









本文首发于博客 LLM 应用开发实践
RAG(Retrieval Augmented Generation)是一种检索增强生成技术,它利用大型语言模型来处理用户查询,RAG 技术的主要组成包括数据提取—embedding—创建索引—检索—排序(Rerank)—LLM 归纳生成,不过实际落地过程来看,将用户查询转换为嵌入向量直接检索,很多时候的结果在相关度方面没有那么理想,本篇分享一种对用户查询进行重写再去进行检索从而提高准确性和召回率的方案。
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读!

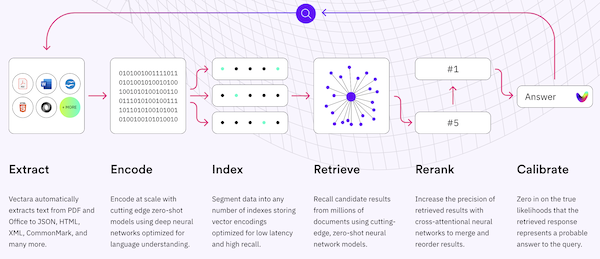
直接检索的问题
将用户查询转换为嵌入向量直接检索会出现下面四类常见问题 👇:
查询结果不匹配
模型假设查询 embedding 和内容 embedding 在嵌入空间中是相似的,但基于要搜索的文本,匹配度不一定是最优的,仅仅靠内容在语义上相似的查询出的结果并不理想。
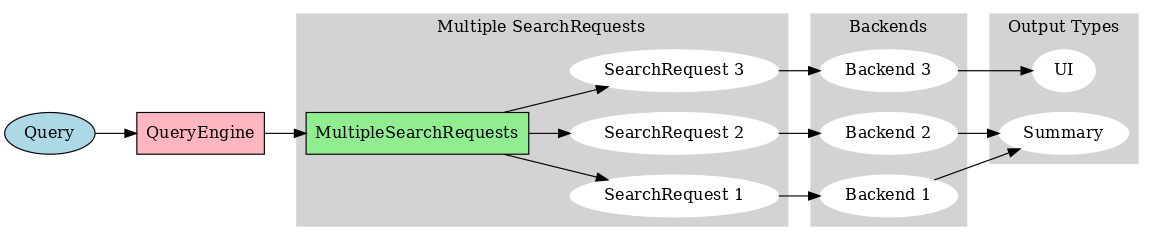
单一搜索后端
实际情况可能有多个搜索后端,每个后端都有自己的 API,可以考虑将查询路由到向量存储、搜索客户端、SQL 数据库等等。
文本搜索的局限性
文本搜索的限制是它仅限于单个字符串的复杂查询,牺牲了表达能力,无法使用关键词、过滤器和其他高级功能。例如,通过简单的文本搜索无法回答“我们上周解决了哪些问题”,因为包含的关键词"问题"和"上周"的将在所有文档范围都存在。
有限的规划能力
假设查询是搜索后端的唯一输入,无法使用其他信息来改善搜索。
解决方案
将自然语言查询通过大语言模型转换为优化后的自定义查询语句,最终能够高效理解达到提高准确性和召回率的目的。
案例一
比如搜索 “人工智能有哪些最新发展”,通过系统内部限定发布日期范围和搜索域列表的方式重写查询。
class DateRange(BaseModel):
start: datetime.date
end: datetime.date
class MetaphorQuery(BaseModel):
rewritten_query: str
published_daterange: DateRange
domains_allow_list: List[str]
async def execute():
return await metaphor.search(...)
import instructor
import openai
# Enables response_model in the openai client
instructor.patch()
query = openai.ChatCompletion.create(
model="gpt-4",
response_model=MetaphorQuery,
messages=[
{
"role": "system",
"content": "You're a query understanding system for the Metafor Systems search engine. Here are some tips: ..."
},
{
"role": "user",
"content": "What are some recent developments in AI?"
}
],
)
重写后的查询内容为在arxiv上搜索最近三个月带有 最新进展 先进人工智能 机器学习 几个关键字的论文,通过限定条件限制了查询范围,提高查询精度
{
"rewritten_query": "novel developments advancements ai artificial intelligence machine learning",
"published_daterange": {
"start": "2023-10-12",
"end": "2021-07-12"
},
"domains_allow_list": ["arxiv.org"]
}
案例二
个人助理的例子,当你问智能助理"我今天有什么事情要做?",从一个模糊的查询中可能需要获取事件、邮件、提醒等,这些数据可能存在于多个后端,但你想要的是一个统一的结果汇总,这种场景下不能假设这些相关的文本都嵌入在一个搜索后端中,可能会有一个日历客户端、邮件客户端等等。
class ClientSource(enum.Enum):
GMAIL = "gmail"
CALENDAR = "calendar"
class SearchClient(BaseModel):
query: str
keywords: List[str]
email: str
source: ClientSource
start_date: datetime.date
end_date: datetime.date
async def execute(self) -> str:
if self.source == ClientSource.GMAIL:
...
elif self.source == ClientSource.CALENDAR:
...
class Retrival(BaseModel):
queries: List[SearchClient]
async def execute(self) -> str:
return await asyncio.gather(*[query.execute() for query in self.queries])
import instructor
import openai
# Enables response_model in the openai client
instructor.patch()
retrival = openai.ChatCompletion.create(
model="gpt-4",
response_model=Retrival,
messages=[
{"role": "system", "content": "You are Jason's personal assistant."},
{"role": "user", "content": "What do I have today?"}
],
)
重写后的查询为今天的邮件和日程表上有会议、电话、zoom等关键字的内容,通过查询列表路由到不同的搜索后端(电子邮件和日历),异步分发,也可以提高性能
{
"queries": [
{
"query": None,
"keywords": None,
"email": "jason@example.com",
"source": "gmail",
"start_date": "2023-10-12",
"end_date": None
},
{
"query": None,
"keywords": ["meeting", "call", "zoom"],
"email": "jason@example.com",
"source": "calendar",
"start_date": "2023-10-12",
"end_date": None
}
]
}
结语
能够实现这一切,得益于开源项目 instructor,封装了复杂的建模过程,拿来即用即可。 本文参考自 RAG is more than just embedding search
更多内容在公号

















 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









