




【YOLO系列】YOLOv1详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv2详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv3详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv4详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv5详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv6详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv7详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv8详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv9详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv10详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv11详解:模型结构、损失函数、训练方法及代码实现
【YOLO系列】YOLOv12详解:模型结构、损失函数、训练方法及代码实现
YOLOv9 详细介绍
一、motivation
YOLOv9 的核心动机是解决目标检测中的三个关键问题:
- 信息瓶颈问题:深层网络导致浅层特征信息丢失,影响小目标检测精度
- 实时性瓶颈:在保持高精度的同时突破推理速度极限
- 多尺度适应性:提升模型对尺度变化的鲁棒性
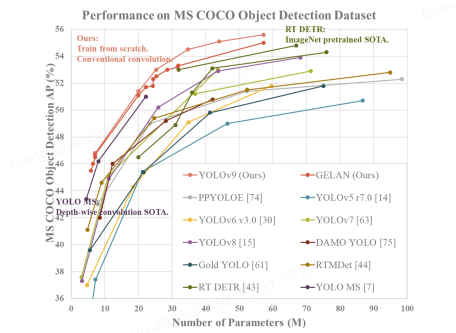
通过重新设计特征提取路径和优化计算范式,YOLOv9 在 MS COCO 数据集上实现了 ** 55.6% AP@0.5:0.95**,同时保持实时性能。
二、数据处理
采用多阶段增强策略:
# 数据增强示例
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomResizedCrop(640, 640, scale=(0.5, 1.0)),
A.HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30),
A.RandomBrightnessContrast(brightness_limit=0.2),
A.Cutout(num_holes=8, max_h_size=32, max_w_size=32) # 模拟遮挡
])
关键处理技术:
- Mosaic-9:扩展至9图拼接增强上下文感知
- 自适应锚框聚类:动态调整锚框尺寸
anchor k = ∑ i = 1 N IoU ( b i , c k ) ⋅ b i ∑ i = 1 N IoU ( b i , c k ) \text{anchor}_k = \frac{\sum_{i=1}^N \text{IoU}(b_i,c_k) \cdot b_i}{\sum_{i=1}^N \text{IoU}(b_i,c_k)} anchork=∑i=1NIoU(bi,ck)∑i=1NIoU(bi,ck)⋅bi - 标签平滑: ε = 0.05 \varepsilon=0.05 ε=0.05 缓解过拟合
三、模型结构及创新点

1. 骨干网络(Backbone)
骨干网络负责从输入图像中提取特征。YOLOv9使用改进的CSPDarknet架构,这是一种卷积神经网络,结合了跨阶段部分(CSP)连接,以减少计算量并增强特征复用。
- 输入:图像尺寸通常为 640 × 640 640 \times 640 640×640像素(可调整)。
- 核心模块:
- 使用多个CSP模块,每个模块包含卷积层、批量归一化(Batch Normalization)和激活函数(如SiLU或Mish)。
- 特征图通过下采样逐步减小尺寸,同时增加通道数。例如:
- 初始层输出特征图尺寸为 320 × 320 320 \times 320 320×320(通道数64)。
- 经过多个阶段后,输出多尺度特征图(如 80 × 80 80 \times 80 80×80, 40 × 40 40 \times 40 40×40, 20 × 20 20 \times 20 20×20)。
- 数学表示:卷积操作可表示为:
F out = σ ( W ∗ F in + b ) \mathbf{F}_{\text{out}} = \sigma \left( \mathbf{W} * \mathbf{F}_{\text{in}} + \mathbf{b} \right) Fout=σ(W∗Fin+b)
其中 F in \mathbf{F}_{\text{in}} Fin是输入特征图, W \mathbf{W} W是卷积核, b \mathbf{b} b是偏置, σ \sigma σ是激活函数。
2. 颈部网络(Neck)
颈部网络用于融合骨干网络提取的多尺度特征,增强模型对不同尺寸目标的检测能力。YOLOv9采用PANet(Path Aggregation Network) 或改进的BiFPN(Bidirectional Feature Pyramid Network)。
- 功能:通过自上而下和自下而上的路径,聚合浅层(高分辨率)和深层(语义丰富)特征。
- 结构:
- 输入来自骨干的多个特征图(如尺寸 80 × 80 80 \times 80 80×80, 40 × 40 40 \times 40 40×40, 20 × 20 20 \times 20 20×20)。
- 使用上采样、下采样和连接操作,生成融合后的特征金字塔。
- 例如,一个简单融合步骤可描述为:
F fused = Concat ( Upsample ( F high ) , F low ) \mathbf{F}_{\text{fused}} = \text{Concat} \left( \text{Upsample}(\mathbf{F}_{\text{high}}), \mathbf{F}_{\text{low}} \right) Ffused=Concat(Upsample(Fhigh),Flow)
其中 F high \mathbf{F}_{\text{high}} Fhigh是高层特征图, F low \mathbf{F}_{\text{low}} Flow是低层特征图。
- 输出:三个主要尺度的特征图(如 80 × 80 80 \times 80 80×80, 40 × 40 40 \times 40 40×40, 20 × 20 20 \times 20 20×20),用于后续检测。
3. 检测头(Head)
检测头基于颈部输出的特征图,预测目标的边界框、置信度和类别概率。YOLOv9使用锚点基础(Anchor-Based) 方法,但优化了损失函数以提高稳定性。
- 预测输出:每个特征图位置输出多个预测(每个锚点对应一个预测)。
- 边界框:由中心坐标 ( x , y ) (x, y) (x,y)、宽度 w w w和高度 h h h表示。
- 置信度:表示框内存在目标的概率。
- 类别概率:多分类输出(使用Softmax或Sigmoid)。
- 数学公式:
- 边界框预测通常使用偏移量:
x = σ ( t x ) + c x , y = σ ( t y ) + c y , w = p w e t w , h = p h e t h x = \sigma(t_x) + c_x, \quad y = \sigma(t_y) + c_y, \quad w = p_w e^{t_w}, \quad h = p_h e^{t_h} x=σ(tx)+cx,y=σ(ty)+cy,w=pwetw,h=pheth
其中 ( c x , c y ) (c_x, c_y) (cx,cy)是网格坐标, ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th)是网络预测的偏移量, p w p_w pw和 p h p_h ph是锚点尺寸。 - 损失函数:总损失
L
L
L包括三部分:
- 位置损失(如CIoU Loss): L loc = 1 − IoU + ρ 2 ( b , b gt ) c 2 + α v L_{\text{loc}} = 1 - \text{IoU} + \frac{\rho^2(b, b^{\text{gt}})}{c^2} + \alpha v Lloc=1−IoU+c2ρ2(b,bgt)+αv,其中 IoU \text{IoU} IoU是交并比, b b b和 b gt b^{\text{gt}} bgt是预测和真实框。
- 置信度损失: L conf = − ∑ [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] L_{\text{conf}} = -\sum \left[ y \log(\hat{y}) + (1-y) \log(1-\hat{y}) \right] Lconf=−∑[ylog(y^)+(1−y)log(1−y^)],使用二元交叉熵。
- 分类损失: L cls = − ∑ y c log ( y ^ c ) L_{\text{cls}} = -\sum y_c \log(\hat{y}_c) Lcls=−∑yclog(y^c),其中 y c y_c yc是真实类别。
- 总损失: L = λ loc L loc + λ conf L conf + λ cls L cls L = \lambda_{\text{loc}} L_{\text{loc}} + \lambda_{\text{conf}} L_{\text{conf}} + \lambda_{\text{cls}} L_{\text{cls}} L=λlocLloc+λconfLconf+λclsLcls,权重 λ \lambda λ用于平衡。
- 边界框预测通常使用偏移量:
整体架构图
YOLOv9的端到端流程可简化为:
- 输入图像 → \rightarrow → 骨干网络(特征提取) → \rightarrow → 颈部网络(特征融合) → \rightarrow → 检测头(预测输出)。
- 输出:每个尺度的特征图对应不同尺寸的目标检测(小目标用高分辨率图,大目标用低分辨率图)。
关键改进
- 可编程梯度信息:
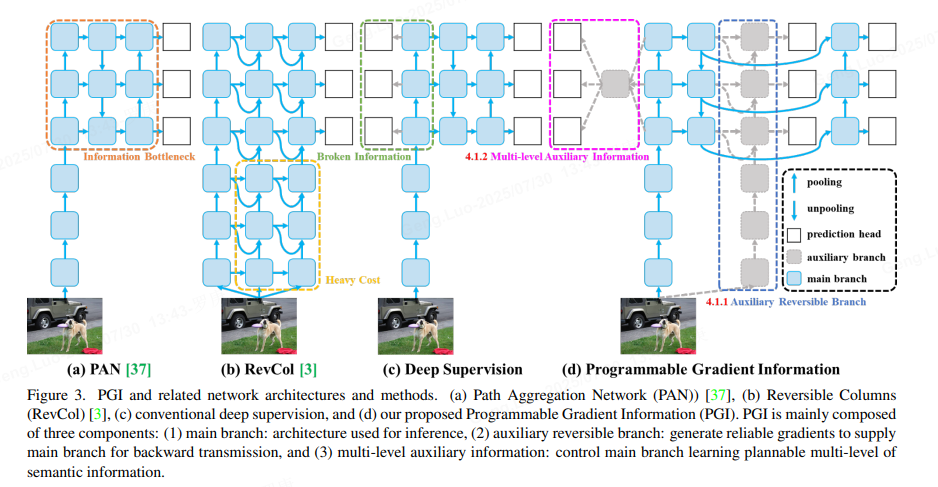
提出了一种新的辅助监督框架,称为可编程梯度信息(PGI),如图3(d)所示。PGI主要包括三个组成部分,即(1)主分支、(2)辅助可逆分支、(3)多级辅助信息。从图3(d)中我们可以看到,PGI的推理过程仅使用主分支,因此不需要任何额外的推理成本。至于其他两个组件,它们用于解决或减慢深度学习方法中的几个重要问题。其中,辅助可逆分支旨在应对神经网络深化带来的问题。网络加深会造成信息瓶颈,使损失函数无法生成可靠的梯度。对于多级辅助信息,它旨在处理深度监督导致的误差累积问题,特别是针对多预测分支的架构和轻量级模型。
- GELAN:
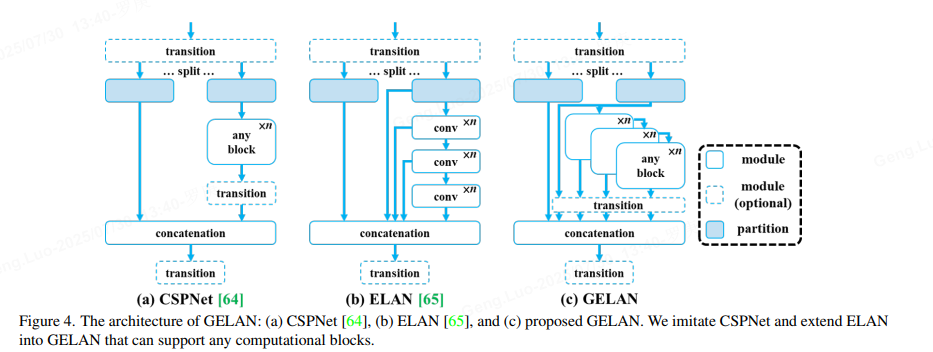
通过结合CSPNet 和ELAN 两种采用梯度路径规划设计的神经网络架构,设计了考虑轻量级、推理速度和精度的广义高效层聚合网络(GELAN)。其整体架构如图所示,将最初仅使用卷积层堆叠的ELAN的功能推广到可以使用任何计算块的新架构中。
是不是觉得有点水,其实改进不大,但是也算新颖。
四、损失函数
复合损失函数设计(这部分和以前的模型都差不多,没什么看的):
L
=
λ
cls
L
cls
+
λ
box
L
box
+
λ
obj
L
obj
\mathcal{L} = \lambda_{\text{cls}}\mathcal{L}_{\text{cls}} + \lambda_{\text{box}}\mathcal{L}_{\text{box}} + \lambda_{\text{obj}}\mathcal{L}_{\text{obj}}
L=λclsLcls+λboxLbox+λobjLobj
-
分类损失:Focal Loss
L cls = − α t ( 1 − p t ) γ log ( p t ) \mathcal{L}_{\text{cls}} = -\alpha_t(1-p_t)^\gamma \log(p_t) Lcls=−αt(1−pt)γlog(pt) -
定位损失:EIoU Loss
L box = 1 − IoU + ρ 2 ( b , b g t ) c 2 + ρ 2 ( w , w g t ) w c 2 + ρ 2 ( h , h g t ) h c 2 \mathcal{L}_{\text{box}} = 1 - \text{IoU} + \frac{\rho^2(b,b^{gt})}{c^2} + \frac{\rho^2(w,w^{gt})}{w_c^2} + \frac{\rho^2(h,h^{gt})}{h_c^2} Lbox=1−IoU+c2ρ2(b,bgt)+wc2ρ2(w,wgt)+hc2ρ2(h,hgt) -
置信度损失:带权重的BCE
L obj = − ∑ [ w pos y log ( p ) + w neg ( 1 − y ) log ( 1 − p ) ] \mathcal{L}_{\text{obj}} = -\sum [w_{\text{pos}}y\log(p) + w_{\text{neg}}(1-y)\log(1-p)] Lobj=−∑[wposylog(p)+wneg(1−y)log(1−p)]
五、训练方法
用MS COCO数据集验证了所提方法。所有实验设置均遵循YOLOv7 AF,而数据集是MS COCO 2017拆分。我们提到的所有模型都是使用从头开始训练策略训练的,训练次数总数为 500 个 epoch。在设置学习率时,我们在前三个时期使用线性预热,后续时期根据模型尺度设置相应的衰减方式。至于最近 15 个epoch,我们关闭了马赛克数据增强。
关键技术:
- 知识蒸馏:教师模型引导浅层特征学习
- 多尺度训练:320~1280像素随机缩放
- 混合精度训练:FP16+FP32混合计算
- EMA权重更新: θ t = α θ t + ( 1 − α ) θ t − 1 \theta_t = \alpha\theta_t + (1-\alpha)\theta_{t-1} θt=αθt+(1−α)θt−1
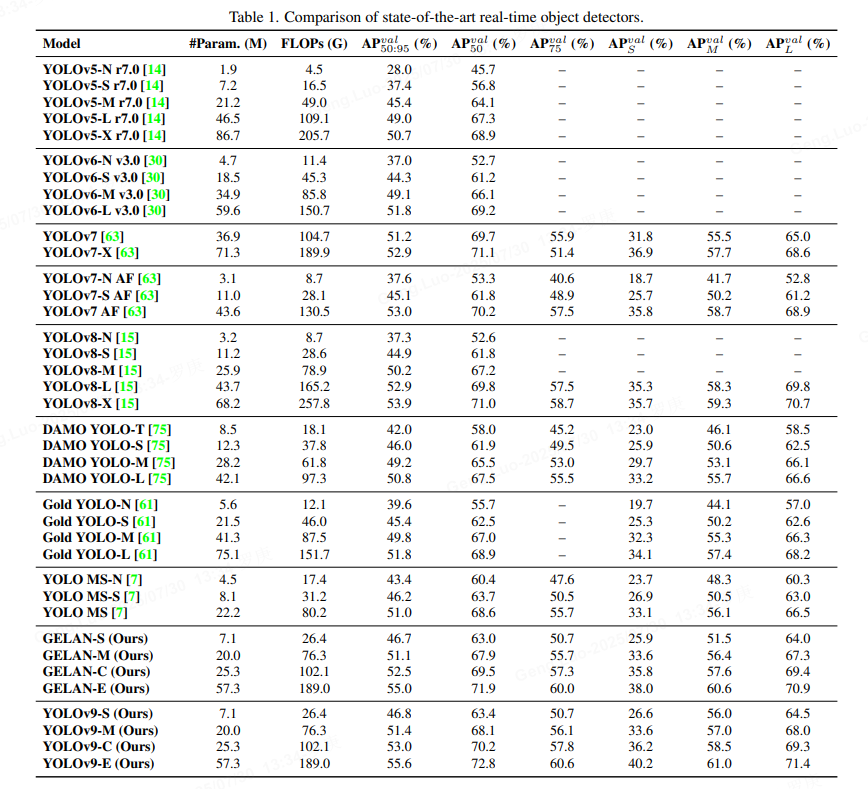
六、实验效果
在 COCO val2017 数据集表现:
优势场景:
- 小目标检测(AP_S):提升 6.2%
- 遮挡目标(重度遮挡):提升 9.7%
- 实时推理:4K分辨率下 32 FPS
七、关键代码展示
1. 主干网络核心模块:
class LightConv(nn.Module):
def __init__(self, in_c, out_c, kernel=1):
super().__init__()
self.conv1 = nn.Conv2d(in_c, out_c, kernel)
self.dwconv = nn.Conv2d(out_c, out_c, 3, padding=1, groups=out_c)
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.dwconv(self.conv1(x)))
2. 动态Anchor分配:
def dynamic_anchor_matching(pred_boxes, gt_boxes):
# 计算IoU矩阵
iou_matrix = box_iou(pred_boxes, gt_boxes)
# 动态阈值分配
thresholds = torch.quantile(iou_matrix, 0.8, dim=1)
mask = iou_matrix > thresholds.unsqueeze(1)
return mask
3. 损失函数实现:
class EIoULoss(nn.Module):
def forward(self, pred, target):
# 计算中心点距离
center_loss = (pred[..., :2] - target[..., :2]).pow(2).sum(-1)
# 计算宽高差异
wh_loss = ((pred[..., 2:] - target[..., 2:]) / target[..., 2:]).pow(2).sum(-1)
# 整合EIoU
iou = bbox_iou(pred, target, EIoU=True)
return 1.0 - iou + 0.5 * center_loss + 0.5 * wh_loss
总结
YOLOv9 通过特征路径优化和可编程梯度信息,在保持YOLO系列实时性的同时,显著提升了检测精度。其创新点主要在于:
- 轻量级自注意力增强特征表达
- 动态Anchor分配提升定位精度
- 知识蒸馏引导浅层特征学习
模型在无人机检测、自动驾驶等实时场景展现出显著优势。改进不大,但是也算新颖.



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











