







参考传送门:
1. Hardware Prefetching笔记
2. 全球百科——缓存预取
3. 百度百科——缓存数据预期技术

0. 什么是Hardware Prefetching(本节内容不包括在论文中)
来自[1]
- hardware prefetch就是硬件提前把数据预取到cache的实现,根据destination的不同,可以分为icache的预取和dcache的预取(当然换一个角度也可以按照L1/L2/LLC进行区分)
- instruction prefetch和data prefetch
- 对于data prefetch而言,memory access比较随机,更容易受到程序风格影响(比如索引表的跳转,OOP的对象访问),可能受到OoO的影响,导致访问流更加乱序;因为处于整个cpu流水线的后端,OoO已经可以隐藏掉部分的miss penalty;由于load、store只是指令流中的一部分,所以access pipe天然会有空闲下来的时间,用来进行prefetch;在抓取的特征上除了地址信息,还有PC信息可以参考
- 对于instruction prefetch而言,memory access相对简单,不会出现乱序打乱pattern的情况,只有sequential access和CTI引起的各类跳转,且后者已经有分支预测器(当然如果单单用分支预测器,预取的及时性就很难保证);正常情况下instruction pipe一直在取指,所以可以prefetch的时机,相对少于data prefetch;在抓取的特征上,直观的地址信息就是PC信息,这就比data prefetch少了一半(当然BP的存在就暗示我们肯定还有其他的信息可以被用来作为prefetch的signature)
- 另一个和prefetch相似的功能模块就是BP
- 缓存预期的收益显而易见,可以让数据以L1 hit的memory latency来返回
- 预取有几个性能指标:准确性、及时性、副作用(Dram Bandwidth,cache pollution)
来自[2]
- 缓存预取是计算机处理器用来通过在实际需要之前将指令或数据从其较慢的内存中的原始存储中提取到较快的本地内存中来提高执行性能的技术
- 预取操作的源通常是主存储器(内存)
- 可以使用非阻塞缓存控制指令来完成预取

- 数据预取在需要之前先获取数据。由于数据访问模式显示的规律性低于指令模式,因此准确的数据预取通常比指令预取更具挑战性
- 指令预取在需要执行指令之前先提取指令,近年来,所有高性能处理器都使用预取技术
- 缓存预取可以通过硬件或软件来完成
- 基于硬件的预取通常是通过在处理器中具有专用的硬件机制来完成的,该机制监视正在执行的程序所请求的指令或数据流,基于该流识别出程序可能需要的下几个元素,然后预取到处理器的缓存中
- 基于软件的预取通常是通过让编译器分析代码并在编译本身期间在程序中插入其他“预取”指令来完成的
- 软件预取仅在常规数组访问的循环中有效,因为程序员必须手工编写预取指令。而硬件预取器则根据程序在运行时的行为动态地工作
- 硬件预取具有较少的CPU开销
来自[3]
- 缓存预期有两个应用场景:一个是指在Web服务中的应用;另一个则是指在计算机体系结构中的应用
- 基于访问概率的预取模型:由于用户对Web的访问具有一定的规律,且具有历史性和相对集中的爱好,因此提出了基于组的兴趣和访问行为对未来将要访问的资源进行预测
- 基于数据挖掘的预取模型:利用数据挖掘技术挖掘用户的兴趣关联规则,作为对用户即将访问的页面进行预取的依据
- 基于Web语义的预取模型:通过提炼用户会话特征,按语义对用户会话进行分类,服务器确定用户会话所属的类别,预送用户可能使用的文档并发送到客户端
- 基于网络性能的预取模型:在对Web代理服务器上的业务进行分析和对网络RTT进行测量分析的基础上,对URL的未来访问进行预测
- 基于流行度的预取模型:定期地统计网页的访问次数,并选取访问次数较多的网页组成流行页面集。然后根据客户最近发出的请求量的大小,从每个服务器上的流行页面集中预取相当于用户最近发出的请求量的页面放在缓存或直接送给用户。利用Zipf第1定律和第2定律对访问流行度建模,提出了基于Web流行度的预取模型
- 基于神经网络的预取模型:采用基于神经网络的预取模型,利用BP或MA等算法进行学习并预测。通过抽取网页超链描述文字信息中的关键词作为神经网络的输入,神经网络输出结果作为预取依据,用户浏览路径页面作为训练样本反馈给神经网络进行学习
- 软件预取:编程人员和编译器通过插入软件预取指令来实现数据预取。
- 硬件预取:现代处理器(CPU)都实现了硬件预取,流预取和步幅预取(stream prefetcher and stride prefetcher)。硬件预取通常只能处理数据访问模式比较固定情况
在阅读完一定的资料后,可以确定的是,本篇论文针对的问题是:计算机体系结构中的缓存预期框架设计
1. 简介
1.1 关于Hardware Prefetching的一些关键信息
- memory access pattern: 即内存访问模式;不同的应用程序,其数据访问模式存在较大的差异,例如有些应用顺序访问内存而有些应用则跳跃访问,更有些应用表现出访问的“无序性”;一个优良的数据缓存预取器应该能够很好地识别出应用的内存访问模式
- feature:预取器用于判断内存访问模式的依据被称为“特征”(feature);常用的feature包括程序计数器(PC),cacheline的地址(Address),cacheline中保存数据的页偏移(Offset)
- 预取器可能带来的好处:降低CPU因缓存未命中而产生的内存级数据获取而浪费的时间
- 预取器可能带来的坏处:内存带宽的浪费、缓存数据污染、内存访问冲突等
1.2 现阶段方法的缺陷
- Single-feature prefetch prediction:现存的大多数预取器仅仅通过某一类feature来进行支持预取操作的决策,这导致大部分的预取器只能良好地预测契合某一种内存访问模式的程序

- Lack of inherent system awareness:几乎所有的现存预取器都存在这个问题,即将系统层面的一些“认知”作为一个单独的控制组件合并到底层系统无法感知到的预取算法中,例如不知道当前系统带宽的紧张程度。因此一个预取器的存在,反而可能降低系统的性能
- Lack of online prefetcher design customization:即现存的预取器没有办法通过线上操作的方式对其配置进行修订。因为这个原因,在面对不同的系统配置,处理不同的应用程序时,往往不能够进行适应性的修订,灵活性不高
1.3 论文团队的目标
设计出一个预取器框架,它能够:
- 可以基于多种feature以及系统层面的反馈来执行预取操作
- 能够轻易地通过线上的方式修改配置以适应不同的系统配置以及应用程序,例如修改预取操作的参考feature,调整预取操作的“程度”(增加或者降低覆盖度,准确度,即时性等)
1.4 核心思想
- 推出了Pythia,将数据预取问题转换为一个增强学习(RL)问题
- Pythia能够与处理器以及存储系统进行交互以提升其数据预取的能力
- Pythia将当前等到的一系列features作为RL的当前状态(state)以进行数据预取
- 对于每一次数据预取操作,Pythia都能够及时地收到基于准确性以及及时性的来自系统层级的反馈(reward)
While Pythia’s framework is general enough to incorporate any type of system-level feedback information into its decision making, in this paper we demonstrate Pythia using one major system-level information for prefetching: memory bandwidth usage.(即Pythia被设计为可以接受各种类型的系统级反馈,但本篇论文中所描述的示例只使用了系统带宽这一项)
2. 必要的背景知识介绍
2.1 强化学习(Reinforcement learning)
- 核心思路:如何在给定当前状态(
state)的情况下采取最大化回报(numerical reward)的行动(Action) - 一个经典的RL模型如下:

- Agent:采取行动的主体
- Environment:供Agent“居住”,提供状态信息的主体
- 基础执行流程:t时刻,1. Environment向Agent传递当前的环境状态信息(S_t) 2. Agent在接收到当前的状态信息后,在一定的判断标准(policy)下采取行动A_t 3. Agent从环境出获得反馈R_(t+1)(
注意:不一定是即时反馈) - policy:Agent的行为规范,即Agent行动的依据;通常而言,policy表示为最大化累计收益(maximum accumulative reward)
- Q-Value:Q(S,A)表示状态S情况下采取行为A的期望累计收益值
- policy更新步骤:
-
更新Q-values:Agent会根据当前时刻的状态,行为对的Q-value(Q(S_t+1, A_t+1)),回馈值(R_t+1)等信息来更新之前的Q-Value。经典的SARSA更新模型:
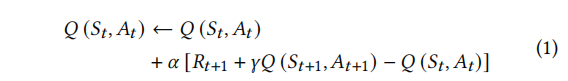
- α是学习步长(learning rate)
- γ是折扣因子(discount factor):从上式可以看出,它的作用是给最新的Q-Value进行加权,文中表明该值越接近1表明越长远的目光(far-sighted)(
暂时没搞明白是为什么,贴一小段原文 the agent can trade off a low immediate reward to gain higher rewards in the future.)
-
优化policy:
- 贪婪式(purely-greedy):总是选择Q-Value最大的行动;但是这使得模型对行为空间的探索空间受限(
总是选择概率最大的行为) - 部分贪婪(ε-greedy):ε(探索率),随机地选择一个概率不低于ε的行为
- 贪婪式(purely-greedy):总是选择Q-Value最大的行动;但是这使得模型对行为空间的探索空间受限(
-
2.2 为什么说强化学习是一个好的解决思路
- Adaptive learning in a complex state space:RL具有在复杂环境下的自学习能力
- Online learning:RL不需要前期精细地调教就可以直接上线,在程序的运行过程中不断强化
- Ease of implementation:1. 模型体积小;2. 推理速度快;3.适应性强
3. 解决方法与思路
3.1 Pythia的核心思想
- 核心结构图:

- Pythia作为整个RL模型的Agent
- Processor以及Memory系统作为RL模型的Environment
- State:被表示为各类feature(
什么是feature请参考前文) - Action:被表示为prefetch行为(
以Offset表征,后文再介绍) - Reward:被表示为系统的各种反馈,如memory bandwidth(
所以Pythia可以感知系统的状态)
3.2 模型构建(Prefetching --> RL)
-
状态建模(State):状态被表征为一个k维向量
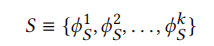
- 每一个状态最多由两个部分组成:
-
- 程序控制特征(program control-flow component):例如load-PC,branch-PC以及相关的历史信息等
-
- 程序数据特征(program data-flow component):例如cacheline address,physical page number,page offset,cacheline delta以及相关的历史信息等
- 示例:

-
行为建模(Action):表征为prefetch offset,即processor当前需求的cacheline address与本次将要预取的cacheline之间的offset
- offset集合:offset并不是一个无限范围的整数,而只能从给定的offset集合中选择一个输出,范围为[-63, 63](
对于一个页大小为4KB,cacheline大小为64Byte的系统而言,这也就确定了一页中只有64个cacheline,因此用该范围就可以完全表征从同一页中取数据的操作) - 如果输出结果为0,表示不进行预取(
Pythia支持当前状态不进行不预取的操作)
- offset集合:offset并不是一个无限范围的整数,而只能从给定的offset集合中选择一个输出,范围为[-63, 63](
-
反馈建模(Reward):由五个部分组成
- Accurate and timely (R𝐴𝑇 ):预取地址判断准确并且在请求到来时预取填充已经完成(
也就是说已经把需要预取的数据填充到了cache中) - Accurate but late (R𝐴𝐿):预取地址判断准确但是在数据请求到来时还没来得及完成填充
- Loss of coverage (R𝐶𝐿):即prefetch操作预取的地址超出了processor处理的数据页(page)
- Inaccurate (R𝐼 𝑁 ):预取地址不准确(
没有被processor使用)时,分为两种可能:1. 不准确但是系统的状态良好(low bandwidth use)2. 不准确且系统状态不良(high bandwidth use) - No-prefetch (R𝑁 𝑃 ):不进行预取操作,同样分为两种可能,同上
- Accurate and timely (R𝐴𝑇 ):预取地址判断准确并且在请求到来时预取填充已经完成(
3.3 Pythia的设计
- 硬件构成:
- Q-Value Store(QVStore):记录所有被Pythia观测的状态信息与其对应的Q-Value
- Evaluation Queue(EQ):是一个FIFO的队列,记录多条信息,每条信息由三部分组成:1. 采取的行动(Action) 2. 预取地址(Prefetch Address) 3. filled bit(用于判断该行动是否已经完成执行,即预取的数据是否已经填充进cache)
- 流程图:

- 算法流程解析:
-
- Pythia检查EQ中的信息:如果请求的地址出现在了EQ中(
说明至少Pythia想要预取这个地址中的内容),接着依据filled bit来判断是否已经将该地址的内容预取进了cache中,并对EQ中命中实体添加一个Reward(R_AT或者R_AL)
- Pythia检查EQ中的信息:如果请求的地址出现在了EQ中(
-
- Pythia抽取得到State Vector
-
- Pythia依据State以及自身的policy,从QVStore中选择合适的action
-
- Pythia将action发送给memory Hierarchy
-
- Pythia将新的prefetch操作添加到EQstore中
-
- EQ的列头元素被弹出,Pythia基于弹出的Entry对QVStore进行更新
-
- Pythia检查请求的数据是否已经被填充进入了cache中,如果是则更新EQ的对应项中的filled bit
-
3.4 基于RL的预取算法

3.5 实现细节
请参考原文
3.6 自动的设计空间探索(Automated design-space exploration)
请参考原文
3.7 存储开销

3.8 与以往工作的不同之处
请参考原文
4. 效果与结论
实验设备:

4.1 实践效果
-
单核实验:预取覆盖率以及过度预取率对比

On average, Pythia provides 6.9%, 8.8%, and 14% higher coverage than MLOP, Bingo, and SPP respectively, while generating 83.8%, 78.2%, and 3.6% fewer overpredictions.Pythia提供了一定程度的预测覆盖率提升,同时过度预取率大幅度降低
-
性能实验概览:

- 不同核心数情况下的对比:图8(a)
- 图片展示了不同核心数情况下各种预取算法爱对性能的提升(纵坐标)
- Pythia的性能超过其他所有预取算法(或框架)
- Pythia的性能提升优越性随着核心数目的提升而增加
- 不同内存带宽情况下的对比:图8(b)
- we simulate the single-core single-channel configuration by scaling the DRAM bandwidth(
在单核,单通道情况下调节内存的带宽) - 各种带宽情况对应了各款商业产品中单核可以获得的内存带宽情况
- Pythia的性能表现超过其他预取器
- 在内存带宽最紧张的情况下,一些预取器反而出现性能下降的情况,而Pythia仍然保持了很好的竞争力
- we simulate the single-core single-channel configuration by scaling the DRAM bandwidth(
- 不同LLC情况下的对比:图8©
- Pythia表现超过其他预取器
- 与多层预取方案的比较:图8(d)
- Stride-L1 以及 Streamer-L2是Intel处理器的解决方案
- IPCP是第三届data prefetching的冠军
- Stride-L1 + Pythia-L2的方案效果表现地更好
-
性能分析:
- 单核实验:

- 四核实验:

- 内存带宽感知所带来的好处(
Benefit of Memory Bandwidth Useage Awareness):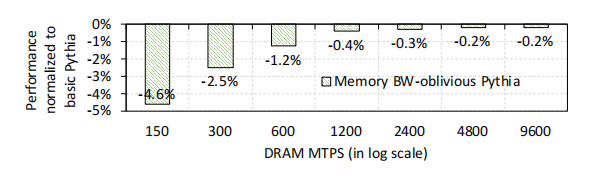
- 单核实验:
-
在“未知”的工作环境下的表现(
即使用用于调试Pythia的之外的程序来测试Pythia):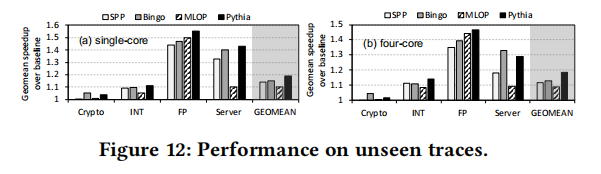
-
更多其他分析请参考原文
4.2 总结
















 2282
2282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









