




 本文通过kmeans聚类对淘宝用户行为进行分析,将用户分为5类,包括纯浏览者、收藏爱好者、购物车活跃用户、潜在消费者和全面参与者。各类用户在点击、收藏、加购和购买上的比例各有特色,揭示了不同用户群体的行为习惯。
本文通过kmeans聚类对淘宝用户行为进行分析,将用户分为5类,包括纯浏览者、收藏爱好者、购物车活跃用户、潜在消费者和全面参与者。各类用户在点击、收藏、加购和购买上的比例各有特色,揭示了不同用户群体的行为习惯。
在上一篇文章,我们初步探讨了这份淘宝用户数据所体现的用户行为特点,具体说到一次淘宝行为是怎么开始的,怎么结束的,当中又涉及多少种,累计多少次小的动作。
本文将继续研究用户的行为特点,通过kmeans聚类将这些行为分为不同的类别,并归纳出各群特征。
依然将用户-商品-时间段-点击数-加购数-收藏数-购买数记为一次淘宝行为,统计周期过长过短都不能概括一次淘宝过程,我这里考虑建模代价与结果反馈选了1个月,具体请视实际情况和业务人员意见为定。
数据准备(用户-商品-时间段-点击数-加购数-收藏数-购买数的聚合计算)——聚类分析——结果展示——特征归纳,下面按这个顺序来。
-
数据准备
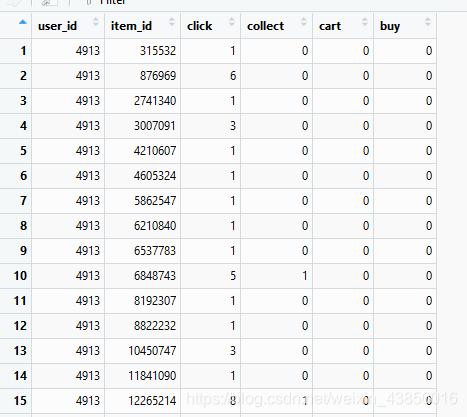
通过sqldf(聚合计算)+reshape2(一维表转二维表),原12256906x6的数据集变为5291166x4再变为4686904x6。
以第15行说明所得数据集的含义,这个月内,用户4913对商品12265214主页看了8次,收藏了1次,但没有加入购物车也没有下单购买。
-
聚类分析
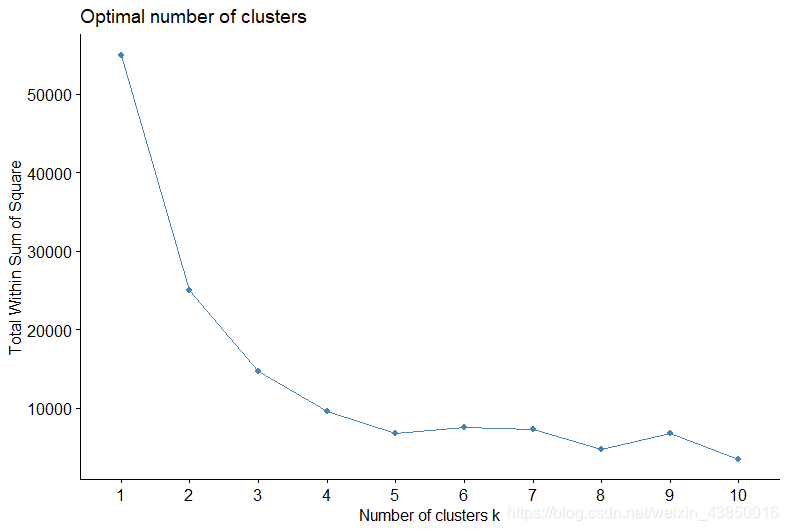
参与聚类的特征指标为一次淘宝行为中四种行为click、collect、cart和buy的占比,因为之前写过一篇关于聚类的文章,类别选择的原理就跳过,直接看结果,类别数为4、5都可以。
-
结果展示
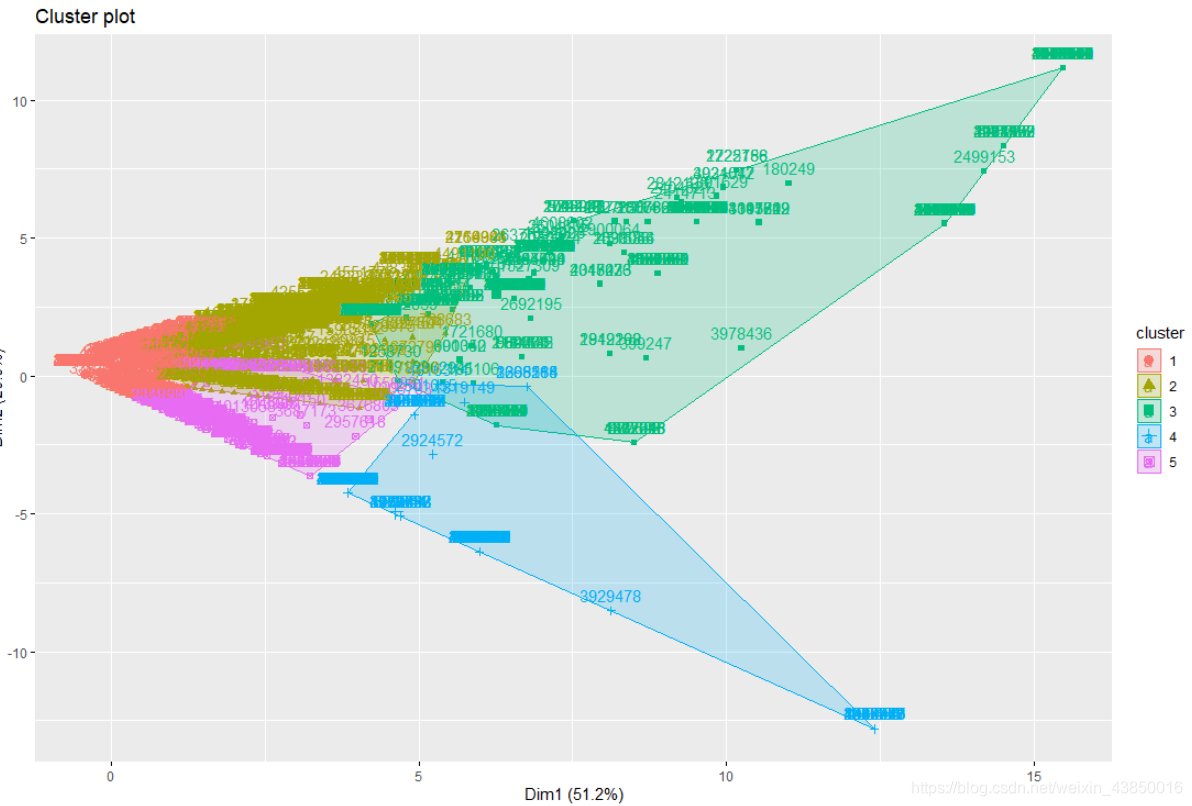
选取类别数为5。分类效果和每个类别的数量如图,阴影重合面积较少,意味着分类效果不错,其中第3类用户占了89.1%。

-
特征归纳
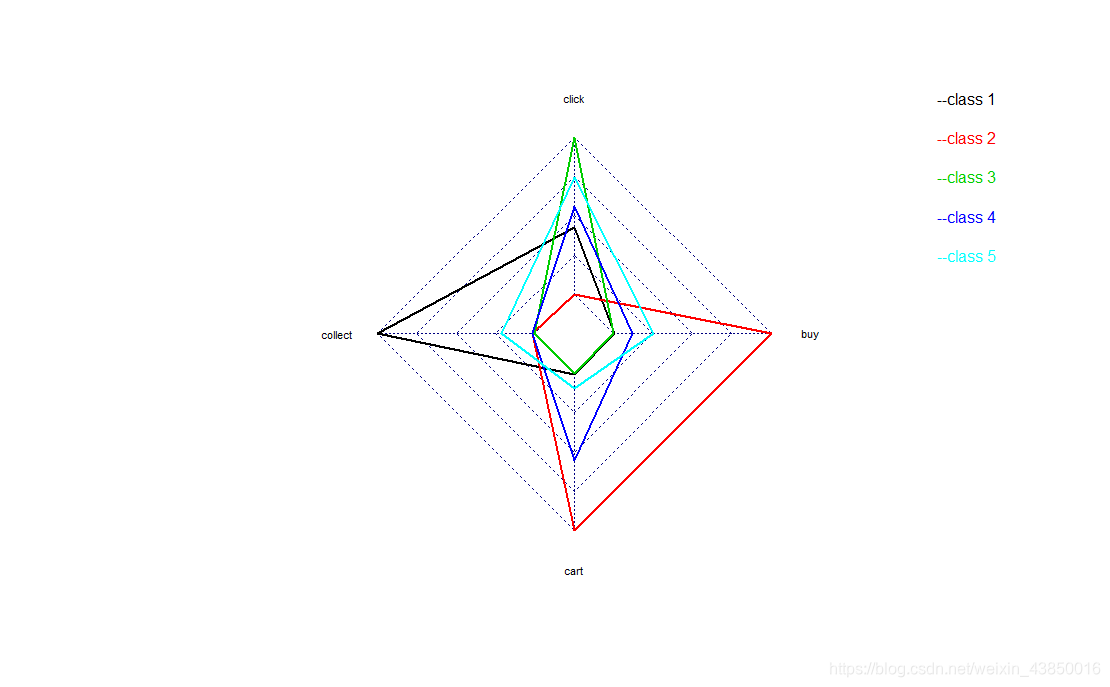
各个类别在四种行为click、collect、cart和buy上区分度很明显。
C1:特别喜欢将逛过的商品收藏起来
C2:加入购物车和购买的比例的比例都是最高
C3:只是单纯看看
C4:看和加入购物车的比例较高,但下单的比例很低
C5:相比C3,不仅看,也会收藏、加购、下单
dd<-read.csv('tianchi_mobile_recommend_train_user.csv')
library(sqldf)
library(gsubfn);library(proto);library(RSQLite)
#过程聚合计算
aa<-sqldf('select user_id,item_id,behavior_type,count(1) from dd
grou 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









