







文章目录
-
- 神经网络的发展史
- 目标检测之one-stage和two-stage网络的区别?
- pooling 层的作用?
- 归一化的作用?
- Internal Covariate Shift与Normalization
- Max-Norm Regularization
- 链式法则及其反向传播
- 神经网络激励函数的作用是什么,及线性与非线性的差别?
- 常用的激活函数?
- softmax的缺点
- relu 在0点是否可导?
- 深度学习的深层次问题?
- 深度学习训练问题?
- 常用的一阶、二阶优化算法有哪些?区别是什么?
- 优化器的比较与选择?
- CV中常用的损失 函数?
- 什么是SOFT NMS?
- IOU LOSS & GIOU LOSS?
- L1&L2正则化在pytorch中的应用
- 怎么权重初始化,有哪些方法?
- 什么是前向传播与后向(反向)传播?
- 反向传播是怎么样的过程?(对上个问题的补充)
- 网络中是如何运用梯度下降法?(对上个问题的补充)
- yolo 的原理、方法是怎么样的?
- 学习率是怎么调节的?
- 训练的时候对原始图片做哪些处理?
- 网络调参,会调节哪些参数?
- Weight Normalization
- Batch norm 的原理是什么样的?
- 深度学习策略BN、LN、IN 、GN、FRN、IBN的联系与区别?
- BN 层放置位置问题
- 深度学习GN?
- 防止过拟合的方法有哪些?
- 怎么去判断一个网络训练结果的好坏?
- 图片进入网络的尺寸怎么确定?
- 正向传播与反向传播的次数?
- 网络中模型大小的计算?
- model.train 与 model.eval
- PyTorch里面的torch.nn.Parameter()
- Rethinking ImageNet Pre-training
- 怎么计算MAP?
- CPU & GPU 在神经网络计算中的区别
- SVM 与 logistic回归的区别?
- 为什么引入Relu呢?
- attention 相关
神经网络的发展史
目标检测之one-stage和two-stage网络的区别?
它们的主要区别
1.one-stage网络速度要快很多
2.one-stage网络的准确性要比two-stage网络要低
那么什么情况下背景ancor不会拉低这个准确率呢?
那你就要设置阀值,与真实grundTtruth iou阀值设得小一点,只要大于这个阀值,我就认为你是非背景ancor(注意这部分ancor只负责计算目标置信度损失,而位置、类别损失仍然还是那几个负责预测的ancor来负责)或者假如一个图片上有非常多的位置都是目标,这样很多ancor都不是背景ancor;总之保证背景ancor和非背景ancor比例差不多,那样可能就不会拉低这个准确率,但是只要它们比例相差比较大,那么就会拉低这个准确率,只是不同的比例,拉低的程度不同而已
解决one-stage网络背景ancor过多导致的不均衡问题方案
1.采用focalloss,将目标置信度这部分的损失换成focalloss,具体如下:
2.增大非背景ancor的数量
某个像素点生成的三个ancor,与真实grundtruth重合最大那个负责预测,它负责计算位置损失、目标置信度损失、类别损失,这些不管,它还有另外两个ancor,虽然另外两个ancor不是与真实grundtruth重合最大,但是只要重合大于某个阀值比如大于0.7,我就认为它是非背景ancor,但注意它只计算目标置信度损失,位置和类别损失不参与计算,而小于0.3的我直接不让它参与目标置信度损失的计算,实现也就是将它的权重置0,这个思想就类似two-stage网络那个筛选机制,从2000多个ancor中筛选300个参与训练或者计算目标置信度损失,相当于我把小于0.3的ancor我都筛选掉了,让它不参与损失计算
3.设置权重
在目标置信度损失计算时,将背景ancor的权重设置得很小,非背景ancor的权重设置得很大
原文:https://blog.csdn.net/weixin_33602281/article/details/86169287
pooling 层的作用?
*本质上,是在精简feature map数据量的同时,最大化保留空间信息和特征信息,的处理技巧;
目的是:
(a)对feature map及参数进行压缩,起到降维作用;
(b)减小过拟合的作用。包括Max pooling 和average pooling;
(c)引入不变性,包括平移、旋转、尺度不变性。但CNN的invariance的能力,本质是由convolution创造的;
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
为什么不用卷积步长的压缩:因为pooling layer的工作原理,在压缩上比convolution更专注和易用。
为什么不用BP神经网络去做呢?
(1)全连接,权值太多,需要很多样本去训练,计算困难。应对之道:减少权值的尝试,局部连接,权值共享。
卷积神经网络有两种神器可以降低参数数目。
第一种神器叫做局部感知野,一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
第二级神器,即权值共享。
(2)边缘过渡不平滑。应对之道:采样窗口彼此重叠。
归一化的作用?
*幅度归一化到同样的范围。目的:为了让不同维度的数据具有相同的分布规模,使后面数据处理更有效。
线性归一化: y = ( x − m i n ) / ( m a x − m i n ) y = (x-min)/(max-min) y=(x−min)/(max−min)
局部归一化:

Internal Covariate Shift与Normalization
Internal Covariate Shift:内部协变量偏移 我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”
解决思想:
白化(Whitening)
白化(Whitening)是机器学习里面常用的一种规范化数据分布的方法,主要是PCA白化与ZCA白化。
白化是对输入数据分布进行变换,进而达到以下两个目的:
1、使得输入特征分布具有相同的均值与方差,其中PCA白化保证了所有特征分布均值为0,方差为1;而ZCA白化则保证了所有特征分布均值为0,方差相同;
2、去除特征之间的相关性。
通过白化操作,我们可以减缓ICS的问题,进而固定了每一层网络输入分布,加速网络训练过程的收敛。
Normalization
但是白化计算成本太高,每一轮训练中的每一层都需要做白化操作;同时白化改变了网络每一层的分布,导致网络层中数据的表达能力受限。
因此提出了normalization方法,能够简化计算过程;又能够让数据尽可能保留原始的表达能力。
但是,实际想想,是不是均值方差一致就是相同的分布了呢?其实不一定,normalization这种方式,实际上并不是直接去解决ICS问题,更多的是面向梯度消失等,去加速网络收敛的。类似covariance shift比较直接的解决思路应该是对样本的Reweight操作,根据前后两个分布进行权重的学习,再对新的分布进行reweight,参考。
Max-Norm Regularization
虽然单独使用 dropout 就可以使得模型获得良好表现,不过,如果搭配Max-Norm 食用的话,那么效果更佳。
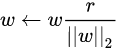
链式法则及其反向传播

神经网络激励函数的作用是什么,及线性与非线性的差别?
*在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数 Activation Function。
如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
如果使用(非线性)的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
常用的激活函数?

-
Sigmoid激活函数
-
hard-sigmoid:
斜率可以自定义
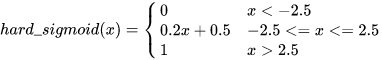

-
softmax激活函数
-
softplus函数
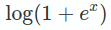
-
Tanh激活函数
-
Relu激活函数
-
Leaky Relu激活函数
-
P-Relu激活函数
-
ELU激活函数
-
Selu激活函数
-
swich激活函数 原始公式为: f ( x ) = x ∗ s i g m o d ( β x ) f(x)=x * sigmod(\beta x) f(x)=x∗sigmod(βx)
Swish 在深层模型上的效果优于 ReLU
-
hard-swish:
虽然这种Swish非线性提高了精度,但是在嵌入式环境中,他的成本是非零的,因为在移动设备上计算sigmoid函数代价要大得多。
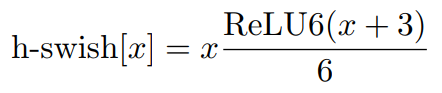
-
Swish-B激活函数的公式则为 f ( x ) = x ∗ s i g m o d ( b ∗ x ) f(x)=x * sigmod(b * x) f(x)=x∗sigmod(b∗x)
-
Relu6: relu6 = min(max(relu(x), 0), 6)
-
Mish:
Relu在x>0的区域使用x进行线性激活,有可能造成激活后的值太大,影响模型的稳定性.
Mish激活函数:Mish=x * tanh(ln(1+e^x))


softmax的缺点
e x i e^{x_i} exi可能会因为xi非常大,而导致溢出,处理方法:除以最大或者减去最大:
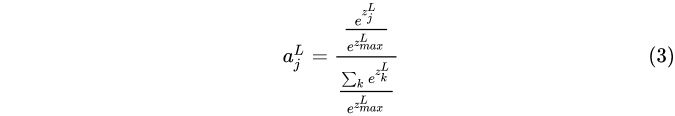
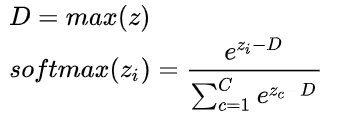
relu 在0点是否可导?
0点处左边导数=0 右边导数为1, 不可导。在relu函数定义中规定,==0的导数取左导数,即为0。
深度学习的深层次问题?
*人工智能最关键的问题是抽象和推理。现如今的监督学习和强化学习需要太多数据,无法像人一样做推理规划,只是在做简单的模式识别。
如果用强化学习的方式,给你的算法一个目标,然后让它自行决定最佳的行动是什么,在计算机学会不同道路情况下躲开汽车之前,可能早已经被车撞死几千次了
常常会犯人们不会犯的错误,比如把牙刷预测成棒球棍。
依赖大量数据。
训练出的结果对相似场景的应用性不好(迁移能力差)。
对特征具备复杂层级关系的应用领域不能自然处理。
开放式推理能力差(意思是无法基于现实知识进行推理,这一点我曾在其他地方看到一篇论文讨论过这种情况,遗憾的是那篇论文仅仅指出人类的推理能力实际上是基于一个现实知识的先验数据库,并未针对深度学习如何提高推理能力做出解释)。
“黑箱”性质。
先验知识难以整合(和第4条基本说的是一回事)。
不能区分数据与结论之间是因果关系还是相关关系(这一点Cliff应该有些体会)。
分析具备潜在前提,比如背景环境的高度稳定性(意思是默认数据和结论之间的联系不受外界干扰)。
只能得到一个近似的答案。
难以工程化(如果深度学习可以工程化了,我个人觉得世界将迎来一个崭新的篇章)。
深度学习训练问题?
*1、欠拟合
2、过拟合
3、梯度消失
4、问题性调参(代码问题)
5、优化性调参
优化性调参可以在三部分进行优化,分别是:数据预处理,模型优化,超参数选择
6、实验及参考
参与别人的参数选择及自己试验得到合理参数。
…
常用的一阶、二阶优化算法有哪些?区别是什么?
一阶的有:梯度下降法GD、SGD、ASGD、指数加权平均AdaDelta、RMSProp、Adam
二阶的有:牛顿法、拟牛顿法
牛顿法:



优化器的比较与选择?
*BGD,SGD,MBGD, SGD with Momentum, SGD with Nesterov accelerated gradient,
自适应优化算法:AdaGrad, Adadelta/RMSProp, Adam, NAdam

RMSprop:

adadelta:

Adam:

https://www.leiphone.com/news/201706/e0PuNeEzaXWsMPZX.html
CV中常用的损失 函数?
*L1 loss 、L2 loss…
1、focal loss(焦点损失)
2、skrinkage loss(收敛损失)
3、lossless Triplet loss一种高效的siamese网络损失函数
4、Repulsion loss
https://blog.csdn.net/gbyy42299/article/details/83956648
blog.csdn.net
5、sample can be faster Than
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9431
9431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









