








🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月20日10点02分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
一、背景及意义介绍
YOLO系列因其在计算成本和检测性能之间取得的有效平衡,已成为实时目标检测领域的主导范式。实时目标检测对于自动驾驶、机器人导航、视频监控等应用场景至关重要,这些领域需要快速且准确的目标检测能力以确保安全和效率。
YOLOv10作为高效轻量、端到端实时目标检测的新标准,在自动驾驶、机器人导航、视频监控和人机交互等领域展现出巨大潜力。
二、概述
本文解读并复现的论文是《YOLOv10: Real-Time End-to-End Object Detection》,2024年发表于NeurIPS(Neural Information Processing System)会议。众所周知,NeurIPS会议是计算机人工智能领域的顶会。
三、论文背景
研究背景:
YOLO系列模型作为实时目标检测的主流方法,因其在检测性能和计算效率之间取得的平衡而广受欢迎。然而,随着技术的发展和应用需求的提高,现有YOLO模型在后处理依赖和模型架构设计上存在局限性,这促使研究者探索新的解决方案以进一步提升性能和效率。
- 尽管YOLO系列取得了显著进展,但其对非最大抑制(NMS)的依赖限制了端到端部署,并影响了推理延迟。此外,YOLOs中各个组件的设计缺乏全面和彻底的检查,导致明显的计算冗余并限制了模型的能力。
- 针对这些挑战,YOLOv10的研究通过一系列技术创新来进一步提升YOLO系列模型的性能和效率。具体来说,YOLOv10提出了一种新的无NMS训练策略,即一致的双重分配机制,该机制结合了一对多和一对一的标签分配方法,有效减少了对传统非最大抑制(NMS)的依赖。此外,YOLOv10还引入了轻量级分类头、空间-通道解耦下采样技术,以及基于秩引导的块设计,这些优化降低了模型的复杂度并提高了特征融合的效率。同时,YOLOv10还采用了大核卷积和部分自注意力(PSA)模块来增强模型的特征提取和全局建模能力,这些技术在保持高检测速度的同时显著提升了检测准确性。通过这些综合改进,YOLOv10满足了实时目标检测领域对高性能和低延迟的双重要求。
研究意义:
- 技术创新:
-
- YOLOv10通过一致双重分配的新技术,消除了训练期间对非最大抑制(NMS)的需求,简化了推理过程,显著减少了延迟。
- YOLOv10的作者精心优化了模型的各个组件,将效率和准确性放在首位,包括轻量级分类头、独特的空间通道解耦下采样技术和秩引导块设计。
- YOLOv10集成了大核卷积和部分自注意力模块等尖端功能,提高了模型的性能而不会产生大量的计算成本。
- 应用价值:
-
- YOLOv10的高效性和高准确性使其能够理想地识别行人、其他车辆和障碍物,确保顺畅安全的驾驶体验。
- 对于从事仓库管理或救援任务的机器人来说,YOLOv10增强了快速准确地检测物体的能力,使机器人能够在动态环境中更有效地运行。
- 在安防系统中,YOLOv10的实时检测潜在威胁的能力可以在事件升级前预防,提高公共安全。
- 启发意义:
-
- YOLOv10的出现预示着目标检测技术将与其他技术如物联网、大数据等融合发展,实现更智能化的应用。
- YOLOv10的发展将向多模态数据处理转变,利用大语言模型和自然语言处理的进步来增强目标检测系统。
四、论文思路
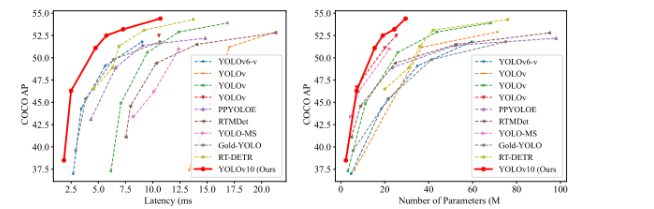
YOLOv10在延迟准确性和大小准确性上和其他目标检测模型的比较
YOLOv10提出了一致双重分配策略以实现无需NMS的端到端训练,优化了模型架构通过轻量级分类头、空间-通道解耦下采样和等级引导块设计来提高效率,以及引入大核卷积和部分自注意力模块来增强模型性能,这些技术共同推动了YOLO系列在实时目标检测任务中性能和效率的显著提升。
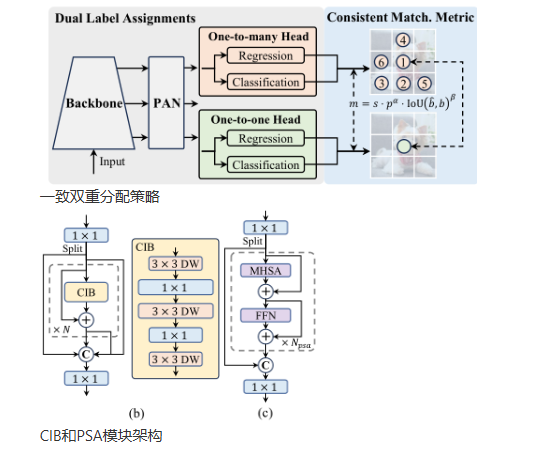
- 无NMS训练策略: YOLOv10中的一项关键创新,它通过引入一致的双重分配机制——结合一对多和一对一的标签分配方法,使得模型在训练时能够获得丰富的监督信号,在推理时则无需依赖传统的非最大抑制(NMS)过程,从而显著提高了目标检测的速度和准确性。模型架构优化集中体现在通过设计轻量级分类头减少计算负担、采用空间-通道解耦下采样提高信息保留率以及实施等级引导块设计以适应不同阶段的信息冗余度,这些综合改进使得模型在保持高检测性能的同时实现了计算效率的显著提升。
- 模型架构优化: 通过设计轻量级分类头减少计算负担、采用空间-通道解耦下采样提高信息保留率以及实施等级引导块设计以适应不同阶段的信息冗余度,这些综合改进使得模型在保持高检测性能的同时实现了计算效率的显著提升。
- 性能增强技术: YOLOv10的性能增强技术通过引入轻量级分类头降低计算负担、采用空间-通道解耦下采样提升信息保留、实施等级引导的模块设计以减少冗余,并结合大核卷积和部分自注意力机制来扩大感受野和增强全局特征学习能力,这些综合改进在保持高检测性能的同时显著提升了模型的推理速度和效率。
五、模型结构
YOLOv10的模型结构通过精心设计的骨干网络实现高效的特征提取,利用改进的特征融合策略增强多尺度特征的整合能力,并通过引入紧凑倒置块(CIB)和部分自注意力(PSA)等性能增强技术,优化了模型的计算效率和检测准确性,从而在保持高准确率的同时显著提升了模型的推理速度,满足了实时目标检测的严格要求。
- 骨干网络: YOLOv10的骨干网络采用改进的CSPNet结构,通过高效的梯度流动和减少计算冗余,提升了特征提取的效率和效果。
- 颈部网络:YOLOv10的颈部设计用于汇聚不同尺度的特征,并将其传递到头部。它包括PAN(Path Aggregation Network)层,这可以实现有效的多尺度特征融合。PAN层通过聚合不同层的特征图,增强了模型对不同尺度目标的检测能力。
- 检测头:YOLOv10采用了一对多头(One-to-Many Head)的设计,在训练过程中为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。同时,它还有一个一对一头(One-to-One Head),在推理过程中为每个对象生成一个最佳预测,消除了对NMS(非最大抑制)的需求,减少了延迟并提高了效率。
- 性能增强技术:CIB通过深度可分离卷积和逐点卷积的组合提供了一个轻量而高效的计算单元,而PSA则通过仅对特征的一部分应用自注意力机制,减少了计算复杂度,同时增强了模型的全局建模能力。这些创新使得YOLOv10在处理各种尺寸的目标时更为精准和高效。
六、损失函数
YOLOv10的损失函数是由分类损失、定位损失、置信度损失以及平衡损失等几个主要部分组成的复合函数,这些部分共同作用以优化模型在目标检测任务中的表现,确保模型能够准确分类目标、精确定位目标位置,并在各类别和目标大小之间保持平衡:
- 分类损失用于衡量模型对目标类别预测的准确性。通常采用交叉熵损失来计算预测类别概率分布和真实标签之间的差异,从而促使模型正确分类目标。
- 定位损失负责优化模型对目标位置的预测。这通常通过计算预测边界框和真实边界框之间的差异来实现,常用的方法包括IoU(交并比)损失或者L1/L2损失,以确保预测框能够准确地覆盖真实目标。
- 置信度损失用于衡量模型对目标存在的预测准确性。这包括目标是否被正确识别的置信度,以及预测框与真实目标的匹配程度。
- 平衡损失用于处理类别不平衡问题,通过对不同类别或不同困难程度的样本赋予不同的权重,确保模型不会忽视少数类别或难以检测的目标。
七、复现过程(重要)
步骤一:创建环境
在终端运行:
conda create -n yolov10 python=3.9
conda activate yolov10步骤二:安装库和依赖
继续运行:
pip install -r requirements.txt
pip install -e .
pip install ultralytics步骤三:定义训练模式
该命令行语句是示例语句,其中的数据集、模型、epoch、batch size、图片大小、单/多卡训练都可根据读者个人需要修改,在刚才的环境上运行:
yolo detect train data=coco.yaml model=yolov10n.yaml epochs=300 batch=32 imgsz=640 device=0读者也可用下面的代码块写出脚本,直接运行脚本,注意要根据实际情况调整路径:
from ultralytics import YOLOv10
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
# or
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
model.val(data='coco.yaml', batch=256)步骤四:定义验证模式
该命令行语句是示例语句,其中的数据集、模型、batch size都可根据读者个人需要修改,注意要根据实际情况调整路径:
yolo val model=jameslahm/yolov10n data=coco.yaml batch=2561
读者也可用下面的代码块写出脚本,直接运行脚本,注意要根据实际情况调整路径和权重:
from ultralytics import YOLOv10
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
# or
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
model.val(data='coco.yaml', batch=256)步骤五:定义预测模式
yolo predict model=jameslahm/yolov10{n/s/m/b/l/x}或运行脚本
from ultralytics import YOLOv10
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
# or
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
model.predict()逐步运行下面的语句,其具体逻辑是导出模型为 ONNX 格式->使用 ONNX 进行预测->导出模型为 TensorRT 引擎(或者使用 trtexec工具)->使用 TensorRT 进行预测:
# End-to-End ONNX
yolo export model=jameslahm/yolov10{n/s/m/b/l/x} format=onnx opset=13 simplify
# Predict with ONNX
yolo predict model=yolov10n/s/m/b/l/x.onnx
# End-to-End TensorRT
yolo export model=jameslahm/yolov10{n/s/m/b/l/x} format=engine half=True simplify opset=13 workspace=16
# or
trtexec --onnx=yolov10n/s/m/b/l/x.onnx --saveEngine=yolov10n/s/m/b/l/x.engine --fp16
# Predict with TensorRT
yolo predict model=yolov10n/s/m/b/l/x.engine或运行脚本
from ultralytics import YOLOv10
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
# or
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
model.export(...)此外,还开发了一个网页版的web供算法的可视化演示,运行app.py,程序运行后进入网址http://127.0.0.1:7861/,就会出来一个界面,输入图像后可进行图像检测。
环境要求:
python 3.9
- torch==2.0.1
- torchvision==0.15.2
- onnx==1.14.0
- onnxruntime==1.15.1
- pycocotools==2.0.7
- PyYAML==6.0.1
- scipy==1.13.0
- onnxslim==0.1.31
- onnxruntime-gpu==1.18.0
- gradio==4.31.5
- opencv-python==4.9.0.80
- psutil==5.9.8
- py-cpuinfo==9.0.0
- huggingface-hub==0.23.2
- safetensors==0.4.3
参考文献
[1]Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J., & Ding, G. (2024). YOLOv10: Real-time end-to-end object detection. arXiv preprint arXiv:2405.14458.
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子



















 7729
7729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











