







先看原始的机器翻译的模型

左边的是编码器,右边的是解码器。什么意思呢?就是左边部分输入中文,然后编码器前向传播传递到尽头后,传入解码器,解码器通过编码器传入的值,先输出第一个翻译出来的英文单词,然后把输出的第一个英文单词输入第二块,输出第二个英文单词,以此类推。便可以实现机器翻译。
但是这样做,会出现一个问题,就是对长句子的翻译能力不好。就像没有复习长难句的人去看英语阅读,看不懂。这时,便引入了注意力机制!
注意力机制通俗理解

如图所示,一个机器翻译的大致概念图,下面蓝色的是编码器,上面绿色的是译码器。橙色的线代表着注意力。其意思是,我的第一个输出为I,应该更加注重于(pay attention to)哪一个输入呢?很明显,应该最注重于第一个输入,因此第一个的注意力系数应该是最大的。那么,以上便是注意力机制的通俗理解,下面我将说一下注意力机制的详细过程。
注意力机制的详细过程
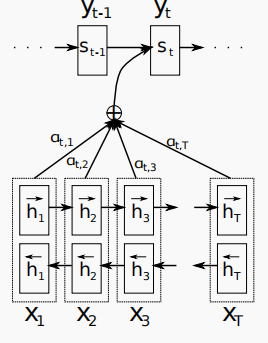
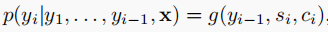
我们的每一个的输出是由前一个的输出,si,还有ci决定的
si表示解码器节点的隐含状态。
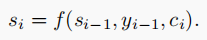
而si又是由前一个si(第一个s0是直接输入的),前一个输出以及ci得到,因此我们只要计算出ci即可得到输出。
那么问题来了,我们应该怎样得到ci呢?
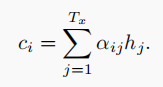
第一个变量如图所示:
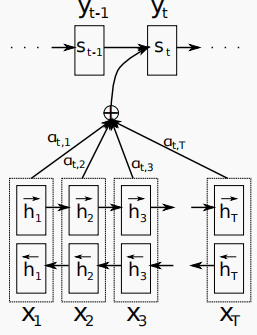
为每个编码器节点的注意力权重,对每个t来说,他们的和加起来等于1。而h实际上是上下两个h组成的特征向量
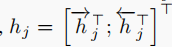
因此,ci相当于把h根据注意力权重来做了个加权平均。
那么说到这里,注意力权重又怎么求呢?
论文给了下面的两个公式来求
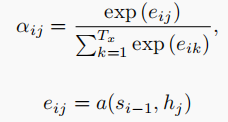
第一个公式为softmax函数,它使得在同一个i(i为解码器结点编号)下的每个αj的和加起来等于1
而eij的计算,是通过将si-1与hj输入一个全连接神经网络得到。

也就是说,我们的编码器节点的注意力权重与编码器节点的隐含状态以及解码器上一个节点的隐含状态有关。
transformor模型中的注意力

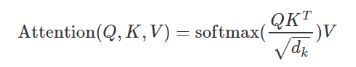
这里利用Q和K的点积进行相似度计算。为了维度不至于太大,再除以根号dk
self-attention
在编码器里和解码器第一个attention是self-attention,Q=K=V。
可以这么理解:
假设输入的一句话有3个单词,embedding分别为h0-h2
Q=(h0,h1,h2)T, //假设每一行是一个h,那么就有3行
KT=(h0T,h1T,h2T)
QKT=
(h0·h0,h0·h1,h0·h2
h1·h0,h1·h1,h1·h2
h2·h0,h2·h1,h2·h2)
得到的是一个相似度矩阵,将其缩小后,再乘以V=(h0,h1,h2)T,得到了一个新的隐含状态矩阵(h0’,h1’,h2’)T
(这个和GAT类似)
encoder-decoder attention

而在encoder和decoder的连接处的attention是encoder-decoder attention如上图所示。
Q来自decoder的上一个子层,K和V来自encoder子层的输出,因此K==V。
计算方法和上面一样















 2980
2980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









