非刚性、运动状态、大场景。还有万物皆可深度学习的情况下,三维重建也可以用深度学习来实现。 -
分类
SfM的 分类:增量式(incremental/sequential),全局式(global),混合式(hybrid),层次式(hierarchical),基于语义的SfM(Semantic SfM)。
以下都是增量式SfM
二、SfM的初始化
-
图像特征点的提取与匹配
一般就是sift -
初始化图像对的选择
一般选择具有最多匹配数目的图像对,而且这些匹配不能由单个单应矩阵很好地建模(主要是避免两张图像接近重合的情况,因为这样基线会很短,不利于三角化)。
使用RANSAC以max(w, h) * 0.4%的离群值阈值找到每对匹配图像之间的单应性,存储与估计的单应性更接近的特征匹配的百分比。选择初始图像对作为对恢复的单应性具有最低百分比的图像对,但是具有至少100个匹配项。此钳位函数的效果是,重投影误差大于16.0像素的所有点将被作为异常值拒绝,而重投影误差小于4.0的所有点将被保留为内值,确切的阈值位于这两个值之间。 -
使用五点法来估计这对相机的参数(外参)
(为什么可以用五点法呢,不是还需要内参K吗?),这里所需要的内参K由图像自带的EXIF提供(包括焦距、像素、镜头型号等),这些作为K的初始值。用五点法,可以估计出R和t。 -
三角测量
有了内参、外参,就可以将两幅图像中可见的轨迹(也就是匹配点)进行。 -
捆绑调整
内参是粗糙,五点法的结果也不一定好。就需要进行两帧捆绑调整。在每次运行优化后,会检测包含至少一个具有较高重投影误差的关键点的离群点轨迹,并将这些轨迹从优化中删除。其中,离群点阈值:计算该图像的重投影误差的第80个百分位数,并使用 m i n ( m a x ( ( 2.4 D 80 , 4.0 ) , 16.0 ) min(max((2.4D_{80},4.0),16.0) min(max((2.4D80,4.0),16.0) 作为离群值阈值。在拒绝异常值之后,重新运行优化,直到没有检测到更多的异常值。 -
(优化中还有很多细节,可以参见文献[2])
三、SfM的实现
上述中,没提到图像的畸变;这里会引入。文献[3]提到,有相关商用软件(PTLens)可以去畸变,利用EXIF的相机和镜头信息,如果有图像是无效去畸变,则提剔除该图像。也有文献写到,把畸变纳入SfM中,如文献[2]。
以下内容参见[2][4]。
1、投影变换矩阵
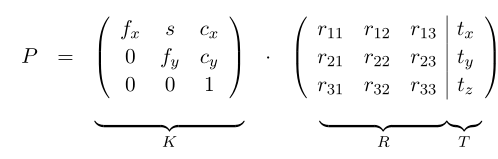
K里面5个参数,R里面3个,T也是3个。所以一共需要估计11个参数。其中,
s
s
s是skew的意思,一般为0;并且假设
f
x
=
f
y
f_x=f_y
fx=fy(因为像素物理尺寸一般是正方形的,例如
3.0
μ
m
×
3.0
μ
m
3.0\mu m × 3.0\mu m
3.0μm×3.0μm),
(
c
x
,
c
y
)
(c_x,c_y)
(cx,cy)是图像中心(根据像素个数就能算出来),所以需要估计的参数变为了7个。当把径向畸变考虑进来时,引入2个系数
κ
1
,
κ
2
\kappa_1,\kappa_2
κ1,κ2。最终,需要估计的参数是9个。
旋转矩阵,可以用旋转向量表示。由旋转向量变换到旋转矩阵R,可由罗德里格斯公式表示
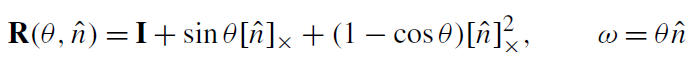
向量的反对称形式:
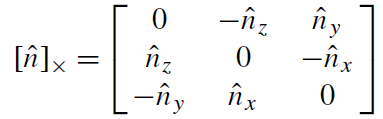
Θ
=
[
ω
,
c
,
f
,
κ
1
,
κ
2
]
\Theta=[\omega,c,f,\kappa_1,\kappa_2]
Θ=[ω,c,f,κ1,κ2],其中
c
c
c就是平移向量,只不过不同文献有不同写法,这里面把它看作了相机光心在世界坐标系的坐标(coordinate),就简写为了
c
c
c
需要估计的参数,都已经列出来了。
2、投影过程
- track说明

这是论文中对tracks的说明:就是tracks是个集合;track是其中一个元素,里面放着一个三维点与不同图像上对应的2D投影点的关系。
关于轨迹(迹)track的个人理解,一个三维点,可能会同时被多张图像所拍到。下面是一条track的示意图,可以理解为一个二维数组。track就是一个3D点在不同图像中对应的特征点所连成的一条链子吧。
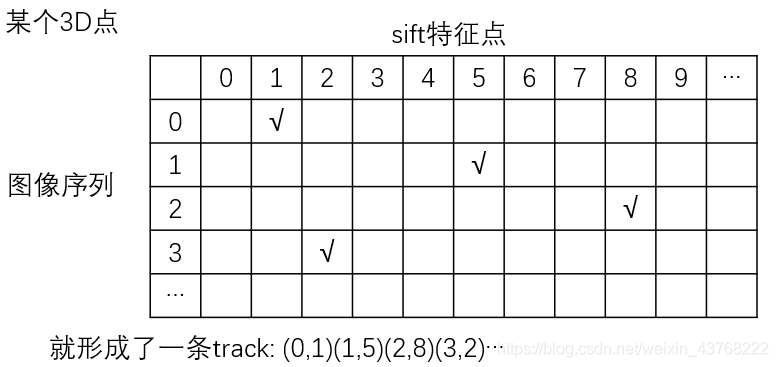
- 参数说明
Θ i \Theta_i Θi表示某张图像(相机)的参数(包含内外参);
X j X_j Xj表示m条tracks中第j条track在 Θ i \Theta_i Θi下的3D点坐标;
P ( Θ , X ) P(\Theta,X) P(Θ,X)表示一个投影过程;
q i j q_{ij} qij表示3D点 X j X_j Xj在图像 Θ i \Theta_i Θi中的像素点;理论上3D点会完美投影到像素点,但是噪声、误差等因素导致不可能出现。 - 公式推导
懒得打公式了,直接截图了,公式推导可以参见文献Modeling the World from Internet Photo Collections。不排除有一些细节,我没展示出来(狗头)
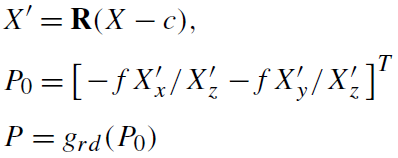
第三条公式的 g r d ( P 0 ) g_{rd}(P_0) grd(P0)表示畸变方程。由下面公式描述该过程:
To map a projected 2D point p = ( p x , p y ) p = (p_x,p_y ) p=(px,py) to a distorted point p ′ = ( x ′ , y ′ ) p^{'} = (x^{'} , y^{'}) p′=(x′,y′), we use the formula: (把一个图像的点投影到畸变点,用下面的公式)
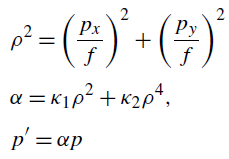
一般 κ 1 , κ 2 \kappa_1,\kappa_2 κ1,κ2会初始化为0,为防止过大,还会在优化函数(后面会讲到)中加入一项 λ ( κ 1 2 + κ 2 2 ) \lambda(\kappa_1^2+\kappa_2^2) λ(κ12+κ22), λ \lambda λ取10.0。
至此,就能把3D点与图像上的2D联系起来。
3、参数初始估计
- 直接线性变换DLT
是利用3D-2D点(至少6组),可以估计外部参数以及一个上三角矩阵K,这些参数用于最小化重投影误差的优化函数中的初始值。 - 问题:此时K有两个初始值?
该怎么抉择?内参主要是 f f f。
对于直接线性变换DLT返回的内参 K 1 K_1 K1的 f 1 = ( K 11 + K 22 ) / 2 f_1=(K_{11}+K_{22})/2 f1=(K11+K22)/2。
对于图像自带EXIF的 f 2 f_2 f2,当满足 0.7 f 1 < f 2 < 1.4 f 1 0.7f_1<f_2<1.4f_1 0.7f1<f2<1.4f1时,就用 f 2 f_2 f2,否则就用 f 1 f_1 f1。
当使用 f 2 f_2 f2时,需要在优化函数中添加一项 γ ( f − f 2 ) 2 \gamma(f-f_2)^2 γ(f−f2)2, γ \gamma γ取0.001,目的是让结果接近 f 2 f_2 f2。
4、最小化重投影误差
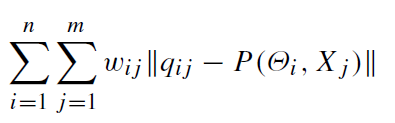
就是要最小化上面的函数,其中
ω
i
j
\omega_{ij}
ωij表示有这个三维点和该帧图像二维点对应时(也就是说这帧图像看到了这个3D点),它就是1,否则就为0。
具体的最小化投影误差过程,网上有一些介绍,就不展开了。
至此,完结!
注意
该博文,并没有详尽描述每一个实现步骤的细节,因为在具体实现中,还有很多考虑的因素,上述的过程是在理想化前提下进行的。有兴趣深入了解的,一定要去看原文献,收益良多。而且,下面的文献都比较老了,现在已经很多优化了,要紧跟潮流呀。
参考文献
[1] Noah, Snavely, Steven, et al. Photo tourism: exploring photo collections in 3D[J]. Acm Transactions on Graphics, 2006.
[2] Snavely N , Seitz S M , Szeliski R . Modeling the World from Internet Photo Collections[J]. International Journal of Computer Vision, 2008, 80(2):189-210.
[3] Goesele M , Snavely N , Curless B , et al. Multi-View Stereo for Community Photo Collections[C]// Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on. IEEE, 2007.
[4] Furukawa Y , C Hernández. Multi-View Stereo: A Tutorial[M]. Now Publishers Inc. 2015.

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









