









Transformer详解
论文简介
2017年Google在NIPS 发表了Attention is all you Need,开创了一个新的阶段,也彻底将NLP任务以前的CNN、RNN甩出了很大的距离,文章提出采用Attention机制进行翻译任务,取得了SOTA。
论文链接链接: Attention is all you Need
工作流程
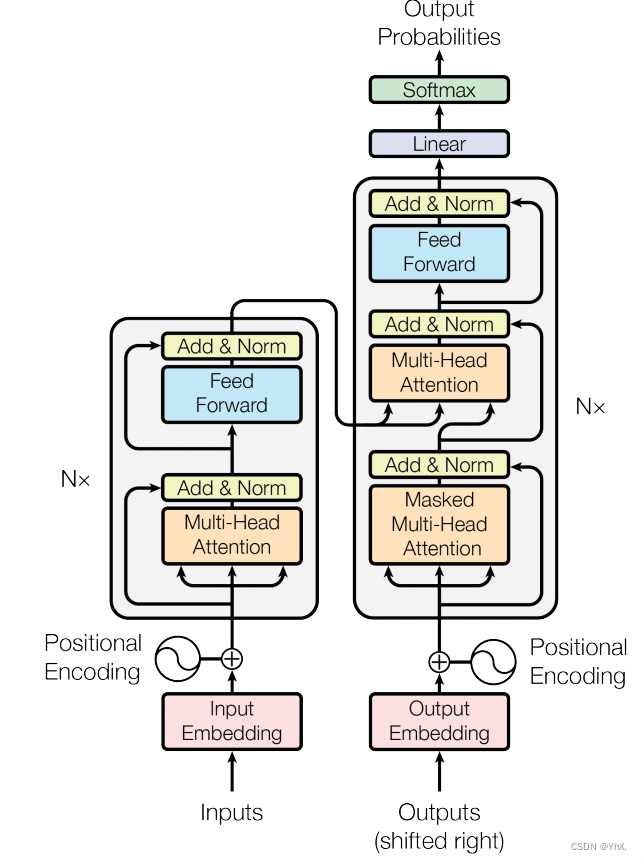
Transformer由Encoder和Decoder两部分组成,Encoder和Decoder都包含6个block。
- 获取输入句子的每一个单词的向量表示X,X由单词的Embedding(原始数据提取的Feature)和单词位置的Embedding相加得到
- 将得到的单词表示向量矩阵传入Encoder中,得到句子所有单词的编码矩阵C。单词向量矩阵用Xn*d表示,n是剧中单词个数d是向量维度。
- 将Encoder输出的编码信息矩阵C传递到Decoder中,Decoder依次根据当前翻译过的单词1~i翻译下一个单词i+1,在使用过程中,翻译到单词i+1的时候需要通过Mask(掩盖)操作掩盖住i+1之后的单词
Transformer的输入
PS:Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
-
单词的 Embedding 可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
-
位置Embedding(PE): 因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以sin,cos公式计算得到,transformer采用sin,cos公式计算PE,公式计算的优点是:使 PE 能够适应比训练集里面所有句子更长的句子、可以让模型容易地计算出相对位置。
Self-Attention
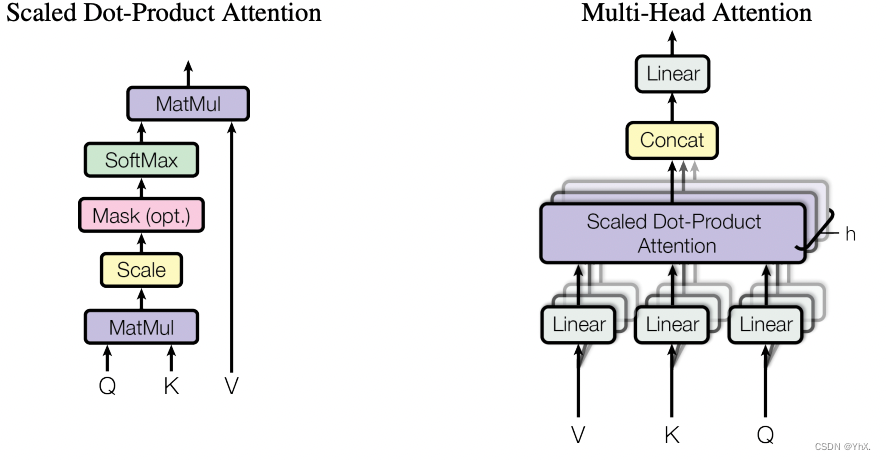
计算的时候需要用到矩阵Q(查询),K(键值),V(值),Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的
- Self-Attention的输入:单词的表示向量x组成的矩阵X,或者上一个 Encoder block 的输出
- QKV的计算:Q = X * WQ,K = X * WK,V = X * WV
- self-Attention的输出:

dk是QK矩阵的列数,即向量维度。公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以dk的平方根。Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1。
- Multi-Head Attention 是由多个 Self-Attention 组合形成的,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z
Encoder结构
-
Encoder由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的
-
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到。
-
Norm指 Layer Normalization(层归一化),通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
-
Feed Forward (前馈)层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数
-
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会作为 Decoder 的输入
Decoder结构
- 与Encoder的不同点:包含两个 Multi-Head Attention 层、第一个 Multi-Head Attention 层采用了 Masked 操作、第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算、最后有一个 Softmax 层计算下一个翻译单词的概率、。
- Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
- Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的,而Q使用上一个 Decoder block 的输出计算。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)
- Decoder block 最后的部分是利用 Softmax 预测下一个单词,Softmax 根据输出矩阵的每一行预测下一个单词
总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
参考:https://zhuanlan.zhihu.com/p/338817680
总结作笔记加强记忆















 6076
6076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









