







1.背景

Unsloth介绍
Unsloth是一个开源项目,主要致力于提高大型语言模型(LLMs)的微调效率。该项目由Daniel Han和Michael Han领导的团队开发,旨在为开发者提供一个高效且低内存占用的微调解决方案。
以下是Unsloth的一些主要特点和功能:
-
高效的微调性能:Unsloth通过优化内核和手动反向传播引擎,实现了微调训练速度的2倍提升。同时,与传统微调方法相比,内存使用减少了70%至80%,使得在相同硬件资源下可以处理更大的数据集和更复杂的模型。
-
广泛的模型支持:Unsloth支持多种流行的LLMs,包括Llama 3.3、Mistral、Phi-4、Qwen 2.5和Gemma等。无论是微调具有70B参数的Llama 3.3模型,还是9B参数的Gemma模型,Unsloth都能满足需求。
-
易于使用的免费笔记本:Unsloth提供了多个免费的笔记本示例,这些笔记本对初学者非常友好。用户只需添加自己的数据集并运行所有代码,即可获得微调后的模型。
-
动态4位量化:Unsloth引入了动态4位量化技术,通过动态选择不量化某些参数,显著提高了模型的准确性,同时只比标准的4位量化多使用了不到10%的显存。
此外,Unsloth还提供了以下功能:
- 支持将微调后的模型导出为GGUF、Ollama、vLLM格式,或上传到Hugging Face。
- 长上下文支持,例如Llama 3.3 (70B)模型的89K上下文窗口,以及Llama 3.1 (8B)模型的342K上下文窗口。
- 视觉模型支持,如Llama 3.2 Vision (11B)、Qwen 2.5 VL (7B)和Pixtral (12B)等。
- 提供多种推理优化选项,显著提高推理速度。
Unsloth的安装和使用相对简单,它支持多种安装方式,包括Conda和Pip安装,并提供了详细的文档和教程来帮助用户快速上手。
2.unsloth安装
自己在使用unsloth安装的时候很被动,一直搞不清楚怎样安装,这几天将安装步骤弄清楚后,分享出来,也可以自己看看。(个人建议最好安装conda来管理,python版本使用的是3.11,3.10应该也可以)
step1:驱动安装
cuda的驱动要安装好,这个网上很多的,我不再说明,安装好驱动后查看cuda的版本,我这里是12.2。
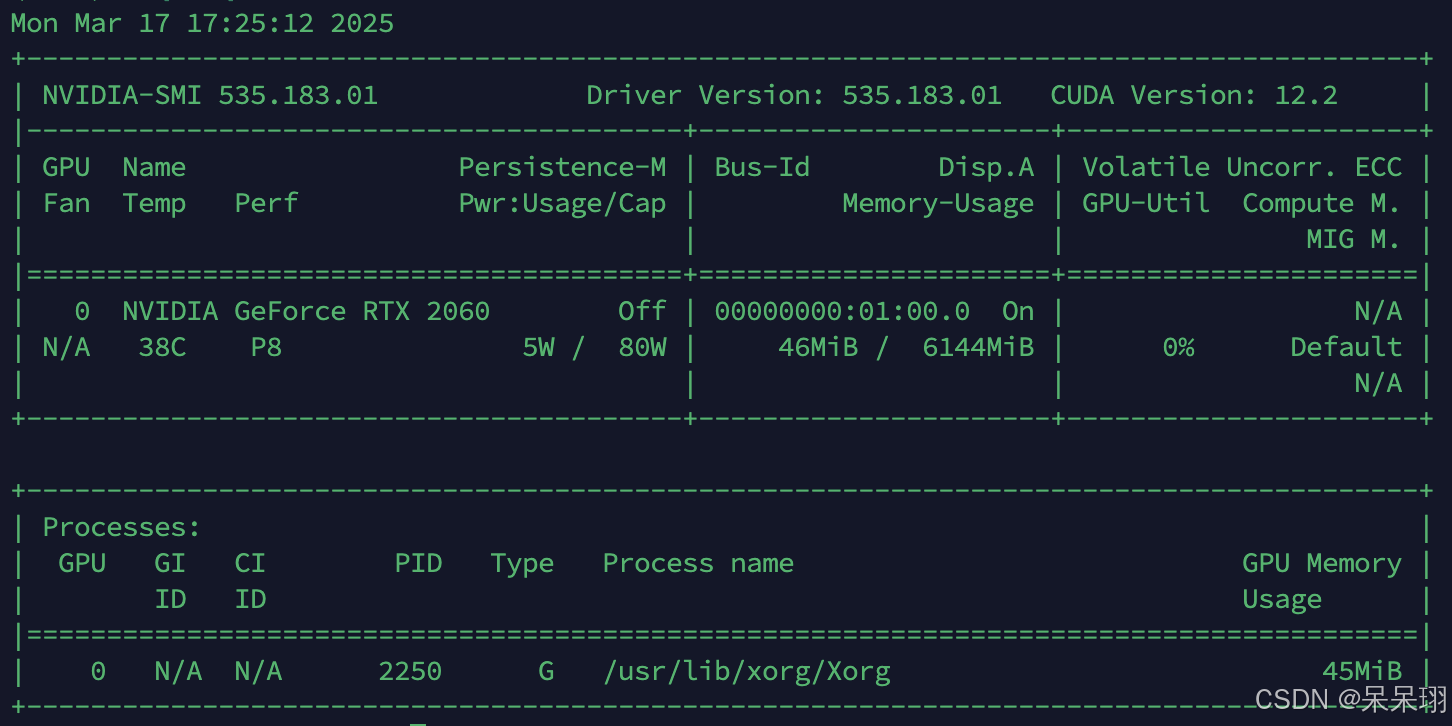
step2:安装unsloth
我安装的是torch2.4.0,配套的torchvision是0.19,驱动是cu122(如果是12.1就写121,根据实际情况安装),还有xformers的版本需要和torch的版本对应(如果安装的是0.0.28,那会更新torch版本和cuda相关的pip库,很麻烦就是了)
pip install --upgrade pip
pip install torch==2.4.0
pip install torchvision==0.19
pip install "unsloth[cu122-torch240] @ git+https://github.com/unslothai/unsloth.git"
pip install --upgrade --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth-zoo.git
pip install xformers==0.0.27.post2(如果torch版本不同,请查找对应的xfomers版本)
step3:测试unsloth
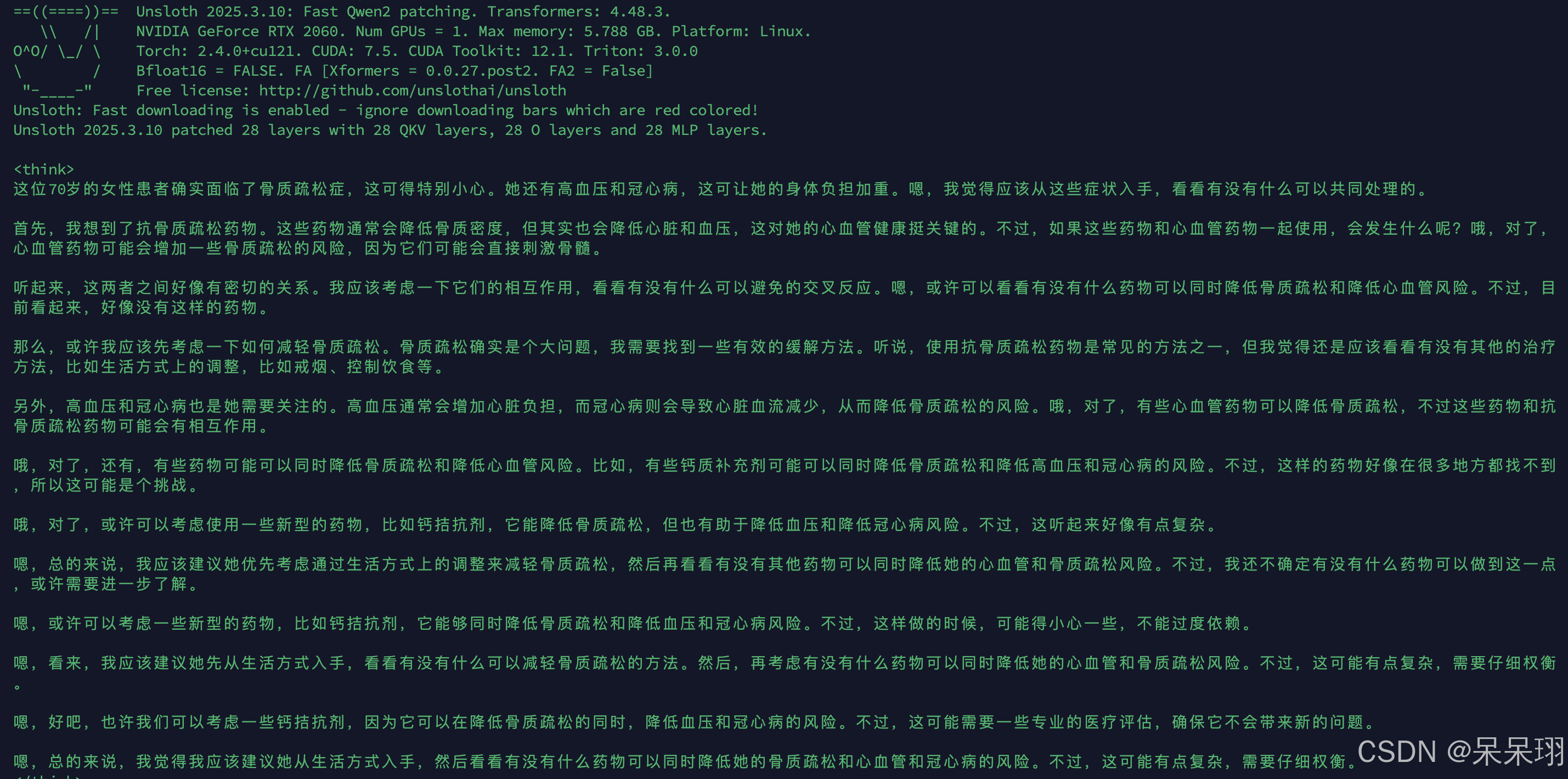
出现这个界面,恭喜你,已经安装成功,开始训练吧

3.模型训练
step1:模型准备
本人的GPU比较弱,只有6G显存,所以就训练1.5B版本来练手,模型下载指令
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5Bstep2:数据准备
中医的语料:数据下载链接
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT/tree/mainstep3:训练代码
参数说明参考链接
https://docs.unsloth.ai/get-started/fine-tuning-guidefrom unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./DeepSeek-R1-Distill-Qwen-1.5B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
OS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
from datasets import load_dataset
dataset = load_dataset("./FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train[0:500]", trust_remote_code=True)
print(dataset.column_names)
dataset = dataset.map(formatting_prompts_func, batched = True)
dataset["text"][0]
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
# num_train_epochs = 1, # For longer training runs!
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # Use this for WandB etc
),
)
trainer_stats = trainer.train()
print(question)
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
step4:微调的lora模型
微调完成后,会在文件中生成outputs文件,这个文件是lora模型,测试的时候加载lora模型(需要保留基座模型:deepseekr1-1.5b,否者无法推理)
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
# model_name = "./outputs/checkpoint-60",
model_name = "./outputs/checkpoint-60",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
4.测试结果



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











