







知识融合
知识融合的概念最早出现在1983年发表的文献中,并在20世纪九十年代得到研究者的广泛关注。而另一种知识融合的定义是指对来自多源的不同概念、上下文和不同表达等信息进行融合的过程认为知识融合的目标是产生新的知识,是对松耦合来源中的知识进行集成,构成一个合成的资源,用来补充不完全的知识和获取新知识。在总结众多知识融合概念的基础上认为知识融合是知识组织与信息融合的交叉学科,它面向需求和创新,通过对众多分散、异构资源上知识的获取、匹配、集成、挖掘等处理,获取隐含的或有价值的新知识,同时优化知识的结构和内涵,提供知识服务。
知识融合过程
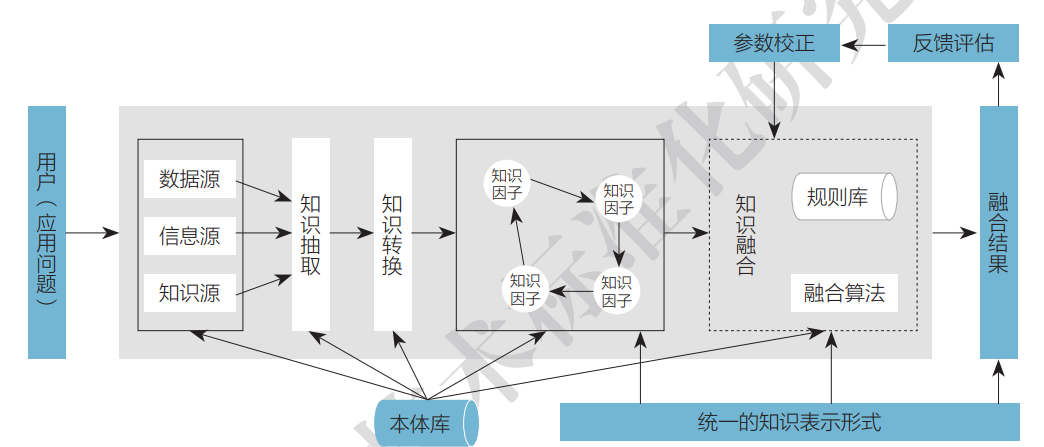
知识融合是一个不断发展变化的概念,尽管以往研究人员的具体表述不同、所站角度不同、强调的侧重点不同,但这些研究成果中还是存在很多共性,这些共性反应了知识融合的固有特征,可以将知识融合与其他类似或相近的概念区分开来。知识融合是面向知识服务和决策问题,以多源异构数据为基础,在本体库和规则库的支持下,通过知识抽取和转换获得隐藏在数据资源中的知识因子及其关联关系,进而在语义层次上组合、推理、创造出新知识的过程,并且这个过程需要根据数据源的变化和用户反馈进行实时动态调整。从流程角度对知识融合概念进行分解,如下图所示。
研究现状
知识融合从融合层面划分可以分为数据层知识融合与概念层知识融合,数据层知识融合主要研究实体链接、实体消解,是面向知识图谱实例层的知识融合;概念层知识融合主要研究本体对齐、跨语言融合等技术。
实体链接问题是数据层知识融合研究的主要任务,其核心是构建多类型多模态上下文及知识的统一表示,并建模不同信息、不同证据之间的相互交互,主要的实体链接方法有:基于实体知识的链接方法、基于篇章主题的链接方法和融合实体知识与篇章主题的实体链接方法。
概念层知识融合是对多个知识库或者信息源在概念层进行模式对齐的过程。本体对齐或者本体匹配是概念层知识融合主要研究任务,是指确定本体概念之间映射关系的过程。本体匹配可以分为单语言本体匹配和跨语言本体匹配,单语言本体匹配是指同一自然语言中本体的对齐映射,跨语言本体匹配是指从两个或多个独立的语言本体中建立本体之间映射关系的过程。本体匹配的研究核心就在于如何通过本体概念之间的相似性度量,发现异构本体间的匹配关系,本体匹配基本方法包括基于结构的方法、基于实例的方法、基于语言学的匹配算法、基于文本的匹配算法和基于已知本体实体联结的匹配算法。
在大数据时代背景下,如何将跨语言的知识图谱进行对齐与融合,实现知识的全球共享,为跨语言知识服务提供便利,是知识图谱进一步研究的过程中需要解决的问题。跨语言知识图谱研究的目的是构建一个包含当前重要知识库的大规模跨语言知识库,提高不同语言之间链接数据的国际化以及知识共享全球化,便于跨语言信息检索、机器翻译和跨语言知识问答等跨语言处理任务的研究与应用。构建了一个有42万中英跨语言实体链接的双语言知识图谱(XLORE2),自动化融合了来自维基百科、百度百科和互动百科的信息。
现有的知识融合工具包括:Falcon-AO、YAM++、Dedupe等。以Falcon-AO为例,其是由南京大学计算机软件新技术国家重点实验室开发的一个基于Java的自动本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。Falcon-AO系统采用了相似度组合策略,首先使用PMO进行分而治之,然后使用语言学算法(V-Doc、I-Sub)进行处理,然后使用结构学算法(GMO)接收前两者结果再做处理,最后连通前面两者的输出使用贪心算法进行选取。
技术发展趋势
尽管知识融合已经在学术和工业应用中取得了非常显著的成效,然而随着网络社会数据特征、跨语言融合、知识规模增加等带来挑战越发紧迫,针对短文本及资源缺乏环境下的实体链接方法、融合先验知识的深度学习端到端实体链接方法、大规模本体的高效匹配方法将成为未来研究的重要趋势。
传统的实体链接任务主要是针对长文档,长文档拥有在写的上下文信息能辅助实体的歧义消解并完成链接。而由于日常生活中人们在社交网络中常常会产生大量短文本数据,相比之下,短文本的实体链接存在口语化严重、短文本上下文语境不丰富等巨大挑战,因而面向短文本的实体链接方法研究将会成为未来的研究热点。另外目前绝大部分的实体链接模型依赖于有监督模型,需要大量标签数据集训练来达到实用目的。因此短文本及资源缺乏环境下,基于无监督/半监督和迁移学习的实体链接模型是解决问题的关键。
今年来,基于深度学习模型(如BiLSTM-CRF)在实体链接任务上取得了较大的进展,同时展现出了巨大的应用潜力,然而基于深度学习的算法训练需要大量标注数据集,缺少面向特定领域特点和任务的针对性设计。另一方面当前实体链接方法易受到实体识别等前序过程的误差影响,因此结合先验知识训练端到端深度学习实体链接模型成为未来的一大研究趋势。针对这个问题,一方面,当前许多算法尝试已经证明结合先验知识的思路在实体链接任务中的有效性,如在深度学习模型中增加句法结构、语言学知识、特定领域任务约束、现有知识库知识和特征结构等,如何更好的结合有效利用这些先验知识是提升实体链接算法性能的有效手段。同时设计基于端到端的深度学习模型将有助于降低实体链接过程中的误差传播效应,提高实体链接准确度。
随着当前各类型知识库的出现和知识规模的快速增长,而由于通常本体匹配的计算复杂度与本体规模成正比,因此大规模跨语言本体匹配成为知识库融合的重大挑战,主要面临的挑战有:大规模本体匹配的快速并行计算问题和人机协同匹配问题。针对这个问题主要的思路有:①研究基于分布式处理技术的大规模本体匹配分布式处理算法,如研究利用MapReduce、GPU等技术的并行匹配算法,提高匹配效率;②研究利用现有本体匹配结果实现潜在本体匹配的方法,同时利用启发式相似度计算方法提高计算效率;③通过对实体匹配进行预剪枝,预先过滤不匹配的实体对,避免本体之间一对一的相似度计算。
















 7149
7149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











